Causal Ensemble Agent: Hierarchical Causal Discovery with LLM-guided Expert Reweighting
Pith reviewed 2026-06-27 14:00 UTC · model grok-4.3
The pith
CEA combines multiple causal discovery algorithms by pooling their outputs and calling on an LLM to reweight them only when the pooled result sits near a decision boundary.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
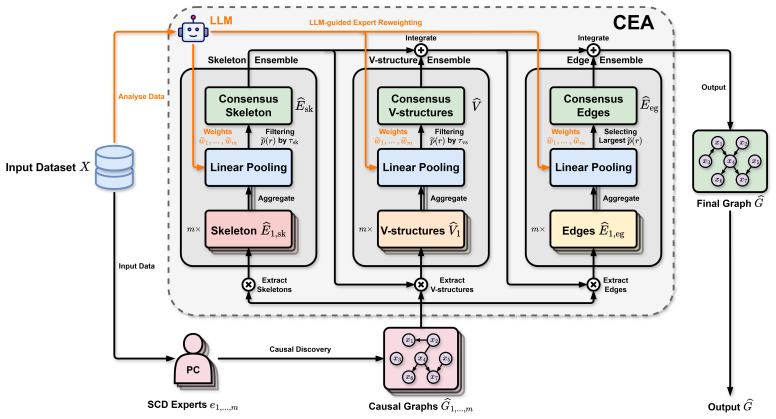
CEA aggregates structural insights from statistical discovery experts across different graph levels via linear opinion pooling, and uses an LLM as a meta-referee to dynamically reweight experts when the aggregated confidence is close to the decision boundary, thereby composing an improved and more complete causal graph.
What carries the argument
Linear opinion pooling of hierarchical graph insights combined with an LLM meta-referee that reweights experts only near decision boundaries.
If this is right
- Conflicting outputs from different statistical algorithms can be reconciled without discarding any of them.
- Domain information enters the process only at moments of statistical uncertainty rather than through direct LLM queries.
- The resulting graphs show stronger performance than either pure statistical methods or standalone LLM inference on both synthetic and real data.
Where Pith is reading between the lines
- The same selective-referee pattern could be tested in other ensemble settings where base models disagree on structure.
- Performance on datasets that include explicit textual feature descriptions would isolate how much the LLM's domain knowledge actually contributes.
- A controlled ablation that always invokes the LLM regardless of boundary condition would show whether the selective trigger is necessary.
Load-bearing premise
The LLM can supply reweighting decisions that improve alignment with the observed data when the aggregated expert is near the decision boundary.
What would settle it
If experiments that disable the LLM reweighting step produce no measurable drop in graph accuracy on the same synthetic and real-world datasets, the contribution of the meta-referee would be falsified.
Figures






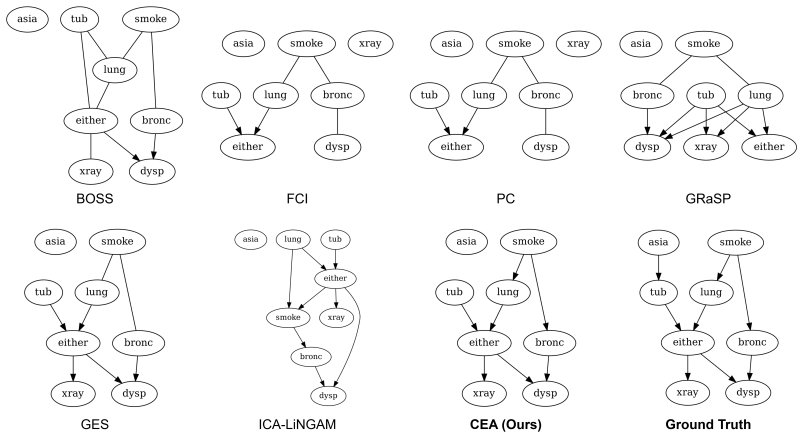
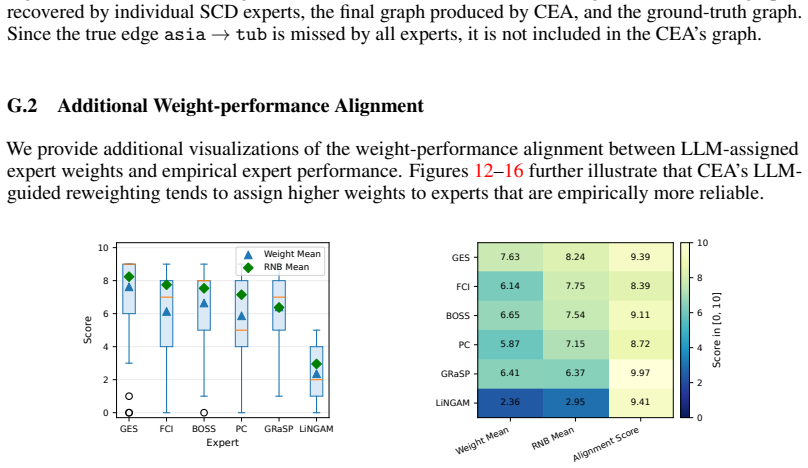
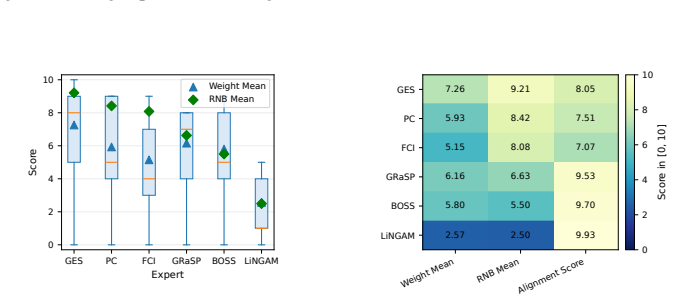
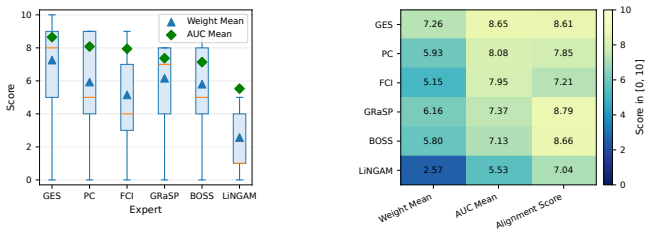
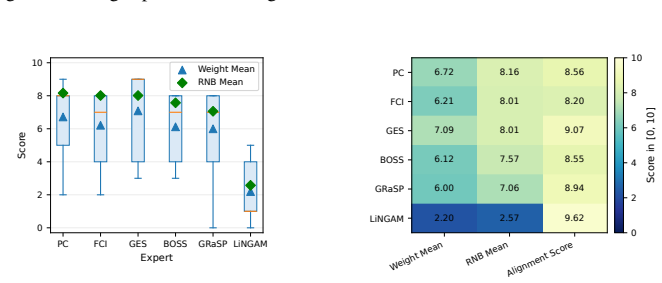
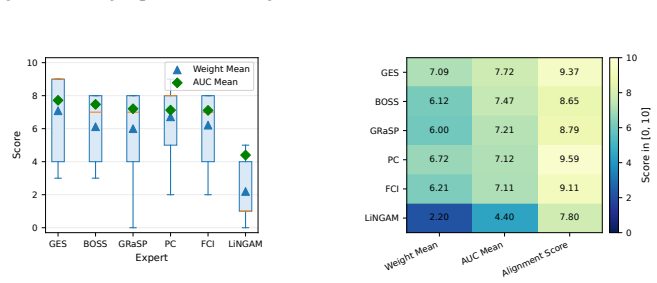
read the original abstract
Causal discovery aims to uncover causal structures from observational data, which is crucial for real-world decision-making. However, different causal discovery algorithms can produce divergent results that conflict with each other, complicating the identification of accurate causal graphs. Traditional approaches rely on numerical values and statistical assumptions, often ignoring rich domain-specific information, such as feature descriptions, which could also help structure learning. While recent works explore using Large Language Models (LLMs) to infer causal relations via direct queries, such methods can be unreliable due to a lack of alignment with the actual data. To address these limitations, we propose Causal Ensemble Agent (CEA), a novel framework that aggregates structural insights from statistical discovery experts across different graph levels via linear opinion pooling, and uses an LLM as a meta-referee to dynamically reweight experts when the aggregated confidence is close to the decision boundary, thereby composing an improved and more complete causal graph. Extensive experiments on both synthetic and real-world datasets demonstrate that CEA achieves the strongest overall performance across a wide range of causal discovery methods, highlighting the effectiveness of using LLMs for meta-analysis in causal discovery.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes the Causal Ensemble Agent (CEA), a hierarchical framework that aggregates outputs from multiple statistical causal discovery experts across graph levels using linear opinion pooling, then invokes an LLM as a meta-referee to dynamically reweight the experts only when the pooled confidence lies near the decision boundary. The central claim is that this yields measurably superior causal graphs on both synthetic and real-world datasets relative to a wide range of existing methods.
Significance. If the performance gains can be isolated to the LLM reweighting step and shown to be statistically reliable, the work would offer a principled way to inject domain knowledge into ensemble causal discovery precisely where statistical methods are most uncertain. The hierarchical pooling plus targeted LLM intervention is a clean architectural idea that could be reusable beyond the specific experts chosen here.
major comments (3)
- [§4 (Experiments)] §4 (Experiments) and the abstract: the headline claim that CEA 'achieves the strongest overall performance' rests on the incremental benefit of the LLM meta-referee reweighting, yet no ablation is reported that holds the multi-level linear opinion pooling fixed and compares (a) the full CEA pipeline against (b) the same pipeline with the LLM step disabled (or replaced by random/fixed reweighting). Without this isolation, superiority could be driven entirely by the pooling construction rather than the LLM component.
- [§3 (Method)] Method description (likely §3): the decision rule for invoking the LLM ('when the aggregated confidence is close to the decision boundary') is stated qualitatively but lacks an explicit, reproducible threshold or confidence measure; it is therefore impossible to determine whether the reported gains are robust to reasonable variations in that threshold or whether the LLM is invoked frequently enough to explain the claimed improvement.
- [Abstract] Abstract and §4: no quantitative metrics (SHD, F1, precision/recall on edges, etc.), no list of baselines, and no mention of statistical significance tests or number of random seeds appear in the summary of results. This prevents any assessment of effect size or whether the 'strongest overall performance' claim survives multiple-comparison correction across the 'wide range of causal discovery methods.'
minor comments (2)
- [§3] Notation for the linear opinion pooling weights and the LLM reweighting function should be introduced with explicit equations rather than prose descriptions to allow readers to verify the claimed 'parameter-free' or 'data-aligned' properties.
- [§4] Figure captions for the synthetic and real-world result plots should include the exact dataset names, sample sizes, and number of runs so that the 'extensive experiments' claim can be evaluated without consulting the main text.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights important areas for strengthening the experimental validation, reproducibility, and clarity of our results. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [§4 (Experiments)] §4 (Experiments) and the abstract: the headline claim that CEA 'achieves the strongest overall performance' rests on the incremental benefit of the LLM meta-referee reweighting, yet no ablation is reported that holds the multi-level linear opinion pooling fixed and compares (a) the full CEA pipeline against (b) the same pipeline with the LLM step disabled (or replaced by random/fixed reweighting). Without this isolation, superiority could be driven entirely by the pooling construction rather than the LLM component.
Authors: We agree that an ablation isolating the LLM reweighting contribution is necessary to substantiate the central claim. In the revised manuscript, we will add experiments that fix the multi-level linear opinion pooling and directly compare the full CEA pipeline against the same pipeline with the LLM step disabled (and, where appropriate, with random or fixed reweighting). This will clarify whether the reported gains are driven by the LLM meta-referee. revision: yes
-
Referee: [§3 (Method)] Method description (likely §3): the decision rule for invoking the LLM ('when the aggregated confidence is close to the decision boundary') is stated qualitatively but lacks an explicit, reproducible threshold or confidence measure; it is therefore impossible to determine whether the reported gains are robust to reasonable variations in that threshold or whether the LLM is invoked frequently enough to explain the claimed improvement.
Authors: We will revise §3 to specify an explicit, reproducible threshold on the aggregated confidence measure (including the precise formula used for aggregation) and report the frequency of LLM invocations across datasets. We will also add a sensitivity analysis showing performance under reasonable variations of the threshold to demonstrate robustness. revision: yes
-
Referee: [Abstract] Abstract and §4: no quantitative metrics (SHD, F1, precision/recall on edges, etc.), no list of baselines, and no mention of statistical significance tests or number of random seeds appear in the summary of results. This prevents any assessment of effect size or whether the 'strongest overall performance' claim survives multiple-comparison correction across the 'wide range of causal discovery methods.'
Authors: The abstract is intentionally concise, but we acknowledge that key quantitative details should be more visible. In the revision we will update the abstract to include representative metrics (e.g., SHD and F1), note the main baselines, and mention the use of multiple random seeds with statistical testing. The body of the paper already contains these details; we will ensure they are summarized clearly enough to support the performance claim. revision: partial
Circularity Check
No significant circularity detected in the proposed framework
full rationale
The paper introduces CEA as a framework that aggregates outputs from multiple statistical causal discovery experts using linear opinion pooling and applies LLM reweighting only in the low-confidence boundary regime. No equations, parameter-fitting procedures, or derivation steps are presented in the abstract or described text that reduce a claimed result to its own inputs by construction. The performance claims rest on experimental comparisons rather than a mathematical chain that could exhibit self-definition, fitted-input renaming, or load-bearing self-citation. The method is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
Socratic agents for autonomous scientific discovery in high-dimensional physical systems
AHOIS is a Socratic multi-agent AI that autonomously discovers and validates a random-interference encoding strategy for multimode fiber optics, achieving 76.97% MNIST and 83.17% Fashion-MNIST accuracy with 16x16 meas...
Reference graph
Works this paper leans on
-
[1]
Castro, and Daniel C
Ahmed Abdulaal, adamos hadjivasiliou, Nina Montana-Brown, Tiantian He, Ayodeji Ijishakin, Ivana Drobnjak, Daniel C. Castro, and Daniel C. Alexander. Causal modelling agents: Causal graph discovery through synergising metadata- and data-driven reasoning. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[2]
Fast scalable and accurate discovery of DAGs using the best order score search and grow shrink trees
Bryan Andrews, Joseph Ramsey, Ruben Sanchez Romero, Jazmin Camchong, and Erich Kummerfeld. Fast scalable and accurate discovery of DAGs using the best order score search and grow shrink trees. InThirty-seventh Conference on Neural Information Processing Systems, 2023
2023
-
[3]
Ensemble framework for causality learning with hetero- geneous directed acyclic graphs through the lens of optimization.Computers & Operations Research, 152:106148, 2023
Babak Aslani and Shima Mohebbi. Ensemble framework for causality learning with hetero- geneous directed acyclic graphs through the lens of optimization.Computers & Operations Research, 152:106148, 2023
2023
-
[4]
Optimal structure identification with greedy search.Journal of machine learning research, 3(Nov):507–554, 2002
David Maxwell Chickering. Optimal structure identification with greedy search.Journal of machine learning research, 3(Nov):507–554, 2002
2002
-
[5]
Data analysis with bayesian networks: A bootstrap approach, 2013
Nir Friedman, Moises Goldszmidt, and Abraham Wyner. Data analysis with bayesian networks: A bootstrap approach, 2013
2013
-
[6]
Review of causal discovery methods based on graphical models.Frontiers in genetics, 10:524, 2019
Clark Glymour, Kun Zhang, and Peter Spirtes. Review of causal discovery methods based on graphical models.Frontiers in genetics, 10:524, 2019
2019
-
[7]
Scalable and flexible two-phase ensemble algorithms for causality discovery.Big Data Research, 26:100252, 2021
Pei Guo, Yiyi Huang, and Jianwu Wang. Scalable and flexible two-phase ensemble algorithms for causality discovery.Big Data Research, 26:100252, 2021
2021
-
[8]
Probability inequalities for sums of bounded random variables.Journal of the American statistical association, 58(301):13–30, 1963
Wassily Hoeffding. Probability inequalities for sums of bounded random variables.Journal of the American statistical association, 58(301):13–30, 1963
1963
-
[9]
Nonlinear causal discovery with additive noise models.Advances in neural information processing systems, 21, 2008
Patrik Hoyer, Dominik Janzing, Joris M Mooij, Jonas Peters, and Bernhard Schölkopf. Nonlinear causal discovery with additive noise models.Advances in neural information processing systems, 21, 2008
2008
-
[10]
Benchmarking of data-driven causality discovery approaches in the interactions of arctic sea ice and atmosphere.Frontiers in big Data, 4:642182, 2021
Yiyi Huang, Matthäus Kleindessner, Alexey Munishkin, Debvrat Varshney, Pei Guo, and Jianwu Wang. Benchmarking of data-driven causality discovery approaches in the interactions of arctic sea ice and atmosphere.Frontiers in big Data, 4:642182, 2021
2021
-
[11]
Survey of hallucination in natural language generation
Ziwei Ji, Nayeon Lee, Rita Frieske, Tiezheng Yu, Dan Su, Yan Xu, Etsuko Ishii, Ye Jin Bang, Andrea Madotto, and Pascale Fung. Survey of hallucination in natural language generation. ACM Computing Surveys, 55(12):1–38, March 2023
2023
-
[12]
Efficient causal graph discovery using large language models
Thomas Jiralerspong, Xiaoyin Chen, Yash More, Vedant Shah, and Yoshua Bengio. Efficient causal graph discovery using large language models. InICLR 2024 Workshop: How Far Are We From AGI, 2024
2024
-
[13]
Causal reasoning and large language models: Opening a new frontier for causality, 2024
Emre Kıcıman, Robert Ness, Amit Sharma, and Chenhao Tan. Causal reasoning and large language models: Opening a new frontier for causality, 2024
2024
-
[14]
Greedy relaxations of the sparsest permuta- tion algorithm
Wai-Yin Lam, Bryan Andrews, and Joseph Ramsey. Greedy relaxations of the sparsest permuta- tion algorithm. In James Cussens and Kun Zhang, editors,Proceedings of the Thirty-Eighth Conference on Uncertainty in Artificial Intelligence, volume 180 ofProceedings of Machine Learning Research, pages 1052–1062. PMLR, 01–05 Aug 2022
2022
-
[15]
S. L. Lauritzen and D. J. Spiegelhalter.Local computations with probabilities on graphical structures and their application to expert systems, page 415–448. Morgan Kaufmann Publishers Inc., San Francisco, CA, USA, 1990
1990
-
[16]
Causal discovery with language models as imperfect experts
Stephanie Long, Alexandre Piché, Valentina Zantedeschi, Tibor Schuster, and Alexandre Drouin. Causal discovery with language models as imperfect experts. InICML 2023 Workshop on Structured Probabilistic Inference and Generative Modeling, 2023
2023
-
[17]
Can large language models build causal graphs? InNeurIPS 2022 Workshop on Causality for Real-world Impact, 2022
Stephanie Long, Tibor Schuster, and Alexandre Piché. Can large language models build causal graphs? InNeurIPS 2022 Workshop on Causality for Real-world Impact, 2022. 10
2022
-
[18]
Causal inference and causal explanation with background knowledge
Christopher Meek. Causal inference and causal explanation with background knowledge. In Proceedings of the Eleventh conference on Uncertainty in artificial intelligence, pages 403–410, 1995
1995
-
[19]
Cambridge University Press, USA, 2nd edition, 2009
Judea Pearl.Causality: Models, Reasoning and Inference. Cambridge University Press, USA, 2nd edition, 2009
2009
-
[20]
Chapman and Hall, Boca Raton, 2nd edition, 2021
Marco Scutari and Jean-Baptiste Denis.Bayesian Networks with Examples in R. Chapman and Hall, Boca Raton, 2nd edition, 2021. ISBN 978-0367366513
2021
-
[21]
Hoyer, Aapo Hyvärinen, and Antti Kerminen
Shohei Shimizu, Patrik O. Hoyer, Aapo Hyvärinen, and Antti Kerminen. A linear non-gaussian acyclic model for causal discovery.Journal of Machine Learning Research, 7(72):2003–2030, 2006
2003
-
[22]
Spirtes, C
P. Spirtes, C. Glymour, and R. Scheines.Causation, Prediction, and Search. MIT press, 2nd edition, 2000
2000
-
[23]
Causal inference in the presence of latent variables and selection bias
Peter Spirtes, Christopher Meek, and Thomas Richardson. Causal inference in the presence of latent variables and selection bias. UAI’95, page 499–506, San Francisco, CA, USA, 1995. Morgan Kaufmann Publishers Inc
1995
-
[24]
Causalrivers - scaling up benchmarking of causal discovery for real-world time-series
Gideon Stein, Maha Shadaydeh, Jan Blunk, Niklas Penzel, and Joachim Denzler. Causalrivers - scaling up benchmarking of causal discovery for real-world time-series. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[25]
Integrating large language models in causal discovery: A statistical causal approach, 2025
Masayuki Takayama, Tadahisa Okuda, Thong Pham, Tatsuyoshi Ikenoue, Shingo Fukuma, Shohei Shimizu, and Akiyoshi Sannai. Integrating large language models in causal discovery: A statistical causal approach, 2025
2025
-
[26]
Causal discovery in the wild: A voting-theoretic ensemble approach
Vy V o, Haoxuan Li, and Mingming Gong. Causal discovery in the wild: A voting-theoretic ensemble approach. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[27]
Learning directed acyclic graphs via bootstrap aggregating, 2014
Ru Wang and Jie Peng. Learning directed acyclic graphs via bootstrap aggregating, 2014
2014
-
[28]
Can foundation models talk causality?, 2022
Moritz Willig, Matej Zeˇcevi´c, Devendra Singh Dhami, and Kristian Kersting. Can foundation models talk causality?, 2022
2022
-
[29]
On the identifiability of the post-nonlinear causal model
Kun Zhang and Aapo Hyvärinen. On the identifiability of the post-nonlinear causal model. In Proceedings of the Twenty-Fifth Conference on Uncertainty in Artificial Intelligence, pages 647–655, 2009
2009
-
[30]
A weighted ensemble causal discovery method for effective connectivity estimation
Qiqi Zhang, Yingwei Zhang, Yanhui Ding, Yiqiang Chen, Shuchao Song, and Shuang Wu. A weighted ensemble causal discovery method for effective connectivity estimation. In2023 IEEE Smart World Congress (SWC), pages 1–8, 2023
2023
-
[31]
Causal graph discovery with retrieval-augmented generation based large language models, 2024
Yuzhe Zhang, Yipeng Zhang, Yidong Gan, Lina Yao, and Chen Wang. Causal graph discovery with retrieval-augmented generation based large language models, 2024
2024
-
[32]
A survey of large language models, 2025
Wayne Xin Zhao, Kun Zhou, Junyi Li, Tianyi Tang, Xiaolei Wang, Yupeng Hou, Yingqian Min, Beichen Zhang, Junjie Zhang, Zican Dong, Yifan Du, Chen Yang, Yushuo Chen, Zhipeng Chen, Jinhao Jiang, Ruiyang Ren, Yifan Li, Xinyu Tang, Zikang Liu, Peiyu Liu, Jian-Yun Nie, and Ji-Rong Wen. A survey of large language models, 2025
2025
-
[33]
Dags with no tears: Contin- uous optimization for structure learning
Xun Zheng, Bryon Aragam, Pradeep K Ravikumar, and Eric P Xing. Dags with no tears: Contin- uous optimization for structure learning. In S. Bengio, H. Wallach, H. Larochelle, K. Grauman, N. Cesa-Bianchi, and R. Garnett, editors,Advances in Neural Information Processing Systems, volume 31. Curran Associates, Inc., 2018
2018
-
[34]
Yujia Zheng, Biwei Huang, Wei Chen, Joseph Ramsey, Mingming Gong, Ruichu Cai, Shohei Shimizu, Peter Spirtes, and Kun Zhang. Causal-learn: Causal discovery in python, 2023. 11 A Additional Theoretical Analyses We provide concise guarantees for the components of CEA that are directly used in Section 3: bootstrap-based linear pooling, margin-aware LLM invoca...
arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.