BrainWorld: A Structural-Prior-Conditioned Generative Model for Whole-Brain 4D fMRI Dynamics
Pith reviewed 2026-06-27 01:16 UTC · model grok-4.3
The pith
BrainWorld generates stable whole-brain 4D fMRI trajectories up to 400 frames by conditioning a generative model on subject-level structural MRI.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
BrainWorld is a structural-prior-conditioned generative model that integrates sMRI as subject-level anatomical context directly into the denoising process for whole-brain 4D fMRI dynamics, rather than treating structure as a parallel modality, and thereby produces stable trajectories up to 400 frames while learning transferable multimodal representations that outperform baselines.
What carries the argument
The integration of sMRI as subject-level anatomical context directly into the denoising process of the generative model.
If this is right
- Generated fMRI sequences can be used as augmentation data to raise performance on downstream prediction tasks.
- The model supports generation of coherent 4D trajectories lasting at least 400 frames without rapid degradation.
- Representations learned by the conditioned model transfer across 22 datasets spanning different cohorts and brain states.
- The approach supplies a condition-aware framework that jointly addresses long-horizon dynamics modeling and multimodal representation learning.
Where Pith is reading between the lines
- If the conditioning mechanism generalizes, similar structural priors could be applied to other time-series imaging modalities where anatomy constrains function.
- Stable long-horizon generation opens the possibility of simulating extended brain-state transitions for hypothesis testing when real data collection is limited.
- Subject-specific anatomical context may prove necessary for capturing individual differences in functional dynamics that population-level models miss.
Load-bearing premise
The claim rests on the premise that embedding sMRI directly into the denoising process, as opposed to other modeling choices or data properties, is what produces the observed stability and representation gains.
What would settle it
An ablation study in which sMRI is instead supplied as a parallel modality yet still yields comparable trajectory stability and downstream gains would falsify the centrality of the specific denoising integration step.
Figures

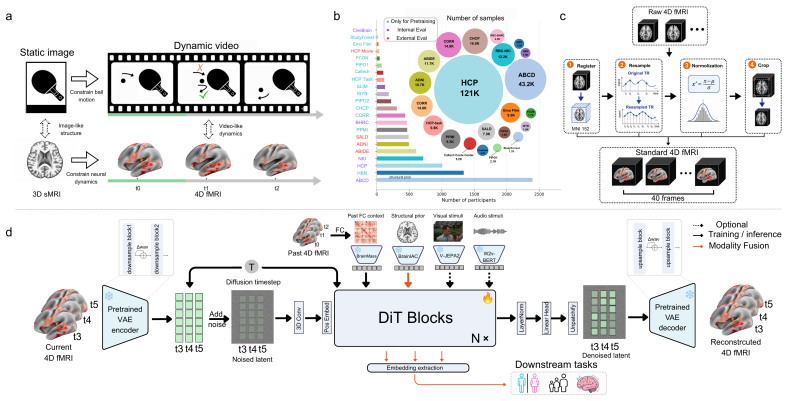
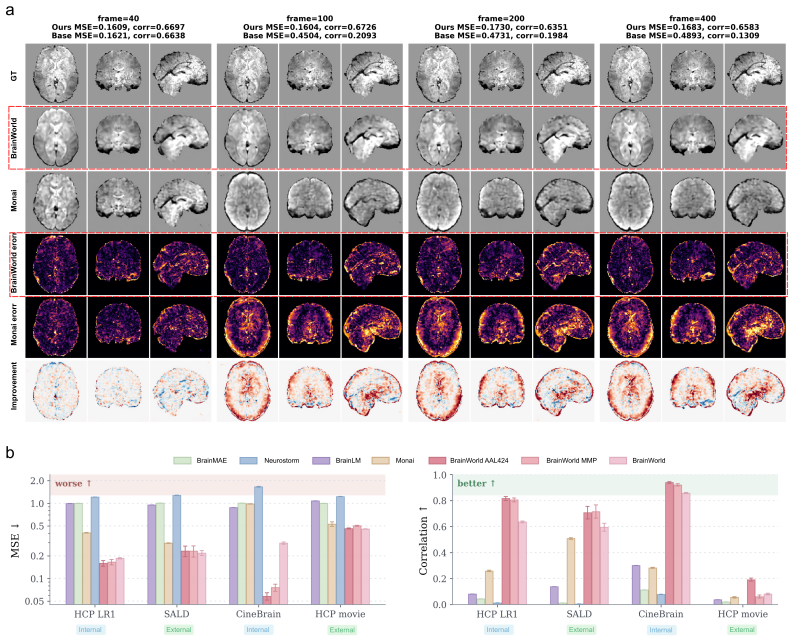

read the original abstract
Whole-brain 4D fMRI generation is valuable for modeling functional brain dynamics, yet existing fMRI foundation models mainly target representation learning and downstream prediction rather than conditional predictive generation. We introduce BrainWorld, a structural-prior-conditioned generative model for whole-brain 4D fMRI dynamics. BrainWorld uses sMRI as subject-level anatomical context to guide future fMRI generation, integrating structural information into the denoising process rather than treating it as a parallel modality. Evaluated on 22 datasets spanning diverse cohorts and brain states, BrainWorld generates stable 4D fMRI trajectories up to 400 frames, improves downstream performance through generated-example augmentation, and learns transferable multimodal representations that outperform baselines. Together, these results establish BrainWorld as a condition-aware generative framework for long-horizon brain dynamics modeling and multimodal representation learning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces BrainWorld, a structural-prior-conditioned generative model for whole-brain 4D fMRI dynamics. It conditions the denoising process directly on subject-level sMRI anatomical context (rather than treating sMRI as a parallel modality) to generate stable trajectories up to 400 frames. The model is evaluated on 22 datasets, with claims that it enables generated-example augmentation for improved downstream performance and learns transferable multimodal representations that outperform baselines.
Significance. If the central claims hold with rigorous validation, the work would be significant for conditional generative modeling in neuroimaging: long-horizon (400-frame) stable 4D fMRI synthesis remains difficult, and a method that demonstrably improves both generation stability and multimodal transfer across diverse cohorts could enable better data augmentation and representation learning. The emphasis on subject-level structural conditioning as a causal factor, if isolated, would also inform future multimodal diffusion architectures.
major comments (1)
- [Abstract] Abstract and Methods (implied): The central claim attributes stable 400-frame generation and outperformance on 22 datasets to integrating sMRI directly into the denoising process rather than as a parallel modality. No ablation or controlled comparison isolating this integration choice from other modeling decisions (architecture, loss, training schedule, or dataset properties) is described, leaving the causality of the reported gains unestablished.
minor comments (2)
- [Abstract] The abstract states evaluation on 22 datasets but provides no quantitative metrics, baseline comparisons, or data-split details; these should be summarized with effect sizes in the abstract or a results table.
- [Abstract] Notation for the conditioning mechanism (how sMRI is injected into the denoising network) is not previewed; a brief equation or diagram reference would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive assessment of the work's potential significance. We address the major comment on the need for ablation studies to establish causality of the structural conditioning below.
read point-by-point responses
-
Referee: [Abstract] Abstract and Methods (implied): The central claim attributes stable 400-frame generation and outperformance on 22 datasets to integrating sMRI directly into the denoising process rather than as a parallel modality. No ablation or controlled comparison isolating this integration choice from other modeling decisions (architecture, loss, training schedule, or dataset properties) is described, leaving the causality of the reported gains unestablished.
Authors: We agree that an explicit ablation isolating the contribution of integrating sMRI directly into the denoising process (as subject-level anatomical context) versus treating it as a parallel modality would strengthen the causal claims. While the manuscript compares against baselines that do not use this conditioning strategy, it does not include a controlled variant with sMRI handled as a parallel input. In the revised version, we will add such an ablation: training an otherwise identical model with sMRI concatenated or cross-attended as a separate modality, and reporting differences in long-horizon stability (up to 400 frames) and downstream augmentation/transfer performance across the evaluation datasets. This will help isolate the effect of the direct denoising conditioning. revision: yes
Circularity Check
No significant circularity; claims rest on empirical evaluation rather than self-referential derivation
full rationale
The abstract and description present BrainWorld as a generative model whose core claims (stable 400-frame trajectories, augmentation benefits, outperformance on 22 datasets) are supported by external evaluation on held-out data across cohorts. No equations, fitted-parameter predictions, or self-citation chains are visible that would reduce any result to its own inputs by construction. The integration of sMRI into denoising is presented as a modeling choice whose effect is tested empirically, not derived tautologically. This is the common honest case of a self-contained empirical paper.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
Beyond Single-Source Cognitive Taskonomy:Multi-Source Task Relations through fMRI Transfer Learning
Multi-source fMRI transfer learning on 23 HCP tasks reveals motor clusters with limited cross-paradigm transfer and uses BIP to prioritize working-memory states for direct supervision under budget constraints.
Reference graph
Works this paper leans on
-
[1]
An open resource for transdiagnostic research in pediatric mental health and learning disorders
Lindsay M Alexander, Jasmine Escalera, Lei Ai, Charissa Andreotti, Karina Febre, Alexander Mangone, Natan Vega-Potler, Nicolas Langer, Alexis Alexander, Meagan Kovacs, et al. An open resource for transdiagnostic research in pediatric mental health and learning disorders. Scientific data, 4(1):170181, 2017
2017
-
[2]
A massive 7T fMRI dataset to bridge cognitive neuroscience and artificial intelligence.Nature neuroscience, 25(1): 116–126, 2022
Emily J Allen, Ghislain St-Yves, Yihan Wu, Jesse L Breedlove, Jacob S Prince, Logan T Dowdle, Matthias Nau, Brad Caron, Franco Pestilli, Ian Charest, et al. A massive 7T fMRI dataset to bridge cognitive neuroscience and artificial intelligence.Nature neuroscience, 25(1): 116–126, 2022
2022
-
[3]
Mido Assran, Adrien Bardes, David Fan, Quentin Garrido, Russell Howes, Matthew Muckley, Ammar Rizvi, Claire Roberts, Koustuv Sinha, Artem Zholus, et al. V-jepa 2: Self-supervised video models enable understanding, prediction and planning.arXiv preprint arXiv:2506.09985, 2025
Pith/arXiv arXiv 2025
-
[4]
A computational model for preplay in the hippocampus.Frontiers in computational neuroscience, 7:161, 2013
Amir H Azizi, Laurenz Wiskott, and Sen Cheng. A computational model for preplay in the hippocampus.Frontiers in computational neuroscience, 7:161, 2013
2013
-
[5]
Loïc Barrault, Yu-An Chung, Mariano Coria Meglioli, David Dale, Ning Dong, Mark Dup- penthaler, Paul-Ambroise Duquenne, Brian Ellis, Hady Elsahar, Justin Haaheim, et al. Seamless: Multilingual expressive and streaming speech translation.arXiv preprint arXiv:2312.05187, 2023
arXiv 2023
-
[6]
A multimodal vision transformer for interpretable fusion of functional and structural neuroimaging data.Human brain mapping, 45 (17):e26783, 2024
Yuda Bi, Anees Abrol, Zening Fu, and Vince D Calhoun. A multimodal vision transformer for interpretable fusion of functional and structural neuroimaging data.Human brain mapping, 45 (17):e26783, 2024
2024
-
[7]
Toward discovery science of human brain function.Proceedings of the national academy of sciences, 107(10):4734–4739, 2010
Bharat B Biswal, Maarten Mennes, Xi-Nian Zuo, Suril Gohel, Clare Kelly, Steve M Smith, Christian F Beckmann, Jonathan S Adelstein, Randy L Buckner, Stan Colcombe, et al. Toward discovery science of human brain function.Proceedings of the national academy of sciences, 107(10):4734–4739, 2010
2010
-
[8]
Video generation models as world simulators
Tim Brooks, Bill Peebles, Connor Holmes, Will DePue, Yufei Guo, Leo Jing, David Schnurr, Joe Taylor, Troy Luhman, Eric Luhman, et al. Video generation models as world simulators. OpenAI Blog, 1(8):1, 2024
2024
-
[9]
Brainlm: A foundation model for brain activity recordings.BioRxiv, pages 2023–09, 2023
Josue Ortega Caro, Antonio H de O Fonseca, Christopher Averill, Syed A Rizvi, Matteo Rosati, James L Cross, Prateek Mittal, Emanuele Zappala, Daniel Levine, Rahul M Dhodapkar, et al. Brainlm: A foundation model for brain activity recordings.BioRxiv, pages 2023–09, 2023
2023
-
[10]
The adolescent brain cognitive development (abcd) study: imaging acquisition across 21 sites
Betty Jo Casey, Tariq Cannonier, May I Conley, Alexandra O Cohen, Deanna M Barch, Mary M Heitzeg, Mary E Soules, Theresa Teslovich, Danielle V Dellarco, Hugh Garavan, et al. The adolescent brain cognitive development (abcd) study: imaging acquisition across 21 sites. Developmental cognitive neuroscience, 32:43–54, 2018
2018
-
[11]
routledge, 2013
Jacob Cohen.Statistical power analysis for the behavioral sciences. routledge, 2013
2013
-
[12]
Iara Peixoto de Oliveira, Ana C Fernandéz, Giovanni A Salum, Ary Gadelha, Pedro Mario Pan, Eurípedes Constantino Miguel, Daniel C Mograbi, and Patricia Bado. Longitudinal patterns of disordered eating behaviors in children and adolescents from the brazilian high-risk cohort study for mental conditions.Brazilian Journal of Psychiatry, 47:e20243867, 2025
2025
-
[13]
The autism brain imaging data exchange: towards a large-scale evaluation of the intrinsic brain architecture in autism.Molecular psychiatry, 19(6):659–667, 2014
Adriana Di Martino, Chao-Gan Yan, Qingyang Li, Erin Denio, Francisco X Castellanos, Kaat Alaerts, Jeffrey S Anderson, Michal Assaf, Susan Y Bookheimer, Mirella Dapretto, et al. The autism brain imaging data exchange: towards a large-scale evaluation of the intrinsic brain architecture in autism.Molecular psychiatry, 19(6):659–667, 2014
2014
-
[14]
Brain-jepa: Brain dynamics foundation model with gradient positioning and spatiotemporal masking.Advances in Neural Information Processing Systems, 37:86048–86073, 2024
Zijian Dong, Ruilin Li, Yilei Wu, Thuan T Nguyen, Joanna S Chong, Fang Ji, Nathanael R Tong, Christopher L Chen, and Juan H Zhou. Brain-jepa: Brain dynamics foundation model with gradient positioning and spatiotemporal masking.Advances in Neural Information Processing Systems, 37:86048–86073, 2024. 10
2024
-
[15]
Zijian Dong, Ruilin Li, Joanna Su Xian Chong, Niousha Dehestani, Yinghui Teng, Yi Lin, Zhizhou Li, Yichi Zhang, Yapei Xie, Leon Qi Rong Ooi, et al. Brain harmony: A multi- modal foundation model unifying morphology and function into 1d tokens.arXiv preprint arXiv:2509.24693, 2025
arXiv 2025
-
[16]
Jianxiong Gao, Yichang Liu, Baofeng Yang, Jianfeng Feng, and Yanwei Fu. Cinebrain: A large-scale multi-modal brain dataset during naturalistic audiovisual narrative processing.arXiv preprint arXiv:2503.06940, 2025
arXiv 2025
-
[17]
A chinese multi-modal neuroimaging data release for increasing diversity of human brain mapping.Scientific Data, 9(1):286, 2022
Peng Gao, Hao-Ming Dong, Si-Man Liu, Xue-Ru Fan, Chao Jiang, Yin-Shan Wang, Daniel Margulies, Hai-Fang Li, and Xi-Nian Zuo. A chinese multi-modal neuroimaging data release for increasing diversity of human brain mapping.Scientific Data, 9(1):286, 2022
2022
-
[18]
A lung ct vision foundation model facilitating disease diagnosis and medical imaging.Nature Communications, 2025
Zebin Gao, Guoxun Zhang, Hengrui Liang, Jiaxin Liu, Liangdi Ma, Tianyun Wang, Yanchen Guo, YuJia Chen, Zeping Yan, Xiangru Chen, et al. A lung ct vision foundation model facilitating disease diagnosis and medical imaging.Nature Communications, 2025
2025
-
[19]
Increasing diversity in connectomics with the chinese human connectome project.Nature Neuroscience, 26(1):163–172, 2023
Jianqiao Ge, Guoyuan Yang, Meizhen Han, Sizhong Zhou, Weiwei Men, Lang Qin, Bingjiang Lyu, Hai Li, Haobo Wang, Hengyi Rao, et al. Increasing diversity in connectomics with the chinese human connectome project.Nature Neuroscience, 26(1):163–172, 2023
2023
-
[20]
A multi-modal parcellation of human cerebral cortex.Nature, 536(7615):171–178, 2016
Matthew F Glasser, Timothy S Coalson, Emma C Robinson, Carl D Hacker, John Harwell, Essa Yacoub, Kamil Ugurbil, Jesper Andersson, Christian F Beckmann, Mark Jenkinson, et al. A multi-modal parcellation of human cerebral cortex.Nature, 536(7615):171–178, 2016
2016
-
[21]
World models.arXiv preprint arXiv:1803.10122, 2(3):440, 2018
David Ha and Jürgen Schmidhuber. World models.arXiv preprint arXiv:1803.10122, 2(3):440, 2018
Pith/arXiv arXiv 2018
-
[22]
A studyfor- rest extension, simultaneous fmri and eye gaze recordings during prolonged natural stimulation
Michael Hanke, Nico Adelhöfer, Daniel Kottke, Vittorio Iacovella, Ayan Sengupta, Falko R Kaule, Roland Nigbur, Alexander Q Waite, Florian Baumgartner, and Jörg Stadler. A studyfor- rest extension, simultaneous fmri and eye gaze recordings during prolonged natural stimulation. Scientific data, 3(1):160092, 2016
2016
-
[23]
Classifier-free diffusion guidance.arXiv preprint arXiv:2207.12598, 2022
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance.arXiv preprint arXiv:2207.12598, 2022
Pith/arXiv arXiv 2022
-
[24]
Synthesizing realistic fmri: a physiological dynamics- driven hierarchical diffusion model for efficient fmri acquisition
Yufan Hu, Wuyang Li, Yixuan Yuan, et al. Synthesizing realistic fmri: a physiological dynamics- driven hierarchical diffusion model for efficient fmri acquisition. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[25]
Whitwell, Chadwick Ward, et al
Clifford R Jack Jr, Matt A Bernstein, Nick C Fox, Paul Thompson, Gene Alexander, Danielle Harvey, Bret Borowski, Paula J Britson, Jennifer L. Whitwell, Chadwick Ward, et al. The alzheimer’s disease neuroimaging initiative (adni): Mri methods.Journal of Magnetic Reso- nance Imaging: An Official Journal of the International Society for Magnetic Resonance in...
2008
-
[26]
Moein Khajehnejad, Forough Habibollahi, and Adeel Razi. Brainsymphony: A transformer- driven fusion of fmri time series and structural connectivity.arXiv preprint arXiv:2506.18314, 2025
arXiv 2025
-
[27]
Swift: Swin 4d fmri transformer.Advances in Neural Information Processing Systems, 36:42015–42037, 2023
Peter Kim, Junbeom Kwon, Sunghwan Joo, Sangyoon Bae, Donggyu Lee, Yoonho Jung, Shinjae Yoo, Jiook Cha, and Taesup Moon. Swift: Swin 4d fmri transformer.Advances in Neural Information Processing Systems, 36:42015–42037, 2023
2023
-
[28]
Caltech conte center, a multimodal data resource for exploring social cognition and decision-making.Scientific Data, 9 (1):138, 2022
Dorit Kliemann, Ralph Adolphs, Tim Armstrong, Paola Galdi, David A Kahn, Tessa Rusch, A Zeynep Enkavi, Deuhua Liang, Steven Lograsso, Wenying Zhu, et al. Caltech conte center, a multimodal data resource for exploring social cognition and decision-making.Scientific Data, 9 (1):138, 2022
2022
-
[29]
Weijie Kong, Qi Tian, Zijian Zhang, Rox Min, Zuozhuo Dai, Jin Zhou, Jiangfeng Xiong, Xin Li, Bo Wu, Jianwei Zhang, et al. Hunyuanvideo: A systematic framework for large video generative models.arXiv preprint arXiv:2412.03603, 2024. 11
Pith/arXiv arXiv 2024
-
[30]
Tian Lan, Yiming Zheng, and Jianxin Yin. Diffusion-based cross-modal feature extraction for multi-label classification.arXiv preprint arXiv:2509.15553, 2025
arXiv 2025
-
[31]
Wf-vae: Enhancing video vae by wavelet-driven energy flow for latent video diffusion model
Zongjian Li, Bin Lin, Yang Ye, Liuhan Chen, Xinhua Cheng, Shenghai Yuan, and Li Yuan. Wf-vae: Enhancing video vae by wavelet-driven energy flow for latent video diffusion model. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 17778–17788, 2025
2025
-
[32]
Longitudinal test-retest neuroimaging data from healthy young adults in southwest china.Scientific data, 4(1):170017, 2017
Wei Liu, Dongtao Wei, Qunlin Chen, Wenjing Yang, Jie Meng, Guorong Wu, Taiyong Bi, Qinglin Zhang, Xi-Nian Zuo, and Jiang Qiu. Longitudinal test-retest neuroimaging data from healthy young adults in southwest china.Scientific data, 4(1):170017, 2017
2017
-
[33]
The parkinson progression marker initiative (ppmi).Progress in neurobiology, 95(4):629–635, 2011
Kenneth Marek, Danna Jennings, Shirley Lasch, Andrew Siderowf, Caroline Tanner, Tanya Simuni, Chris Coffey, Karl Kieburtz, Emily Flagg, Sohini Chowdhury, et al. The parkinson progression marker initiative (ppmi).Progress in neurobiology, 95(4):629–635, 2011
2011
-
[34]
Milham, Damien Fair, Maarten Mennes, and Stewart H
Michael P. Milham, Damien Fair, Maarten Mennes, and Stewart H. Mostofsky. The adhd- 200 consortium: a model to advance the translational potential of neuroimaging in clinical neuroscience.Frontiers in Systems Neuroscience, V olume 6 - 2012, 2012. ISSN 1662-5137
2012
-
[35]
Emo-film: a multimodal dataset for affective neuroscience using naturalistic stimuli.Scientific Data, 12(1):684, 2025
Elenor Morgenroth, Stefano Moia, Laura Vilaclara, Raphael Fournier, Michal Muszynski, Maria Ploumitsakou, Marina Almató-Bellavista, Patrik Vuilleumier, and Dimitri Van De Ville. Emo-film: a multimodal dataset for affective neuroscience using naturalistic stimuli.Scientific Data, 12(1):684, 2025
2025
-
[36]
Do text-free diffusion models learn discriminative visual representations? InEuropean Conference on Computer Vision, pages 253–272
Soumik Mukhopadhyay, Matthew Gwilliam, Yosuke Yamaguchi, Vatsal Agarwal, Namitha Padmanabhan, Archana Swaminathan, Tianyi Zhou, Jun Ohya, and Abhinav Shrivastava. Do text-free diffusion models learn discriminative visual representations? InEuropean Conference on Computer Vision, pages 253–272. Springer, 2024
2024
-
[37]
Quantitative models reveal the organization of diverse cognitive functions in the brain.Nature communications, 11(1):1142, 2020
Tomoya Nakai and Shinji Nishimoto. Quantitative models reveal the organization of diverse cognitive functions in the brain.Nature communications, 11(1):1142, 2020
2020
-
[38]
A unique brain connectome fingerprint predates and predicts response to antidepressants.IScience, 23(1), 2020
Samaneh Nemati, Teddy J Akiki, Jeremy Roscoe, Yumeng Ju, Christopher L Averill, Samar Fouda, Arpan Dutta, Shane McKie, John H Krystal, JF William Deakin, et al. A unique brain connectome fingerprint predates and predicts response to antidepressants.IScience, 23(1), 2020
2020
-
[39]
A demographic-conditioned variational autoencoder for fmri distribution sampling and removal of confounds.ArXiv, pages arXiv–2405, 2024
Anton Orlichenko, Gang Qu, Ziyu Zhou, Anqi Liu, Hong-Wen Deng, Zhengming Ding, Julia M Stephen, Tony W Wilson, Vince D Calhoun, and Yu-Ping Wang. A demographic-conditioned variational autoencoder for fmri distribution sampling and removal of confounds.ArXiv, pages arXiv–2405, 2024
2024
-
[40]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF international conference on computer vision, pages 4195–4205, 2023
2023
-
[41]
Walter HL Pinaya, Mark S Graham, Eric Kerfoot, Petru-Daniel Tudosiu, Jessica Dafflon, Vir- ginia Fernandez, Pedro Sanchez, Julia Wolleb, Pedro F Da Costa, Ashay Patel, et al. Generative ai for medical imaging: extending the monai framework.arXiv preprint arXiv:2307.15208, 2023
arXiv 2023
-
[42]
Uncovering cognitive taskonomy through transfer learning in masked autoencoder-based fmri reconstruction
Youzhi Qu, Junfeng Xia, Xinyao Jian, Wendu Li, Kaining Peng, Zhichao Liang, Haiyan Wu, and Quanying Liu. Uncovering cognitive taskonomy through transfer learning in masked autoencoder-based fmri reconstruction. InInternational Workshop on Human Brain and Artificial Intelligence, pages 35–50. Springer, 2024
2024
-
[43]
Local-global parcellation of the human cerebral cortex from intrinsic functional connectivity mri.Cerebral cortex, 28(9):3095–3114, 2018
Alexander Schaefer, Ru Kong, Evan M Gordon, Timothy O Laumann, Xi-Nian Zuo, Avram J Holmes, Simon B Eickhoff, and BT Thomas Yeo. Local-global parcellation of the human cerebral cortex from intrinsic functional connectivity mri.Cerebral cortex, 28(9):3095–3114, 2018
2018
-
[44]
Jungwoo Seo, David Keetae Park, Shinjae Yoo, and Jiook Cha. Scalable diffusion transformer for conditional 4d fmri synthesis.arXiv preprint arXiv:2511.22870, 2025. 12
arXiv 2025
-
[45]
Reproducible brain charts: An open data resource for mapping brain development and its associations with mental health
Golia Shafiei, Nathalia B Esper, Mauricio S Hoffmann, Lei Ai, Andrew A Chen, Jon Cluce, Sydney Covitz, Steven Giavasis, Connor Lane, Kahini Mehta, et al. Reproducible brain charts: An open data resource for mapping brain development and its associations with mental health. Neuron, 113(22):3758–3779, 2025
2025
-
[46]
The amsterdam open mri collection, a set of multimodal mri datasets for individual difference analyses.Scientific data, 8(1):85, 2021
Lukas Snoek, Maite M van der Miesen, Tinka Beemsterboer, Andries Van Der Leij, Annemarie Eigenhuis, and H Steven Scholte. The amsterdam open mri collection, a set of multimodal mri datasets for individual difference analyses.Scientific data, 8(1):85, 2021
2021
-
[47]
V oxel-level brain states prediction using swin transformer.IEEE Journal of Biomedical and Health Informatics, 29(12):8719–8726, 2025
Yifei Sun, Daniel Chahine, Qinghao Wen, Tianming Liu, Xiang Li, Yixuan Yuan, Fernando Calamante, and Jinglei Lv. V oxel-level brain states prediction using swin transformer.IEEE Journal of Biomedical and Health Informatics, 29(12):8719–8726, 2025
2025
-
[48]
Axiomatic attribution for deep networks
Mukund Sundararajan, Ankur Taly, and Qiqi Yan. Axiomatic attribution for deep networks. In International conference on machine learning, pages 3319–3328. PMLR, 2017
2017
-
[49]
A foundation model for generalized brain mri analysis.MedRxiv, 2024
Divyanshu Tak, Biniam A Garomsa, Tafadzwa L Chaunzwa, Anna Zapaishchykova, Juan Carlos Climent Pardo, Zezhong Ye, John Zielke, Yashwanth Ravipati, Sri Vajapeyam, Maryam Mahootiha, et al. A foundation model for generalized brain mri analysis.MedRxiv, 2024
2024
-
[50]
An open-access dataset of naturalistic viewing using simultaneous eeg-fmri.Scientific Data, 10(1): 554, 2023
Qawi K Telesford, Eduardo Gonzalez-Moreira, Ting Xu, Yiwen Tian, Stanley J Colcombe, Jessica Cloud, Brian E Russ, Arnaud Falchier, Maximilian Nentwich, Jens Madsen, et al. An open-access dataset of naturalistic viewing using simultaneous eeg-fmri.Scientific Data, 10(1): 554, 2023
2023
-
[51]
The WU-Minn Human Connectome Project: An Overview.Neuroimage, 80:62–79, 2013
David C Van Essen, Stephen M Smith, Deanna M Barch, Timothy EJ Behrens, Essa Yacoub, Kamil Ugurbil, Wu-Minn HCP Consortium, et al. The WU-Minn Human Connectome Project: An Overview.Neuroimage, 80:62–79, 2013
2013
-
[52]
Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, Jianyuan Zeng, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 3(4):6, 2025
Pith/arXiv arXiv 2025
-
[53]
Towards a general-purpose foundation model for fmri analysis.arXiv preprint arXiv:2506.11167, 2025
Cheng Wang, Yu Jiang, Zhihao Peng, Chenxin Li, Changbae Bang, Lin Zhao, Jinglei Lv, Jorge Sepulcre, Carl Yang, Lifang He, et al. Towards a general-purpose foundation model for fmri analysis.arXiv preprint arXiv:2506.11167, 2025
arXiv 2025
-
[54]
Mo Wang, Junfeng Xia, Wenhao Ye, Enyu Liu, Kaining Peng, Jianfeng Feng, Quanying Liu, and Hongkai Wen. SLIM-Brain: A Data-and Training-Efficient Foundation Model for fMRI Data Analysis.arXiv preprint arXiv:2512.21881, 2025
arXiv 2025
-
[55]
Mo Wang, Wenhao Ye, Junfeng Xia, Minghao Xu, Hongkai Wen, and Quanying Liu. Flexibrain: Resolution-agnostic voxel-level encoding for native fmri.arXiv preprint arXiv:2606.11500, 2026
Pith/arXiv arXiv 2026
-
[56]
Omni-fmri: A universal atlas-free fmri foundation model
Mo Wang, Wenhao Ye, Junfeng Xia, Junxiang Zhang, Xuanye Pan, Minghao Xu, Haotian Deng, Hongkai Wen, and Quanying Liu. Omni-fmri: A universal atlas-free fmri foundation model. arXiv preprint arXiv:2601.23090, 2026
arXiv 2026
-
[57]
Eegdm: Learning eeg representation with latent diffusion model.arXiv preprint arXiv:2508.20705, 2025
Shaocong Wang, Tong Liu, Yihan Li, Ming Li, Kairui Wen, Pei Yang, Wenqi Ji, Minjing Yu, and Yong-Jin Liu. Eegdm: Learning eeg representation with latent diffusion model.arXiv preprint arXiv:2508.20705, 2025
Pith/arXiv arXiv 2025
-
[58]
Structural and functional brain scans from the cross- sectional Southwest University adult lifespan dataset.Scientific Data, 5(1):180134, July 2018
Dongtao Wei, Kaixiang Zhuang, Lei Ai, Qunlin Chen, Wenjing Yang, Wei Liu, Kangcheng Wang, Jiangzhou Sun, and Jiang Qiu. Structural and functional brain scans from the cross- sectional Southwest University adult lifespan dataset.Scientific Data, 5(1):180134, July 2018. ISSN 2052-4463
2018
-
[59]
Yuxiang Wei, Yanteng Zhang, Xi Xiao, Chengxuan Qian, Tianyang Wang, and Vince D Calhoun. fmri-lm: Towards a universal foundation model for language-aligned fmri understanding.arXiv preprint arXiv:2511.21760, 2025. 13
Pith/arXiv arXiv 2025
-
[60]
4d multimodal co-attention fusion network with latent contrastive alignment for alzheimer’s diagnosis
Yuxiang Wei, Yanteng Zhang, Xi Xiao, Tianyang Wang, Xiao Wang, and Vince D Calhoun. 4d multimodal co-attention fusion network with latent contrastive alignment for alzheimer’s diagnosis. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 5457–5466, 2026
2026
-
[61]
Junfeng Xia, Wenhao Ye, Xuanye Pan, Xinke Shen, Mo Wang, and Quanying Liu. Brain-dit: A universal multi-state fmri foundation model with metadata-conditioned pretraining.arXiv preprint arXiv:2604.12683, 2026
Pith/arXiv arXiv 2026
-
[62]
Simmim: A simple framework for masked image modeling
Zhenda Xie, Zheng Zhang, Yue Cao, Yutong Lin, Jianmin Bao, Zhuliang Yao, Qi Dai, and Han Hu. Simmim: A simple framework for masked image modeling. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9653–9663, 2022
2022
-
[63]
Nyströmformer: A nyström-based algorithm for approximating self-attention
Yunyang Xiong, Zhanpeng Zeng, Rudrasis Chakraborty, Mingxing Tan, Glenn Fung, Yin Li, and Vikas Singh. Nyströmformer: A nyström-based algorithm for approximating self-attention. In Proceedings of the AAAI conference on artificial intelligence, volume 35, pages 14138–14148, 2021
2021
-
[64]
Diffusion model as representation learner
Xingyi Yang and Xinchao Wang. Diffusion model as representation learner. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 18938–18949, 2023
2023
-
[65]
Brainmass: Advancing brain network analysis for diagnosis with large-scale self-supervised learning.IEEE transactions on medical imaging, 43(11):4004–4016, 2024
Yanwu Yang, Chenfei Ye, Guinan Su, Ziyao Zhang, Zhikai Chang, Hairui Chen, Piu Chan, Yue Yu, and Ting Ma. Brainmass: Advancing brain network analysis for diagnosis with large-scale self-supervised learning.IEEE transactions on medical imaging, 43(11):4004–4016, 2024
2024
-
[66]
Deep fusion of brain structure- function in mild cognitive impairment.Medical image analysis, 72:102082, 2021
Lu Zhang, Li Wang, Jean Gao, Shannon L Risacher, Jingwen Yan, Gang Li, Tianming Liu, Dajiang Zhu, Alzheimer’s Disease Neuroimaging Initiative, et al. Deep fusion of brain structure- function in mild cognitive impairment.Medical image analysis, 72:102082, 2021
2021
-
[67]
An open science resource for establishing reliability and reproducibility in functional connectomics
Xi-Nian Zuo, Jeffrey S Anderson, Pierre Bellec, Rasmus M Birn, Bharat B Biswal, Janusch Blautzik, John Breitner, Randy L Buckner, Vince D Calhoun, F Xavier Castellanos, et al. An open science resource for establishing reliability and reproducibility in functional connectomics. Scientific data, 1(1):140049, 2014. 14 Supplementary Material A. ROI baseline f...
2014
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.