EventVLA: Event-Driven Visual Evidence Memory for Long-Horizon Vision-Language-Action Policies
Pith reviewed 2026-06-30 10:46 UTC · model grok-4.3
The pith
EventVLA stores sparse task-critical visual events by predicting future keyframes from VLA latent embeddings.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
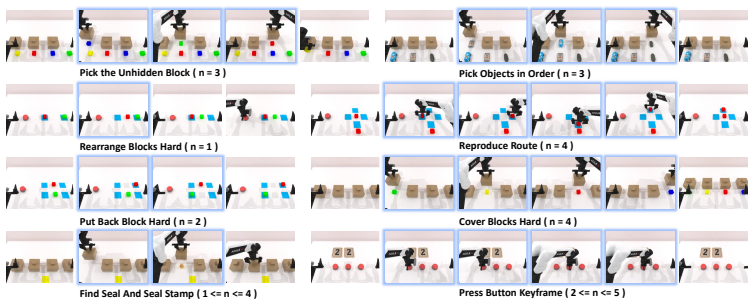
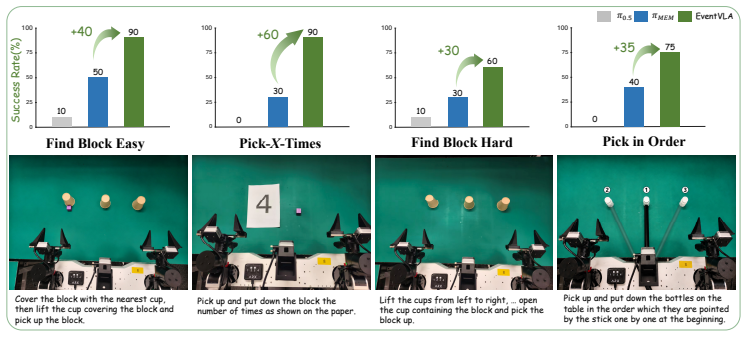
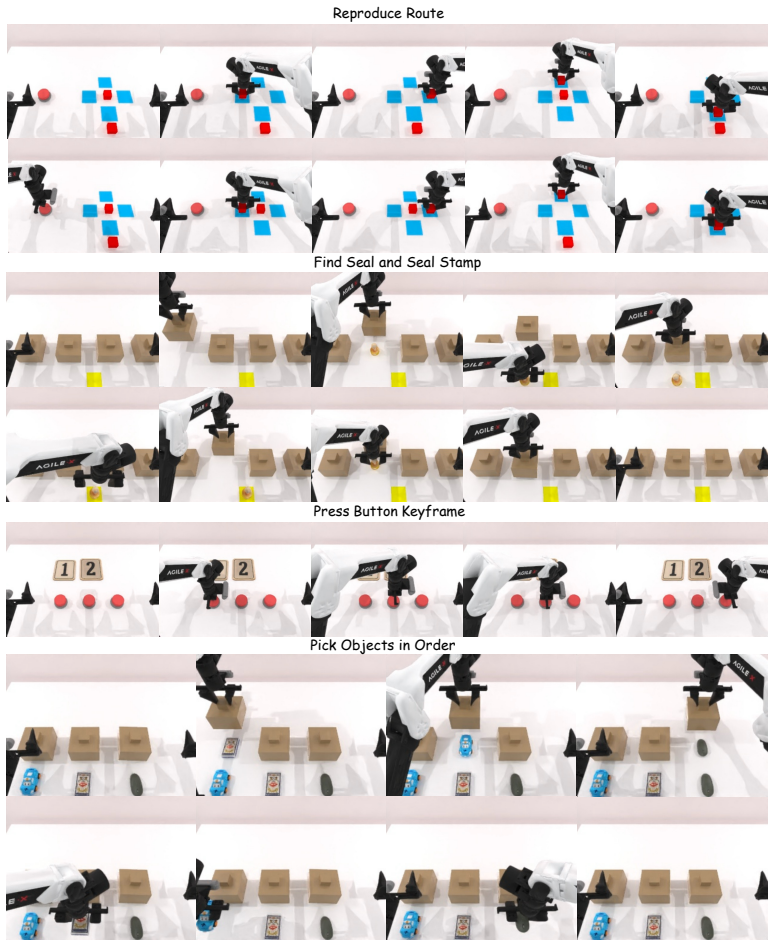
EventVLA is an end-to-end framework that maintains sparse visual evidence memory through foundational visual anchors and a Keyframe Evidence Memory module. The module predicts future keyframe probabilities directly from the VLA's latent embeddings, allowing the policy to capture and retain transient, task-critical visual events before they become unobservable. This foresight-driven selection replaces both dense history buffers and decoupled dual systems, producing an average success-rate gain of forty percent on seventeen simulation tasks and four real bimanual tasks while introducing the RoboTwin-MeM benchmark for evaluating non-Markovian manipulation.
What carries the argument
Keyframe Evidence Memory (KEM) module that predicts future keyframe probabilities from the VLA's latent embeddings to autonomously capture and store sparse task-critical visual events.
If this is right
- Policies avoid both information bottlenecks from compressed history and latency from separate memory systems.
- Selective storage eliminates the accumulation of visual redundancies that plague unselective buffers.
- The same architecture supports both simulated and real-world bimanual manipulation without task-specific redesign.
- The RoboTwin-MeM benchmark provides a standardized way to measure progress on non-Markovian manipulation.
Where Pith is reading between the lines
- The same predictive selection principle could be tested on long-horizon navigation or household activity sequences where visual state changes are irreversible.
- If KEM predictions remain reliable under distribution shift, the method might reduce the need for explicit object tracking in robotic stacks.
- The benchmark tasks could serve as a test bed for any memory mechanism that claims to handle temporary observability loss.
Load-bearing premise
The Keyframe Evidence Memory module can accurately predict future keyframe probabilities directly from the VLA's latent embeddings in a way that captures task-critical visual events before they become unobservable.
What would settle it
Running EventVLA on a set of occlusion-heavy tasks where the KEM module is replaced by random keyframe selection and measuring whether the forty-percent success-rate gain disappears.
Figures





read the original abstract
Memory remains a critical bottleneck for long-horizon robotic manipulation, as standard Vision-Language-Action (VLA) policies often fail when task-relevant cues become occluded or unobservable over time. While existing memory-augmented methods utilize historical context, they either suffer from severe information bottlenecks, incur high latency via decoupled dual systems, or rely on unselective buffers that accumulate massive visual redundancies. To address these limitations, we introduce EventVLA, an end-to-end framework founded on the concept of sparse visual evidence memory that comprises two core components: foundational visual anchors to retain initial and short-term contexts, and a dynamic Keyframe Evidence Memory (KEM) module. Specifically, KEM directly predicts future keyframe probabilities from the VLA's latent embeddings to autonomously capture and store sparse, task-critical visual events. This foresight-driven mechanism empowers the policy to dynamically evaluate the future causal utility of current observations, preserving transient visual evidence before it becomes unobservable. Furthermore, we propose RoboTwin-MeM, a diagnostic benchmark specifically designed to evaluate non-Markovian manipulation tasks with interactive visual evidence. Extensive evaluations show that across 17 memory-requiring simulation tasks and 4 real-world bimanual tasks, EventVLA achieves an average success rate improvement of +40% over state-of-the-art memory-augmented VLAs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces EventVLA, an end-to-end framework for long-horizon vision-language-action (VLA) policies. It proposes sparse visual evidence memory with foundational visual anchors and a Keyframe Evidence Memory (KEM) module that predicts future keyframe probabilities from the VLA's latent embeddings to capture task-critical visual events before they become unobservable. The paper also presents the RoboTwin-MeM benchmark for non-Markovian manipulation tasks and reports an average +40% success rate improvement over state-of-the-art memory-augmented VLAs on 17 simulation tasks and 4 real-world bimanual tasks.
Significance. If the reported performance improvements are substantiated, the work could have significant impact on developing more robust VLA policies for complex, long-horizon robotic tasks by addressing memory bottlenecks in a computationally efficient manner. The diagnostic benchmark for memory-requiring tasks is a useful contribution to the field.
major comments (2)
- [Abstract] Abstract: The central claim of a +40% average success rate improvement is presented without any reference to the experimental protocol, specific baselines used, number of evaluation runs, statistical tests, or ablation studies. This information is load-bearing for evaluating whether the gains are attributable to the KEM module.
- [§3 (Method), KEM module] §3 (Method), KEM module: The Keyframe Evidence Memory module is described as directly predicting future keyframe probabilities from latent embeddings, but no details are provided on the prediction head architecture, training objective, supervision signal, or any validation metric for the prediction accuracy. This is critical for assessing if the foresight mechanism functions as claimed.
minor comments (1)
- [Abstract] Abstract: The term 'foundational visual anchors' is introduced without a clear definition or distinction from standard initial state retention.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments below and will revise the manuscript to improve clarity on experimental claims and methodological details.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim of a +40% average success rate improvement is presented without any reference to the experimental protocol, specific baselines used, number of evaluation runs, statistical tests, or ablation studies. This information is load-bearing for evaluating whether the gains are attributable to the KEM module.
Authors: We agree that the abstract would benefit from additional context. In the revised version, we will add a sentence summarizing the evaluation protocol: results are reported as averages over 17 simulation tasks from the RoboTwin-MeM benchmark and 4 real-world bimanual tasks, compared against state-of-the-art memory-augmented VLAs, with full details on baselines, run counts, ablations, and statistical analysis provided in Section 4. This keeps the abstract concise while directing readers to the supporting evidence. revision: yes
-
Referee: [§3 (Method), KEM module] §3 (Method), KEM module: The Keyframe Evidence Memory module is described as directly predicting future keyframe probabilities from latent embeddings, but no details are provided on the prediction head architecture, training objective, supervision signal, or any validation metric for the prediction accuracy. This is critical for assessing if the foresight mechanism functions as claimed.
Authors: We acknowledge that Section 3 would be strengthened by explicit details on the KEM implementation. We will expand the section in the revised manuscript to describe the prediction head architecture, training objective, supervision signal, and any validation metrics used for keyframe probability prediction. This will allow readers to fully assess the foresight mechanism. revision: yes
Circularity Check
No circularity; empirical claims rest on external task evaluations
full rationale
The paper introduces EventVLA as an engineering framework with KEM for predicting keyframe probabilities from latent embeddings, but reports performance solely via success rates on 17 simulation tasks and 4 real-world tasks. No equations, derivations, or self-citations appear in the provided text that reduce any result to a fitted input or self-defined quantity. The +40% improvement is presented as an observed outcome on held-out benchmarks rather than a constructed prediction, rendering the chain self-contained without circular reduction.
Axiom & Free-Parameter Ledger
invented entities (2)
-
Keyframe Evidence Memory (KEM)
no independent evidence
-
foundational visual anchors
no independent evidence
Forward citations
Cited by 1 Pith paper
-
DIM-WAM: World-Action Modeling with Diverse Historical Event Memory
DiM-WAM is a memory-augmented world-action model that integrates multi-scale historical events and global task progress to improve long-horizon robot manipulation performance.
Reference graph
Works this paper leans on
-
[1]
$\pi_{0.5}$: a Vision-Language-Action Model with Open-World Generalization
P. Intelligence, K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, et al. π0.5: a vision-language-action model with open-world generalization. arXiv preprint arXiv:2504.16054, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
$\pi^{*}_{0.6}$: a VLA That Learns From Experience
P. Intelligence, A. Amin, R. Aniceto, A. Balakrishna, K. Black, K. Conley, G. Connors, J. Darpinian, K. Dhabalia, J. DiCarlo, et al. π∗ 0.6: a vla that learns from experience.arXiv preprint arXiv:2511.14759, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
C. Chi, Z. Xu, S. Feng, E. Cousineau, Y . Du, B. Burchfiel, R. Tedrake, and S. Song. Diffusion policy: Visuomotor policy learning via action diffusion.The International Journal of Robotics Research, 44(10-11):1684–1704, 2025
2025
-
[4]
Y . Ze, G. Zhang, K. Zhang, C. Hu, M. Wang, and H. Xu. 3d diffusion policy: Generalizable visuomotor policy learning via simple 3d representations.arXiv preprint arXiv:2403.03954, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
T. Z. Zhao, V . Kumar, S. Levine, and C. Finn. Learning fine-grained bimanual manipulation with low-cost hardware.arXiv preprint arXiv:2304.13705, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
Y . Dai, H. Fu, J. Lee, Y . Liu, H. Zhang, J. Yang, C. Finn, N. Fazeli, and J. Chai. Robomme: Benchmarking and understanding memory for robotic generalist policies.arXiv preprint arXiv:2603.04639, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[7]
A. Sridhar, J. Pan, S. Sharma, and C. Finn. Memer: Scaling up memory for robot control via experience retrieval.arXiv preprint arXiv:2510.20328, 2025
- [8]
- [9]
-
[10]
L. Xiao, J. Li, J. Gao, F. Ye, Y . Jin, J. Qian, J. Zhang, Y . Wu, and X. Yu. Ava-vla: Improving vision-language-action models with active visual attention.arXiv preprint arXiv:2511.18960, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Bulatov, Y
A. Bulatov, Y . Kuratov, and M. Burtsev. Recurrent memory transformer.Advances in Neural Information Processing Systems, 35:11079–11091, 2022. 9
2022
-
[12]
H. Shi, B. Xie, Y . Liu, L. Sun, F. Liu, T. Wang, E. Zhou, H. Fan, X. Zhang, and G. Huang. Mem- oryvla: Perceptual-cognitive memory in vision-language-action models for robotic manipulation. arXiv preprint arXiv:2508.19236, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
H. Li, S. Yang, Y . Chen, Y . Tian, X. Yang, X. Chen, H. Wang, T. Wang, F. Zhao, D. Lin, et al. Cronusvla: Transferring latent motion across time for multi-frame prediction in manipulation. arXiv e-prints, pages arXiv–2506, 2025
2025
- [14]
-
[15]
S. Bai, Y . Cai, R. Chen, K. Chen, X. Chen, Z. Cheng, L. Deng, W. Ding, C. Gao, C. Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [16]
-
[17]
X-VLA: Soft-Prompted Transformer as Scalable Cross-Embodiment Vision-Language-Action Model
J. Zheng, J. Li, Z. Wang, D. Liu, X. Kang, Y . Feng, Y . Zheng, J. Zou, Y . Chen, J. Zeng, et al. X-vla: Soft-prompted transformer as scalable cross-embodiment vision-language-action model. arXiv preprint arXiv:2510.10274, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
T. Chen, Y . Mu, Z. Liang, Z. Chen, S. Peng, Q. Chen, M. Xu, R. Hu, H. Zhang, X. Li, et al. G3flow: Generative 3d semantic flow for pose-aware and generalizable object manipulation. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 1735–1744, 2025
2025
-
[19]
J. Wen, Y . Zhu, J. Li, Z. Tang, C. Shen, and F. Feng. Dexvla: Vision-language model with plug-in diffusion expert for general robot control.arXiv preprint arXiv:2502.05855, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
M. Lin, P. Ding, S. Wang, Z. Zhuang, Y . Liu, X. Tong, W. Song, S. Lyu, S. Huang, and D. Wang. Hif-vla: Hindsight, insight and foresight through motion representation for vision-language- action models.arXiv preprint arXiv:2512.09928, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
Z. Liang, Y . Li, T. Yang, C. Wu, S. Mao, T. Nian, L. Pei, S. Zhou, X. Yang, J. Pang, et al. Discrete diffusion vla: Bringing discrete diffusion to action decoding in vision-language-action policies.arXiv preprint arXiv:2508.20072, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [22]
- [23]
-
[24]
J. Wen, Y . Zhu, M. Zhu, Z. Tang, J. Li, Z. Zhou, X. Liu, C. Shen, Y . Peng, and F. Feng. Diffusionvla: Scaling robot foundation models via unified diffusion and autoregression. In Forty-second International Conference on Machine Learning, 2025
2025
-
[25]
J. Wen, Y . Zhu, J. Li, M. Zhu, Z. Tang, K. Wu, Z. Xu, N. Liu, R. Cheng, C. Shen, et al. Tinyvla: Towards fast, data-efficient vision-language-action models for robotic manipulation.IEEE Robotics and Automation Letters, 2025
2025
-
[26]
Zheng, Y
R. Zheng, Y . Liang, S. Huang, J. Gao, H. Daum ´e III, A. Kolobov, F. Huang, and J. Yang. Tracevla: Visual trace prompting enhances spatial-temporal awareness for generalist robotic policies. InInternational Conference on Learning Representations, volume 2025, pages 54277– 54296, 2025. 10
2025
- [27]
- [28]
- [29]
- [30]
- [31]
- [32]
- [33]
- [34]
-
[35]
T. Chen, Z. Chen, B. Chen, Z. Cai, Y . Liu, Z. Li, Q. Liang, X. Lin, Y . Ge, Z. Gu, et al. Robotwin 2.0: A scalable data generator and benchmark with strong domain randomization for robust bimanual robotic manipulation.arXiv preprint arXiv:2506.18088, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
RoboCasa: Large-Scale Simulation of Everyday Tasks for Generalist Robots
S. Nasiriany, A. Maddukuri, L. Zhang, A. Parikh, A. Lo, A. Joshi, A. Mandlekar, and Y . Zhu. Robocasa: Large-scale simulation of everyday tasks for generalist robots.arXiv preprint arXiv:2406.02523, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [37]
-
[38]
C. Li, R. Zhang, J. Wong, C. Gokmen, S. Srivastava, R. Mart´ın-Mart´ın, C. Wang, G. Levine, M. Lingelbach, J. Sun, et al. Behavior-1k: A benchmark for embodied ai with 1,000 everyday activities and realistic simulation. InConference on Robot Learning, pages 80–93. PMLR, 2023
2023
-
[39]
X. Li, K. Hsu, J. Gu, K. Pertsch, O. Mees, H. R. Walke, C. Fu, I. Lunawat, I. Sieh, S. Kir- mani, et al. Evaluating real-world robot manipulation policies in simulation.arXiv preprint arXiv:2405.05941, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [40]
-
[41]
E. Cherepanov, N. Kachaev, A. K. Kovalev, and A. I. Panov. Memory, benchmark & robots: A benchmark for solving complex tasks with reinforcement learning.arXiv preprint arXiv:2502.10550, 2025
-
[42]
B. Liu, Y . Zhu, C. Gao, Y . Feng, Q. Liu, Y . Zhu, and P. Stone. Libero: Benchmarking knowledge transfer for lifelong robot learning.Advances in Neural Information Processing Systems, 36: 44776–44791, 2023. 11
2023
-
[43]
S. Han, B. Qiu, Y . Liao, S. Huang, C. Gao, S. Yan, and S. Liu. Robocerebra: A large-scale benchmark for long-horizon robotic manipulation evaluation.Advances in Neural Information Processing Systems, 38, 2026
2026
-
[44]
H. Lei, W. Song, H. Zhang, J. Pei, J. Chen, H. Yan, H. Zhao, P. Ding, Z. Zhang, L. Huang, et al. Robomemarena: A comprehensive and challenging robotic memory benchmark.arXiv preprint arXiv:2605.10921, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[45]
Xiang, Y
F. Xiang, Y . Qin, K. Mo, Y . Xia, H. Zhu, F. Liu, M. Liu, H. Jiang, Y . Yuan, H. Wang, et al. Sapien: A simulated part-based interactive environment. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11097–11107, 2020
2020
-
[46]
StarVLA: A Lego-like Codebase for Vision-Language-Action Model Developing
S. Community. Starvla: A lego-like codebase for vision-language-action model developing. arXiv preprint arXiv:2604.05014, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[47]
M. J. Kim, C. Finn, and P. Liang. Fine-tuning vision-language-action models: Optimizing speed and success.arXiv preprint arXiv:2502.19645, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[48]
W. Kwon, Z. Li, S. Zhuang, Y . Sheng, L. Zheng, C. H. Yu, J. E. Gonzalez, H. Zhang, and I. Stoica. Efficient memory management for large language model serving with pagedattention. InProceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles, 2023. 12 Appendix A Implementation Details of EventVLA A.1 Training Formulations and Curriculum ...
2023
-
[49]
Find key state transitions for this task (e.g., stable grasp acquired, object placed, cycle transition)
-
[50]
Keep keyframes representative and temporally ordered across the full task progress
-
[51]
Output format constraints:
For repeated pick/place cycles, pick the most stable and recognizable moments per cycle. Output format constraints:
-
[52]
No markdown, no explanations
Return JSON only. No markdown, no explanations
-
[53]
Format:{”keyframe steps”: [int, int, ...]} 3.keyframe stepsmust: - have length exactly<num keyframes> - be strictly increasing - be in [0,<total frames - 1>] - contain no duplicates Annotation Reliability and Error Analysis.To rigorously validate the reliability of this automated pipeline, we conducted a comprehensive cross-validation study. In the simula...
2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.