Stuttering Classification and Segmentation with Attention-Based Multiple Instance Learning
Pith reviewed 2026-06-26 15:32 UTC · model grok-4.3
The pith
Attention-based multiple instance learning on speech encoders trains clip-level stuttering labels into accurate frame-level segmentation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that attention-based multiple instance learning applied to fine-tuned wav2vec 2.0, WavLM, and Whisper encoders, trained solely on clip-level labels, produces a 23 percent improvement in frame-level F1 score and 2-9 percent improvement in clip-level F1 score, showing that clip-level data can be used directly for frame-level stuttering segmentation.
What carries the argument
Attention-based multiple instance learning that aggregates frame predictions or embeddings to match clip labels while identifying positive instances within each clip.
If this is right
- Frame-level stuttering segmentation becomes feasible on existing clip-labeled corpora.
- Duration measurements of individual dysfluencies can be obtained without new frame annotations.
- Clip-level F1 also rises, indicating the learned frame decisions improve overall classification.
- The same architecture can be applied to other speech tasks that have only bag-level labels.
Where Pith is reading between the lines
- Annotation effort for stuttering datasets could shift from frames to clips, lowering cost.
- The method may extend to other audio events where only coarse labels exist, such as certain medical sounds.
- Performance differences across the three encoders could indicate which pre-training best captures stuttering acoustics.
Load-bearing premise
Every clip labeled positive for stuttering actually contains at least one stuttering frame that the model can correctly identify.
What would settle it
On a held-out dataset that supplies both clip and frame labels, a model trained only on the clip labels shows no meaningful frame-level F1 gain over a clip-level baseline.
Figures

read the original abstract
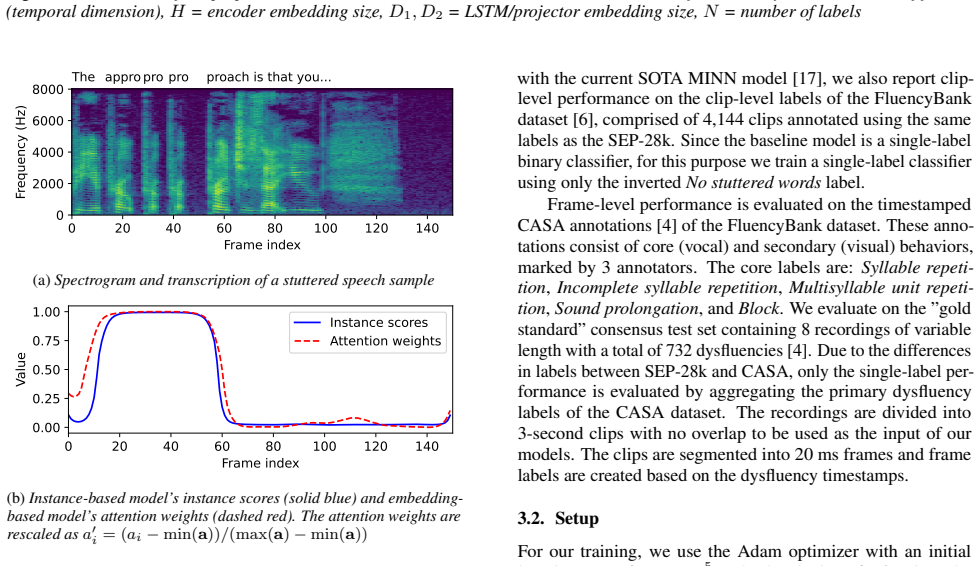
Stuttering detection and classification using deep learning methods has the potential to improve the process of stuttering severity assessment. Most stuttering classification datasets provide clip-level labels, making them unsuitable for fine-grained frame-level classification needed to determine the duration of individual stuttering dysfluencies. To overcome this challenge, we present a multiple instance neural network architecture based on fine-tuned wav2vec 2.0, WavLM and Whisper encoders. We apply instance- and embedding-based multiple instance learning approaches to train models on a clip-level dataset for both clip-level and frame-level stuttering classification tasks. Our results show a 23% improvement in frame-level F1 score and between 2% and 9% in clip-level F1 score, demonstrating the ability of our models to utilize clip-level data for frame-level segmentation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes an attention-based multiple instance learning (MIL) framework built on fine-tuned wav2vec 2.0, WavLM, and Whisper encoders. It trains exclusively on clip-level stuttering labels to produce both clip-level classification and frame-level segmentation outputs, claiming a 23% gain in frame-level F1 and 2–9% gains in clip-level F1 relative to unspecified baselines.
Significance. If the central empirical claims hold after verification, the work would demonstrate a practical route for converting abundant clip-level stuttering corpora into frame-level segmenters, which is relevant for clinical severity assessment. The dual use of instance-level and embedding-level MIL together with multiple self-supervised encoders is a reasonable technical choice; credit is given for the explicit attempt to move beyond bag-level supervision.
major comments (2)
- [Abstract and Results] Abstract and Results section: the headline 23% frame-level F1 improvement is stated without any description of the baseline architecture(s), the dataset (size, class balance, stuttering subtypes, train/test split), cross-validation procedure, or statistical significance testing. These omissions make it impossible to determine whether the reported gain supports the claim that clip-level supervision is successfully converted into reliable frame-level segmentation.
- [Methods and Results] Methods (MIL formulation) and Results: the central claim rests on the assumption that the attention weights in the MIL heads correctly localize actual stuttering frames rather than proxy acoustic cues. No ablation isolating the contribution of the attention mechanism (e.g., attention-based MIL versus a simple clip-level classifier followed by post-hoc saliency) is reported, nor is any verification against frame-level ground truth provided. Without such evidence the frame-level F1 metric cannot be taken as a direct measure of segmentation quality.
minor comments (2)
- [Methods] The distinction between the instance-level and embedding-level MIL heads is described in overlapping terms; a short clarifying paragraph or diagram would improve readability.
- [Figures] Figure captions should explicitly state whether any attention-weight visualizations are accompanied by human-annotated frame labels for qualitative validation.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point by point below and will revise the manuscript to improve clarity and add supporting analyses where appropriate.
read point-by-point responses
-
Referee: [Abstract and Results] Abstract and Results section: the headline 23% frame-level F1 improvement is stated without any description of the baseline architecture(s), the dataset (size, class balance, stuttering subtypes, train/test split), cross-validation procedure, or statistical significance testing. These omissions make it impossible to determine whether the reported gain supports the claim that clip-level supervision is successfully converted into reliable frame-level segmentation.
Authors: We agree that key experimental details should be more prominent in the abstract and results. While the Methods and Experiments sections already specify the dataset (including size, splits, and stuttering subtypes), the three pre-trained encoders, the MIL variants, and the train/test protocol, we will revise the abstract to include a concise description of the baselines (standard clip-level classifiers without MIL) and the evaluation procedure. We will also add statistical significance testing (bootstrap confidence intervals and paired tests) to the results tables in the revision. revision: yes
-
Referee: [Methods and Results] Methods (MIL formulation) and Results: the central claim rests on the assumption that the attention weights in the MIL heads correctly localize actual stuttering frames rather than proxy acoustic cues. No ablation isolating the contribution of the attention mechanism (e.g., attention-based MIL versus a simple clip-level classifier followed by post-hoc saliency) is reported, nor is any verification against frame-level ground truth provided. Without such evidence the frame-level F1 metric cannot be taken as a direct measure of segmentation quality.
Authors: The frame-level F1 scores are computed on a subset of the test data that carries frame-level annotations (used only for evaluation, not training). To directly address the concern about whether attention weights reflect true stuttering localization, we will add an ablation that compares the full attention-based MIL against (i) a clip-level classifier followed by post-hoc saliency and (ii) a non-attention MIL variant. This will be included in the revised results section. revision: partial
Circularity Check
No circularity; empirical MIL application is self-contained
full rationale
The paper applies standard instance- and embedding-level MIL to fine-tuned audio encoders using only clip-level labels, reporting empirical F1 metrics. No equations, derivations, or predictions are presented that reduce to fitted inputs by construction. The MIL assumption is an explicit modeling choice, not a self-referential definition or self-citation chain. Results are obtained from standard training and evaluation on held-out data, with no load-bearing self-citations or renamed known results.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Introduction Stuttering is a speech fluency disorder characterized by involun- tary dysfluencies such as blocks, repetitions and prolongations that disrupt the natural flow of speech. The research of stuttering detection and classification using machine learning methods has gained popularity in recent years due to its potential to automate the process of ...
-
[2]
A multiple-instance neural network (MINN) model architec- ture achieving SOTA clip-level multi-label stuttering classifi- cation results on the SEP-28k-E dataset,
-
[3]
Achieving SOTA frame-level stuttering classification perfor- mance on the CASA annotations of the FluencyBank dataset
-
[4]
Method 2.1. Multiple instance learning Frame-level stuttering classification can be learned from clip- level data by formulating the clip-level stuttering classification task as a weakly-supervised MIL task. Under this formulation, each audio clip is divided into a number of frames. In the context of MIL, a frame represents an instance, and a clip is a co...
Pith/arXiv arXiv 2026
-
[5]
Data We train our models on the standardized SEP-28k-E split of the clip-level SEP-28k dataset [32]
Experiments 3.1. Data We train our models on the standardized SEP-28k-E split of the clip-level SEP-28k dataset [32]. The dataset contains 28,000 3- second clips labeled with the following dysfluency labels:Block, Prolongation,Sound repetition,Word repetition,Interjection, andNo stuttered words. Each sample was labeled by 3 annotators. We consider a label...
-
[6]
Our results fall slightly short of the baselines for prolongations and the general dysfluent label
Discussion Our WavLM- and Whisper-based models achieve SOTA results in the clip-level detection of blocks, sound repetitions, word repetitions and interjections. Our results fall slightly short of the baselines for prolongations and the general dysfluent label. The improvement in results might depend most on the archi- tecture of the foundational encoders...
-
[7]
Conclusion Our work investigates the application of the weakly-supervised multiple instance learning paradigm to the task of stuttering classification, being the first to explore MIL for multi-label stuttering classification, as well as the application of attention- pooling embedding-based MINNs to this task. We discover that instance-based and embedding-...
-
[8]
Computing resources were provided by the University of Zagreb Computing Centre (SRCE) through the Advanced Computing service
Acknowledgements This research was supported by the European Union- NextGenerationEU project NPOO 581-16956 VISTAHealth. Computing resources were provided by the University of Zagreb Computing Centre (SRCE) through the Advanced Computing service
-
[9]
Generative AI Use Disclosure Generative AI tools (Claude Sonnet 4.6) were used to assist with grammar and spelling, with all changes reviewed and approved by the authors
-
[10]
Computational Intelligence-Based Stuttering Detection: A Systematic Review,
R. Alnashwan, N. Alhakbani, A. Al-Nafjan, A. Almudhi, and W. Al-Nuwaiser, “Computational Intelligence-Based Stuttering Detection: A Systematic Review,”Diagnostics, vol. 13, no. 23, p. 3537, Nov. 2023
2023
-
[11]
Machine learning for stuttering identification: Review, challenges and future directions,
S. A. Sheikh, M. Sahidullah, F. Hirsch, and S. Ouni, “Machine learning for stuttering identification: Review, challenges and future directions,”Neurocomputing, vol. 514, pp. 385–402, Dec. 2022
2022
-
[12]
Systematic Review of Machine Learning Approaches for Detecting Developmental Stuttering,
L. Barrett, J. Hu, and P. Howell, “Systematic Review of Machine Learning Approaches for Detecting Developmental Stuttering,” IEEE/ACM Transactions on Audio, Speech, and Language Pro- cessing, vol. 30, pp. 1160–1172, 2022
2022
-
[13]
Clinical Annotations for Automatic Stuttering Severity Assessment,
A. Valente, R. Marew, H. Toyin, H. Al-Ali, A. Bohnen, I. Becerra, E. Soares, G. Leal, and H. Aldarmaki, “Clinical Annotations for Automatic Stuttering Severity Assessment,” inInterspeech 2025. ISCA, Aug. 2025, pp. 4318–4322
2025
-
[14]
Boli: A dataset for understanding stuttering experience and analyzing stuttered speech,
A. Batra, M. Narang, N. K. Sharma, and P. K. Das, “Boli: A dataset for understanding stuttering experience and analyzing stuttered speech,” inIEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Apr. 2025, pp. 1–4
2025
-
[15]
SEP- 28k: A Dataset for Stuttering Event Detection from Podcasts with People Who Stutter,
C. Lea, V . Mitra, A. Joshi, S. Kajarekar, and J. P. Bigham, “SEP- 28k: A Dataset for Stuttering Event Detection from Podcasts with People Who Stutter,” inIEEE International Conference on Acous- tics, Speech and Signal Processing (ICASSP), Jun. 2021, pp. 6798– 6802
2021
-
[16]
KSoF: The Kassel State of Fluency Dataset – A Therapy Centered Dataset of Stuttering,
S. Bayerl, A. Wolff von Gudenberg, F. H ¨onig, E. Noeth, and K. Riedhammer, “KSoF: The Kassel State of Fluency Dataset – A Therapy Centered Dataset of Stuttering,” inProceedings of the Thirteenth Language Resources and Evaluation Conference. European Language Resources Association, Jun. 2022, pp. 1780– 1787
2022
-
[17]
AS-70: A Mandarin stuttered speech dataset for automatic speech recognition and stuttering event detection,
R. Gong, H. Xue, L. Wang, X. Xu, Q. Li, L. Xie, H. Bu, S. Wu, J. Zhou, Y . Qin, B. Zhang, J. Du, J. Bin, and M. Li, “AS-70: A Mandarin stuttered speech dataset for automatic speech recognition and stuttering event detection,” inInterspeech 2024. ISCA, Sep. 2024, pp. 5098–5102
2024
-
[18]
A Stuttering Severity Instrument for Children and Adults,
G. D. Riley, “A Stuttering Severity Instrument for Children and Adults,”Journal of Speech and Hearing Disorders, vol. 37, no. 3, pp. 314–322, Aug. 1972
1972
-
[19]
The Speech Efficiency Score (SES): A time-domain measure of speech fluency,
O. Amir, Y . Shapira, L. Mick, and J. S. Yaruss, “The Speech Efficiency Score (SES): A time-domain measure of speech fluency,” Journal of Fluency Disorders, vol. 58, pp. 61–69, Dec. 2018
2018
-
[20]
A Stutter Seldom Comes Alone – Cross- Corpus Stuttering Detection as a Multi-label Problem,
S. P. Bayerl, D. Wagner, I. Baumann, F. H¨onig, T. Bocklet, E. N¨oth, and K. Riedhammer, “A Stutter Seldom Comes Alone – Cross- Corpus Stuttering Detection as a Multi-label Problem,” inInter- speech 2023, 2023, pp. 1538–1542
2023
-
[21]
Detect- ing Dysfluencies in Stuttering Therapy Using wav2vec 2.0,
S. P. Bayerl, D. Wagner, E. Noeth, and K. Riedhammer, “Detect- ing Dysfluencies in Stuttering Therapy Using wav2vec 2.0,” in Interspeech 2022. ISCA, Sep. 2022
2022
-
[22]
Stuttering Detection Based on Self-Attention Weights of Temporal Acoustic Vector Sequence,
G. Miyahara, T. Kato, and A. Tamura, “Stuttering Detection Based on Self-Attention Weights of Temporal Acoustic Vector Sequence,” inInterspeech 2025. ISCA, Aug. 2025, pp. 5298–5302
2025
-
[23]
Comparative Analysis of Classi- fiers using Wav2Vec2.0 Layer Embeddings for Imbalanced Stutter- ing Datasets,
M. Sen, A. Batra, and P. K. Das, “Comparative Analysis of Classi- fiers using Wav2Vec2.0 Layer Embeddings for Imbalanced Stutter- ing Datasets,” inInternational Conference on Electronics, Commu- nication and Signal Processing (ICECSP), Aug. 2024, pp. 1–6
2024
-
[24]
Whister: Using Whisper’s repre- sentations for Stuttering detection,
V . Changawala and F. Rudzicz, “Whister: Using Whisper’s repre- sentations for Stuttering detection,” inInterspeech 2024. ISCA, Sep. 2024, pp. 897–901
2024
-
[25]
Exploring Whisper Embeddings for Stutter Detection: A Layer-Wise Study,
A. Batra, B. Kar, and P. K. Das, “Exploring Whisper Embeddings for Stutter Detection: A Layer-Wise Study,”33rd European Signal Processing Conference (EUSIPCO 2025), 2025
2025
-
[26]
Self- Supervised Speech Models For Word-Level Stuttered Speech De- tection,
Y .-J. Shih, Z. Gkalitsiou, A. G. Dimakis, and D. Harwath, “Self- Supervised Speech Models For Word-Level Stuttered Speech De- tection,” inIEEE Spoken Language Technology Workshop, SLT. IEEE, 2024, pp. 937–944
2024
-
[27]
Dysfluency Classification in Stut- tered Speech Using Deep Learning for Real-Time Applications,
M. Jouaiti and K. Dautenhahn, “Dysfluency Classification in Stut- tered Speech Using Deep Learning for Real-Time Applications,” inIEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), May 2022, pp. 6482–6486
2022
-
[28]
Enhancing Stutter Detec- tion using Long-Term Average Spectrum Values,
V . Narasinga, P. Kommagouni, S. Vanga, K. S. S. Motepalli, S. Akarsh C, P. Barche, and A. Vuppala, “Enhancing Stutter Detec- tion using Long-Term Average Spectrum Values,” inIEEE Inter- national Conference on Acoustics, Speech and Signal Processing (ICASSP), Apr. 2025, pp. 1–5
2025
-
[29]
Dysfluency Classification in Speech Using a Biological Sound Perception Model,
M. Jouaiti and K. Dautenhahn, “Dysfluency Classification in Speech Using a Biological Sound Perception Model,” in9th Inter- national Conference on Soft Computing & Machine Intelligence (ISCMI), Nov. 2022, pp. 173–177
2022
-
[30]
YOLO-Stutter: End-to-end Region-Wise Speech Dysfluency Detection,
X. Zhou, A. Kashyap, S. Li, A. Sharma, B. Morin, D. Baquirin, J. V onk, Z. Ezzes, Z. Miller, M. Tempini, J. Lian, and G. Anu- manchipalli, “YOLO-Stutter: End-to-end Region-Wise Speech Dysfluency Detection,” inInterspeech 2024. ISCA, Sep. 2024, pp. 937–941
2024
-
[31]
StutterCut: Uncertainty-Guided Normalised Cut for Dysfluency Segmentation,
S. Ghosh, M. Jouaiti, J.-O. Perschewski, and S. Stober, “StutterCut: Uncertainty-Guided Normalised Cut for Dysfluency Segmentation,” inInterspeech 2025, 2025, pp. 808–812
2025
-
[32]
Frame-Level Stutter Detection,
J. Harvill, M. Hasegawa-Johnson, and C. D. Yoo, “Frame-Level Stutter Detection,” inInterspeech 2022. ISCA, Sep. 2022, pp. 2843–2847
2022
-
[33]
Multiple instance learning: A survey of problem characteristics and applications,
M.-A. Carbonneau, V . Cheplygina, E. Granger, and G. Gagnon, “Multiple instance learning: A survey of problem characteristics and applications,”Pattern Recognition, vol. 77, pp. 329–353, May 2018
2018
-
[34]
Revisiting multiple instance neural networks,
X. Wang, Y . Yan, P. Tang, X. Bai, and W. Liu, “Revisiting multiple instance neural networks,”Pattern Recognition, vol. 74, pp. 15–24, Feb. 2018
2018
-
[35]
Attention-based Deep Mul- tiple Instance Learning,
M. Ilse, J. Tomczak, and M. Welling, “Attention-based Deep Mul- tiple Instance Learning,” inProceedings of the 35th International Conference on Machine Learning. PMLR, Jul. 2018, pp. 2127– 2136
2018
-
[36]
Psychophysio- logical Arousal in Young Children Who Stutter: An Interpretable AI Approach,
H. Sharma, Y . Xiao, V . Tumanova, and A. Salekin, “Psychophysio- logical Arousal in Young Children Who Stutter: An Interpretable AI Approach,”Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies, vol. 6, no. 3, pp. 137:1– 137:32, Sep. 2022
2022
-
[37]
Wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Represen- tations,
A. Baevski, Y . Zhou, A. Mohamed, and M. Auli, “Wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Represen- tations,” inAdvances in Neural Information Processing Systems, vol. 33. Curran Associates, Inc., 2020, pp. 12 449–12 460
2020
-
[38]
Robust Speech Recognition via Large-Scale Weak Supervision,
A. Radford, J. W. Kim, T. Xu, G. Brockman, C. Mcleavey, and I. Sutskever, “Robust Speech Recognition via Large-Scale Weak Supervision,” inProceedings of the 40th International Conference on Machine Learning. PMLR, Jul. 2023, pp. 28 492–28 518
2023
-
[39]
WavLM: Large-Scale Self- Supervised Pre-Training for Full Stack Speech Processing,
S. Chen, C. Wang, Z. Chen, Y . Wu, S. Liu, Z. Chen, J. Li, N. Kanda, T. Yoshioka, X. Xiao, J. Wu, L. Zhou, S. Ren, Y . Qian, Y . Qian, J. Wu, M. Zeng, X. Yu, and F. Wei, “WavLM: Large-Scale Self- Supervised Pre-Training for Full Stack Speech Processing,”IEEE Journal of Selected Topics in Signal Processing, vol. 16, no. 6, pp. 1505–1518, Oct. 2022
2022
-
[40]
Interface Design for Self-Supervised Speech Models,
Y .-J. Shih and D. Harwath, “Interface Design for Self-Supervised Speech Models,” inInterspeech 2024. ISCA, Sep. 2024, pp. 2504–2508
2024
-
[41]
The Influence of Dataset Partitioning on Dysfluency Detection Systems,
S. P. Bayerl, D. Wagner, E. N¨oth, T. Bocklet, and K. Riedhammer, “The Influence of Dataset Partitioning on Dysfluency Detection Systems,” inText, Speech, and Dialogue. Springer International Publishing, 2022, pp. 423–436
2022
-
[42]
Multilingual Stutter Event Detection for English, German, and Mandarin Speech,
F. Haas and S. P. Bayerl, “Multilingual Stutter Event Detection for English, German, and Mandarin Speech,” inText, Speech, and Dialogue. Springer Nature Switzerland, 2026, vol. 16029, pp. 194–206
2026
-
[43]
WhisperX: Time- Accurate Speech Transcription of Long-Form Audio,
M. Bain, J. Huh, T. Han, and A. Zisserman, “WhisperX: Time- Accurate Speech Transcription of Long-Form Audio,” inInter- speech 2023. ISCA, Aug. 2023, pp. 4489–4493
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.