Governed Shared Memory for Multi-Agent LLM Systems
Pith reviewed 2026-06-25 23:54 UTC · model grok-4.3
The pith
Multi-agent LLM systems require explicit governed shared memory abstractions to address four key failure modes that long-context retrieval cannot handle.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
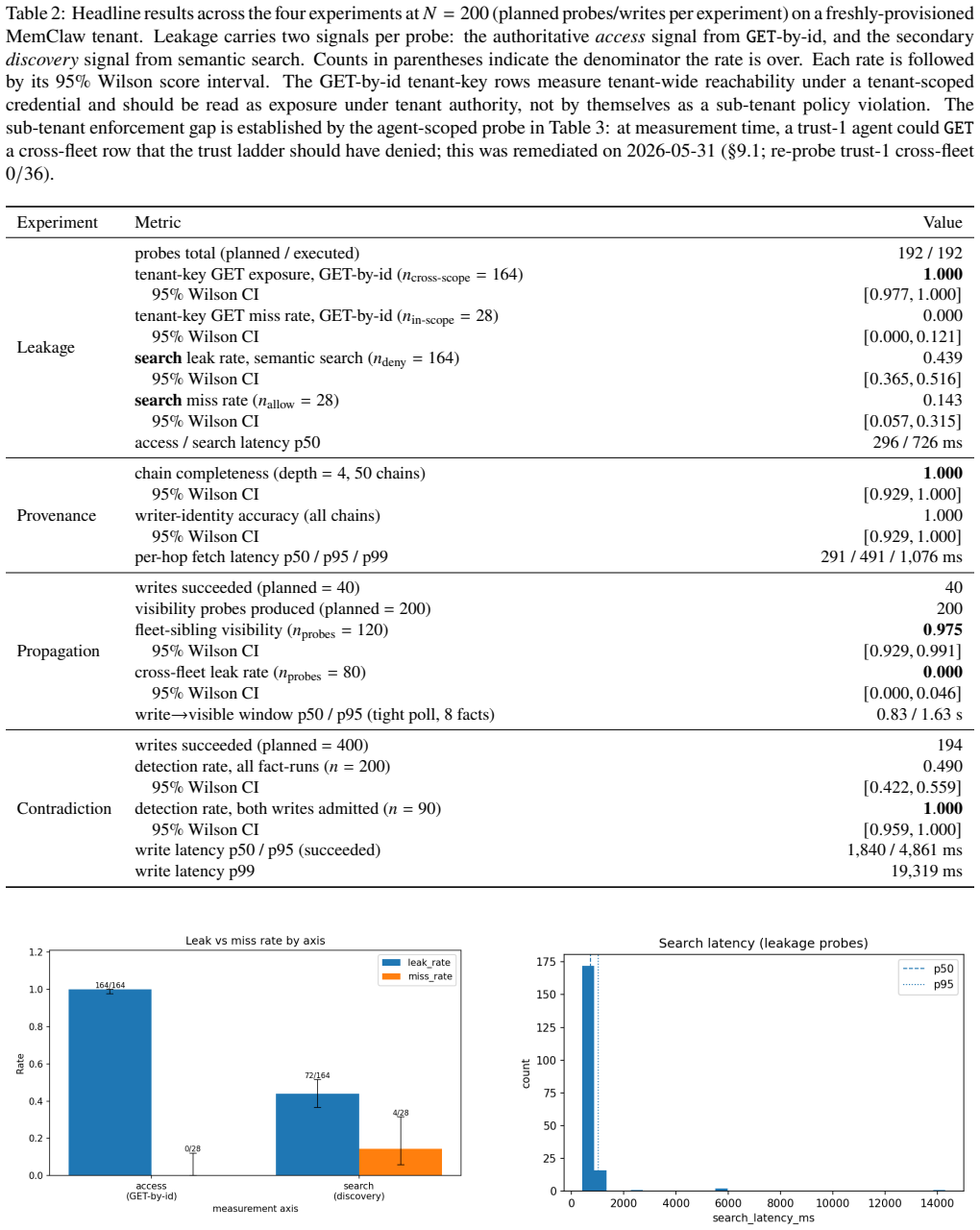
Long-context retrieval alone is insufficient for production multi-agent memory. Governed shared memory demands explicit systems-level abstractions, and live evaluation is vital to expose enforcement and pipeline-ordering failures missed by design-only treatments. The primitives enable 100% provenance reconstruction of derivation chains and zero cross-fleet leakage while optimizing latencies.
What carries the argument
The fleet-memory problem formalized through its four failure modes, addressed by the four primitives of scoped retrieval, temporal supersession, provenance tracking, and policy-governed memory propagation, as implemented in MemClaw and evaluated in ArgusFleet.
If this is right
- Provenance tracking successfully reconstructs 100% of depth-four derivation chains with correct writer identity at sub-second per-hop latency.
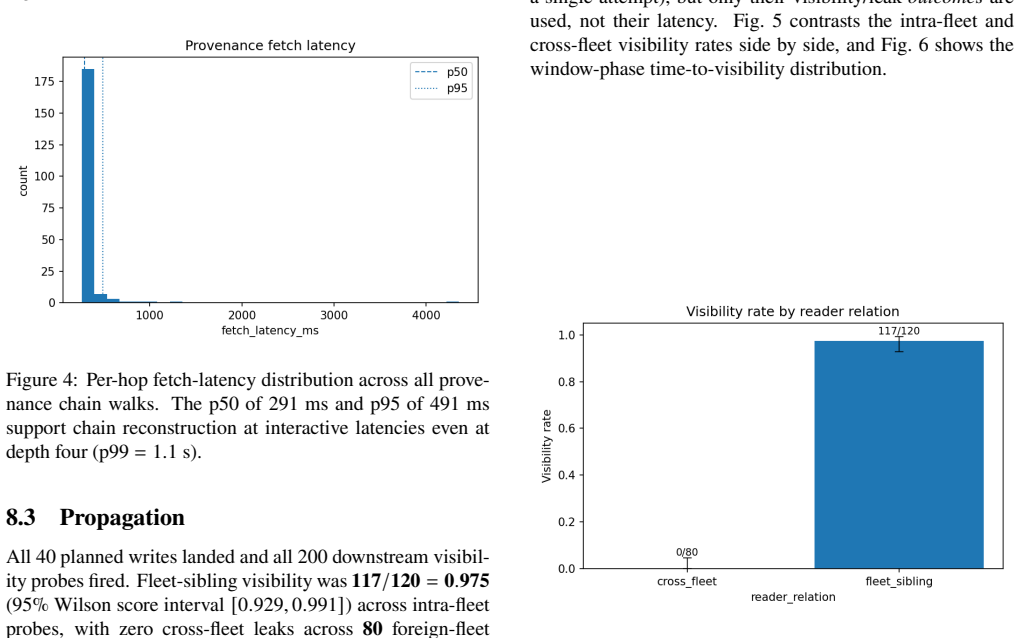
- Policy-governed propagation achieves high intra-fleet visibility with zero cross-fleet leakage.
- Strong write mode reduces write-to-visible latency to a single search round-trip.
- Live testing uncovers asymmetric scope enforcement where sub-tenant scope was bypassed on direct GET-by-id requests.
- Pipeline ordering conflicts can cause premature rejection of contradictory writes by synchronous gates before asynchronous detectors evaluate them.
Where Pith is reading between the lines
- The identified failure modes and primitives may generalize to other distributed knowledge systems beyond LLM agents.
- Addressing pipeline ordering requires careful design of synchronous and asynchronous components in memory services.
- Production services should incorporate live evaluation harnesses like ArgusFleet to validate governance in realistic conditions.
Load-bearing premise
That the four failure modes represent the primary and sufficient set of issues that must be addressed for robust fleet memory and that the ArgusFleet harness provides representative coverage of production conditions.
What would settle it
Demonstration of a multi-agent LLM fleet using only long-context retrieval that maintains isolation, freshness, consistency, and provenance without the proposed primitives would falsify the necessity of explicit systems-level abstractions.
Figures





read the original abstract
Multi-agent LLM environments require robust mechanisms for shared knowledge management. This paper formalizes the fleet-memory problem and identifies four foundational failure modes: unauthorized leakage, stale propagation, contradiction persistence, and provenance collapse. To address these, we define explicit systems-level primitives: scoped retrieval, temporal supersession, provenance tracking, and policy-governed memory propagation. These primitives are implemented in MemClaw, a production multi-tenant memory service, and evaluated via ArgusFleet, a reproducible harness testing four governance dimensions. Rather than a baseline comparison, this study measures a live production service, emphasizing real-world architectural insights and negative results. Key Evaluation Results Provenance: Successfully reconstructed 100% of depth-four derivation chains with correct writer identity at sub-second per-hop latency. Propagation: Demonstrated high intra-fleet visibility with zero cross-fleet leakage. Under strong write mode, write-to-visible latency was optimized to a single search round-trip. Production Architectural Issues Discovered Asymmetric Scope Enforcement: Tenant isolation held, but sub-tenant scope was initially bypassed on direct GET-by-id requests for agent-scoped credentials (disclosed and remediated during the study). Pipeline Ordering Conflict: While contradiction supersession works for admitted writes, a synchronous near-duplicate gate can prematurely reject contradictory writes before the asynchronous contradiction detector can evaluate them. Conclusion: Long-context retrieval alone is insufficient for production multi-agent memory. Governed shared memory demands explicit systems-level abstractions, and live evaluation is vital to expose enforcement and pipeline-ordering failures missed by design-only treatments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper formalizes the fleet-memory problem for multi-agent LLM systems and identifies four foundational failure modes: unauthorized leakage, stale propagation, contradiction persistence, and provenance collapse. It defines four systems-level primitives (scoped retrieval, temporal supersession, provenance tracking, and policy-governed memory propagation) to address them, implements the primitives in the MemClaw production multi-tenant memory service, and evaluates governance properties using the ArgusFleet reproducible harness. The evaluation reports 100% reconstruction of depth-four provenance chains with correct writer identity at sub-second latency, zero cross-fleet leakage, high intra-fleet visibility, and two remediated architectural issues (asymmetric scope enforcement on direct GET-by-id and pipeline ordering conflict between synchronous near-duplicate gates and asynchronous contradiction detection). The central conclusion is that long-context retrieval alone is insufficient and that explicit abstractions plus live evaluation are required to expose enforcement and ordering failures.
Significance. If the results hold, the work offers concrete, production-derived insights into multi-agent memory governance by measuring a live service and disclosing negative findings rather than relying solely on design arguments or simulations. The reproducible ArgusFleet harness and emphasis on pipeline-ordering failures constitute a strength that could guide practical system design in the field.
major comments (1)
- [Introduction / fleet-memory problem formalization] Introduction / fleet-memory problem formalization: The four failure modes are presented as foundational and primary without a completeness argument, threat model, or empirical survey establishing that they are the main issues or that other potential problems (e.g., consistency under concurrent agents or cross-model semantic drift) are secondary. The ArgusFleet evaluation tests the implemented primitives on governance dimensions but does not validate whether unaddressed modes would still produce production failures; this assumption is load-bearing for the claim that the four primitives are necessary.
minor comments (1)
- [Abstract / Evaluation] Abstract and evaluation section: The reported metrics (100% provenance reconstruction, zero leakage) are given without details on test scale, number of agents/queries, or variance, which would strengthen the reproducibility claim even though the harness itself is described as reproducible.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the fleet-memory problem formalization. We address the major comment below.
read point-by-point responses
-
Referee: The four failure modes are presented as foundational and primary without a completeness argument, threat model, or empirical survey establishing that they are the main issues or that other potential problems (e.g., consistency under concurrent agents or cross-model semantic drift) are secondary. The ArgusFleet evaluation tests the implemented primitives on governance dimensions but does not validate whether unaddressed modes would still produce production failures; this assumption is load-bearing for the claim that the four primitives are necessary.
Authors: The four failure modes were identified from incidents observed during operation of the MemClaw production service rather than from a formal survey or threat model. The manuscript presents them as foundational in the context of the fleet-memory problem we formalize, but does not assert completeness or that other issues (such as concurrent consistency or cross-model semantic drift) are secondary. The evaluation measures the effectiveness of the four primitives against the modes they target in a live multi-tenant setting; it does not claim to have tested or ruled out unaddressed modes. We will revise the introduction to state explicitly that the modes are derived from production observations, are not asserted to be exhaustive, and that the paper's central claim is the insufficiency of long-context retrieval alone plus the value of live evaluation for exposing enforcement failures. This clarification addresses the scope concern while preserving the reported results. revision: yes
Circularity Check
No circularity: paper is implementation and measurement driven with no derivations or self-referential reductions.
full rationale
The paper formalizes the fleet-memory problem by naming four failure modes and defining four primitives to address them, then implements the primitives in MemClaw and measures them via ArgusFleet. No equations, fitted parameters, predictions, or uniqueness theorems appear in the provided text. The identification of failure modes is presented as a modeling premise rather than a derived result, and the evaluation consists of direct runtime measurements (e.g., 100% provenance reconstruction, zero leakage) rather than any quantity that reduces to its own inputs by construction. No self-citations are invoked as load-bearing support for the central claims. This is a standard systems paper whose central claims rest on implementation and live testing, not on circular logic.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Multi-agent LLM environments require robust mechanisms for shared knowledge management.
invented entities (3)
-
fleet-memory problem
no independent evidence
-
MemClaw
no independent evidence
-
ArgusFleet
no independent evidence
Forward citations
Cited by 1 Pith paper
-
Always-OnAgents:A Survey of Persistent Memory, State, and Governance in LLMAgents
Survey mapping persistent state in LLM agents along six axes and proposing the AOEP-v0 protocol to evaluate governance and recovery obligations.
Reference graph
Works this paper leans on
-
[1]
Mem0: Buildingproduction- readyAIagentswithscalablelong-termmemory,2025
Prateek Chhikara, Dev Khant, Saket Aryan, Taranjeet Singh,andDeshrajYadav. Mem0: Buildingproduction- readyAIagentswithscalablelong-termmemory,2025. URLhttps://arxiv.org/abs/2504.19413
Pith/arXiv arXiv 2025
-
[2]
Corbett, Jeffrey Dean, Michael Epstein, An- drew Fikes, Christopher Frost, J
James C. Corbett, Jeffrey Dean, Michael Epstein, An- drew Fikes, Christopher Frost, J. J. Furman, Sanjay Ghemawat, Andrey Gubarev, Christopher Heiser, Pe- ter Hochschild, Wilson Hsieh, Sebastian Kanthak, Eu- gene Kogan, Hongyi Li, Alexander Lloyd, Sergey Mel- nik, David Mwaura, David Nagle, Sean Quinlan, Ra- jesh Rao, Lindsay Rolig, Yasushi Saito, Michal ...
-
[3]
ISSN 0734-2071. doi: 10.1145/2491245. URL https://doi.org/10.1145/2491245
-
[4]
Se- curing AI agents with information-flow control, 2025
Manuel Costa, Boris Köpf, Aashish Kolluri, Andrew Paverd,MarkRussinovich,AhmedSalem,ShrutiTople, Lukas Wutschitz, and Santiago Zanella-Béguelin. Se- curing AI agents with information-flow control, 2025. URLhttps://arxiv.org/abs/2505.23643
Pith/arXiv arXiv 2025
-
[5]
Defeating prompt injections by design
EdoardoDebenedetti,IliaShumailov,TianqiFan,Jamie Hayes, Nicholas Carlini, Daniel Fabian, Christoph Kern, Chongyang Shi, Andreas Terzis, and Flo- rian Tramèr. Defeating prompt injections by design. arXiv:2503.18813, 2025
Pith/arXiv arXiv 2025
-
[6]
Giuseppe DeCandia, Deniz Hastorun, Madan Jampani, Gunavardhan Kakulapati, Avinash Lakshman, Alex Pilchin,SwaminathanSivasubramanian,PeterVosshall, and Werner Vogels. Dynamo: Amazon’s highly avail- able key-value store.ACM SIGOPS Operating Systems 14 Review, 41(6):205–220, 2007. doi: 10.1145/1294261. 1294281
-
[7]
Hu, David Ferraiolo, Rick Kuhn, Adam Schnitzer, Kenneth Sandlin, Robert Miller, and Karen Scarfone
Vincent C. Hu, David Ferraiolo, Rick Kuhn, Adam Schnitzer, Kenneth Sandlin, Robert Miller, and Karen Scarfone. Guide to attribute based access control (ABAC) definition and considerations. NIST Special Publication800-162,NationalInstituteofStandardsand Technology, 2014
2014
-
[8]
Time, Clocks, and the Ordering of Events in a Distributed System,
LeslieLamport.Time,clocks,andtheorderingofevents in a distributed system.Communications of the ACM, 21(7):558–565, 1978. doi: 10.1145/359545.359563
-
[9]
LangMem: Long-term memory for LLM agents.https://langchain-ai.github.io/ langmem/, 2024
LangChain. LangMem: Long-term memory for LLM agents.https://langchain-ai.github.io/ langmem/, 2024
2024
-
[10]
Retrieval-augmented generation for knowledge-intensive NLP tasks
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler,MikeLewis,WentauYih,TimRocktäschel,Se- bastian Riedel, and Douwe Kiela. Retrieval-augmented generation for knowledge-intensive NLP tasks. In Advances in Neural Information Processing Systems (NeurIPS), 2020
2020
-
[11]
A comprehensive sur- vey on long context language modeling, 2025
Jiaheng Liu, Dawei Zhu, Zhiqi Bai, Yancheng He, Huanxuan Liao, Haoran Que, Zekun Wang, Chenchen Zhang,GeZhang,JiebinZhang,YuanxingZhang,Zhuo Chen, Hangyu Guo, Shilong Li, Ziqiang Liu, Yong Shan, Yifan Song, Jiayi Tian, Wenhao Wu, Zhejian Zhou, Ruijie Zhu, Junlan Feng, Yang Gao, Shizhu He, Zhoujun Li, Tianyu Liu, Fanyu Meng, Wenbo Su, Yingshui Tan, Zili Wa...
arXiv 2025
-
[12]
PeerRank: Autonomous LLM evaluation through web-grounded, bias-controlled peer review, 2026
Yanki Margalit, Erni Avram, Ran Taig, Oded Margalit, and Nurit Cohen-Inger. PeerRank: Autonomous LLM evaluation through web-grounded, bias-controlled peer review, 2026. URLhttps://arxiv.org/abs/2602. 02589
2026
-
[13]
CanLLMskeepasecret? testingprivacyimplica- tionsoflanguagemodelsviacontextualintegritytheory,
Niloofar Mireshghallah, Hyunwoo Kim, Xuhui Zhou, Yulia Tsvetkov, Maarten Sap, Reza Shokri, and Yejin Choi. CanLLMskeepasecret? testingprivacyimplica- tionsoflanguagemodelsviacontextualintegritytheory,
-
[14]
URLhttps://arxiv.org/abs/2310.17884
-
[15]
Patil, Ion Stoica, and Joseph E
CharlesPacker,SarahWooders,KevinLin,VivianFang, Shishir G. Patil, Ion Stoica, and Joseph E. Gonza- lez. MemGPT: Towards LLMs as operating systems. arXiv:2310.08560, 2023
Pith/arXiv arXiv 2023
-
[16]
Zep: A tem- poral knowledge graph architecture for agent memory
Preston Rasmussen, Pavlo Paliychuk, Travis Beau- vais, Jack Ryan, and Daniel Chalef. Zep: A tem- poral knowledge graph architecture for agent memory. arXiv:2501.13956, 2025
Pith/arXiv arXiv 2025
-
[17]
Collaborativememory: Multi- user memory sharing in LLM agents with dynamic ac- cess control
AlirezaRezazadeh,ZichaoLi,AngeLou,YuyingZhao, WeiWei,andYujiaBao. Collaborativememory: Multi- user memory sharing in LLM agents with dynamic ac- cess control. arXiv:2505.18279, 2025
arXiv 2025
-
[18]
RaviS.Sandhu,EdwardJ.Coyne,HalL.Feinstein,and Charles E. Youman. Role-based access control models. IEEE Computer, 29(2):38–47, 1996. doi: 10.1109/2. 485845
work page doi:10.1109/2 1996
-
[19]
Conflict-free replicated data types
Marc Shapiro, Nuno Preguiça, Carlos Baquero, and Marek Zawirski. Conflict-free replicated data types. In Symposium on Self-Stabilizing Systems (SSS), volume 6976ofLectureNotesinComputerScience,pages386– 400.Springer,2011.doi: 10.1007/978-3-642-24550-3_ 29
-
[20]
Douglas B. Terry, Marvin M. Theimer, Karin Petersen, Alan J. Demers, Mike J. Spreitzer, and Carl H. Hauser. ManagingupdateconflictsinBayou,aweaklyconnected replicatedstoragesystem. InACMSymposiumonOper- atingSystemsPrinciples(SOSP),pages172–182,1995. doi: 10.1145/224056.224070
-
[21]
Unveiling privacy risks in LLM agent memory, 2025
Bo Wang, Weiyi He, Shenglai Zeng, Zhen Xiang, Yue Xing, Jiliang Tang, and Pengfei He. Unveiling privacy risks in LLM agent memory, 2025. URLhttps:// arxiv.org/abs/2502.13172
arXiv 2025
-
[22]
MIRIX: Multi-agent memory systemforLLM-basedagents
Yu Wang and Xi Chen. MIRIX: Multi-agent memory systemforLLM-basedagents. arXiv:2507.07957,2025
Pith/arXiv arXiv 2025
-
[23]
Auto- Gen: Enabling next-gen LLM applications via multi- agentconversation,2023
Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Beibin Li, Erkang Zhu, Li Jiang, Xiaoyun Zhang, Shaokun Zhang, Jiale Liu, Ahmed Hassan Awadallah, Ryen W White, Doug Burger, and Chi Wang. Auto- Gen: Enabling next-gen LLM applications via multi- agentconversation,2023. URLhttps://arxiv.org/ abs/2308.08155
Pith/arXiv arXiv 2023
-
[24]
A-MEM: Agentic memory for LLM agents
Wujiang Xu, Zujie Liang, Kai Mei, Hang Gao, Juntao Tan, and Yongfeng Zhang. A-MEM: Agentic memory for LLM agents. arXiv:2502.12110, 2025
Pith/arXiv arXiv 2025
-
[25]
URL https://arxiv.org/abs/2506.07398
Guibin Zhang, Muxin Fu, Guancheng Wan, Miao Yu, KunWang,andShuichengYan.G-Memory: Tracinghi- erarchicalmemoryformulti-agentsystems,2025. URL https://arxiv.org/abs/2506.07398. 15
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.