Always-OnAgents:A Survey of Persistent Memory, State, and Governance in LLMAgents
Pith reviewed 2026-06-30 03:41 UTC · model grok-4.3
The pith
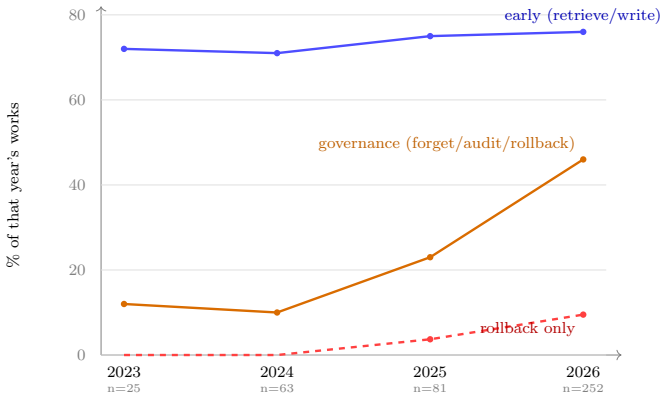
Literature on always-on LLM agents focuses more on accumulating and retrieving state than on governing, recovering, or relinquishing it.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
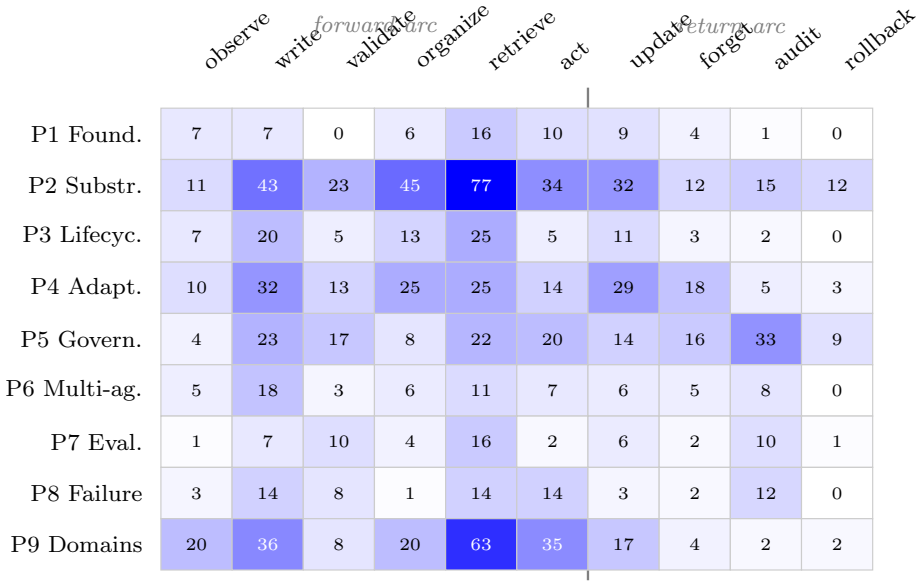
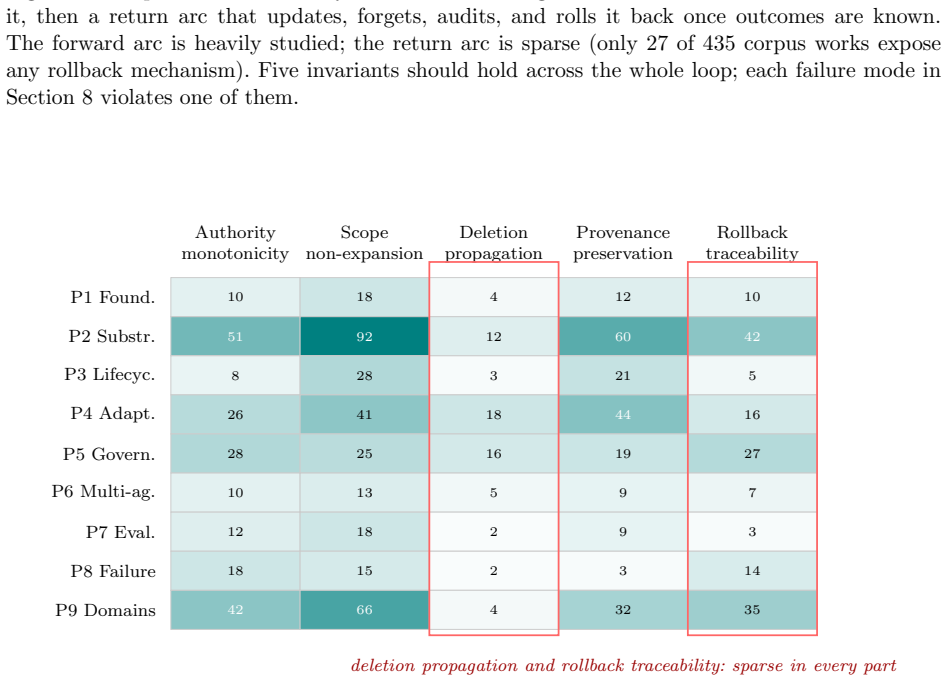
Across a 435-work coded corpus, treated as a scoped map rather than an exhaustive census, the literature concentrates more heavily on accumulating and retrieving state than on governing, recovering, or relinquishing it. The survey introduces the Always-On Evaluation Protocol (AOEP-v0), a pilot evaluation contract that makes these governance requirements concrete by scoring state mutation and recovery obligations rather than answer quality alone.
What carries the argument
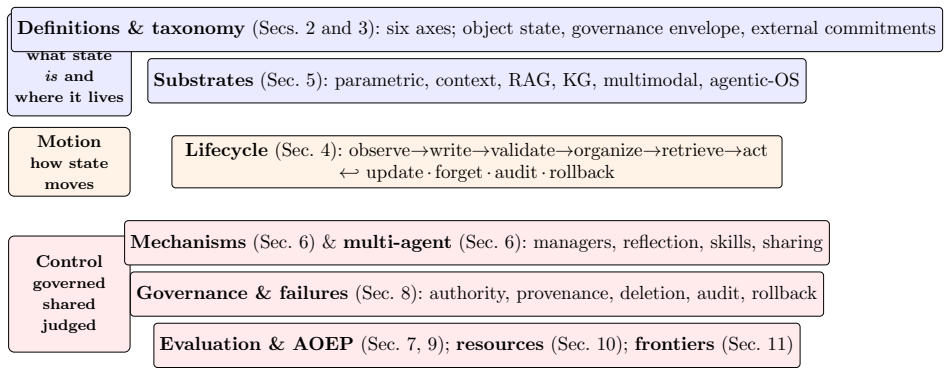
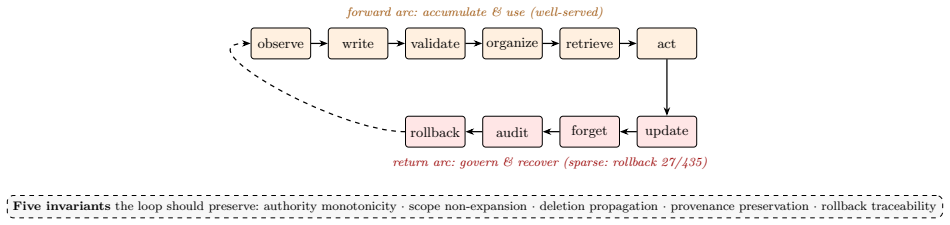
Six diagnostic axes (authority, scope, mutability, provenance, recoverability, actionability) applied to each state item across a lifecycle of write, validate, organize, retrieve, act upon, update, forget, audit, and rollback.
If this is right
- Agent evaluations must incorporate explicit checks for state recovery and rollback obligations rather than answer quality alone.
- Systems need built-in mechanisms to forget or roll back state when permissions change or errors occur.
- Provenance and audit records must be treated as first-class state items with the same management requirements as memories.
- Shared state and externally committed effects require coordination protocols drawn from databases and distributed systems.
Where Pith is reading between the lines
- Current agent benchmarks that ignore long-term state consistency would likely receive low AOEP-v0 scores.
- Techniques from machine unlearning could be adapted to implement the forgetting stage for always-on agents.
- Capability-based security models may offer concrete ways to enforce authority and scope axes on agent state.
Load-bearing premise
The six diagnostic axes and the described lifecycle stages adequately capture the key aspects of persistent state management in always-on agents and allow meaningful coding of the literature.
What would settle it
A re-coding of the same 435 works that finds roughly equal coverage of accumulation, governance, recovery, and relinquishment would falsify the reported concentration.
Figures


read the original abstract
Always-on agents are systems whose future behavior depends on durable state accumulated across earlier interactions. We treat them as persistent-state systems: the operative system includes retrievable memories, but also task ledgers, permissions, credentials, commitments, provenance and audit records, shared state, trigger conditions, and externally committed effects linked to those records. The survey reads the literature through six diagnostic axes for each state item, authority, scope, mutability, provenance, recoverability, and actionability, and through a lifecycle in which state is written, validated, organized, retrieved, acted upon, updated, forgotten, audited, and sometimes rolled back. Across a 435-work coded corpus, treated as a scoped map rather than an exhaustive census, the literature concentrates more heavily on accumulating and retrieving state than on governing, recovering, or relinquishing it. We therefore introduce the Always-On Evaluation Protocol (AOEP-v0), a pilot evaluation contract that makes these governance requirements concrete by scoring state mutation and recovery obligations rather than answer quality alone. The resulting agenda connects always-on agents to databases, distributed systems, formal methods, capability security, and machine unlearning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper surveys always-on LLM agents as persistent-state systems whose behavior depends on durable records including memories, ledgers, permissions, and commitments. It analyzes a 435-work corpus through six diagnostic axes (authority, scope, mutability, provenance, recoverability, actionability) and a nine-stage lifecycle (write, validate, organize, retrieve, act, update, forget, audit, rollback). The central observation is that the literature concentrates on state accumulation and retrieval while under-emphasizing governance, recovery, and relinquishment. The authors introduce AOEP-v0, a pilot evaluation protocol that scores state mutation and recovery obligations rather than answer quality alone, and connect the agenda to databases, distributed systems, formal methods, capability security, and machine unlearning.
Significance. If the coding methodology is made rigorous, the observational map usefully identifies an imbalance in current research priorities and supplies a concrete evaluation contract (AOEP-v0) that could shift assessment practices away from answer quality alone. The explicit linkage to established fields (databases, formal methods, machine unlearning) is a constructive strength; the work is framed as a scoped map rather than a census, which appropriately limits its claims.
major comments (2)
- [corpus construction / abstract] The central claim of literature concentration rests on the coding of 435 works using the six axes and lifecycle stages. The manuscript provides no details on coding methodology, inter-rater reliability, exclusion criteria, or how borderline cases were resolved (see the section describing the corpus construction and the abstract). This information is load-bearing for the reliability of the reported imbalance.
- [AOEP-v0 introduction] AOEP-v0 is presented as a pilot protocol that scores state mutation and recovery obligations. No validation, pilot results, or comparison against existing benchmarks is reported, leaving the protocol's practical utility untested (see the section introducing AOEP-v0).
minor comments (2)
- [diagnostic axes and lifecycle] The six axes and lifecycle stages are introduced without an explicit justification or comparison to prior state-management taxonomies in the agent or database literature; a short related-work paragraph would clarify novelty.
- [corpus description] The paper states the corpus is 'treated as a scoped map rather than an exhaustive census' but does not specify the search strings, date range, or inclusion filters used to arrive at 435 works.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights opportunities to improve methodological transparency and to better contextualize the proposed protocol. We address each major comment below, indicating planned revisions where appropriate. The manuscript is framed as a scoped map, which informs our responses.
read point-by-point responses
-
Referee: The central claim of literature concentration rests on the coding of 435 works using the six axes and lifecycle stages. The manuscript provides no details on coding methodology, inter-rater reliability, exclusion criteria, or how borderline cases were resolved (see the section describing the corpus construction and the abstract). This information is load-bearing for the reliability of the reported imbalance.
Authors: We agree that additional transparency on the corpus construction process is warranted to support the observational claims. In the revised manuscript we will insert a new subsection detailing the selection criteria for the 435 works, the procedure for applying the six diagnostic axes and nine-stage lifecycle, how borderline cases were handled through discussion among authors, and the steps taken to maintain consistency across codings. Although the work is explicitly positioned as a scoped map rather than a formal systematic review, these additions will allow readers to evaluate the reported patterns more rigorously. revision: yes
-
Referee: AOEP-v0 is presented as a pilot protocol that scores state mutation and recovery obligations. No validation, pilot results, or comparison against existing benchmarks is reported, leaving the protocol's practical utility untested (see the section introducing AOEP-v0).
Authors: We acknowledge that the current presentation of AOEP-v0 lacks any illustrative application or comparison to existing benchmarks. In revision we will augment the section with a brief worked example applying the protocol to two publicly described agent systems, thereby demonstrating its scoring mechanics in practice. A comprehensive validation study or head-to-head benchmark comparison lies outside the scope of this survey and is reserved for subsequent work; the protocol is offered as an initial contract rather than a fully validated instrument. revision: partial
Circularity Check
No significant circularity in survey and protocol proposal
full rationale
The paper is a literature survey that codes a 435-work corpus using six explicitly defined diagnostic axes and a lifecycle model, then reports an observational concentration on accumulation/retrieval versus governance/recovery. It introduces AOEP-v0 as a pilot evaluation contract motivated by that map. No equations, fitted parameters, predictions, self-definitional reductions, or load-bearing self-citations appear in the argument structure; the central claim is an external coding result treated as a scoped map rather than a derived theorem, rendering the work self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The six diagnostic axes (authority, scope, mutability, provenance, recoverability, actionability) adequately capture the relevant properties of state items in always-on agents.
- domain assumption The listed lifecycle stages (written, validated, organized, retrieved, acted upon, updated, forgotten, audited, rolled back) represent the key operations on persistent state.
invented entities (1)
-
Always-On Evaluation Protocol (AOEP-v0)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
109 Maya Anderson, Guy Amit, and Abigail Goldsteen
doi: 10.1037/0033-295X.111.4.1036. 109 Maya Anderson, Guy Amit, and Abigail Goldsteen. Is my data in your retrieval database? mem- bership inference attacks against retrieval augmented generation,
-
[2]
com/docs/en/memory
URL https://code.claude. com/docs/en/memory. Accessed 2026-06-28. Mustafa Arslan. Aeon: High-performance neuro-symbolic memory management for long-horizon llm agents,
2026
-
[3]
doi: 10.1016/S1364-6613(00)01538-2. Yushi Bai, Xin Lv, Jiajie Zhang, Hongchang Lyu, Jiankai Tang, Zhidian Huang, Zhengxiao Du, Xiao Liu, Aohan Zeng, Lei Hou, Yuxiao Dong, Jie Tang, and Juanzi Li. Longbench: A bilingual, multitask benchmark for long context understanding,
-
[4]
URL https://arxiv.org/abs/2605.06527. Chunliang Chen, Ming Guan, Xiao Lin, Jiaxu Li, Luxi Lin, Qiyi Wang, Xiangyu Chen, Jixiang Luo, Changzhi Sun, Dell Zhang, and Xuelong Li. Telemem: Building long-term and multimodal memory for agentic ai, 2026a. Jiawei Chen, Hongyu Lin, Xianpei Han, and Le Sun. Benchmarking large language models in retrieval-augmented g...
-
[5]
Kai Chen, Yan Pang, and Tianhao Wang
URL https://arxiv.org/abs/2309.01431. Kai Chen, Yan Pang, and Tianhao Wang. Mrmmia: Membership inference attacks on memory in chat agents, 2026b. 111 Lei (Rachel) Chen, Guilin Zhang, Kai Zhao, Dalmo Cirne, Andy Olsen, Xu Chu, Zeke Miller, Alet Blanken, Amine Anoun, and Jerry Ting. Deployment-time memorization in foundation-model agents, 2026c. URL https:/...
-
[6]
Zheng Chen, Hanqing Liu, Duling Xu, Dong Dong, Jialin Li, Bangzheng Pu, and Jidong Zhai
URL https://arxiv.org/abs/2407.12784. Zheng Chen, Hanqing Liu, Duling Xu, Dong Dong, Jialin Li, Bangzheng Pu, and Jidong Zhai. Cordon: Semantic transactions for tool-using llm agents, 2026h. Zhibao Chen and Qian Cheng. Learning what to remember: A cognitively grounded multi-factor value model for agentic memory,
-
[7]
URL https://arxiv.org/abs/ 2504.19413. Wei-Lin Chiang, Lianmin Zheng, Ying Sheng, Anastasios Nikolas Angelopoulos, Tianle Li, Dacheng Li, Hao Zhang, Banghua Zhu, Michael Jordan, Joseph E. Gonzalez, and Ion Stoica. Chatbot arena: An open platform for evaluating llms by human preference,
-
[8]
112 Zheng Chu, Jingchang Chen, Qianglong Chen, Weijiang Yu, Haotian Wang, Ming Liu, and Bing Qin
URL https://arxiv.org/abs/2604.23338. 112 Zheng Chu, Jingchang Chen, Qianglong Chen, Weijiang Yu, Haotian Wang, Ming Liu, and Bing Qin. Timebench: A comprehensive evaluation of temporal reasoning abilities in large language models,
-
[9]
URL https://arxiv.org/abs/2406.13352. Edoardo Debenedetti, Ilia Shumailov, Tianqi Fan, Jamie Hayes, Nicholas Carlini, Daniel Fabian, Christoph Kern, Chongyang Shi, Andreas Terzis, and Florian Tram` er. Defeating prompt injec- tions by design,
-
[10]
URL https://arxiv.org/abs/2403.07718. Pengfei Du. Memory for autonomous llm agents: Mechanisms, evaluation, and emerging frontiers,
-
[11]
URL https://arxiv.org/abs/2508.06433. Bahare Fatemi, Mehran Kazemi, Anton Tsitsulin, Karishma Malkan, Jinyeong Yim, John Palow- itch, Sungyong Seo, Jonathan Halcrow, and Bryan Perozzi. Test of time: A benchmark for evaluating llms on temporal reasoning,
-
[12]
URL https://arxiv.org/abs/2407.11005. Yuhang Gan, Yiwei Yang, Yuyi Li, Xiangyu Gao, Yichen Wang, Rain Jiang, Xiaoning Ding, Andi Quinn, and Chen Qian. Concordia: Jit-compiled persistent-kernel checkpointing for fault-tolerant llm inference,
-
[13]
Accessed 2026-06-28
URL https://cloud.google.com/gemini/enterprise/docs/configure- personalization. Accessed 2026-06-28. Jiawei Gu, Xuhui Jiang, Zhichao Shi, Hexiang Tan, Xuehao Zhai, Chengjin Xu, Wei Li, Yinghan Shen, Shengjie Ma, Honghao Liu, Saizhuo Wang, Kun Zhang, Yuanzhuo Wang, Wen Gao, Lionel Ni, and Jian Guo. A survey on llm-as-a-judge,
2026
-
[14]
He Hu, Chiyuan Ma, Qianning Wang, Lin Liu, Yucheng Zhou, Laizhong Cui, Fei Ma, and Qi Tian
URL https://arxiv.org/abs/2404.06654. He Hu, Chiyuan Ma, Qianning Wang, Lin Liu, Yucheng Zhou, Laizhong Cui, Fei Ma, and Qi Tian. Theramind: A strategic and adaptive agent for longitudinal psychological counseling, 2025a. Hebin Hu, Renke Dai, Ah-Hwee Tan, and Yilin Kang. Synthesis and evaluation of long-term history-aware medical dialogue,
-
[15]
Evaluating memory in llm agents via incremental multi-turn interactions, 2025b
Yuanzhe Hu, Yu Wang, and Julian McAuley. Evaluating memory in llm agents via incremental multi-turn interactions, 2025b. URL https://arxiv.org/abs/2507.05257. Yuyang Hu, Shichun Liu, Yanwei Yue, Guibin Zhang, Boyang Liu, Fangyi Zhu, Jiahang Lin, Honglin Guo, Shihan Dou, Zhiheng Xi, Senjie Jin, Jiejun Tan, Yanbin Yin, Jiongnan Liu, Zeyu Zhang, Zhongxiang S...
-
[16]
URL https://arxiv.org/abs/ 2602.06052. Zhaopei Huang, Qifeng Dai, Guozheng Wu, Xiaopeng Wu, Kehan Chen, Chuan Yu, Xubin Li, Tiezheng Ge, Wenxuan Wang, and Qin Jin. Mem-pal: Towards memory-based personalized dialogue assistants for long-term user-agent interaction, 2025b. Ziheng Huang, Sebastian Gutierrez, Hemanth Kamana, and Stephen MacNeil. Memory sandbo...
-
[17]
Qingcan Kang, Liu Mingyang, Shixiong Kai, Kaichao Liang, Tao Zhong, and Mingxuan Yuan
URL https: //arxiv.org/abs/2506.06326. Qingcan Kang, Liu Mingyang, Shixiong Kai, Kaichao Liang, Tao Zhong, and Mingxuan Yuan. Learning what to remember: Observability-safe memory retention via constrained optimization for long-horizon language agents,
-
[18]
doi: 10.1016/j.tics.2016.05.004. Maximilian Kuschewski, Lam-Duy Nguyen, Matthias Jasny, Tobias Ziegler, Viktor Leis, and Muhammad El-Hindi. Btrlog: Low-latency logging for cloud database systems,
-
[19]
doi: 10.7551/mitpress/7688. 001.0001. Tu Lan and Chaowei Xiao. Runtime skill audit: Targeted runtime probing for agent skill security,
-
[20]
URL https://arxiv.org/abs/2604.16548. Adam Liska, Tomas Kocisky, Elena Gribovskaya, Tayfun Terzi, Eren Sezener, Devang Agrawal, Cyprien de Masson d’Autume, Tim Scholtes, Manzil Zaheer, Susannah Young, Ellen Gilsenan- McMahon, Sophia Austin, Phil Blunsom, and Angeliki Lazaridou. Streamingqa: A benchmark for adaptation to new knowledge over time in question...
-
[21]
URL https://arxiv.org/abs/2307.03172. Ruiping Liu, Junwei Zheng, Yufan Chen, Di Wen, Shaofang Quan, Chengzhi Wu, Jiaming Zhang, Kailun Yang, Kunyu Peng, and Rainer Stiefelhagen. Egoexomem: Cross-view memory reasoning over synchronized egocentric and exocentric videos, 2026d. Simiao Liu, Li Zhang, Fang Liu, Xiaoli Lian, Yang Liu, and Yinghao Zhu. Memrepair...
-
[22]
URL https://arxiv. org/abs/2402.17753. Bodhisattwa Prasad Majumder, Bhavana Dalvi Mishra, Peter Jansen, Oyvind Tafjord, Niket Tan- don, Li Zhang, Chris Callison-Burch, and Peter Clark. Clin: A continually learning language agent for rapid task adaptation and generalization,
-
[23]
Ripon Chandra Malo and Tong Qiu
URL https://arxiv.org/abs/2310.10134. Ripon Chandra Malo and Tong Qiu. Projectmem: A local-first, event-sourced memory and judg- ment layer for ai coding agents,
-
[24]
URL https://arxiv.org/abs/2606.24535. 121 Samuele Marro, Alan Chan, Xinxing Ren, Lewis Hammond, Jesse Wright, Gurjyot Wanga, Tiziano Piccardi, Nuno Campos, Tobin South, Jialin Yu, Sunando Sengupta, Eric Sommerlade, Alex Pentland, Philip Torr, and Jiaxin Pei. Permission manifests for web agents,
-
[25]
Kevin Meng, David Bau, Alex Andonian, and Yonatan Belinkov
doi: 10.1037/0033-295X.102.3.419. Michael McCloskey and Neal J. Cohen. Catastrophic interference in connectionist networks: The sequential learning problem. InPsychology of Learning and Motivation, volume 24, pages 109–
-
[26]
URLhttp://www.sciencedirect.com/science/article/pii/ S0079742108605368
doi: 10.1016/S0079-7421(08)60536-8. Kai Mei, Xi Zhu, Wujiang Xu, Wenyue Hua, Mingyu Jin, Zelong Li, Shuyuan Xu, Ruosong Ye, Yingqiang Ge, and Yongfeng Zhang. Aios: Llm agent operating system,
-
[27]
Huichao Men, Yizhen Hu, Yu Gao, Xiaofeng Mou, Yi Xu, and Xinhua Xiao
URL https://arxiv.org/ abs/2507.13334. Huichao Men, Yizhen Hu, Yu Gao, Xiaofeng Mou, Yi Xu, and Xinhua Xiao. An autonomous agent framework for feature-label extraction from device dialogues and automatic multi-dimensional device hosting planning based on large language models,
-
[28]
Accessed 2026-06-28
URL https://support.microsoft.com/en-us/microsoft-365-copilot/manage-copilot-memory-in- microsoft-365-copilot. Accessed 2026-06-28. Evan Miller. Adding error bars to evals: A statistical approach to language model evaluations,
2026
-
[29]
Praveen Kumar Myakala, Manan Agrawal, and Rahul Manche
doi: 10.1371/journal.pone.0120644. Praveen Kumar Myakala, Manan Agrawal, and Rahul Manche. Beliefshift: Benchmarking temporal belief consistency and opinion drift in llm agents,
-
[30]
URL https://arxiv.org/abs/2603.23848. Yohei Nakajima. Regimes: An auditable, held-out-gated improvement loop demonstrated on long- memeval with activegraph,
-
[31]
URL https://arxiv.org/abs/2401.00396. Yasmine Omri, Ziyu Gan, Zachary Broveak, Robin Geens, Zexue He, Alex Pentland, Marian Ver- helst, Tsachy Weissman, and Thierry Tambe. Agent memory: Characterization and system implications of stateful long-horizon workloads,
-
[32]
Accessed 2026-06-28
URL https://help.openai.com/en/articles/ 8590148-memory-faq. Accessed 2026-06-28. 123 Barak Or. Mttr-a: Measuring cognitive recovery latency in multi-agent systems,
2026
-
[33]
Yein Park, Chanwoong Yoon, Jungwoo Park, Donghyeon Lee, Minbyul Jeong, and Jaewoo Kang
URL https://arxiv.org/abs/2304.03442. Yein Park, Chanwoong Yoon, Jungwoo Park, Donghyeon Lee, Minbyul Jeong, and Jaewoo Kang. Chroknowledge: Unveiling chronological knowledge of language models in multiple domains,
-
[34]
EMNLP 2024 (ACL Anthology 2024.emnlp-main)
URL https://aclanthology.org/2024.emnlp-main.394/. EMNLP 2024 (ACL Anthology 2024.emnlp-main). Suliu Qin, Haomin Zhuang, Yujun Zhou, Yufei Han, and Xiangliang Zhang. Airguard: Guarding agent actions with runtime authority control,
2024
-
[35]
Andoni Rodriguez, Alberto Pozanco, and Daniel Borrajo
URL https://arxiv.org/abs/2505.18279. Andoni Rodriguez, Alberto Pozanco, and Daniel Borrajo. Is your agent playing dead? deployed llm agents exhibit constraint-evasive fabrication and thanatosis,
-
[36]
URL https: //aclanthology.org/2024.acl-long.399/
doi: 10.18653/v1/2024.acl-long.399. URL https: //aclanthology.org/2024.acl-long.399/. 125 Klaus-Dieter Schewe, Andreas Prinz, and Egon B¨ orger. Concurrent computing with shared repli- cated memory,
-
[37]
Yiheng Shu, Bernal Jimenez Gutierrez, Saisri Padmaja Jonnalagedda, Yuguang Yao, Huan Sun, and Yu Su
URL https://arxiv.org/abs/2303.11366. Yiheng Shu, Bernal Jimenez Gutierrez, Saisri Padmaja Jonnalagedda, Yuguang Yao, Huan Sun, and Yu Su. Agentcl: Toward rigorous evaluation of continual learning in language agents,
-
[38]
Haoran Tan, Zeyu Zhang, Zhicheng Cao, Rui Li, and Xu Chen
URL https://arxiv.org/abs/2309.02427. Haoran Tan, Zeyu Zhang, Zhicheng Cao, Rui Li, and Xu Chen. Deltamem: Incremental experience memory for llm agents via residual trees,
-
[39]
URL https://aclanthology.org/2024.acl-long.850/
doi: 10.18653/v1/2024.acl-long.850. URL https://aclanthology.org/2024.acl-long.850/. 127 Endel Tulving. Episodic and semantic memory. In Endel Tulving and Wayne Donaldson, editors, Organization of Memory, pages 381–403. Academic Press,
- [40]
-
[41]
Voyager: An open-ended embodied agent with large language models, 2023a
Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. Voyager: An open-ended embodied agent with large language models, 2023a. URL https://arxiv.org/abs/2305.16291. Haoyu Wang, Christopher M. Poskitt, Jiali Wei, and Jun Sun. Probguard: Probabilistic runtime monitoring for llm agent safety, 2025a. Ji...
-
[42]
Openrath: Session-centered runtime state for agent systems, 2026a
Fukang Wen, Zhijie Wang, and Ruilin Xu. Openrath: Session-centered runtime state for agent systems, 2026a. Yule Wen, Yanzhe Zhang, Jianxun Lian, Xiaoyuan Yi, Xing Xie, and Diyi Yang. Contextualized privacy defense for LLM agents, 2026b. URL https://arxiv.org/abs/2603.02983. Yixuan Weng, Minjun Zhu, Qiujie Xie, Qiyao Sun, Zhen Lin, Sifan Liu, and Yue Zhang...
-
[43]
Cailin Winston, Claris Winston, and Ren´ e Just
doi: 10.1126/science.8036517. Cailin Winston, Claris Winston, and Ren´ e Just. Solver-aided verification of policy compliance in tool-augmented llm agents,
-
[44]
Longmemeval: Benchmarking chat assistants on long-term interactive memory, 2025a
Di Wu, Hongwei Wang, Wenhao Yu, Yuwei Zhang, Kai-Wei Chang, and Dong Yu. Longmemeval: Benchmarking chat assistants on long-term interactive memory, 2025a. URL https://arxiv.org/ abs/2410.10813. Junde Wu, Minhao Hu, Jiayuan Zhu, Jiazhen Pan, Yuyuan Liu, Min Xu, and Yueming Jin. Git context controller: Manage the context of llm-based agents like git, 2025b....
-
[45]
Streamingvlm: Real-time understanding for infinite video streams, 2025b
Ruyi Xu, Guangxuan Xiao, Yukang Chen, Liuning He, Yao Lu, and Song Han. Streamingvlm: Real-time understanding for infinite video streams, 2025b. Wujiang Xu, Zujie Liang, Kai Mei, Hang Gao, Juntao Tan, and Yongfeng Zhang. A-mem: Agentic memory for llm agents, 2025c. URL https://arxiv.org/abs/2502.12110. Xiaoyu Xu, Minxin Du, Qipeng Xie, Haobin Ke, Qingqing...
-
[46]
Groupmembench: Benchmarking llm agent memory in multi-party conversations, 2026b
Jingbo Yang, Kwei-Herng Lai, Xiaowen Wang, Shiyu Chang, Yaar Harari, and Evgeniy Gabrilovich. Groupmembench: Benchmarking llm agent memory in multi-party conversations, 2026b. URL https://arxiv.org/abs/2605.14498. Jingkang Yang, Shuai Liu, Hongming Guo, Yuhao Dong, Xiamengwei Zhang, Sicheng Zhang, Pengyun Wang, Zitang Zhou, Binzhu Xie, Ziyue Wang, Bei Ouy...
-
[47]
URL https://arxiv.org/abs/2406.04744. Yutao Yang, Junsong Li, Qianjun Pan, Jie Zhou, Kai Chen, Qin Chen, Jingyuan Zhao, Ningning Zhou, Xin Li, and Liang He. Psychagent: An experience-driven lifelong learning agent for self- evolving psychological counselor, 2026c. Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William W. Cohen, Ruslan Salakhutdinov,...
arXiv 2018
-
[48]
Cohen, Ruslan Salakhutdinov, and Christopher D
doi: 10.18653/v1/D18-1259. URL https://aclanthology.org/D18- 1259/. Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models,
-
[49]
URL https://arxiv.org/abs/ 2210.03629. Shunyu Yao, Noah Shinn, Pedram Razavi, and Karthik Narasimhan.τ-bench: A benchmark for tool-agent-user interaction in real-world domains,
-
[50]
Yanyu Yao, Shangze Li, Zhi Zheng, Hui Zheng, Qi Liu, Tong Xu, and Enhong Chen
URL https://arxiv.org/abs/2406.12045. Yanyu Yao, Shangze Li, Zhi Zheng, Hui Zheng, Qi Liu, Tong Xu, and Enhong Chen. Atommem: Building simple and effective memory system for llm agents via atomic facts,
-
[51]
URL https://arxiv. org/abs/2503.16416. Yejin Yoon, Minseo Kim, and Taeuk Kim. Latent preference modeling for cross-session personalized tool calling,
-
[52]
Chaerin Yu, Chihun Choi, Sunjae Lee, Hyosu Kim, Steven Y
URL https://arxiv.org/abs/2601.05111. Chaerin Yu, Chihun Choi, Sunjae Lee, Hyosu Kim, Steven Y. Ko, Young-Bae Ko, and Sangeun Oh. Leveraging llms for efficient and personalized smart home automation, 2026a. Jiatong Yu, Yinghui He, Anirudh Goyal, and Sanjeev Arora. On the impossibility of retrain equiv- alence in machine unlearning,
-
[53]
Understanding users’ privacy perceptions towards llm’s rag- based memory, 2025a
Zhang, Ma, Ma, Li, Xu, Yi, and Li. Understanding users’ privacy perceptions towards llm’s rag- based memory, 2025a. Binchi Zhang, Zihan Chen, Cong Shen, and Jundong Li. Verification of machine unlearning is fragile, 2024a. Chaoyun Zhang, Shilin He, Jiaxu Qian, Bowen Li, Liqun Li, Si Qin, Yu Kang, Minghua Ma, Guyue Liu, Qingwei Lin, Saravan Rajmohan, Dongm...
-
[54]
Bingxi Zhao, Jiahao Zhang, Xubin Ren, Zirui Guo, Tianzhe Chu, Yi Ma, and Chao Huang
URL https://arxiv.org/abs/2308.10144. Bingxi Zhao, Jiahao Zhang, Xubin Ren, Zirui Guo, Tianzhe Chu, Yi Ma, and Chao Huang. Deep- tutor: Towards agentic personalized tutoring, 2026a. Siyan Zhao, Mingyi Hong, Yang Liu, Devamanyu Hazarika, and Kaixiang Lin. Do llms recognize your preferences? evaluating personalized preference following in llms,
-
[55]
URL https: //arxiv.org/abs/2505.11942. Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. Judging LLM-as-a-judge with MT-Bench and chatbot arena,
-
[56]
Yusheng Zheng, Tianyuan Wu, Quanzhi Fu, Tong Yu, Wenan Mao, Wei Wang, Dan Williams, and Andi Quinn
NeurIPS 2023 Datasets and Benchmarks. Yusheng Zheng, Tianyuan Wu, Quanzhi Fu, Tong Yu, Wenan Mao, Wei Wang, Dan Williams, and Andi Quinn. Actplane: Programmable os-level policy enforcement for agent harnesses, 2026c. Yusheng Zheng, Yiwei Yang, Wei Zhang, and Andi Quinn. Acrfence: Preventing semantic rollback attacks in agent checkpoint-restore, 2026d. Wan...
2023
-
[57]
URL https://arxiv.org/abs/2305.10250. 135 Chenyu Zhou, Huacan Chai, Wenteng Chen, Zihan Guo, Rong Shan, Yuanyi Song, Tianyi Xu, Yingxuan Yang, Aofan Yu, Weiming Zhang, Congming Zheng, Jiachen Zhu, Zeyu Zheng, Zhu- osheng Zhang, Xingyu Lou, Changwang Zhang, Zhihui Fu, Jun Wang, Weiwen Liu, Jianghao Lin, and Weinan Zhang. Externalization in llm agents: A un...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.