SceneBot: Contact-Prompted General Humanoid Whole Body Tracking with Scene-Interaction
Pith reviewed 2026-06-29 01:17 UTC · model grok-4.3
The pith
SceneBot unifies free-space and contact-rich humanoid tracking by conditioning one policy on reference motions plus per-link contact labels.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
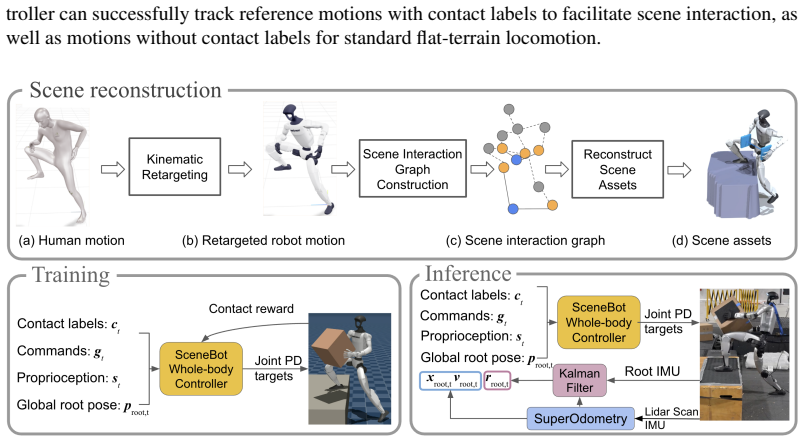
SceneBot trains one policy on reference motions and per-link contact labels that are obtained by hindsight scene reconstruction from retargeted human motion. The resulting policy handles freespace locomotion, uneven terrain, and whole-body manipulation, generalizes to motions and scenes outside the training set, and completes long-horizon tasks such as carrying a box upstairs. The work therefore presents contact conditioning as a practical interface that resolves physical ambiguities pure kinematic tracking cannot address.
What carries the argument
per-link contact conditioning, which supplies explicit expected interaction labels to a single policy so it can resolve contact ambiguities across locomotion and manipulation.
If this is right
- A single policy executes both free-space and contact-rich behaviors without controller switching.
- Training on 7.5 hours of reconstructed contact-rich data suffices for generalization to unseen motions and environments.
- Contact conditioning provides a reusable interface that extends kinematic tracking to scene-interacting tasks.
- Complex long-horizon sequences such as carrying objects upstairs become feasible within one learned controller.
Where Pith is reading between the lines
- The same contact-label interface could be tested on other robot morphologies or multi-robot coordination tasks.
- If reconstruction errors accumulate on highly deformable objects, the method would require additional sensing or online label correction.
- Real-robot transfer would need to verify that simulated contact labels remain valid under actuator noise and model mismatch.
Load-bearing premise
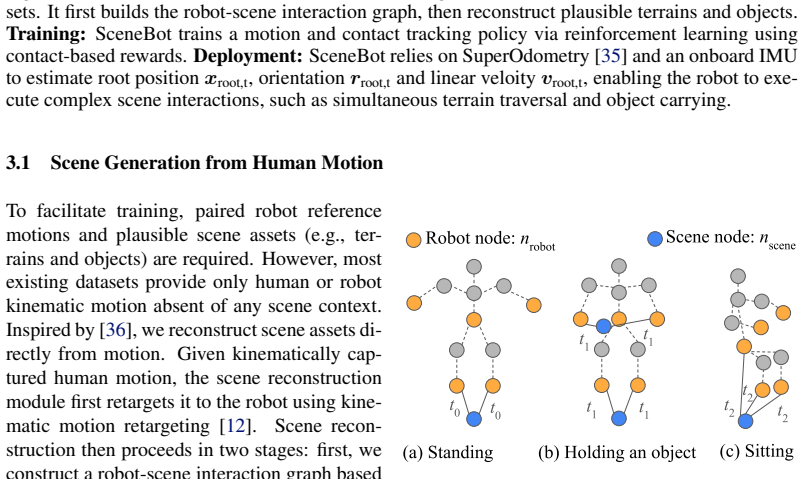
The hindsight scene reconstruction step produces sufficiently accurate per-link contact labels from retargeted human motion without introducing systematic errors that would prevent policy generalization.
What would settle it
Run the trained policy on a new scene where the reconstructed contact labels disagree with the actual geometry and physics; if the policy produces unstable or incorrect contacts while a version trained with ground-truth labels succeeds, the reconstruction assumption fails.
Figures








read the original abstract
Current humanoid reinforcement-learning policies excel at free-space motions but struggle with contact-rich tasks, as pure kinematic tracking cannot resolve the physical ambiguities of interacting with objects and uneven terrain. To address this, we introduce SceneBot, a unified motion-tracking framework capable of handling freespace locomotion, terrain traversal, and whole-body manipulation. SceneBot conditions a single policy on both reference motions and per-link contact labels, explicitly defining expected environmental interactions. To overcome the lack of annotated interaction data, we propose a hindsight scene reconstruction approach that infers scene-interaction graphs from retargeted human motion. Trained on 7.5 hours of this reconstructed, contact-rich data, SceneBot successfully generalizes to unseen motions and environments. Our results demonstrate that SceneBot is the first general framework to seamlessly unify free-space and contact-rich behaviors executing complex, long-horizon tasks like carrying a box upstairs and establishing contact conditioning as a powerful interface for humanoid control. All code and data will be open-sourced. More demos and information are available at: https://ericcsr.github.io/scenebot/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SceneBot, a unified RL-based motion-tracking framework for humanoids that conditions a single policy on reference motions plus per-link contact labels. These labels are obtained via a hindsight scene-reconstruction pipeline applied to retargeted human motion; the resulting 7.5-hour dataset is used to train the policy, which is claimed to generalize to unseen motions and environments while seamlessly handling both free-space locomotion and contact-rich whole-body tasks such as carrying a box upstairs.
Significance. If the central claims hold, the work would be significant for humanoid control by demonstrating that explicit contact conditioning can serve as a general interface bridging free-space and interaction behaviors, with the open release of code and data providing a concrete resource for the community.
major comments (2)
- [Abstract / Methods (hindsight reconstruction pipeline)] The unification claim and generalization to long-horizon contact-rich tasks rest on the assumption that hindsight scene reconstruction produces sufficiently accurate per-link contact labels. No quantitative validation of label fidelity (e.g., precision/recall of contact timing and location against physics simulation or ground-truth scenes) is reported, so systematic retargeting biases could cause the policy to overfit to reconstruction artifacts rather than true dynamics.
- [Abstract / Results] The abstract asserts successful generalization to unseen motions and environments and to complex tasks, yet supplies no quantitative results, ablation studies, tracking-error metrics, or success rates. Without these data the evidence supporting the central claim cannot be evaluated.
minor comments (1)
- [Abstract] The manuscript should include a clear description of the policy architecture, observation space, and reward terms in the main text rather than relying solely on the project page.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We respond to each major comment below, indicating planned revisions where the manuscript can be strengthened.
read point-by-point responses
-
Referee: [Abstract / Methods (hindsight reconstruction pipeline)] The unification claim and generalization to long-horizon contact-rich tasks rest on the assumption that hindsight scene reconstruction produces sufficiently accurate per-link contact labels. No quantitative validation of label fidelity (e.g., precision/recall of contact timing and location against physics simulation or ground-truth scenes) is reported, so systematic retargeting biases could cause the policy to overfit to reconstruction artifacts rather than true dynamics.
Authors: We agree this is a valid point and that explicit validation of label quality would strengthen the paper. In the revision we will add a dedicated analysis (new subsection in Methods or Experiments) that reports precision, recall, and timing error for contact labels on a held-out set of motions, obtained by comparing the reconstructed labels against forward simulation in the target scenes. This will directly address potential retargeting biases. revision: yes
-
Referee: [Abstract / Results] The abstract asserts successful generalization to unseen motions and environments and to complex tasks, yet supplies no quantitative results, ablation studies, tracking-error metrics, or success rates. Without these data the evidence supporting the central claim cannot be evaluated.
Authors: The full results section already presents quantitative tracking-error curves, per-task success rates (including the box-carrying example), and ablations on contact conditioning versus baselines. To make the strength of evidence immediately visible, we will revise the abstract to include concise numerical highlights drawn from those results (e.g., mean tracking error and success rate ranges). revision: partial
Circularity Check
No circularity: derivation is self-contained with external data pipeline
full rationale
The paper presents a policy trained on contact labels generated via an external hindsight reconstruction process from retargeted human motion data. No equations, fitted parameters, or predictions are shown that reduce to the inputs by construction. The generalization claim is to unseen motions and environments, which are independent of the training set. No self-citation chains or uniqueness theorems are invoked in the provided text to support the central result. The method is a standard supervised training pipeline on reconstructed labels, with no load-bearing step that equates the output to the input definition.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
VLK: Learning Humanoid Loco-Manipulation from Synthetic Interactions in Reconstructed Scenes
Generates 48,000 synthetic VLK trajectories in 3D-reconstructed scenes to train a policy for egocentric perception-based humanoid navigation and object transport, shown on physical Unitree G1 robot.
Reference graph
Works this paper leans on
-
[1]
Q. Liao, T. E. Truong, X. Huang, Y . Gao, G. Tevet, K. Sreenath, and C. K. Liu. Beyondmimic: From motion tracking to versatile humanoid control via guided diffusion.arXiv preprint arXiv:2508.08241, 2025
Pith/arXiv arXiv 2025
-
[2]
X. B. Peng, P. Abbeel, S. Levine, and M. Van de Panne. Deepmimic: Example-guided deep re- inforcement learning of physics-based character skills.ACM Transactions On Graphics (TOG), 37(4):1–14, 2018
2018
-
[3]
T. He, J. Gao, W. Xiao, Y . Zhang, Z. Wang, J. Wang, Z. Luo, G. He, N. Sobanbab, C. Pan, et al. Asap: Aligning simulation and real-world physics for learning agile humanoid whole- body skills.arXiv preprint arXiv:2502.01143, 2025
arXiv 2025
-
[4]
Z. Luo, Y . Yuan, T. Wang, C. Li, S. Chen, F. Castaneda, Z.-A. Cao, J. Li, D. Minor, Q. Ben, et al. Sonic: Supersizing motion tracking for natural humanoid whole-body control.arXiv preprint arXiv:2511.07820, 2025
Pith/arXiv arXiv 2025
-
[5]
Z. Chen, M. Ji, X. Cheng, X. Peng, X. B. Peng, and X. Wang. Gmt: General motion tracking for humanoid whole-body control.arXiv preprint arXiv:2506.14770, 2025
arXiv 2025
- [6]
-
[7]
Y . Ze, Z. Chen, J. P. Ara´ujo, Z.-a. Cao, X. B. Peng, J. Wu, and C. K. Liu. Twist: Teleoperated whole-body imitation system.arXiv preprint arXiv:2505.02833, 2025
arXiv 2025
-
[8]
Q. Lu, Y . Feng, B. Shi, M. Piseno, Z. Bao, and C. K. Liu. Gentlehumanoid: Learn- ing upper-body compliance for contact-rich human and object interaction.arXiv preprint arXiv:2511.04679, 2025
arXiv 2025
-
[9]
S. Chen, Z.-a. Cao, Z. Luo, F. Casta ˜neda, C. Li, T. Wang, Y . Yuan, L. Fan, C. K. Liu, Y . Zhu, et al. Chip: Adaptive compliance for humanoid control through hindsight perturbation.arXiv preprint arXiv:2512.14689, 2025
arXiv 2025
-
[10]
Mahmood, N
N. Mahmood, N. Ghorbani, N. F. Troje, G. Pons-Moll, and M. J. Black. Amass: Archive of motion capture as surface shapes. InProceedings of the IEEE/CVF international conference on computer vision, pages 5442–5451, 2019
2019
-
[11]
J. Saito, J. Li, M. de Ruyter, M. Guerrero, E. Lim, E. Hassani, R. B. Ribera, H. Moon, M. Dadela, M. D. Lucca, Q. Wang, X. Li, J. Kautz, S. Yuen, and U. Iqbal. Soma: Unify- ing parametric human body models.arXiv preprint arXiv:2603.16858, 2026. URLhttps: //arxiv.org/abs/2603.16858
arXiv 2026
-
[12]
J. P. Araujo, Y . Ze, P. Xu, J. Wu, and C. K. Liu. Retargeting matters: General motion retargeting for humanoid motion tracking.arXiv preprint arXiv:2510.02252, 2025
arXiv 2025
-
[13]
M. Mittal, P. Roth, J. Tigue, A. Richard, O. Zhang, P. Du, A. Serrano-Munoz, X. Yao, R. Zurbr ¨ugg, N. Rudin, et al. Isaac lab: A gpu-accelerated simulation framework for multi- modal robot learning.arXiv preprint arXiv:2511.04831, 2025
Pith/arXiv arXiv 2025
- [14]
-
[15]
Y . Ze, S. Zhao, W. Wang, A. Kanazawa, R. Duan, P. Abbeel, G. Shi, J. Wu, and C. K. Liu. Twist2: Scalable, portable, and holistic humanoid data collection system.arXiv preprint arXiv:2511.02832, 2025. 10
arXiv 2025
-
[16]
Deits and R
R. Deits and R. Tedrake. Footstep planning on uneven terrain with mixed-integer convex optimization. In2014 IEEE-RAS international conference on humanoid robots, pages 279–
-
[17]
Kuindersma, R
S. Kuindersma, R. Deits, M. Fallon, A. Valenzuela, H. Dai, F. Permenter, T. Koolen, P. Marion, and R. Tedrake. Optimization-based locomotion planning, estimation, and control design for the atlas humanoid robot.Autonomous robots, 40(3):429–455, 2016
2016
-
[18]
Q. Ben, B. Xu, K. Li, F. Jia, W. Zhang, J. Wang, J. Wang, D. Lin, and J. Pang. Gallant: V oxel grid-based humanoid locomotion and local-navigation across 3d constrained terrains.arXiv preprint arXiv:2511.14625, 2025
arXiv 2025
- [19]
- [20]
-
[21]
L. Yang, X. Huang, Z. Wu, A. Kanazawa, P. Abbeel, C. Sferrazza, C. K. Liu, R. Duan, and G. Shi. Omniretarget: Interaction-preserving data generation for humanoid whole-body loco- manipulation and scene interaction.arXiv preprint arXiv:2509.26633, 2025
Pith/arXiv arXiv 2025
-
[22]
Z. Wu, X. Huang, L. Yang, Y . Zhang, K. Sreenath, X. Chen, P. Abbeel, R. Duan, A. Kanazawa, C. Sferrazza, et al. Perceptive humanoid parkour: Chaining dynamic human skills via motion matching.arXiv preprint arXiv:2602.15827, 2026
Pith/arXiv arXiv 2026
-
[23]
X. B. Peng, Z. Ma, P. Abbeel, S. Levine, and A. Kanazawa. Amp: Adversarial motion priors for stylized physics-based character control.ACM Transactions on Graphics (ToG), 40(4): 1–20, 2021
2021
-
[24]
S. Zhu, Z. Zhuang, M. Zhao, K.-Y . Lee, and H. Zhao. Hiking in the wild: A scalable perceptive parkour framework for humanoids.arXiv preprint arXiv:2601.07718, 2026
arXiv 2026
-
[25]
M. Xu, Y . Shi, K. Yin, and X. B. Peng. Parc: Physics-based augmentation with reinforcement learning for character controllers. InProceedings of the Special Interest Group on Computer Graphics and Interactive Techniques Conference Conference Papers, pages 1–11, 2025
2025
-
[26]
Z. Zhang, K. Wen, M. Xu, J. He, C. Li, T. Miki, C. Schwarke, C. Zhang, X. B. Peng, and M. Hutter. Learning whole-body humanoid locomotion via motion generation and motion tracking.arXiv preprint arXiv:2604.17335, 2026
Pith/arXiv arXiv 2026
-
[27]
J. Bjorck, F. Casta ˜neda, N. Cherniadev, X. Da, R. Ding, L. Fan, Y . Fang, D. Fox, F. Hu, S. Huang, et al. Gr00t n1: An open foundation model for generalist humanoid robots.arXiv preprint arXiv:2503.14734, 2025
Pith/arXiv arXiv 2025
-
[28]
S. Wei, H. Jing, B. Li, Z. Zhao, J. Mao, Z. Ni, S. He, J. Liu, X. Liu, K. Kang, et al.ψ 0: An open foundation model towards universal humanoid loco-manipulation.arXiv preprint arXiv:2603.12263, 2026
arXiv 2026
-
[29]
J. Li, J. Wu, and C. K. Liu. Object motion guided human motion synthesis.ACM Transactions on Graphics (TOG), 42(6):1–11, 2023
2023
-
[30]
Lu, C.-H
J. Lu, C.-H. P. Huang, U. Bhattacharya, Q. Huang, and Y . Zhou. Humoto: A 4d dataset of mocap human object interactions. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 10886–10897, 2025
2025
-
[31]
H. Weng, Y . Li, N. Sobanbabu, Z. Wang, Z. Luo, T. He, D. Ramanan, and G. Shi. Hdmi: Learning interactive humanoid whole-body control from human videos.arXiv preprint arXiv:2509.16757, 2025. 11
arXiv 2025
-
[32]
Z. Wu, J. Li, P. Xu, and C. K. Liu. Human-object interaction from human-level instructions. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 11176– 11186, 2025
2025
-
[33]
S. Zhao, Y . Ze, Y . Wang, C. K. Liu, P. Abbeel, G. Shi, and R. Duan. Resmimic: From gen- eral motion tracking to humanoid whole-body loco-manipulation via residual learning.arXiv preprint arXiv:2510.05070, 2025
arXiv 2025
- [34]
-
[35]
S. Zhao, H. Zhang, P. Wang, L. Nogueira, and S. Scherer. Super odometry: Imu-centric lidar-visual-inertial estimator for challenging environments. In2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 8729–8736. IEEE, 2021
2021
-
[36]
Y . Jiang, Y . Ye, D. Gopinath, J. Won, A. W. Winkler, and C. K. Liu. Transformer inertial poser: Real-time human motion reconstruction from sparse imus with simultaneous terrain generation. InSIGGRAPH Asia 2022 Conference Papers, SA ’22, page 1–9. ACM, Nov. 2022. doi:10.1145/3550469.3555428. URLhttp://dx.doi.org/10.1145/3550469.3555428
-
[37]
F. G. Harvey, M. Yurick, D. Nowrouzezahrai, and C. Pal. Robust motion in-betweening. ACM Transactions on Graphics, 39(4), Aug. 2020. ISSN 1557-7368. doi:10.1145/3386569. 3392480. URLhttp://dx.doi.org/10.1145/3386569.3392480. 12 A Scene Reconstruction Algorithm Algorithm 1Scene Reconstruction from Human Motion Require:Human kinematic motionM human Ensure:R...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.