Equation Discovery for Nonlinear System Identification
Pith reviewed 2026-05-25 12:12 UTC · model grok-4.3
The pith
Process-based modeling reconstructs both the structure and parameters of nonlinear systems from measured data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
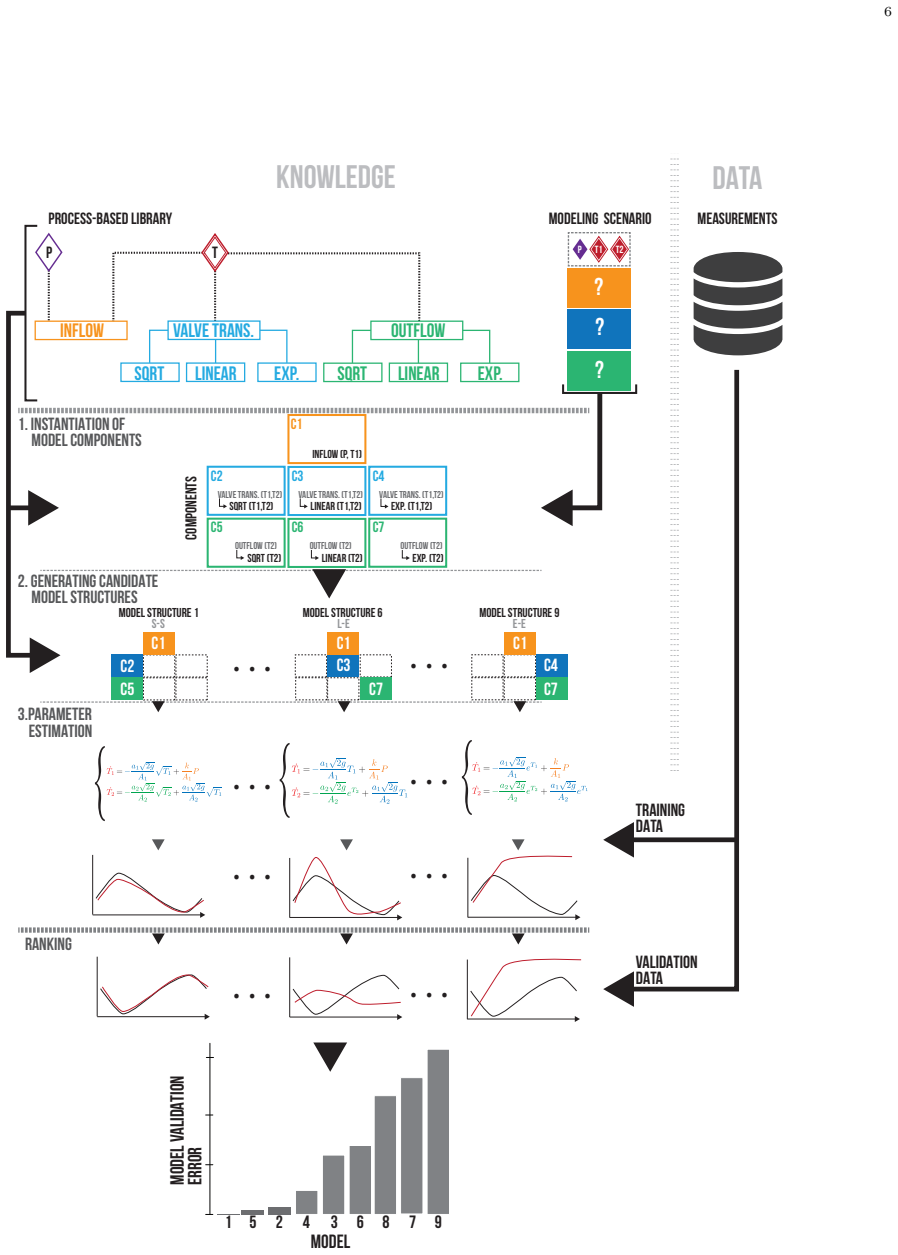
Process-based modeling performs computer-aided identification of a model structure composed of elements selected from user-specified domain-specific modeling knowledge, interlaced with parameter estimation. When applied to continuous-time nonlinear systems, this reconstructs both the model structure and the parameters from measured data, as shown in a synthetic case study and a standard system-identification benchmark with real measurements.
What carries the argument
Process-based modeling, which identifies model structure by composing user-specified domain-specific building blocks and then estimates parameters.
If this is right
- The method produces gray-box models that incorporate partial domain knowledge rather than purely data-driven black-box fits.
- It recovers both structure and parameters on continuous-time nonlinear systems when the supplied elements are appropriate.
- It supports model construction for tasks where expert knowledge about component processes is available but the exact combination is unknown.
Where Pith is reading between the lines
- The same structure-identification step could be tested on discrete-time or hybrid systems to check whether the interlacing with parameter estimation generalizes.
- If the building-block library is expanded automatically from first principles, the method might reduce reliance on manual domain input.
- Recovered models could be directly inserted into simulation or control software without additional translation steps.
Load-bearing premise
The user-specified domain-specific modeling knowledge contains the correct building-block elements from which the true underlying model structure can be composed.
What would settle it
A dataset generated from a dynamical system whose governing equations require building blocks absent from the supplied domain knowledge, on which the method returns an incorrect structure, would falsify the reconstruction claim.
Figures


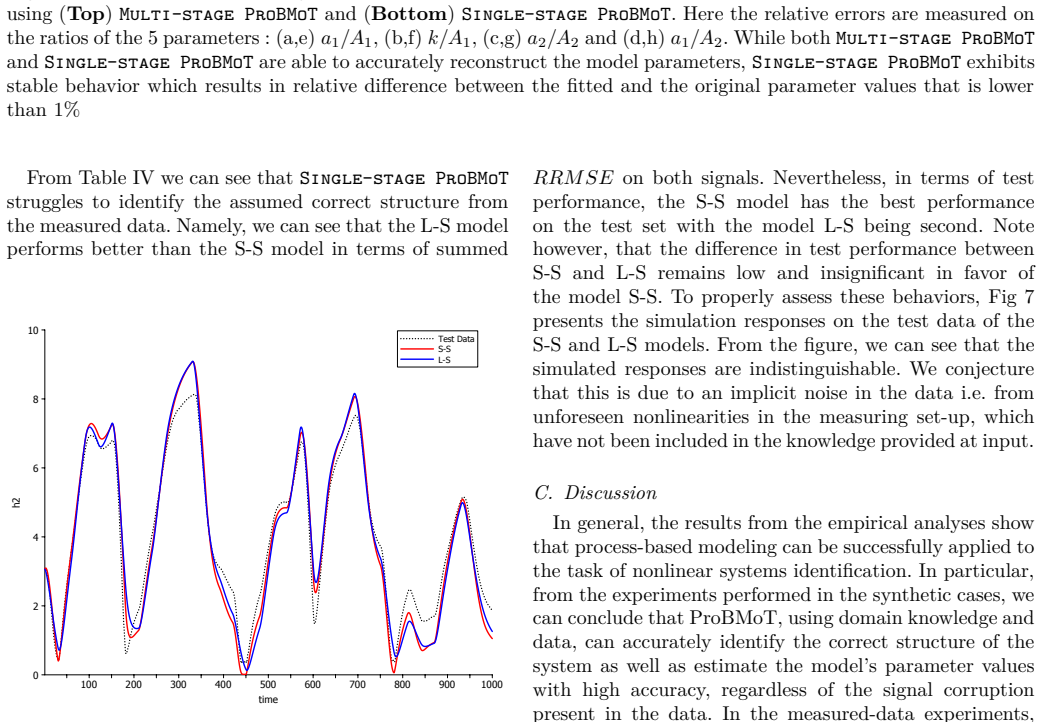
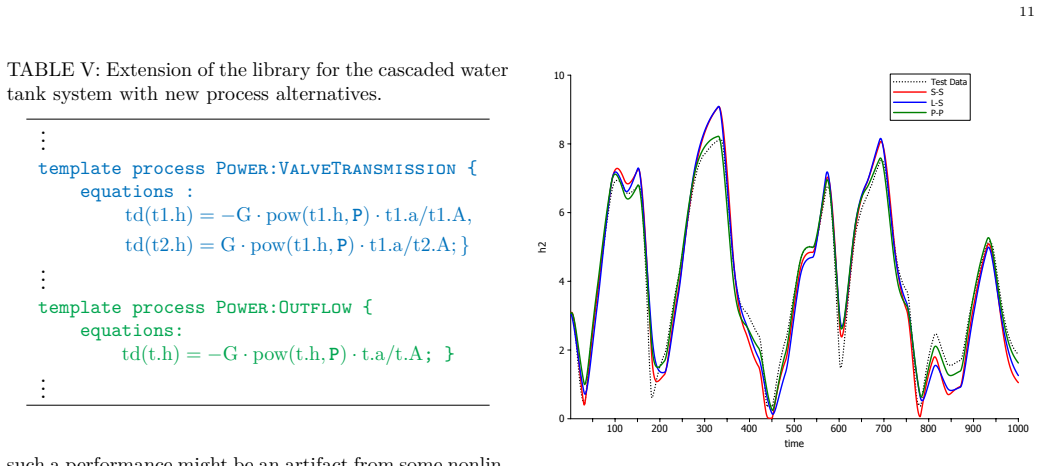
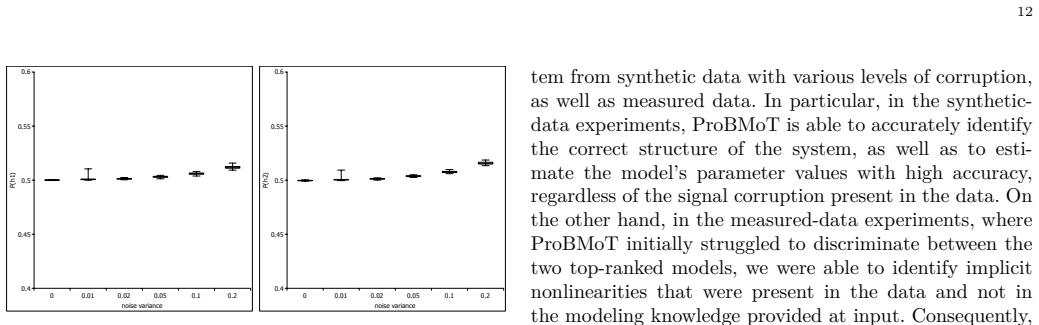
read the original abstract
Equation discovery methods enable modelers to combine domain-specific knowledge and system identification to construct models most suitable for a selected modeling task. The method described and evaluated in this paper can be used as a nonlinear system identification method for gray-box modeling. It consists of two interlaced parts of modeling that are computer-aided. The first performs computer-aided identification of a model structure composed of elements selected from user-specified domain-specific modeling knowledge, while the second part performs parameter estimation. In this paper, recent developments of the equation discovery method called process-based modeling, suited for nonlinear system identification, are elaborated and illustrated on two continuous-time case studies. The first case study illustrates the use of the process-based modeling on synthetic data while the second case-study evaluates on measured data for a standard system-identification benchmark. The experimental results clearly demonstrate the ability of process-based modeling to reconstruct both model structure and parameters from measured data.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents recent developments in process-based modeling, an equation discovery method for nonlinear system identification in a gray-box setting. It consists of two interlaced computer-aided parts: structure identification from user-specified domain-specific modeling primitives, followed by parameter estimation. The method is illustrated on two continuous-time case studies—one using synthetic data and one using measured data from a standard system-identification benchmark—with the central claim that the experimental results demonstrate successful reconstruction of both model structure and parameters from measured data.
Significance. If the central claim holds under appropriate user-supplied primitives, the approach provides a structured way to incorporate partial domain knowledge into nonlinear system identification, bridging black-box data-driven methods and fully mechanistic modeling. This could be valuable in domains with known building-block processes but unknown compositions.
major comments (2)
- [Abstract / Case studies] Abstract and case-study sections: The assertion that 'the experimental results clearly demonstrate the ability of process-based modeling to reconstruct both model structure and parameters' is presented without any quantitative metrics (e.g., parameter error, prediction RMSE, structure recovery rates), error bars, or baseline comparisons, leaving the strength of the demonstration unevaluated.
- [Method] Method description: The central claim depends on the user supplying a set of primitives that contains the correct building blocks; while this gray-box assumption is stated, the experiments do not include a sensitivity test or ablation on incomplete or noisy domain knowledge to bound the method's robustness.
minor comments (1)
- [Method] Notation for the two interlaced modeling parts could be clarified with explicit pseudocode or a diagram showing the information flow between structure search and parameter estimation.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We provide point-by-point responses to the major comments below.
read point-by-point responses
-
Referee: [Abstract / Case studies] Abstract and case-study sections: The assertion that 'the experimental results clearly demonstrate the ability of process-based modeling to reconstruct both model structure and parameters' is presented without any quantitative metrics (e.g., parameter error, prediction RMSE, structure recovery rates), error bars, or baseline comparisons, leaving the strength of the demonstration unevaluated.
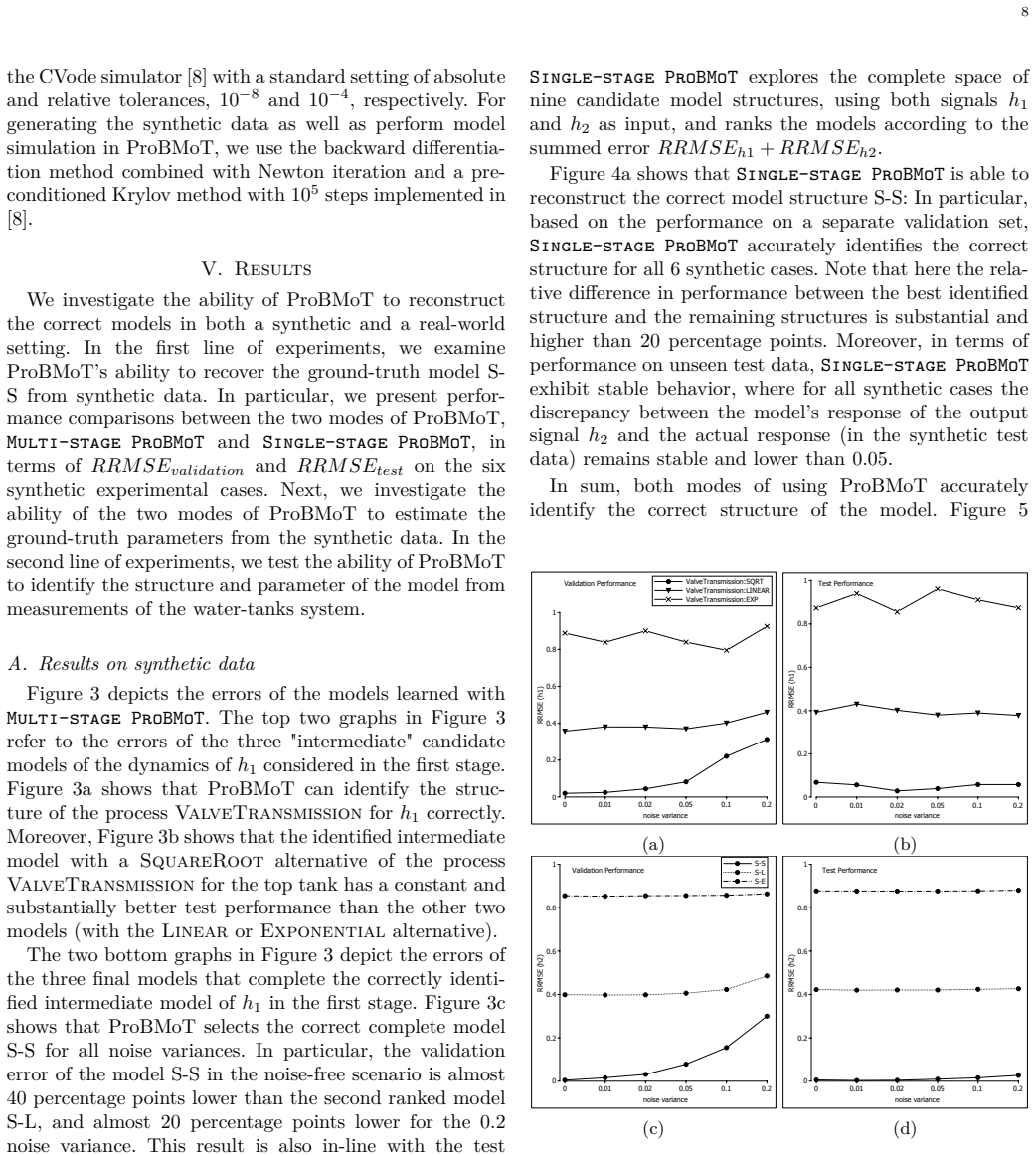
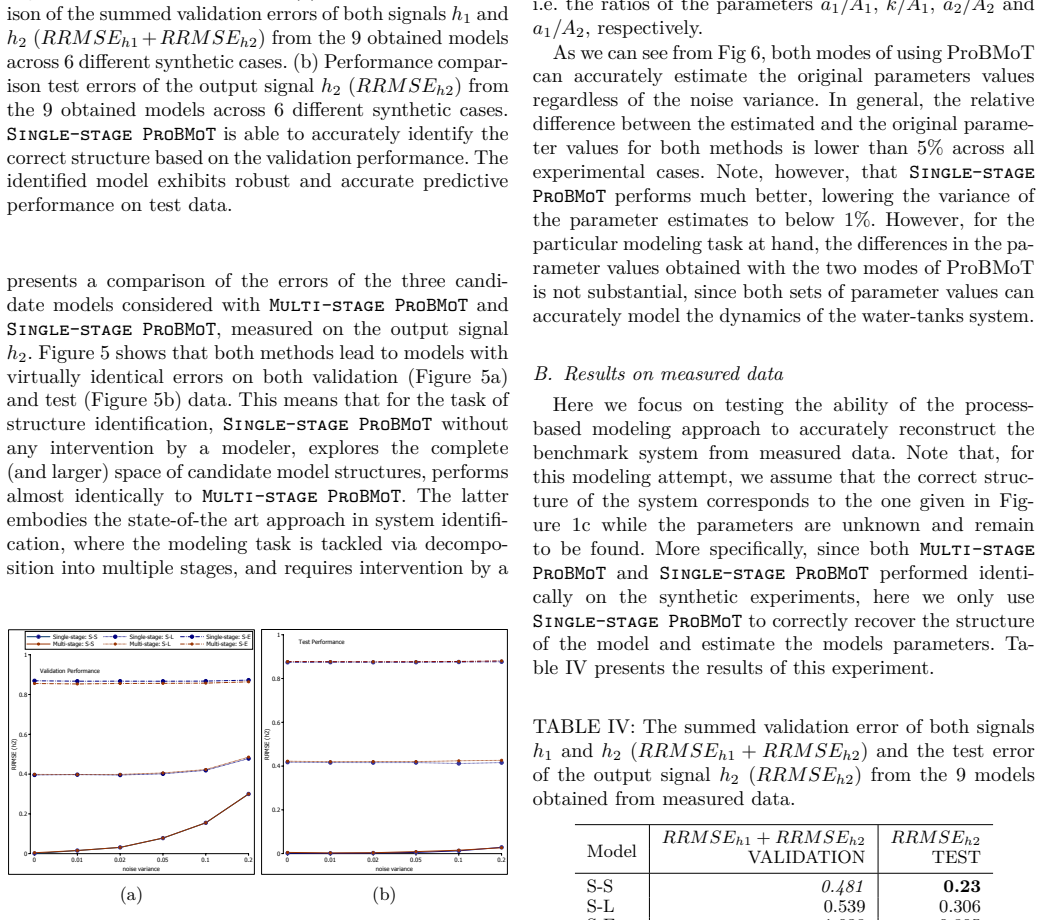
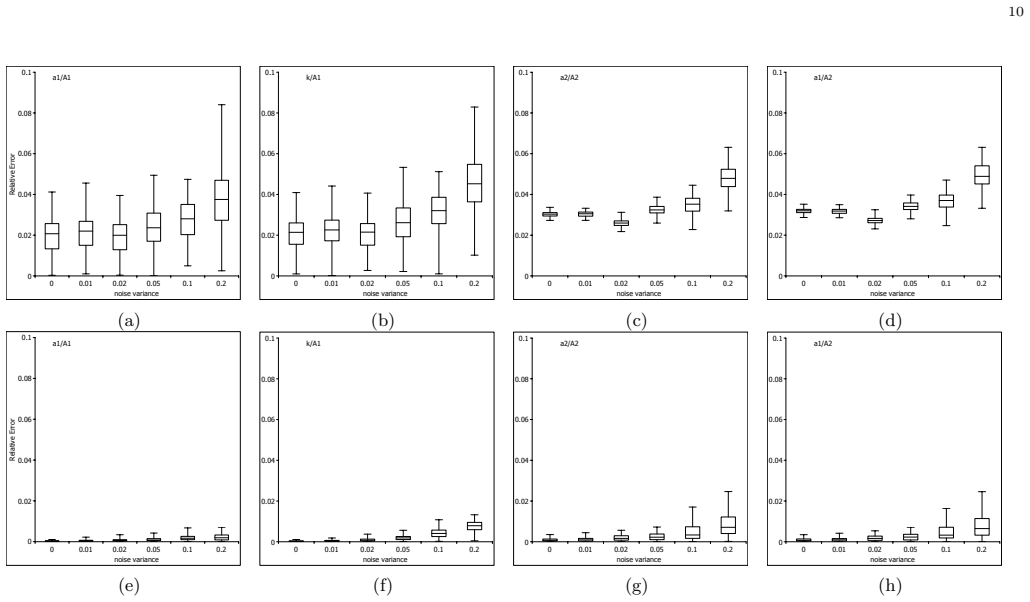
Authors: We agree that the presentation of results in the abstract and case studies relies on qualitative assessment and visual comparisons rather than explicit quantitative metrics. The manuscript includes plots showing the fit of the discovered models to the data, but does not report numerical values such as RMSE or parameter errors. To address this, we will add quantitative metrics, including parameter estimation errors, prediction RMSE, and where possible structure recovery indicators, along with comparisons to baseline methods in the revised version. revision: yes
-
Referee: [Method] Method description: The central claim depends on the user supplying a set of primitives that contains the correct building blocks; while this gray-box assumption is stated, the experiments do not include a sensitivity test or ablation on incomplete or noisy domain knowledge to bound the method's robustness.
Authors: The method is explicitly designed as a gray-box approach where the user provides the domain-specific primitives, and the claim is made under the assumption that these include the necessary building blocks. The experiments illustrate successful reconstruction when this assumption holds. We acknowledge that no sensitivity analysis to incomplete or noisy primitives is provided. Adding such an analysis would require additional experiments defining various levels of incompleteness, which we can include in a revision to better bound the method's applicability. revision: yes
Circularity Check
No significant circularity
full rationale
The paper presents a gray-box equation discovery method (process-based modeling) that takes as explicit external inputs both user-specified domain primitives and measured time-series data, then performs structure search followed by parameter estimation. No derivation step reduces a claimed result to a quantity defined by the method's own fitted outputs, nor does any load-bearing premise rest on a self-citation chain that itself lacks independent verification. The reported reconstructions are evaluated on held-out synthetic and benchmark data under the stated assumption that the supplied building blocks are adequate; this is an empirical demonstration rather than a self-referential identity. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption User-provided domain knowledge contains the elementary processes or components needed to form the correct model structure.
Reference graph
Works this paper leans on
-
[1]
D. Aleksovski, J. Kocijan, and S. Džeroski. Ensembles of fuzzy linear model trees for the identification of multioutput systems. IEEE Transactions on Fuzzy Systems, 24(4):916–929, 2016
work page 2016
-
[2]
P. J. Ashenden. The Designer’s Guide to VHDL. Morgan Kaufmann Inc., San Francisco, CA, USA, 3 edition, 2008
work page 2008
-
[3]
N. Atanasova, L. Todorovski, S. Džeroski, R. Remec, F. Reck- nagel, and B. Kompare. Automated modelling of a food web in Lake Bled using measured data and a library of domain knowledge. Ecological Modelling, 194(1-3):37–48, 2006
work page 2006
-
[4]
L. Breiman, J. H. Friedman, C. J. Stone, and R. A. Olshen. Classification and Regression Trees. Chapman & Hall, London, UK, 1984
work page 1984
-
[5]
W. Bridewell, P. W. Langley, L. Todorovski, and S. Džeroski. Inductive process modeling.Machine Learning, 71:1–32, 2008
work page 2008
-
[6]
S. L. Brunton, J. L. Proctor, and J. N. Kutz. Discovering gov- erning equations from data by sparse identification of nonlinear dynamical systems. Proceedings of the National Academy of Sciences, 113(15):3932–3937, 2016
work page 2016
-
[7]
H. Cao, F. Recknagel, L. Cetin, and B. Zhang. Process-based simulation library SALMO-OO for lake ecosystems. Part 2: Multi-objective parameter optimization by evolutionary algo- rithms. Ecological Informatics, 3(2):181 – 190, 2008
work page 2008
-
[8]
S. D. Cohen and A. C. Hindmarsh. CVode, a stiff/nonstiff ODE solver in C.Journal of Computational Physics, 10(2):138–143, 1996
work page 1996
-
[9]
S. Džeroski and L. Todorovski. Equation discovery for systems biology: Finding the structure and dynamics of biological net- worksfromtimecoursedata. CurrentOpinioninBiotechnology , 19(4):360–368, 2008
work page 2008
-
[10]
J. J. Durillo and A. J. Nebro. jMetal: A Java framework for multi-objective optimization. Advances in Engineering Soft- ware, 42:760–771, 2011
work page 2011
-
[11]
S. Džeroski and L. Todorovski. Discovering dynamics: From inductive logic programming to machine discovery.Journal of Intelligent Information Systems, 4(1):89–108, 1995
work page 1995
-
[12]
L. Ferariu and A. Patelli.Multiobjective Genetic Programming for Nonlinear System Identification, pages 233–242. Springer Berlin, Germany, 2009
work page 2009
- [13]
-
[14]
F.GiriandE.-W.Bai,editors. Block-orientedNonlinearSystem Identification, volume 404 of Lecture Notes in Control and Information Sciences, Springer, Berlin, Germany, 2010
work page 2010
-
[15]
G. J. Gray, D. J. Murray-Smith, Y. Li, K. C. Sharman, and T. Weinbrenner. Nonlinear model structure identification using genetic programming.Control Engineering Practice, 6(11):1341 – 1352, 1998
work page 1998
-
[16]
G. Kerschen, K. Worden, A. F. Vakakis, and J.-C. Golinval. Past, present and future of nonlinear system identification in structural dynamics. Mechanical Systems and Signal Process- ing, 20(3):505 – 592, 2006
work page 2006
-
[17]
J. R. Koza. Genetic Programming II: Automatic Discovery of Reusable Programs. MIT Press, Cambridge, MA, USA, 1994
work page 1994
-
[18]
P. W. Langley, H. A. Simon, G. Bradshaw, and J. M. Zytkow. Scientific Discovery: Computational Explorations of the Cre- ative Processes. MIT Press, Cambridge, MA, USA, 1987
work page 1987
-
[19]
Ljung.System identification - Theory for the User
L. Ljung.System identification - Theory for the User. Prentice- Hall, 1999
work page 1999
-
[20]
L. Ljung. Perspectives on system identification.IFAC Proceed- ings Volumes, 41(2):7172 – 7184, 2008
work page 2008
- [21]
-
[22]
R. I. Mckay, N. X. Hoai, P. A. Whigham, Y. Shan, and M. O’Neill. Grammar-based genetic programming: A survey. Genetic Programming and Evolvable Machines, 11(3-4):365– 396, 2010
work page 2010
-
[23]
K. Rodriguez-Vazquez, C. M. Fonseca, and P. J. Fleming. Identifying the structure of nonlinear dynamic systems using multiobjective genetic programming. IEEE Transactions on Systems, Man, and Cybernetics - Part A: Systems and Humans, 34(4):531–545, 2004. 14
work page 2004
-
[24]
M. Schmidt and H. Lipson. Distilling free-form natural laws from experimental data.Science, 324(5923):81–85, 2009
work page 2009
-
[25]
J. Schoukens, R. Pintelon, Y. Rolain, M. Schoukens, K. Tiels, L. Vanbeylen, A. V. Mulders, and G. Vandersteen. Structure discrimination in block-oriented models using linear approxima- tions: A theoretic framework.Automatica, 53:225 – 234, 2015
work page 2015
-
[26]
J. Schoukens, M. Vaes, A. Esfahani, and R. Relan. Challenges in the identification of discrete time block oriented models for continuous time nonlinear systems. IFAC-PapersOnLine, 48(28):596 – 601, 2015
work page 2015
-
[27]
M. Schoukens and K. Tiels. Identification of block-oriented non- linear systems starting from linear approximations: A survey. Automatica, 85:272 – 292, 2017
work page 2017
-
[28]
M.Schoukens,K.Tiels,M.Ishteva,andJ.Schoukens. Identifica- tion of parallel Wiener-Hammerstein systems with a decoupled static nonlinearity.IFAC Proceedings Volumes, 47(3):505 – 510, 2014
work page 2014
-
[29]
J. Tanevski, L. Todorovski, and S. Džeroski. Learning stochastic process-based models of dynamical systems from knowledge and data. BMC Systems Biology, 10(1):30, 2016
work page 2016
-
[30]
K. Taškova, J. ’ilc, N. Atanasova, and S. Džeroski. Parameter estimation in a nonlinear dynamic model of an aquatic ecosys- tem with meta-heuristic optimization. Ecological Modelling, 226:36–61, 2012
work page 2012
-
[31]
L. Todorovski, W. Bridewell, O. Shiran, and P. W. Langley. Inducing hierarchical process models in dynamic domains. In K. S. Veloso M.M., editor, Proceedings of the 20th National Conference on Artificial Intelligence, NCAI ’05, pages 892–897. AAAI Press, Pittsburgh, PA, USA, 2005
work page 2005
-
[32]
L. Todorovski and S. Džeroski. Integrating domain knowledge in equation discovery. In L. Todorovski and S. Džeroski, editors, Computational Discovery of Scientific Knowledge, volume 4660 of Lecture Notes in Computer Science, pages 69–97. Springer, Berlin, Germany, 2007
work page 2007
-
[33]
D. Čerepnalkoski, K. Taškova, L. Todorovski, N. Atanasova, and S. Džeroski. The influence of parameter fitting methods on model structure selection in automated modeling of aquatic ecosystems. Ecological Modelling, 245(0):136 – 165, 2012
work page 2012
-
[34]
P. Whigham and F. Recknagel. Predicting chlorophyll-a in freshwater lakes by hybridising process-based models and ge- netic algorithms. Ecological Modelling, 146(1–3):243 – 251, 2001
work page 2001
-
[35]
T. Wigren and J. Schoukens. Three free data sets for devel- opment and benchmarking in nonlinear system identification. In Proceedings of the 2013 European Control Conference, ECC 2013, pages 2933–2938. IEEE, 2013
work page 2013
-
[36]
Q. Zhang. Nonlinear system identification with output error model through stabilized simulation. IFAC Proceedings Vol- umes, 37(13):501 – 506, 2004
work page 2004
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.