Identifying vital nodes based on reverse greedy method
Pith reviewed 2026-05-25 10:29 UTC · model grok-4.3
The pith
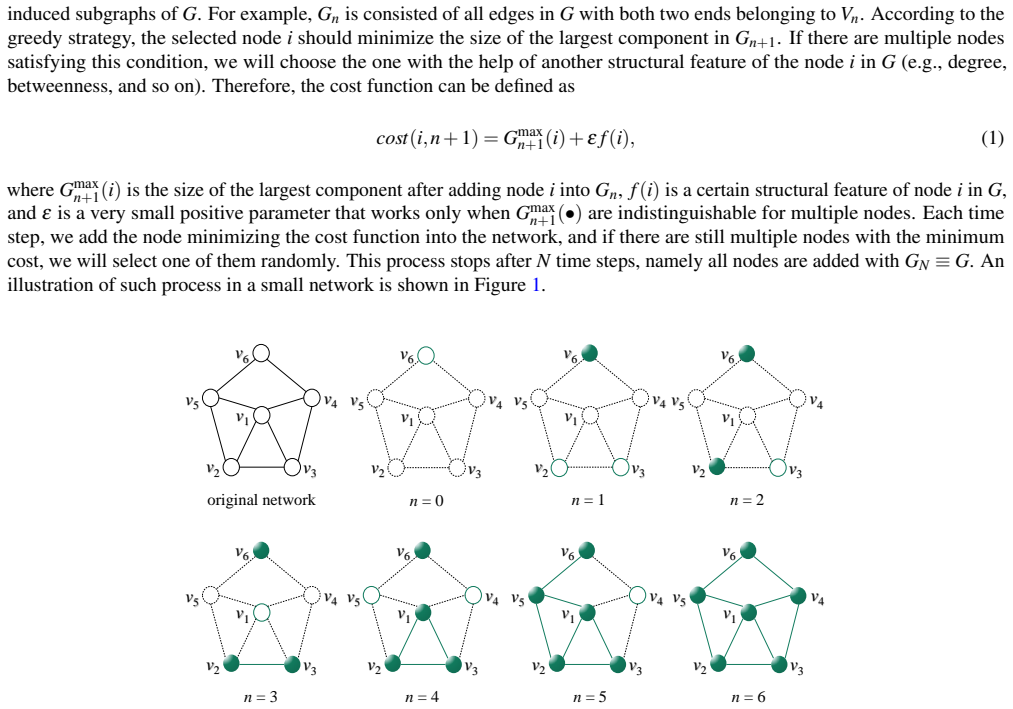
A reverse greedy method ranks nodes by their importance to network connectivity by selecting the least important ones first.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The reverse greedy method identifies vital nodes by iteratively choosing the least important nodes to make the size of the largest component in the corresponding induced subgraph as small as possible, with nodes chosen later being more important in maintaining the connectivity.
What carries the argument
The reverse greedy method that minimizes the largest connected component size in the induced subgraph by preferring least important nodes.
Load-bearing premise
That minimizing the size of the largest connected component when preferentially including least-important nodes produces a ranking that correctly identifies nodes vital for overall network connectivity.
What would settle it
Observing that on additional networks or controlled examples the reverse greedy ranking does not correlate with the actual impact of removing nodes on connectivity.
Figures

read the original abstract
The identification of vital nodes that maintain the network connectivity is a long-standing challenge in network science. In this paper, we propose a so-called reverse greedy method where the least important nodes are preferentially chosen to make the size of the largest component in the corresponding induced subgraph as small as possible. Accordingly, the nodes being chosen later are more important in maintaining the connectivity. Empirical analyses on ten real networks show that the reverse greedy method performs remarkably better than well-known state-of-the-art methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a reverse greedy algorithm for ranking nodes by their importance to network connectivity: nodes are added in an order that keeps the largest connected component (LCC) of the induced subgraph as small as possible at each step, so that nodes selected later are deemed more vital. The central empirical claim is that this ordering outperforms well-known state-of-the-art vital-node methods on ten real networks.
Significance. If the reported performance advantage is reproducible and statistically supported, the work would contribute a parameter-free, connectivity-focused ranking procedure to the vital-node literature. The method directly optimizes an observable (LCC size) rather than relying on heuristic centrality scores, which is a conceptual strength. No machine-checked proofs or open code are mentioned, but the explicit comparison on multiple real networks is a positive feature.
major comments (2)
- [Results] Results section (presumably containing the ten-network comparisons): the abstract states that the method 'performs remarkably better' but supplies no quantitative metrics (e.g., Kendall-τ, AUC on robustness curves, or statistical significance tests), no list of the ten networks, and no description of the exact baseline implementations. Without these details the central empirical claim cannot be evaluated and is therefore load-bearing for acceptance.
- [Method] Method definition (likely §2 or §3): the reverse-greedy procedure is described only at a high level; it is unclear how ties in LCC size are broken, whether the algorithm is deterministic, and what the precise time complexity is. These ambiguities affect reproducibility of the reported rankings and must be resolved before the performance comparison can be trusted.
minor comments (2)
- [Abstract] The abstract should be expanded to name the performance metric, the ten networks, and the baselines so that readers can immediately assess the scope of the claim.
- [Method] Notation for the induced subgraph and LCC size should be introduced once and used consistently; currently the description mixes verbal and symbolic language.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments below and will revise the manuscript to improve clarity, reproducibility, and the self-contained nature of the central claims.
read point-by-point responses
-
Referee: [Results] Results section (presumably containing the ten-network comparisons): the abstract states that the method 'performs remarkably better' but supplies no quantitative metrics (e.g., Kendall-τ, AUC on robustness curves, or statistical significance tests), no list of the ten networks, and no description of the exact baseline implementations. Without these details the central empirical claim cannot be evaluated and is therefore load-bearing for acceptance.
Authors: We agree that the abstract does not include quantitative metrics or network details, which limits immediate evaluation of the performance claim. The results section of the manuscript does list the ten networks (with basic statistics) and reports comparisons against standard baselines using Kendall-τ and robustness-curve AUC, but these are not summarized in the abstract. In the revision we will expand the abstract to report the specific performance gains (e.g., average Kendall-τ improvement) and briefly note the baseline implementations and the use of statistical tests. This change will make the empirical claim self-contained without altering the underlying experiments. revision: yes
-
Referee: [Method] Method definition (likely §2 or §3): the reverse-greedy procedure is described only at a high level; it is unclear how ties in LCC size are broken, whether the algorithm is deterministic, and what the precise time complexity is. These ambiguities affect reproducibility of the reported rankings and must be resolved before the performance comparison can be trusted.
Authors: We acknowledge that the current method description is high-level and omits tie-breaking, determinism, and complexity. In the revised manuscript we will add an explicit statement that ties are broken by lowest node index (ensuring the procedure is fully deterministic) and will include a complexity analysis of the naïve implementation together with a note on possible optimizations. These additions will be placed in the method section and will not change the algorithm itself. revision: yes
Circularity Check
No significant circularity: independent algorithmic definition evaluated on external networks
full rationale
The reverse greedy method is defined directly as an algorithmic procedure: nodes are selected in order of preference to minimize the LCC size of the induced subgraph, with later-selected nodes ranked as more important for connectivity. This definition stands alone without reference to the target ranking or performance metric. The central claim is an empirical comparison of this ranking against other methods on ten real networks, which is externally falsifiable and does not reduce to any fitted parameter, self-definition, or self-citation chain. No load-bearing steps match the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The size of the largest connected component in the induced subgraph serves as a valid proxy for assessing a node's contribution to network connectivity.
Reference graph
Works this paper leans on
-
[1]
Newman, M. E. J. Networks (Oxford University Press, Oxford, 2018)
work page 2018
-
[2]
Scale-Free Networks: Complex Webs in Nature and Technology (Oxford University Press, Oxford, 2007)
Caldarelli, G. Scale-Free Networks: Complex Webs in Nature and Technology (Oxford University Press, Oxford, 2007)
work page 2007
-
[3]
Cohen, R., Erez, K., Ben-Avraham, D. & Havlin, S. Breakdown of the internet under intentional attack. Phys. Rev. Lett. 86, 3682-3685 (2001)
work page 2001
-
[4]
Motter, A. E. & Lai, Y . C. Cascade-based attacks on complex networks.Phys. Rev. E 66, 065102 (2002)
work page 2002
-
[5]
Motter, A. E. Cascade control and defense in complex networks. Phys. Rev. Lett. 93, 098701 (2004)
work page 2004
-
[6]
Albert, R., Albert, I. & Nakarado, G. L. Structural vulnerability of the North American power grid.Phys. Rev. E 69, 025103 (2004)
work page 2004
-
[7]
Albert, R., Jeong, H. & Barabási, A. L. Error and attack tolerance of complex networks. Nature 406, 378–382 (2000)
work page 2000
-
[8]
Li, D., Fu, B., Wang, Y ., Lu, G., Berezin, Y ., Stanley, H. E.,& Havlind, S. Percolation transition in dynamical traffic network with evolving critical bottlenecks. Proc. Natl. Acad. Sci. USA 112, 669-672 (2015)
work page 2015
-
[9]
Haldane, A. G., & May, R. M. Systemic risk in banking ecosystems. Nature 469, 351-355 (2011)
work page 2011
-
[10]
Lü, L., Chen, D., Ren, X. L., Zhang, Q. M., Zhang, Y . C.& Zhou, T. Vital nodes identification in complex networks.Phys. Rep. 650, 1-63 (2016)
work page 2016
-
[11]
Factoring and weighting approaches to status scores and clique identification.Math
Bonacich, P. Factoring and weighting approaches to status scores and clique identification.Math. Sociol. 2, 113-120 (1972)
work page 1972
-
[12]
Lü, L., Zhou, T., Zhang, Q. M. & Stanley, H. E. The H-index of a network node and its relation to degree and coreness. Nat. Commun. 7, 10168 (2016)
work page 2016
-
[13]
K., Havlin, S., Liljeros, F., Muchnik, L.& Stanley, H
Kitsak, M., Gallos, L. K., Havlin, S., Liljeros, F., Muchnik, L.& Stanley, H. E. Identification of influential spreaders in complex networks. Nat. Phys. 6, 888-893 (2010)
work page 2010
- [14]
-
[15]
Leaders in social networks, the delicious case
Lü, L., Zhang, Y .-C., Yeung, C.-H.& Zhou, T. Leaders in social networks, the delicious case. PLoS ONE 6, e21202 (2011)
work page 2011
-
[16]
Freeman, L. C. Centrality in social networks conceptual clarification.Soc. Networks 1, 215-239 (1979)
work page 1979
-
[17]
Freeman, L. C. A set of measures of centrality based on betweenness. Sociometry 40, 35-41 (1977)
work page 1977
-
[18]
Morone, F. & Makse, H. A. Influence maximization in complex networks through optimal percolation. Nature 524, 65-68 (2015). 5/6
work page 2015
-
[19]
Morone, F., Min, B., Bo, L., Mari, R. & Makse, H. A. Collective influence algorithm to find influencers via optimal percolation in massively large social media. Sci. Rep. 6, 30062 (2016)
work page 2016
-
[20]
Gleiser, P. & Danon, L. Community structure in Jazz.Adv. Complex Syst. 6, 565 (2003)
work page 2003
-
[21]
Newman, M. E. J. Finding community structure in networks using the eigenvectors of matrices. Phys. Rev. E 74, 036104 (2006)
work page 2006
-
[22]
Guimer˙a, R., Danon, L., Díaz-Guilera, A., Giralt, F. & Arenas, A. Self-similar community structure in a network of human interactions. Phys. Rev. E 68, 065103 (2003)
work page 2003
-
[23]
Adamic, L. A. & Glance, N. The political blogosphere and the 2004 U.S. election: divided they blog. In Proceedings of the 3rd International Workshop on Link Discovery (ACM Press, 2005, pp. 36-43)
work page 2004
-
[24]
Rocha, L. E., Liljeros, F. & Holme, P. Simulated epidemics in an empirical spatiotemporal network of 50,185 sexual contacts. PLoS Comput. Biol. 7, e1001109 (2011)
work page 2011
-
[25]
Viswanath, B., Mislove, A., Cha, M. & Gummadi, K. P. On the Evolution of User Interaction in Facebook. In Proceedings of the 2nd ACM Workshop on Online Social Networks (ACM Press, 2009, pp. 37–42)
work page 2009
-
[26]
Batageli, V . & Mrvar, A. Pajek Datasets. Available at http://vlado.fmf.uni-lj.si/pub/networks/data/ (2007)
work page 2007
-
[27]
Watts, D. J. & Strogatz, S. H. Collective dynamics of ‘small-world’ networks. Nature 393, 440-442 (1998)
work page 1998
-
[28]
Spring, N., Mahajan, R., Wetherall, D. & Anderson, T. Measuring ISP topologies with rocketfuel. IEEE/ACM Trans. Networking 12, 2-16 (2004)
work page 2004
-
[29]
Gehrke, J., Ginsparg, P. & Kleinberg, J. Overview of the 2003 KDD Cup.SIGKDD Explorations 5, 149-151 (2003)
work page 2003
-
[30]
Newman, M. E. J. Assortative mixing in networks. Phys. Rev. Lett. 89, 208701 (2002)
work page 2002
-
[31]
Hu, H. B. & Wang, X. F. Unified index to quantifying heterogeneity of complex networks. Physica A 387, 3769-3780 (2008)
work page 2008
-
[32]
Schneider, C. M., Moreira, A. A., Andrade, J. S., Havlin, S.& Herrmann, H. J. Mitigation of malicious attacks on networks. Proc. Natl. Acad. Sci. U.S.A. 108, 3838-3841 (2011)
work page 2011
-
[33]
Zhou, R. & Hansen, E. A. Beam-stack search: Integrating backtracking with beam search. In Proceedings of the 15th International Conference on Automated Planning and Scheduling (AAAI Press, 2005, pp. 90–98)
work page 2005
-
[34]
Hirsch, J. E. An index to quantify an individual’s scientific research output.Proc. Natl. Acad. Sci. U.S.A. 102, 16569–16572 (2005). Acknowledgements The authors acknowledge DataCastle to hold the related world-wide competition and to share the data. This work is partially supported by National Natural Science Foundation of China (61473073, 61104074, 61433...
work page 2005
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.