Linked Crunchbase: A Linked Data API and RDF Data Set About Innovative Companies
Pith reviewed 2026-05-24 18:42 UTC · model grok-4.3
The pith
Crunchbase data on companies, people and investments has been converted to an RDF knowledge graph of over 347 million triples and exposed through a Linked Data API.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
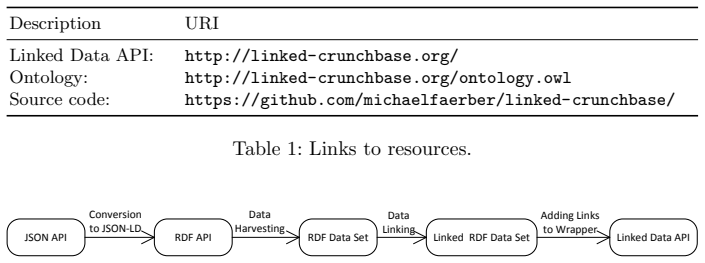
We developed and hosted a Linked Data API for Crunchbase and integrated sameAs links to other data sources. We then crawled RDF data based on this API to build a custom Crunchbase RDF knowledge graph. We created an RDF data set with over 347 million triples, including 781k people, 659k organizations, and 343k investments. Our Crunchbase Linked Data API is available online at http://linked-crunchbase.org.
What carries the argument
The Linked Data API for Crunchbase, which both serves the data in RDF and serves as the entry point for crawling the full knowledge graph.
If this is right
- The data becomes usable by anyone on the Web in machine-readable RDF format.
- sameAs links allow the dataset to be integrated with other linked open data sources.
- Standard SPARQL queries can now be run directly against the Crunchbase content.
- The knowledge graph can be kept current by re-crawling the API.
Where Pith is reading between the lines
- Other closed data platforms could follow the same API-plus-crawl pattern to increase their reach.
- The resulting graph could support large-scale studies of investment networks that combine Crunchbase with public financial or patent data.
- Downstream applications might treat the triples as a live, queryable index rather than a static dump.
Load-bearing premise
Crunchbase's internal data model can be mapped to RDF without significant loss of meaning or accuracy, and the resulting triples faithfully represent the original records.
What would settle it
A sample-by-sample comparison between the generated RDF triples and the original Crunchbase records that would reveal any systematic loss or distortion in the mapping.
Figures




read the original abstract
Crunchbase is an online platform collecting information about startups and technology companies, including attributes and relations of companies, people, and investments. Data contained in Crunchbase is, to a large extent, not available elsewhere, making Crunchbase to a unique data source. In this paper, we present how to bring Crunchbase to the Web of Data so that its data can be used in the machine-readable RDF format by anyone on the Web. First, we give insights into how we developed and hosted a Linked Data API for Crunchbase and how sameAs links to other data sources are integrated. Then, we present our method for crawling RDF data based on this API to build a custom Crunchbase RDF knowledge graph. We created an RDF data set with over 347 million triples, including 781k people, 659k organizations, and 343k investments. Our Crunchbase Linked Data API is available online at http://linked-crunchbase.org.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents the development of a Linked Data API for Crunchbase (a platform for startup, company, people, and investment data) together with a crawling procedure that produces an RDF knowledge graph containing over 347 million triples (781k people, 659k organizations, 343k investments). sameAs links to external sources are added, and both the API and a snapshot are made publicly available at http://linked-crunchbase.org.
Significance. If the conversion is faithful, the work supplies a large-scale, publicly accessible RDF resource for a domain whose data are otherwise unavailable in machine-readable linked form. The explicit release of both the live API and the 347 M-triple snapshot, together with cross-dataset links, constitutes a concrete contribution to the Linked Open Data cloud.
major comments (2)
- [Abstract (data conversion paragraph)] Abstract, paragraph on data conversion: the claim that the generated triples 'faithfully represent the original records' is unsupported because no ontology, property-mapping rules, or validation procedure is described.
- [Section on crawling RDF data] Section describing the crawling method: no information is supplied on deduplication logic, crawl completeness, handling of rate limits or pagination, or how the reported entity counts were obtained from the API responses.
minor comments (1)
- The abstract states that 'insights' into API development are given, yet the manuscript supplies no concrete technical details (endpoint structure, authentication, response formats) that would allow reproduction or independent use of the API.
Simulated Author's Rebuttal
We thank the referee for their thorough review and constructive comments. We address the two major comments point by point below.
read point-by-point responses
-
Referee: [Abstract (data conversion paragraph)] Abstract, paragraph on data conversion: the claim that the generated triples 'faithfully represent the original records' is unsupported because no ontology, property-mapping rules, or validation procedure is described.
Authors: We acknowledge that the abstract asserts faithful representation without describing the ontology, mapping rules, or validation. The revised manuscript will expand the data conversion section to detail the ontology (including vocabularies used), the explicit property-mapping rules from Crunchbase fields to RDF, and the validation steps performed. The abstract will be revised to qualify or remove the unsupported claim. revision: yes
-
Referee: [Section on crawling RDF data] Section describing the crawling method: no information is supplied on deduplication logic, crawl completeness, handling of rate limits or pagination, or how the reported entity counts were obtained from the API responses.
Authors: We agree that these implementation details are absent. The revised manuscript will add descriptions of the deduplication logic, how crawl completeness was evaluated, the handling of rate limits and pagination, and the precise method used to derive the reported entity counts from API responses. revision: yes
Circularity Check
No significant circularity
full rationale
This is a data engineering paper describing the construction of an RDF dataset and Linked Data API from an external commercial source (Crunchbase). The abstract and available text report a mapping process, crawling, and release of 347M triples with counts of entities, but contain no equations, fitted parameters, predictions, uniqueness theorems, or self-citations that could reduce any claim to its own inputs by construction. The central claim (public availability of the API and snapshot) is externally falsifiable and does not rely on internal derivation chains.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Crunchbase data can be represented faithfully in RDF without loss of key relations
- standard math Standard Linked Data practices (sameAs links, dereferenceable URIs) apply directly to company records
Reference graph
Works this paper leans on
-
[1]
In: Digital Startups in Transition Economies
Skala, A.: Characteristics of Startups. In: Digital Startups in Transition Economies. Springer (2019) 41–91
work page 2019
-
[2]
In: OECD Science, Technology and Industry Working Papers
Dalle, J.M., den Besten, M., Menon, C.: Using Crunchbase for economic and managerial research. In: OECD Science, Technology and Industry Working Papers. OECD Publishing (2017)
work page 2017
-
[3]
Master’s thesis, Aalto University (2016)
Meril¨ ainen, K.: Success factors in corporate startup accelerators. Master’s thesis, Aalto University (2016)
work page 2016
-
[4]
Ewens, M., Townsend, R.: Are Early Stage Investors Biased Against Women? Journal of Financial Economics (JFE) (2018)
work page 2018
-
[5]
Semantic Web 9(4) (2018) 505–515
F¨ arber, M., Menne, C., Harth, A.: A linked data wrapper for crunchbase. Semantic Web 9(4) (2018) 505–515
work page 2018
-
[6]
In: Proceedings of the 10th International Conference on Business Information Systems
Mochol, M., Wache, H., Nixon, L.: Improving the Accuracy of Job Search with Semantic Techniques. In: Proceedings of the 10th International Conference on Business Information Systems. BIS’07, Springer (2007) 301–313
work page 2007
-
[7]
In: Proceedings of the 13th Extended Semantic Web Conference
F¨ arber, M., Rettinger, A., Harth, A.: Towards Monitoring of Novel Statements in the News. In: Proceedings of the 13th Extended Semantic Web Conference. ESWC 2016, Springer (2016) 285–299
work page 2016
-
[8]
In: Proceedings of the 22nd International Conference on World Wide Web
Stadtm¨ uller, S., Speiser, S., Harth, A., Studer, R.: Data-Fu: A Language and an Interpreter for Interaction with Read/Write Linked Data. In: Proceedings of the 22nd International Conference on World Wide Web. WWW’13 (2013) 1225–1236
work page 2013
-
[9]
Semantic Web 5(3) (2014) 173–176
Janowicz, K., Hitzler, P., Adams, B., Kolas, D., Vardeman, C.: Five stars of Linked Data vocabulary use. Semantic Web 5(3) (2014) 173–176
work page 2014
-
[10]
In: Proceedings of the 4th International Conference on Consuming Linked Data
Harth, A., Knoblock, C.A., Stadtm¨ uller, S., Studer, R., Szekely, P.: On-the-fly Integration of Static and Dynamic Linked Data. In: Proceedings of the 4th International Conference on Consuming Linked Data. COLD’13 (2013) 1–12
work page 2013
-
[11]
In: Proceedings of the 15th International Conference on Informatics and Semiotics in Organisations
Lee, V., Goto, M., Hu, B., Naseer, A., Vandenbussche, P., Shakair, G., Rodrigues, E.M.: Exploiting Linked Data in Financial Engineering. In: Proceedings of the 15th International Conference on Informatics and Semiotics in Organisations. ICISO’14. (2014) 116–125
work page 2014
-
[12]
In: Proceedings of the 6th International AAAI Conference on Weblogs and Social Media
Xiang, G., Zheng, Z., Wen, M., Hong, J.I., Ros´ e, C.P., Liu, C.: A Supervised Approach to Predict Company Acquisition with Factual and Topic Features Using Profiles and News Articles on TechCrunch. In: Proceedings of the 6th International AAAI Conference on Weblogs and Social Media. ICWSM’12 (2012) 607–610
work page 2012
-
[13]
Internet Research 26(1) (2016) 74–100 15
Liang, Y.E., Yuan, S.D.: Predicting investor funding behavior using crunchbase social network features. Internet Research 26(1) (2016) 74–100 15
work page 2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.