DropAttention: A Regularization Method for Fully-Connected Self-Attention Networks
Pith reviewed 2026-05-24 16:19 UTC · model grok-4.3
The pith
DropAttention regularizes self-attention by randomly dropping attention weights to prevent co-adaptation of feature vectors.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors claim that randomly dropping attention weights in self-attention networks prevents different contextualized feature vectors from co-adapting, supplying a regularization method for fully-connected self-attention layers that improves performance and reduces overfitting on a wide range of tasks.
What carries the argument
DropAttention, a regularization technique that randomly drops elements of the attention weight matrix during training of self-attention layers.
If this is right
- DropAttention can be added to existing Transformer architectures without changing their core structure.
- It provides a direct analogue to dropout methods used in fully-connected, convolutional, and recurrent layers.
- Performance improves and overfitting decreases across a wide range of tasks when attention weights are regularized this way.
- The method addresses a gap in regularization specific to attention mechanisms.
Where Pith is reading between the lines
- The technique could be tested in attention-heavy models outside language processing, such as vision transformers.
- It might combine with standard output dropout to produce additive regularization effects.
- Attention-specific regularization may prove more efficient than applying dropout only after the attention layer.
Load-bearing premise
Randomly dropping attention weights will stop co-adaptation of contextualized feature vectors without harming the model's ability to learn useful long-range dependencies.
What would settle it
Training multiple Transformer models on standard benchmarks with and without DropAttention and finding that the version with DropAttention shows equal or higher overfitting rates and lower task performance would falsify the central claim.
Figures


read the original abstract
Variants dropout methods have been designed for the fully-connected layer, convolutional layer and recurrent layer in neural networks, and shown to be effective to avoid overfitting. As an appealing alternative to recurrent and convolutional layers, the fully-connected self-attention layer surprisingly lacks a specific dropout method. This paper explores the possibility of regularizing the attention weights in Transformers to prevent different contextualized feature vectors from co-adaption. Experiments on a wide range of tasks show that DropAttention can improve performance and reduce overfitting.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes DropAttention, a regularization technique that randomly drops elements of the attention weight matrix in fully-connected self-attention layers of Transformer models. The goal is to prevent co-adaptation among contextualized feature vectors. The central claim is that this method reduces overfitting and yields performance gains, supported by experiments across a range of tasks.
Significance. If the reported gains prove robust and reproducible, DropAttention would supply a lightweight, attention-specific regularization tool that complements existing dropout variants for recurrent and convolutional layers. Its value would lie in the empirical demonstration that targeted dropping of attention weights improves generalization without requiring architectural changes.
major comments (2)
- [§4] §4 (Experiments): the manuscript reports performance improvements on multiple tasks but supplies no implementation details on the dropout probability schedule, scaling factor applied to retained weights, or whether dropping occurs only at training time. These omissions make it impossible to evaluate whether the claimed benefit is reproducible or specific to the proposed method.
- [Tables 1-2] Table 1 and Table 2: no error bars, number of random seeds, or statistical significance tests are reported for the accuracy or perplexity deltas. Without these, the claim that DropAttention “can improve performance” cannot be distinguished from noise or from the effect of standard dropout applied elsewhere in the network.
minor comments (2)
- [§3] The notation for the attention matrix in §3 is introduced without an explicit equation linking the drop mask to the scaled dot-product; a short pseudocode block would clarify the forward pass.
- [Figure 1] Figure 1 caption does not state the dataset or layer depth used for the attention visualization, reducing interpretability.
Simulated Author's Rebuttal
We thank the referee for their detailed review and constructive comments on our paper. We address each major comment below and will revise the manuscript accordingly to improve clarity and reproducibility.
read point-by-point responses
-
Referee: [§4] §4 (Experiments): the manuscript reports performance improvements on multiple tasks but supplies no implementation details on the dropout probability schedule, scaling factor applied to retained weights, or whether dropping occurs only at training time. These omissions make it impossible to evaluate whether the claimed benefit is reproducible or specific to the proposed method.
Authors: We agree with the referee that these implementation details are essential for reproducibility. The original manuscript did not provide sufficient specifics on these aspects. In the revised version, we will add explicit descriptions in Section 4 regarding the dropout probability schedule used in our experiments, the scaling factor applied to the retained attention weights, and confirmation that the dropping is performed only at training time. This will ensure the method is fully reproducible and distinguishable from other dropout applications. revision: yes
-
Referee: [Tables 1-2] Table 1 and Table 2: no error bars, number of random seeds, or statistical significance tests are reported for the accuracy or perplexity deltas. Without these, the claim that DropAttention “can improve performance” cannot be distinguished from noise or from the effect of standard dropout applied elsewhere in the network.
Authors: The referee correctly identifies a limitation in our reporting. The original experiments were conducted with single runs without reporting variability. For the revision, we commit to performing additional experiments with at least 3-5 random seeds per task, reporting means and standard deviations as error bars in Tables 1 and 2, and conducting statistical significance tests (such as t-tests) to demonstrate that the observed improvements are statistically significant and not attributable to random variation or other dropout mechanisms. revision: yes
Circularity Check
No significant circularity
full rationale
The paper introduces DropAttention as an empirical regularization method for attention weights in Transformers, motivated by preventing co-adaptation of feature vectors. Its central claims rest on experimental results across tasks demonstrating performance gains and reduced overfitting. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the provided material that would reduce any result to its own inputs by construction. Prior dropout variants are referenced as background without load-bearing self-citations or uniqueness theorems imported from the authors' own work. The derivation chain is self-contained as an applied technique rather than a mathematical reduction.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 2 Pith papers
-
Explicit Dropout: Deterministic Regularization for Transformer Architectures
Explicit dropout reformulates stochastic dropout as deterministic loss penalties for Transformers, matching or exceeding standard performance with independent control per component.
-
Language models recognize dropout and Gaussian noise applied to their activations
Language models detect, localize, and distinguish dropout from Gaussian noise applied to their activations, often with high accuracy.
Reference graph
Works this paper leans on
-
[1]
Jimmy Lei Ba, Jamie Ryan Kiros, and Geoffrey E Hinton. Layer normalization. arXiv preprint arXiv:1607.06450,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
A large annotated corpus for learning natural language inference
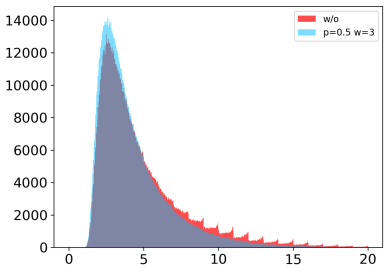
9 Figure 3: The histogram of largest attention weights distribution. x-axis represents the attention weights value multiplied by the sentence length, y-axis represents the number of corresponding attention weights. Model with DropAttention tends to allocate smaller attention weights compared to model without DropAttention. Samuel R Bowman, Gabor Angeli, C...
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
A Fast Unified Model for Parsing and Sentence Understanding
Samuel R Bowman, Jon Gauthier, Abhinav Rastogi, Raghav Gupta, Christopher D Manning, and Christopher Potts. A fast unified model for parsing and sentence understanding. arXiv preprint arXiv:1603.06021,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Improved Regularization of Convolutional Neural Networks with Cutout
Terrance DeVries and Graham W Taylor. Improved regularization of convolutional neural networks with cutout. arXiv preprint arXiv:1708.04552,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Xavier Gastaldi. Shake-shake regularization. arXiv preprint arXiv:1705.07485,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Zoneout: Regularizing RNNs by Randomly Preserving Hidden Activations
David Krueger, Tegan Maharaj, János Kramár, Mohammad Pezeshki, Nicolas Ballas, Nan Rosemary Ke, Anirudh Goyal, Yoshua Bengio, Aaron Courville, and Chris Pal. Zoneout: Regularizing rnns by randomly preserving hidden activations. arXiv preprint arXiv:1606.01305,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
FractalNet: Ultra-Deep Neural Networks without Residuals
Gustav Larsson, Michael Maire, and Gregory Shakhnarovich. Fractalnet: Ultra-deep neural networks without residuals. arXiv preprint arXiv:1605.07648,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Multi-Head Attention with Disagreement Regularization
Jian Li, Zhaopeng Tu, Baosong Yang, Michael R Lyu, and Tong Zhang. Multi-head attention with disagreement regularization. arXiv preprint arXiv:1810.10183,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
A Structured Self-attentive Sentence Embedding
Zhouhan Lin, Mo Feng, Yu, Bing Xiang, Bowen Zhou, and Yoshua Bengio. A structured self-attentive sentence embedding. arXiv preprint arXiv:1703.03130,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Scaling Neural Machine Translation
Myle Ott, Sergey Edunov, David Grangier, and Michael Auli. Scaling neural machine translation. CoRR, abs/1806.00187,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Recurrent Dropout without Memory Loss
Stanislau Semeniuta, Aliaksei Severyn, and Erhardt Barth. Recurrent dropout without memory loss. arXiv preprint arXiv:1603.05118,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Neural Machine Translation of Rare Words with Subword Units
Rico Sennrich, Barry Haddow, and Alexandra Birch. Neural machine translation of rare words with subword units. arXiv preprint arXiv:1508.07909,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Dropout: a simple way to prevent neural networks from overfitting
Nitish Srivastava, Geoffrey Hinton, Alex Krizhevsky, Ilya Sutskever, and Ruslan Salakhutdinov. Dropout: a simple way to prevent neural networks from overfitting. The Journal of Machine Learning Research, 15(1):1929–1958,
work page 1929
-
[14]
Document modeling with gated recurrent neural network for sentiment classification
Duyu Tang, Bing Qin, and Ting Liu. Document modeling with gated recurrent neural network for sentiment classification. In Proceedings of the 2015 conference on empirical methods in natural language processing, pages 1422–1432,
work page 2015
-
[15]
Shakedrop regularization for deep residual learning
Yoshihiro Yamada, Masakazu Iwamura, Takuya Akiba, and Koichi Kise. Shakedrop regularization for deep residual learning. arXiv preprint arXiv:1802.02375,
-
[16]
Multi-Task Cross-Lingual Sequence Tagging from Scratch
Zhilin Yang, Ruslan Salakhutdinov, and William Cohen. Multi-task cross-lingual sequence tagging from scratch. arXiv preprint arXiv:1603.06270,
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.