Pruning Federated Models through Loss Landscape Analysis and Client Agreement Scoring
Pith reviewed 2026-05-24 00:38 UTC · model grok-4.3
The pith
AutoFLIP prunes federated models by mapping the collective loss landscape through one-time client collaboration and then refining sub-networks via ongoing client agreement scoring.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
AutoFLIP performs a one-time federated loss exploration in which clients collaboratively construct a map of the collective loss landscape; this map then directs an adaptive pruning strategy that is continuously adjusted according to client agreement scores throughout subsequent training, thereby locating robust sub-networks from the start.
What carries the argument
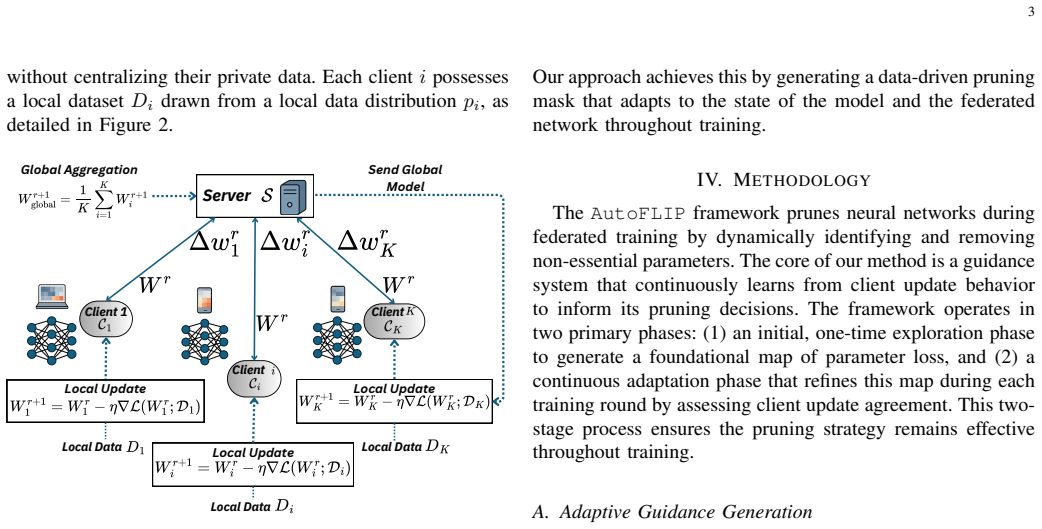
The AutoFLIP framework, whose core mechanism is the initial federated loss-landscape mapping followed by client-agreement-guided pruning.
If this is right
- Computational overhead drops by an average of 52 percent across tested settings.
- Communication costs fall by more than 65 percent while accuracy remains at state-of-the-art levels.
- Resource-constrained devices can host larger models without proportional increases in training expense.
- The same loss-landscape map serves as a stable reference for pruning choices made at any later training stage.
Where Pith is reading between the lines
- The same loss-exploration step could be reused to initialize other federated compression techniques beyond magnitude-based pruning.
- Client agreement scores might serve as a lightweight diagnostic for detecting when the global model has overfit to particular client subsets.
- If the loss map proves stable, periodic re-exploration could be omitted, further lowering the upfront cost.
Load-bearing premise
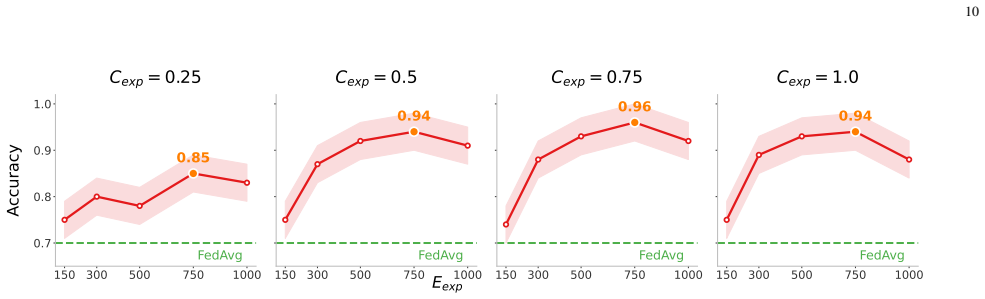
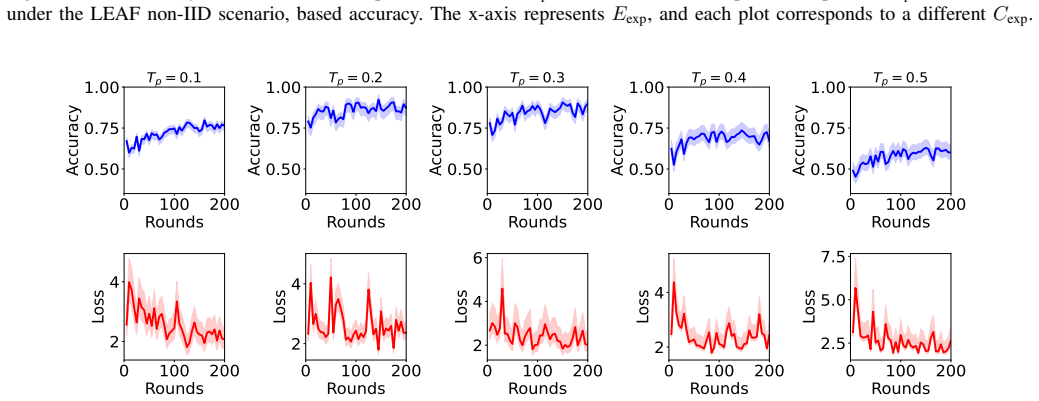
A single one-time federated loss exploration performed before main training produces a sufficiently accurate and stable map of the collective loss landscape to support effective pruning decisions across heterogeneous clients.
What would settle it
An experiment in which pruning decisions derived from the initial loss map produce measurably lower final accuracy than an unpruned baseline under the same non-IID client partitions would falsify the central claim.
Figures









read the original abstract
The practical deployment of Federated Learning (FL) on resource-constrained devices is fundamentally limited by the high cost of training large models and the instability caused by heterogeneous (non-IID) client data. Conventional pruning methods often treat data heterogeneity as a problem to be mitigated. In this work, we introduce a paradigm shift: we reframe client diversity as a feature to be harnessed. We propose AutoFLIP, a framework that begins not with training, but with a one-time federated loss exploration. During this phase, clients collaboratively build a map of the collective loss landscape, using their diverse data to reveal the problem's essential structure. This shared intelligence then guides an adaptive pruning strategy that is dynamically refined by client agreement throughout training. This approach allows AutoFLIP to identify robust and efficient sub-networks from the outset. Our extensive experiments show that AutoFLIP reduces computational overhead by an average of 52% and communication costs by over 65% while simultaneously achieving state-of-the-art accuracy in challenging non-IID settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes AutoFLIP, a federated learning pruning framework that performs a one-time federated loss exploration phase in which clients collaboratively construct a map of the collective loss landscape from their heterogeneous data. This shared map then guides an adaptive pruning strategy that is dynamically refined using client agreement scores throughout training. The authors claim that the method reduces computational overhead by an average of 52% and communication costs by over 65% while attaining state-of-the-art accuracy in challenging non-IID settings.
Significance. If the central claims hold, the work would be significant because it reframes client data heterogeneity as a source of useful structural information for pruning rather than solely a source of instability. The combination of loss-landscape exploration and client-agreement scoring offers a concrete mechanism for identifying robust sub-networks early, which could improve the practicality of large-model FL on edge devices.
major comments (1)
- [Abstract (paragraph describing the framework)] Abstract (paragraph describing the framework): The central premise that a single one-time federated loss exploration phase performed before main training yields a sufficiently accurate and stable collective loss landscape for guiding pruning decisions is load-bearing for the efficiency and accuracy claims. No quantitative evidence (landscape similarity metrics across training rounds, ablation on re-exploration frequency, or analysis of Hessian/gradient drift under non-IID conditions) is supplied to show that the initial map remains effective once local models begin to diverge. This directly affects whether the reported 52% compute and 65% communication reductions can be expected to persist.
minor comments (2)
- The abstract asserts quantitative gains and SOTA accuracy without describing the experimental protocol, baseline methods, number of runs, statistical tests, or error bars, making it impossible to judge whether the data support the claims.
- Clarify the precise definition and computation of the client agreement score and how it is used to update the pruning mask at each round.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the stability of the one-time federated loss exploration phase. We address the major comment below.
read point-by-point responses
-
Referee: [Abstract (paragraph describing the framework)] Abstract (paragraph describing the framework): The central premise that a single one-time federated loss exploration phase performed before main training yields a sufficiently accurate and stable collective loss landscape for guiding pruning decisions is load-bearing for the efficiency and accuracy claims. No quantitative evidence (landscape similarity metrics across training rounds, ablation on re-exploration frequency, or analysis of Hessian/gradient drift under non-IID conditions) is supplied to show that the initial map remains effective once local models begin to diverge. This directly affects whether the reported 52% compute and 65% communication reductions can be expected to persist.
Authors: We appreciate the referee identifying this as a load-bearing assumption. The manuscript's empirical results demonstrate that the reported efficiency gains (52% compute, 65% communication) and SOTA non-IID accuracy are achieved and maintained with the one-time exploration, as shown by the end-to-end training curves and final metrics across multiple datasets and non-IID partitions. These outcomes indicate that the initial collective map remains effective in practice. However, we agree that explicit quantitative validation of landscape stability would strengthen the claims. In the revised manuscript we will add (i) cosine similarity metrics between the initial loss landscape and gradients at later rounds, (ii) an ablation varying re-exploration frequency, and (iii) a brief analysis of gradient drift under the non-IID regimes studied. These additions will directly quantify how long the initial map remains useful. revision: yes
Circularity Check
No circularity; empirical framework with no load-bearing derivations
full rationale
The paper introduces AutoFLIP as an empirical pruning framework based on a one-time federated loss exploration phase followed by client-agreement-guided adaptation, with performance claims resting on experimental results rather than any mathematical derivation chain. No equations, fitted parameters renamed as predictions, self-definitional constructs, or self-citation load-bearing steps appear in the abstract or described methodology. The approach is self-contained as a practical method whose validity is asserted via external benchmarks and experiments, not by reducing outputs to inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
The roadmap to 6g: Ai empowered wireless networks,
K. B. Letaief, W. Chen, Y . Shi, J. Zhang, and Y .-J. A. Zhang, “The roadmap to 6g: Ai empowered wireless networks,”IEEE Communica- tions Magazine, vol. 57, no. 8, pp. 84–90, 2019
work page 2019
-
[2]
A vision of 6g wireless systems: Applications, trends, technologies, and open research problems,
W. Saad, M. Bennis, and M. Chen, “A vision of 6g wireless systems: Applications, trends, technologies, and open research problems,”IEEE Network, vol. 34, no. 3, pp. 134–142, 2020
work page 2020
-
[3]
Federated learning on non-iid data: A survey,
H. Zhu, J. Xu, S. Liu, and Y . Jin, “Federated learning on non-iid data: A survey,”Neurocomput., vol. 465, no. C, p. 371–390, Nov. 2021. [Online]. Available: https://doi.org/10.1016/j.neucom.2021.07.098
-
[4]
The future of digital health with federated learning,
N. Rieke, J. Hancox, W. Li, F. Milletar `ı, H. R. Roth, S. Albarqouni, S. Bakas, M. N. Galtier, B. A. Landman, K. Maier-Hein, S. Ourselin, M. Sheller, R. M. Summers, A. Trask, D. Xu, M. Baust, and M. J. Cardoso, “The future of digital health with federated learning,”npj Digital Medicine, vol. 3, no. 1, p. 119, Sep 2020
work page 2020
-
[5]
Advances and open problems in federated learning,
P. e. a. Kairouz, “Advances and open problems in federated learning,” Hanover, MA, USA, p. 1–210, Jun. 2021. [Online]. Available: https://doi.org/10.1561/2200000083
-
[6]
K. Hoffpauir, J. Simmons, N. Schmidt, R. Pittala, I. Briggs, S. Makani, and Y . Jararweh, “A survey on edge intelligence and lightweight machine learning support for future applications and services,”J. Data and Information Quality, vol. 15, no. 2, Jun. 2023. [Online]. Available: https://doi.org/10.1145/3581759
-
[7]
A survey on intent-based networking,
A. Leivadeas and M. Falkner, “A survey on intent-based networking,” Commun. Surveys Tuts., vol. 25, no. 1, p. 625–655, Jan. 2023. [Online]. Available: https://doi.org/10.1109/COMST.2022.3215919
-
[8]
D. Haj Hussein and M. Ibnkahla, “Toward intelligent intent-based network slicing for iot systems: Enabling technologies, challenges, and vision,”IEEE Transactions on Network and Service Management, vol. 22, no. 4, pp. 3480–3495, 2025
work page 2025
-
[9]
Skeletonization: A technique for trimming the fat from a network via relevance assessment,
M. C. Mozer and P. Smolensky, “Skeletonization: A technique for trimming the fat from a network via relevance assessment,” inAdvances in Neural Information Processing Systems, D. Touretzky, Ed., vol. 1. Morgan-Kaufmann, 1988
work page 1988
-
[10]
Y . LeCun, J. Denker, and S. Solla, “Optimal brain damage,” inAdvances in Neural Information Processing Systems, D. Touretzky, Ed., vol. 2. Morgan-Kaufmann, 1989. [Online]. Available: https://proceedings.neurips.cc/paper files/paper/ 1989/file/6c9882bbac1c7093bd25041881277658-Paper.pdf
work page 1989
-
[11]
S. Han, H. Mao, and W. J. Dally, “Deep compression: Compressing deep neural network with pruning, trained quantization and huffman coding,”
-
[12]
Available: https://api.semanticscholar.org/CorpusID: 2134321
[Online]. Available: https://api.semanticscholar.org/CorpusID: 2134321
-
[13]
Pruning convolutional neural networks for resource efficient inference,
P. Molchanov, S. Tyree, T. Karras, T. Aila, and J. Kautz, “Pruning convolutional neural networks for resource efficient inference,” in International Conference on Learning Representations, 2017. [Online]. Available: https://openreview.net/forum?id=SJGCiw5gl
work page 2017
-
[14]
Gate decorator: Global filter pruning method for accelerating deep convolutional neural networks,
Z. You, K. Yan, J. Ye, M. Ma, and P. Wang, “Gate decorator: Global filter pruning method for accelerating deep convolutional neural networks,” inAdvances in Neural Information Processing Systems, H. Wallach, H. Larochelle, A. Beygelzimer, F. d'Alch ´e-Buc, E. Fox, and R. Garnett, Eds., vol. 32. Curran Associates, Inc.,
-
[15]
[Online]. Available: https://proceedings.neurips.cc/paper files/ paper/2019/file/b51a15f382ac914391a58850ab343b00-Paper.pdf
work page 2019
-
[16]
Hrank: Filter pruning using high-rank feature map,
M. Lin, R. Ji, Y . Wang, Y . Zhang, B. Zhang, Y . Tian, and L. Shao, “Hrank: Filter pruning using high-rank feature map,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2020
work page 2020
-
[17]
SNIP: SINGLE-SHOT NETWORK PRUNING BASED ON CONNECTION SENSITIVITY ,
N. Lee, T. Ajanthan, and P. Torr, “SNIP: SINGLE-SHOT NETWORK PRUNING BASED ON CONNECTION SENSITIVITY ,” inInterna- tional Conference on Learning Representations, 2019
work page 2019
-
[18]
Rigging the lottery: Making all tickets winners,
U. Evci, T. Gale, J. Menick, P. S. C. Rivadeneira, and E. Elsen, “Rigging the lottery: Making all tickets winners,” inInternational Conference of Machine Learning, 2020
work page 2020
-
[19]
Communication-efficient learning of deep networks from decentralized data,
H. B. McMahan, E. Moore, D. Ramage, S. Hampson, and B. A. y Arcas, “Communication-efficient learning of deep networks from decentralized data,” 2023
work page 2023
-
[20]
Model Pruning Enables Efficient Federated Learning on Edge Devices,
Y . Jiang, S. Wang, V . Valls, B. J. Ko, W.-H. Lee, K. K. Leung, and L. Tassiulas, “Model Pruning Enables Efficient Federated Learning on Edge Devices,”IEEE Transactions on Neural Networks and Learning Systems, vol. 34, no. 12, pp. 10 374–10 386, Dec. 2023
work page 2023
-
[21]
Efficient federated learning on resource- constrained edge devices based on model pruning,
T. Wu, C. Song, and P. Zeng, “Efficient federated learning on resource- constrained edge devices based on model pruning,”Complex & Intelli- gent Systems, vol. 9, no. 6, pp. 6999–7013, 2023
work page 2023
-
[22]
FedMask: Jointly learning to trust and mask for federated learning,
G. Gong, X. Liu, Y . Zhang, L. Liu, and Y . Yang, “FedMask: Jointly learning to trust and mask for federated learning,” inProceedings of the 29th ACM International Conference on Multimedia, 2021, pp. 3266– 3274
work page 2021
-
[23]
Importance estimation for neural network pruning,
P. Molchanov, A. Mallya, S. Tyree, I. Frosio, and J. Kautz, “Importance estimation for neural network pruning,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019, pp. 11 264–11 272
work page 2019
-
[24]
Global sparse momentum sgd for pruning very deep neural networks,
X. Ding, g. ding, X. Zhou, Y . Guo, J. Han, and J. Liu, “Global sparse momentum sgd for pruning very deep neural networks,” inAdvances in Neural Information Processing Systems, H. Wallach, H. Larochelle, A. Beygelzimer, F. d'Alch ´e-Buc, E. Fox, and R. Garnett, Eds., vol. 32. Curran Associates, Inc., 2019. [Online]. Available: https://proceedings.neurips....
work page 2019
-
[25]
Universal statistics of fisher information in deep neural networks: Mean field approach,
R. Karakida, S. Akaho, and S.-i. Amari, “Universal statistics of fisher information in deep neural networks: Mean field approach,” inProceedings of the Twenty-Second International Conference on Artificial Intelligence and Statistics, ser. Proceedings of Machine Learning Research, K. Chaudhuri and M. Sugiyama, Eds., vol. 89. PMLR, 16–18 Apr 2019, pp. 1032–...
work page 2019
-
[26]
Federated loss explo- ration for improved convergence on non-iid data,
C. Intern `o, M. Olhofer, Y . Jin, and B. Hammer, “Federated loss explo- ration for improved convergence on non-iid data,” in2024 International Joint Conference on Neural Networks (IJCNN), 2024, pp. 1–8
work page 2024
-
[27]
S. Thrun and L. Pratt,Learning to Learn: Introduction and Overview. Boston, MA: Springer US, 1998, pp. 3–17
work page 1998
-
[28]
Model-agnostic meta-learning for fast adaptation of deep networks,
C. Finn, P. Abbeel, and S. Levine, “Model-agnostic meta-learning for fast adaptation of deep networks,” inProceedings of the 34th International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, D. Precup and Y . W. Teh, Eds., vol. 70. PMLR, 06–11 Aug 2017, pp. 1126–1135
work page 2017
-
[29]
The need for biases in learning generalizations,
T. M. Mitchell, “The need for biases in learning generalizations,” 2007
work page 2007
-
[30]
S. Hochreiter and J. Schmidhuber, “Flat minima,”Neural Comput., vol. 9, no. 1, p. 1–42, Jan. 1997
work page 1997
-
[31]
D. Nikoli ´c, D. Andri ´c, and V . Nikoli´c, “Guided transfer learning,” 2023
work page 2023
-
[32]
K. Li, D. Nikoli ´c, V . Nikoli ´c, D. Andri ´c, L. M. Sanders, and S. V . Costes, “Using guided transfer learning to predispose ai agent to learn efficiently from small rna-sequencing datasets,” 2023
work page 2023
-
[33]
Connecting low-loss subspace for personalized federated learning,
S.-J. Hahn, M. Jeong, and J. Lee, “Connecting low-loss subspace for personalized federated learning,” inProceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. ACM, aug 2022
work page 2022
-
[34]
Leaf: A benchmark for federated settings,
S. Caldas, S. M. K. Duddu, P. Wu, T. Li, J. Kone ˇcn´y, H. B. McMahan, V . Smith, and A. Talwalkar, “Leaf: A benchmark for federated settings,” 2019
work page 2019
-
[35]
L. Zhu, “Thop: Pytorch-opcounter,”THOP: PyTorch-OpCounter, 2022
work page 2022
-
[36]
Federated learning with differential privacy: Algorithms and performance analysis,
K. Wei, J. Li, M. Ding, C. Ma, H. H. Yang, F. Farhad, S. Jin, T. Q. S. Quek, and H. V . Poor, “Federated learning with differential privacy: Algorithms and performance analysis,” 2019
work page 2019
-
[37]
PPFLex: Securing non-IID optimization in federated learning via MPC,
N. Yuca, C. Intern `o, N. Matyunin, M. Olhofer, B. Hammer, and S. Katzenbeisser, “PPFLex: Securing non-IID optimization in federated learning via MPC,” in1st Workshop on Federated Learning for Critical Applications, 2026. [Online]. Available: https: //openreview.net/forum?id=PTdCBanvv3
work page 2026
-
[38]
On the opportunities and risks of foundation models,
R. B. et al., “On the opportunities and risks of foundation models,”
-
[39]
On the Opportunities and Risks of Foundation Models
[Online]. Available: https://arxiv.org/abs/2108.07258
work page internal anchor Pith review Pith/arXiv arXiv
-
[40]
Federatedfactory: Generative one-shot learning for extremely non-iid distributed scenarios,
A. Moleri, C. Intern `o, A. Raza, M. Olhofer, D. Klindt, F. Stella, and B. Hammer, “Federatedfactory: Generative one-shot learning for extremely non-iid distributed scenarios,” 2026. [Online]. Available: https://arxiv.org/abs/2603.16370
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.