SVGFusion: A VAE-Diffusion Transformer for Vector Graphic Generation
Pith reviewed 2026-05-23 07:19 UTC · model grok-4.3
The pith
SVGFusion fuses SVG code and rendered pixels in a VAE then diffuses the result to produce editable text-aligned vector graphics.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a Vector-Pixel Fusion VAE jointly encoding SVG code and its rendered image learns a latent space rich enough for a Vector Space Diffusion Transformer to perform iterative refinement, and that adding Rendering Sequence Modeling ensures correct object layering and occlusion, yielding high-quality editable SVGs that remain strictly aligned with the input text on a 240k-example dataset.
What carries the argument
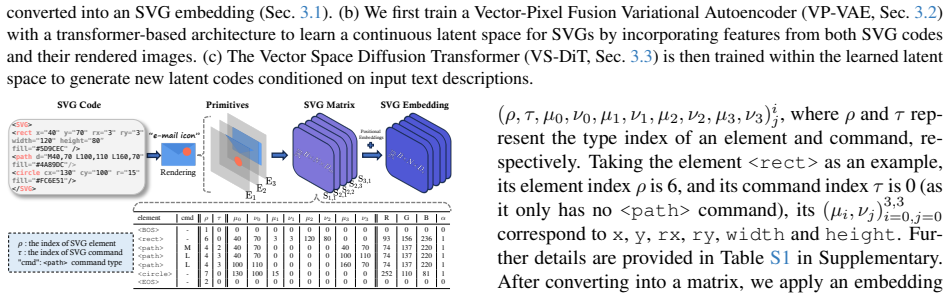
The Vector-Pixel Fusion Variational Autoencoder (VP-VAE) that jointly encodes SVG code and its rendered image to produce the latent space operated on by the diffusion transformer.
If this is right
- The diffusion process produces globally coherent compositions through iterative denoising rather than one-shot token prediction.
- Rendering Sequence Modeling enforces correct depth ordering so overlapping objects appear in the intended visual sequence.
- Outputs remain fully editable in standard vector tools because the model emits native SVG commands rather than raster approximations.
- The method scales to a 240k-example corpus of human-designed SVGs and reports state-of-the-art alignment metrics.
- The same architecture avoids both the error accumulation of flat token sequences and the slow per-example optimization of earlier approaches.
Where Pith is reading between the lines
- The joint code-image latent space may transfer editing operations learned on pixels back into editable vector commands more reliably than pure code models.
- Because the VAE sees both modalities, the same framework could be tested on other hybrid representations such as LaTeX or HTML that also have visual renderings.
- Layer-order modeling might generalize to tasks requiring consistent depth ordering in 3-D scene descriptions generated from text.
- If the latent space proves stable, downstream applications could add user-specified constraints directly in the diffusion stage without retraining.
Load-bearing premise
Jointly encoding SVG code together with its rendered pixel image creates a latent space from which diffusion can recover coherent, layered, and editable vector output.
What would settle it
Human or automatic evaluations showing that SVGFusion outputs contain more structural mismatches with the text prompt or lose editability compared with strong LLM-based baselines on the same prompts.
Figures





read the original abstract
Generating high-quality Scalable Vector Graphics (SVGs) from text remains a significant challenge. Existing LLM-based models that generate SVG code as a flat token sequence struggle with poor structural understanding and error accumulation, while optimization-based methods are slow and yield uneditable outputs. To address these limitations, we introduce SVGFusion, a unified framework that adapts the VAE-diffusion architecture to bridge the dual code-visual nature of SVGs. Our model features two core components: a Vector-Pixel Fusion Variational Autoencoder (VP-VAE) that learns a perceptually rich latent space by jointly encoding SVG code and its rendered image, and a Vector Space Diffusion Transformer (VS-DiT) that achieves globally coherent compositions through iterative refinement. Furthermore, this architecture is enhanced by a Rendering Sequence Modeling strategy, which ensures accurate object layering and occlusion. Evaluated on our novel SVGX-Dataset comprising 240k human-designed SVGs, SVGFusion establishes a new state-of-the-art, generating high-quality, editable SVGs that are strictly semantically aligned with the input text.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SVGFusion, a VAE-diffusion framework for text-to-SVG generation. It features a Vector-Pixel Fusion VAE (VP-VAE) that jointly encodes SVG code and rendered images to produce a latent space, a Vector Space Diffusion Transformer (VS-DiT) for iterative refinement of globally coherent compositions, and Rendering Sequence Modeling to handle layering and occlusion. The model is trained and evaluated on the new SVGX-Dataset of 240k human-designed SVGs and claims to achieve state-of-the-art results in generating high-quality, editable SVGs that are strictly semantically aligned with input text.
Significance. If the empirical claims hold, the work would offer a meaningful step forward in text-conditioned vector graphics synthesis by explicitly bridging the code and visual modalities of SVGs within a single latent space and diffusion process. The joint encoding strategy and sequence modeling for occlusion are conceptually well-motivated relative to prior LLM token-sequence or optimization-based baselines.
major comments (2)
- [Abstract] Abstract: The central claim that SVGFusion 'establishes a new state-of-the-art' is unsupported by any reported quantitative metrics, baseline comparisons, ablation studies, or error analysis. This absence makes the performance assertion impossible to evaluate and is load-bearing for the paper's primary contribution.
- [Abstract] Abstract (VP-VAE description): The assertion that the Vector-Pixel Fusion VAE 'learns a perceptually rich latent space by jointly encoding SVG code and its rendered image' is presented without any supporting reconstruction loss values, latent-space alignment metrics, interpolation results, or ablation (e.g., pixel branch removed) demonstrating that the fusion step improves semantic fidelity or structural coherence for the downstream VS-DiT. This is the least-secured link between architecture and claimed performance.
Simulated Author's Rebuttal
We thank the referee for these targeted comments on the abstract. We agree that the abstract must be revised to ensure all performance and architectural claims are directly supported by evidence reported in the manuscript, and we will make the necessary changes.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that SVGFusion 'establishes a new state-of-the-art' is unsupported by any reported quantitative metrics, baseline comparisons, ablation studies, or error analysis. This absence makes the performance assertion impossible to evaluate and is load-bearing for the paper's primary contribution.
Authors: We accept this criticism. The current abstract states the SOTA claim without embedding the supporting numbers or comparisons that appear later in the paper. In the revised version we will either (a) insert concise quantitative results (e.g., key FID, CLIP-score, or editability metrics versus the strongest baselines) or (b) qualify the claim to reflect exactly what the experiments demonstrate. This change will be made. revision: yes
-
Referee: [Abstract] Abstract (VP-VAE description): The assertion that the Vector-Pixel Fusion VAE 'learns a perceptually rich latent space by jointly encoding SVG code and its rendered image' is presented without any supporting reconstruction loss values, latent-space alignment metrics, interpolation results, or ablation (e.g., pixel branch removed) demonstrating that the fusion step improves semantic fidelity or structural coherence for the downstream VS-DiT. This is the least-secured link between architecture and claimed performance.
Authors: We agree that the abstract's phrasing for the VP-VAE currently lacks direct evidentiary anchors. The manuscript contains reconstruction losses, alignment metrics, and ablations for the fusion design in Sections 3 and 4; however, these are not referenced in the abstract. We will revise the abstract sentence to either cite the relevant quantitative improvements or adopt more measured language that does not overstate what is shown. This revision will be incorporated. revision: yes
Circularity Check
No significant circularity; derivation is architectural description without self-referential reductions.
full rationale
The paper introduces SVGFusion via VP-VAE joint encoding and VS-DiT refinement, evaluated on SVGX-Dataset. The abstract and description contain no equations, fitted parameters, or predictions that reduce to inputs by construction. No self-citation load-bearing steps, uniqueness theorems, or ansatz smuggling are present. The central claim rests on the proposed architecture and external evaluation rather than any definitional loop or renamed known result. This qualifies as self-contained with score 0.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel (J uniqueness) unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
VP-VAE ... jointly encoding SVG code and its rendered image ... Rendering Sequence Modeling strategy ... VS-DiT ... diffusion process in the latent space
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat (8-tick / orbit structure) unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
N = 1024 ... incremental accumulation of SVG codes ... progressive sequence of drawing steps
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
no reconstruction loss, latent interpolation results, or ablation showing that removing the pixel branch degrades semantic fidelity
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 7 Pith papers
-
VAnim: Rendering-Aware Sparse State Modeling for Structure-Preserving Vector Animation
VAnim creates open-domain text-to-SVG animations via sparse state updates on a persistent DOM tree, identification-first planning, and rendering-aware RL with a new 134k-example benchmark.
-
Render-in-the-Loop: Vector Graphics Generation via Visual Self-Feedback
Render-in-the-Loop reformulates SVG generation as a step-wise visual-context-aware process using self-feedback from rendered intermediate states, VSF training, and RaV inference to outperform baselines on MMSVGBench f...
-
mEOL: Training-Free Instruction-Guided Multimodal Embedder for Vector Graphics and Image Retrieval
mEOL creates aligned embeddings for text, images, and SVGs using instruction-guided MLLM one-word summaries and semantic SVG rewriting, outperforming baselines on a new text-to-SVG retrieval benchmark.
-
LottieGPT: Tokenizing Vector Animation for Autoregressive Generation
LottieGPT tokenizes Lottie animations into compact sequences and fine-tunes Qwen-VL to autoregressively generate coherent vector animations from natural language or visual prompts, outperforming prior SVG models.
-
Hierarchical SVG Tokenization: Learning Compact Visual Programs for Scalable Vector Graphics Modeling
HiVG introduces hierarchical SVG tokenization with atomic and segment tokens plus HMN initialization to enable more efficient and stable autoregressive generation of vector graphics programs.
-
Stroke of Surprise: Progressive Semantic Illusions in Vector Sketching
Stroke of Surprise is a framework that generates vector sketches undergoing semantic transformation from one concept to another by adding strokes, using dual-branch SDS and overlay loss for optimization.
-
Reason-SVG: Enhancing Structured Reasoning for Vector Graphics Generation with Reinforcement Learning
Reason-SVG adds a Drawing-with-Thought reasoning stage and GRPO-based reinforcement learning with a hybrid reward to improve LLM and VLM performance on accurate SVG generation.
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report. arXiv preprint arXiv:2303.08774, 2023. 7
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Anthropic. Claude 3.5 sonnet. https : / / www . anthropic.com/news/claude- 3- 5- sonnet ,
-
[3]
All are worth words: A vit backbone for diffusion models
Fan Bao, Shen Nie, Kaiwen Xue, Yue Cao, Chongxuan Li, Hang Su, and Jun Zhu. All are worth words: A vit backbone for diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 22669–22679, 2023. 3
work page 2023
-
[4]
Deepsvg: A hierarchical genera- tive network for vector graphics animation
Alexandre Carlier, Martin Danelljan, Alexandre Alahi, and Radu Timofte. Deepsvg: A hierarchical genera- tive network for vector graphics animation. Advances in Neural Information Processing Systems (NeurIPS) , 33: 16351–16361, 2020. 2, 3, 4, 6, 14, 16
work page 2020
-
[5]
Pixart-$ \alpha$: Fast training of diffusion transformer for photorealistic text- to-image synthesis
Junsong Chen, Jincheng YU, Chongjian GE, Lewei Yao, Enze Xie, Zhongdao Wang, James Kwok, Ping Luo, Huchuan Lu, and Zhenguo Li. Pixart-$ \alpha$: Fast training of diffusion transformer for photorealistic text- to-image synthesis. In The Twelfth International Confer- ence on Learning Representations (ICLR), 2024. 6
work page 2024
-
[6]
FIGR: Few-shot Image Generation with Reptile
Louis Clou ˆatre and Marc Demers. Figr: Few- shot image generation with reptile. arXiv preprint arXiv:1901.02199, 2019. 3
work page internal anchor Pith review Pith/arXiv arXiv 1901
-
[7]
Imagenet: A large-scale hierarchical im- age database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical im- age database. In 2009 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 248–255,
work page 2009
-
[8]
Diffusion mod- els beat gans on image synthesis
Prafulla Dhariwal and Alexander Nichol. Diffusion mod- els beat gans on image synthesis. Advances in neural in- formation processing systems (NeurIPS), 34:8780–8794,
-
[9]
CLIP- Draw: Exploring text-to-drawing synthesis through language-image encoders
Kevin Frans, Lisa Soros, and Olaf Witkowski. CLIP- Draw: Exploring text-to-drawing synthesis through language-image encoders. In Advances in Neural Infor- mation Processing Systems (NeurIPS), 2022. 2, 3, 6, 7
work page 2022
-
[10]
Google. Noto emoji fonts. https://github.com/ googlefonts/noto-emoji, 2014. 3, 6, 12
work page 2014
-
[11]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reason- ing capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948, 2025. 7
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Animatediff: Animate your personalized text-to-image diffusion models without specific tuning
Yuwei Guo, Ceyuan Yang, Anyi Rao, Zhengyang Liang, Yaohui Wang, Yu Qiao, Maneesh Agrawala, Dahua Lin, and Bo Dai. Animatediff: Animate your personalized text-to-image diffusion models without specific tuning. In The Twelfth International Conference on Learning Representations (ICLR), 2024. 3
work page 2024
-
[13]
A neural representation of sketch drawings
David Ha and Douglas Eck. A neural representation of sketch drawings. In International Conference on Learn- ing Representations (ICLR), 2018. 2, 3
work page 2018
-
[14]
Gans trained by a two time-scale update rule converge to a local nash equilibrium
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium. Advances in neural information processing systems (NeurIPS), 30, 2017. 6
work page 2017
-
[15]
Classifier-Free Diffusion Guidance
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance. arXiv preprint arXiv:2207.12598, 2022. 3, 6
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[16]
Denoising diffusion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. In Advances in Neural Information Processing Systems (NeurIPS), pages 6840– 6851, 2020. 3
work page 2020
-
[17]
Jonathan Ho, Tim Salimans, Alexey Gritsenko, William Chan, Mohammad Norouzi, and David J Fleet. Video diffusion models. Advances in Neural Information Pro- cessing Systems (NeurIPS), 35:8633–8646, 2022. 3
work page 2022
-
[18]
Supersvg: Superpixel- based scalable vector graphics synthesis
Teng Hu, Ran Yi, Baihong Qian, Jiangning Zhang, Paul L Rosin, and Yu-Kun Lai. Supersvg: Superpixel- based scalable vector graphics synthesis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 24892–24901, 2024. 3
work page 2024
-
[19]
Word-as-image for seman- tic typography
Shir Iluz, Yael Vinker, Amir Hertz, Daniel Berio, Daniel Cohen-Or, and Ariel Shamir. Word-as-image for seman- tic typography. ACM Transactions on Graphics (TOG), 42(4), 2023. 6, 7
work page 2023
-
[20]
Vectorfusion: Text-to-svg by abstracting pixel-based diffusion models
Ajay Jain, Amber Xie, and Pieter Abbeel. Vectorfusion: Text-to-svg by abstracting pixel-based diffusion models. In Proceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition (CVPR), 2023. 2, 3, 6, 7
work page 2023
-
[21]
Differentiable vector graphics rasterization for editing and learning
Tzu-Mao Li, Michal Luk ´aˇc, Gharbi Micha ¨el, and Jonathan Ragan-Kelley. Differentiable vector graphics rasterization for editing and learning. ACM Transactions on Graphics (TOG), 39(6):193:1–193:15, 2020. 2, 3, 7
work page 2020
-
[22]
Sora: A Review on Background, Technology, Limitations, and Opportunities of Large Vision Models
Yixin Liu, Kai Zhang, Yuan Li, Zhiling Yan, Chujie Gao, Ruoxi Chen, Zhengqing Yuan, Yue Huang, Hanchi Sun, Jianfeng Gao, et al. Sora: A review on background, technology, limitations, and opportunities of large vision models. arXiv preprint arXiv:2402.17177, 2024. 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
A learned representation for scalable vector graphics
Raphael Gontijo Lopes, David Ha, Douglas Eck, and Jonathon Shlens. A learned representation for scalable vector graphics. In Proceedings of the IEEE/CVF Inter- national Conference on Computer Vision (ICCV) , 2019. 3, 6
work page 2019
-
[24]
Dpm-solver: A fast ode solver for diffusion probabilistic model sampling in around 10 steps
Cheng Lu, Yuhao Zhou, Fan Bao, Jianfei Chen, Chongx- uan Li, and Jun Zhu. Dpm-solver: A fast ode solver for diffusion probabilistic model sampling in around 10 steps. Advances in Neural Information Processing Sys- tems (NeurIPS), 35:5775–5787, 2022. 6, 12 9
work page 2022
-
[25]
Sit: Exploring flow and diffusion-based genera- tive models with scalable interpolant transformers
Nanye Ma, Mark Goldstein, Michael S Albergo, Nicholas M Boffi, Eric Vanden-Eijnden, and Saining Xie. Sit: Exploring flow and diffusion-based genera- tive models with scalable interpolant transformers. In Proceedings of the European Conference on Computer Vision (ECCV), 2024. 3
work page 2024
-
[26]
Towards layer-wise image vectorization
Xu Ma, Yuqian Zhou, Xingqian Xu, Bin Sun, Valerii Filev, Nikita Orlov, Yun Fu, and Humphrey Shi. Towards layer-wise image vectorization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 16314–16323, 2022. 3, 7
work page 2022
-
[27]
Microsoft. Fluent emoji. https://github.com/ microsoft/fluentui-emoji, 2021. 6, 12
work page 2021
-
[28]
Im- proved denoising diffusion probabilistic models
Alexander Quinn Nichol and Prafulla Dhariwal. Im- proved denoising diffusion probabilistic models. In International conference on machine learning (ICLR) , pages 8162–8171, 2021. 3
work page 2021
-
[29]
GLIDE: Towards pho- torealistic image generation and editing with text-guided diffusion models
Alexander Quinn Nichol, Prafulla Dhariwal, Aditya Ramesh, Pranav Shyam, Pamela Mishkin, Bob Mcgrew, Ilya Sutskever, and Mark Chen. GLIDE: Towards pho- torealistic image generation and editing with text-guided diffusion models. In Proceedings of the 39th Interna- tional Conference on Machine Learning (ICML) , pages 16784–16804, 2022. 3
work page 2022
-
[30]
OpenAI. Introducing chatgpt. https://openai. com/index/chatgpt/, 2023. 12
work page 2023
-
[31]
Maxime Oquab, Timoth ´ee Darcet, Th ´eo Moutakanni, Huy V . V o, Marc Szafraniec, Vasil Khalidov, Pierre Fer- nandez, Daniel HAZIZA, Francisco Massa, Alaaeldin El-Nouby, Mido Assran, Nicolas Ballas, Wojciech Galuba, Russell Howes, Po-Yao Huang, Shang-Wen Li, Ishan Misra, Michael Rabbat, Vasu Sharma, Gabriel Synnaeve, Hu Xu, Herve Jegou, Julien Mairal, Pat...
work page 2024
-
[32]
Scalable diffu- sion models with transformers
William Peebles and Saining Xie. Scalable diffu- sion models with transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 4195–4205, 2023. 2, 3, 6, 8
work page 2023
-
[33]
SDXL: Improving latent diffu- sion models for high-resolution image synthesis
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas M ¨uller, Joe Penna, and Robin Rombach. SDXL: Improving latent diffu- sion models for high-resolution image synthesis. In The Twelfth International Conference on Learning Represen- tations (ICLR), 2024. 3
work page 2024
-
[34]
Ben Poole, Ajay Jain, Jonathan T. Barron, and Ben Mildenhall. Dreamfusion: Text-to-3d using 2d diffusion. In The Eleventh International Conference on Learning Representations (ICLR), 2023. 3
work page 2023
-
[35]
Learning transferable visual models from natural lan- guage supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sas- try, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural lan- guage supervision. In International Conference on Ma- chine Learning (ICML), pages 8748–8763. PMLR, 2021. 2, 3, 6, 7
work page 2021
-
[36]
Hierarchical Text-Conditional Image Generation with CLIP Latents
Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen. Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:2204.06125, 2022. 3
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[37]
Im2vec: Synthesizing vector graph- ics without vector supervision
Pradyumna Reddy, Michael Gharbi, Michal Lukac, and Niloy J Mitra. Im2vec: Synthesizing vector graph- ics without vector supervision. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 7342–7351, 2021. 3
work page 2021
-
[38]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj¨orn Ommer. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 10684–10695, 2022. 2, 3, 6, 7
work page 2022
-
[39]
Photorealistic text-to-image diffusion models with deep language understanding
Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily L Denton, Kamyar Ghasemipour, Raphael Gontijo Lopes, Burcu Karagol Ayan, Tim Sali- mans, et al. Photorealistic text-to-image diffusion models with deep language understanding. In Advances in Neu- ral Information Processing Systems (NeurIPS) , pages 36479–36494, 2022. 3
work page 2022
-
[40]
Christoph Schuhmann. Improved aesthetic predictor. https : / / github . com / christophschuhmann / improved - aesthetic-predictor, 2022. 6
work page 2022
-
[41]
Make-a-video: Text-to-video generation without text-video data
Uriel Singer, Adam Polyak, Thomas Hayes, Xi Yin, Jie An, Songyang Zhang, Qiyuan Hu, Harry Yang, Oron Ashual, Oran Gafni, Devi Parikh, Sonal Gupta, and Yaniv Taigman. Make-a-video: Text-to-video generation without text-video data. In The Eleventh International Conference on Learning Representations (ICLR) , 2023. 3
work page 2023
-
[42]
Deep unsupervised learning using nonequilibrium thermodynamics
Jascha Sohl-Dickstein, Eric Weiss, Niru Mah- eswaranathan, and Surya Ganguli. Deep unsupervised learning using nonequilibrium thermodynamics. In Proceedings of the International Conference on Machine Learning (ICML), pages 2256–2265, 2015. 3
work page 2015
-
[43]
De- noising diffusion implicit models
Jiaming Song, Chenlin Meng, and Stefano Ermon. De- noising diffusion implicit models. In International Con- ference on Learning Representations (ICLR), 2021. 12
work page 2021
-
[44]
Generative modeling by estimating gradients of the data distribution
Yang Song and Stefano Ermon. Generative modeling by estimating gradients of the data distribution. InAdvances in Neural Information Processing Systems (NeurIPS) , 2019
work page 2019
-
[45]
Score- based generative modeling through stochastic differential equations
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score- based generative modeling through stochastic differential equations. In International Conference on Learning Rep- resentations (ICLR), 2021. 3
work page 2021
-
[46]
Clipvg: Text-guided image manipulation using differentiable vector graphics
Yiren Song, Xuning Shao, Kang Chen, Weidong Zhang, Zhongliang Jing, and Minzhe Li. Clipvg: Text-guided image manipulation using differentiable vector graphics. In Proceedings of the Conference on Artificial Intelli- gence (AAAI), 2023. 2, 3
work page 2023
-
[47]
If by deepfloyd lab at stabilityai
StabilityAI. If by deepfloyd lab at stabilityai. https: //github.com/deep-floyd/IF, 2023. 3 10
work page 2023
-
[48]
Roformer: Enhanced trans- former with rotary position embedding
Jianlin Su, Murtadha Ahmed, Yu Lu, Shengfeng Pan, Wen Bo, and Yunfeng Liu. Roformer: Enhanced trans- former with rotary position embedding. Neurocomput., 568(C), 2024. 12
work page 2024
-
[49]
Strokenuwa: Tokeniz- ing strokes for vector graphic synthesis
Zecheng Tang, Chenfei Wu, Zekai Zhang, Mingheng Ni, Shengming Yin, Yu Liu, Zhengyuan Yang, Lijuan Wang, Zicheng Liu, Juntao Li, et al. Strokenuwa: Tokeniz- ing strokes for vector graphic synthesis. arXiv preprint arXiv:2401.17093, 2024. 2, 3, 6, 16
-
[50]
Vecfusion: Vector font generation with diffusion
Vikas Thamizharasan, Difan Liu, Shantanu Agarwal, Matthew Fisher, Micha¨el Gharbi, Oliver Wang, Alec Ja- cobson, and Evangelos Kalogerakis. Vecfusion: Vector font generation with diffusion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 7943–7952, 2024. 3
work page 2024
-
[51]
Nivel: Neural implicit vector layers for text-to-vector generation
Vikas Thamizharasan, Difan Liu, Matthew Fisher, Nanx- uan Zhao, Evangelos Kalogerakis, and Michal Lukac. Nivel: Neural implicit vector layers for text-to-vector generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages 4589–4597, 2024. 3
work page 2024
-
[52]
Modern evolution strategies for creativity: Fitting concrete images and abstract con- cepts
Yingtao Tian and David Ha. Modern evolution strategies for creativity: Fitting concrete images and abstract con- cepts. In Artificial Intelligence in Music, Sound, Art and Design, pages 275–291. Springer, 2022. 2, 3, 6, 7
work page 2022
-
[53]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timoth´ee Lacroix, Bap- tiste Rozi`ere, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, and Guillaume Lample. Llama: Open and efficient founda- tion language models. ArXiv, abs/2302.13971, 2023. 12
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[54]
Twitter color emoji svginot font
Twitter. Twitter color emoji svginot font. https:// github.com/13rac1/twemoji- color- font ,
-
[55]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. In Advances in Neural Information Processing Systems (NeurIPS). Curran Associates, Inc., 2017. 12
work page 2017
-
[56]
Clipasso: Semantically-aware object sketching
Yael Vinker, Ehsan Pajouheshgar, Jessica Y Bo, Ro- man Christian Bachmann, Amit Haim Bermano, Daniel Cohen-Or, Amir Zamir, and Ariel Shamir. Clipasso: Semantically-aware object sketching. ACM Transactions on Graphics (TOG), 41(4):1–11, 2022. 2, 3
work page 2022
-
[57]
Haochen Wang, Xiaodan Du, Jiahao Li, Raymond A. Yeh, and Greg Shakhnarovich. Score jacobian chain- ing: Lifting pretrained 2d diffusion models for 3d gen- eration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 12619–12629, 2023. 3
work page 2023
-
[58]
Deepvecfont: Synthesiz- ing high-quality vector fonts via dual-modality learning
Yizhi Wang and Zhouhui Lian. Deepvecfont: Synthesiz- ing high-quality vector fonts via dual-modality learning. ACM Transactions on Graphics (TOG), 40(6), 2021. 2, 3, 4, 14, 16
work page 2021
-
[59]
Deepvecfont-v2: Exploiting trans- formers to synthesize vector fonts with higher quality
Yuqing Wang, Yizhi Wang, Longhui Yu, Yuesheng Zhu, and Zhouhui Lian. Deepvecfont-v2: Exploiting trans- formers to synthesize vector fonts with higher quality. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages 18320– 18328, 2023. 2, 16
work page 2023
-
[60]
Zhengyi Wang, Cheng Lu, Yikai Wang, Fan Bao, Chongxuan Li, Hang Su, and Jun Zhu. Prolificdreamer: High-fidelity and diverse text-to-3d generation with vari- ational score distillation. In Thirty-seventh Conference on Neural Information Processing Systems (NeurIPS) ,
-
[61]
Reshot - free icons & illustrations
ReShot website. Reshot - free icons & illustrations. de- sign freely with instant downloads and commercial li- censes. https://www.reshot.com/, . 6, 12
-
[62]
Open-licensed svg vector and icons
SVGRepo website. Open-licensed svg vector and icons. https://www.svgrepo.com/, . 6, 12
-
[63]
Icon- shop: Text-based vector icon synthesis with autoregressive transformers
Ronghuan Wu, Wanchao Su, Kede Ma, and Jing Liao. Iconshop: Text-based vector icon synthesis with autore- gressive transformers. arXiv preprint arXiv:2304.14400,
-
[64]
2, 3, 4, 6, 7, 14, 16
-
[65]
Human preference score: Better aligning text-to-image models with human preference
Xiaoshi Wu, Keqiang Sun, Feng Zhu, Rui Zhao, and Hongsheng Li. Human preference score: Better aligning text-to-image models with human preference. In Pro- ceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 2096–2105, 2023. 6
work page 2096
-
[66]
Diffsketcher: Text guided vector sketch synthesis through latent diffusion models
Ximing Xing, Chuang Wang, Haitao Zhou, Jing Zhang, Qian Yu, and Dong Xu. Diffsketcher: Text guided vector sketch synthesis through latent diffusion models. In Advances in Neural Information Processing Systems (NeurIPS), 2023. 2, 3, 6, 7
work page 2023
-
[67]
Empowering llms to understand and generate complex vector graphics
Ximing Xing, Juncheng Hu, Guotao Liang, Jing Zhang, Dong Xu, and Qian Yu. Empowering llms to understand and generate complex vector graphics. arXiv preprint arXiv:2412.11102, 2024. 2
-
[68]
Svgdreamer++: Advancing editability and diversity in text-guided svg generation
Ximing Xing, Qian Yu, Chuang Wang, Haitao Zhou, Jing Zhang, and Dong Xu. Svgdreamer++: Advancing editability and diversity in text-guided svg generation. arXiv preprint arXiv:2411.17832, 2024. 3
-
[69]
Svgdreamer: Text guided svg generation with diffusion model
Ximing Xing, Haitao Zhou, Chuang Wang, Jing Zhang, Dong Xu, and Qian Yu. Svgdreamer: Text guided svg generation with diffusion model. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 4546–4555, 2024. 2, 3, 6, 7
work page 2024
-
[70]
Peiying Zhang, Nanxuan Zhao, and Jing Liao. Text-to- vector generation with neural path representation. ACM Trans. Graph., 43(4), 2024. 3, 14 11 SVGFusion: Scalable Text-to-SVG Generation via Vector Space Diffusion Supplementary Material Overview This supplementary material provides additional details and analyses related to SVGFusion, organized as fol- l...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.