Recognition: unknown
Render-in-the-Loop: Vector Graphics Generation via Visual Self-Feedback
Pith reviewed 2026-05-10 01:09 UTC · model grok-4.3
The pith
Multimodal models generate better SVGs by observing their own intermediate renderings during code synthesis.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
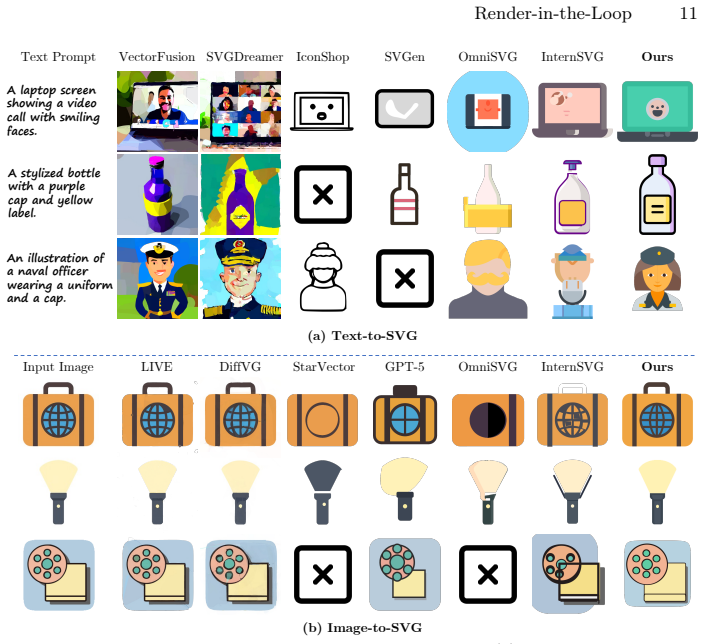
SVG synthesis is reformulated as a step-wise, visual-context-aware process. By rendering intermediate code states into a cumulative canvas, the model explicitly observes the evolving visual context at each step and leverages on-the-fly feedback to guide subsequent generation. Fine-grained path decomposition constructs dense multi-step visual trajectories, Visual Self-Feedback training conditions next-primitive generation on intermediate visual states, and Render-and-Verify inference filters degenerate primitives. This approach outperforms strong open-weight baselines on MMSVGBench for both Text-to-SVG and Image-to-SVG tasks.
What carries the argument
The Render-in-the-Loop process that renders cumulative canvases from partial SVG code and feeds them back as visual context to condition the next generation step, enabled by Visual Self-Feedback training.
Load-bearing premise
That off-the-shelf multimodal models cannot use incremental visual-code mappings without the specific fine-grained path decomposition and Visual Self-Feedback training strategy.
What would settle it
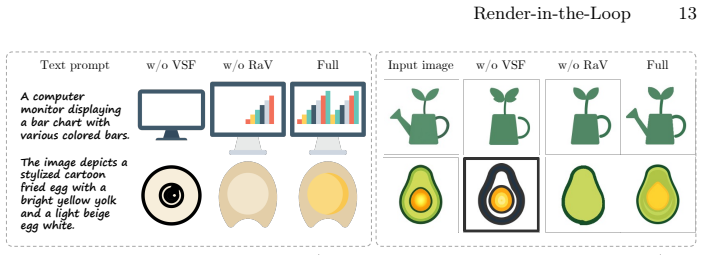
Measure SVG generation quality on occlusion-heavy test cases when the same model is run once with the visual self-feedback loop enabled and once without it.
Figures



read the original abstract
Multimodal Large Language Models (MLLMs) have shown promising capabilities in generating Scalable Vector Graphics (SVG) via direct code synthesis. However, existing paradigms typically adopt an open-loop "blind drawing" approach, where models generate symbolic code sequences without perceiving intermediate visual outcomes. This methodology severely underutilizes the powerful visual priors embedded in MLLMs vision encoders, treating SVG generation as a disjointed textual sequence modeling task rather than an integrated visuo-spatial one. Consequently, models struggle to reason about partial canvas states and implicit occlusion relationships, which are visually explicit but textually ambiguous. To bridge this gap, we propose Render-in-the-Loop, a novel generation paradigm that reformulates SVG synthesis as a step-wise, visual-context-aware process. By rendering intermediate code states into a cumulative canvas, the model explicitly observes the evolving visual context at each step, leveraging on-the-fly feedback to guide subsequent generation. However, we demonstrate that applying this visual loop naively to off-the-shelf models is suboptimal due to their inability to leverage incremental visual-code mappings. To address this, we first utilize fine-grained path decomposition to construct dense multi-step visual trajectories, and then introduce a Visual Self-Feedback (VSF) training strategy to condition the next primitive generation on intermediate visual states. Furthermore, a Render-and-Verify (RaV) inference mechanism is proposed to effectively filter degenerate and redundant primitives. Our framework, instantiated on a multimodal foundation model, outperforms strong open-weight baselines on the standard MMSVGBench. This result highlights the remarkable data efficiency and generalization capability of our Render-in-the-Loop paradigm for both Text-to-SVG and Image-to-SVG tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Render-in-the-Loop, a paradigm that reformulates SVG generation with MLLMs as a step-wise visual-context-aware process. Intermediate code is rendered to a cumulative canvas to provide on-the-fly visual feedback, addressing limitations of open-loop 'blind drawing' in reasoning about partial states and occlusions. The approach uses fine-grained path decomposition to create dense multi-step trajectories, a Visual Self-Feedback (VSF) training strategy to condition next-primitive generation on rendered states, and a Render-and-Verify (RaV) inference filter for degenerate primitives. Instantiated on a multimodal foundation model, the framework is claimed to outperform strong open-weight baselines on MMSVGBench for both Text-to-SVG and Image-to-SVG, with emphasis on data efficiency and generalization.
Significance. If the empirical claims hold after proper isolation of components, the work could meaningfully advance vector-graphics synthesis by better exploiting visual priors already present in MLLM encoders rather than treating generation as pure sequence modeling. The data-efficiency angle is particularly relevant for domains where SVG annotations are scarce. However, the absence of reported metrics, baselines, or ablations in the abstract, combined with the untested assumption that gains arise from visual reasoning rather than trajectory density, limits the immediate assessable impact.
major comments (3)
- Abstract: the claim that the framework 'outperforms strong open-weight baselines on the standard MMSVGBench' and highlights 'remarkable data efficiency' supplies no quantitative metrics, baseline names, error bars, or statistical tests, preventing verification of the central empirical result.
- Method section (Visual Self-Feedback training and path decomposition): the paper states that naive visual-loop application is suboptimal due to off-the-shelf MLLMs' inability to leverage incremental visual-code mappings, yet no ablation is described that retains fine-grained decomposition and the training objective while masking or ablating the visual feedback channel; without this isolation it remains possible that reported gains derive primarily from denser trajectories rather than learned visual-state conditioning.
- Experiments (MMSVGBench results): the abstract asserts generalization across Text-to-SVG and Image-to-SVG tasks, but without reported per-task breakdowns, ablation tables, or comparisons against decomposition-only variants, the load-bearing claim that VSF specifically enables occlusion/partial-state reasoning cannot be evaluated.
minor comments (2)
- Abstract: the phrase 'Render-in-the-Loop paradigm' is introduced without a concise one-sentence definition before the detailed description, which would aid readability.
- Notation: 'VSF' and 'RaV' are used without an initial expansion in the abstract, although they are later defined in the body.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We have reviewed the major comments carefully and will revise the manuscript to address the concerns about the abstract, experimental isolation, and result breakdowns. Our point-by-point responses follow.
read point-by-point responses
-
Referee: Abstract: the claim that the framework 'outperforms strong open-weight baselines on the standard MMSVGBench' and highlights 'remarkable data efficiency' supplies no quantitative metrics, baseline names, error bars, or statistical tests, preventing verification of the central empirical result.
Authors: We agree that the abstract would benefit from explicit quantitative support. In the revised manuscript we will expand the abstract to report the key performance numbers on MMSVGBench (for both Text-to-SVG and Image-to-SVG), name the strong open-weight baselines, and include any available error bars or statistical details. revision: yes
-
Referee: Method section (Visual Self-Feedback training and path decomposition): the paper states that naive visual-loop application is suboptimal due to off-the-shelf MLLMs' inability to leverage incremental visual-code mappings, yet no ablation is described that retains fine-grained decomposition and the training objective while masking or ablating the visual feedback channel; without this isolation it remains possible that reported gains derive primarily from denser trajectories rather than learned visual-state conditioning.
Authors: This is a fair criticism. While the manuscript contrasts the proposed approach against open-loop baselines and notes the sub-optimality of naive visual-loop use, it does not contain a controlled ablation that keeps the fine-grained path decomposition and training objective but removes the visual-feedback channel. We will add this ablation to the revised version to isolate the contribution of VSF from trajectory density. revision: yes
-
Referee: Experiments (MMSVGBench results): the abstract asserts generalization across Text-to-SVG and Image-to-SVG tasks, but without reported per-task breakdowns, ablation tables, or comparisons against decomposition-only variants, the load-bearing claim that VSF specifically enables occlusion/partial-state reasoning cannot be evaluated.
Authors: We acknowledge the need for greater transparency. The current manuscript presents aggregate MMSVGBench results, but we will add per-task breakdowns, explicit ablation tables that include decomposition-only variants, and additional analysis demonstrating how VSF improves reasoning about occlusions and partial canvas states. revision: yes
Circularity Check
No circularity; new training/inference strategy on external MLLMs with benchmark evaluation
full rationale
The paper introduces Render-in-the-Loop as a step-wise visual feedback paradigm, fine-grained path decomposition for trajectories, Visual Self-Feedback (VSF) training, and Render-and-Verify inference. These are presented as additions to off-the-shelf multimodal models rather than derivations from fitted parameters or self-referential definitions. No equations reduce outputs to inputs by construction, and no self-citations form load-bearing uniqueness claims. Performance claims rest on MMSVGBench comparisons, which are external to the method definition. The assertion that naive visual-loop use is suboptimal is stated directly without circular justification or reduction to the proposed components.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Multimodal LLMs possess visual priors in their vision encoders that can be leveraged for spatial reasoning during generation.
Forward citations
Cited by 3 Pith papers
-
BoostAPR: Boosting Automated Program Repair via Execution-Grounded Reinforcement Learning with Dual Reward Models
BoostAPR improves automated program repair by using execution-grounded RL with a sequence-level assessor and line-level credit allocator, reaching 40.7% on SWE-bench Verified and strong cross-language results.
-
VAnim: Rendering-Aware Sparse State Modeling for Structure-Preserving Vector Animation
VAnim creates open-domain text-to-SVG animations via sparse state updates on a persistent DOM tree, identification-first planning, and rendering-aware RL with a new 134k-example benchmark.
-
BoostAPR: Boosting Automated Program Repair via Execution-Grounded Reinforcement Learning with Dual Reward Models
BoostAPR uses supervised fine-tuning on verified fixes, dual sequence- and line-level reward models from execution feedback, and PPO to reach 40.7% on SWE-bench Verified with strong cross-language results.
Reference graph
Works this paper leans on
-
[1]
Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F.L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., et al.: Gpt-4 technical report. arXiv preprint arXiv:2303.08774 (2023) Render-in-the-Loop 21 Input ImageLIVEDiffVGOurs Image-to-SVG Fig.S4:A zoomed-in visualization of the SVG paths generated by optimization-based baselines (LIV...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Bai, S., Cai, Y., Chen, R., Chen, K., Chen, X., Cheng, Z., Deng, L., Ding, W., Gao, C., Ge, C., Ge, W., Guo, Z., Huang, Q., Huang, J., Huang, F., Hui, B., Jiang, S., Li, Z., Li, M., Li, M., Li, K., Lin, Z., Lin, J., Liu, X., Liu, J., Liu, C., Liu, Y., Liu, D., Liu, S., Lu, D., Luo, R., Lv, C., Men, R., Meng, L., Ren, X., Ren, X., Song, S., Sun, Y., Tang, ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Advances in Neural Information Processing Systems (NeurIPS)33, 16351–16361 (2020)
Carlier, A., Danelljan, M., Alahi, A., Timofte, R.: Deepsvg: A hierarchical gen- erative network for vector graphics animation. Advances in Neural Information Processing Systems (NeurIPS)33, 16351–16361 (2020)
2020
-
[4]
ChatGPT: Gpt-5 (2024),https://chatgpt.com
2024
-
[5]
In: Proceedings of the 33rd ACM International Conference on Multimedia
Chen, H., Zhao, Z., Chen, Y., Liang, Z., Ni, B.: Svgthinker: Instruction-aligned and reasoning-driven text-to-svg generation. In: Proceedings of the 33rd ACM International Conference on Multimedia. pp. 11004–11012 (2025)
2025
-
[6]
Consortium, W.W.W.: Scalable vector graphics (svg) specification (1999),https: //www.w3.org/TR/1999/WD-SVG-19990211/
1999
-
[7]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., et al.: An image is 22 G. Liang et al. worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929 (2020)
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[8]
In: Advances in Neural Information Pro- cessing Systems (NeurIPS) (2022)
Frans, K., Soros, L., Witkowski, O.: CLIPDraw: Exploring text-to-drawing syn- thesis through language-image encoders. In: Advances in Neural Information Pro- cessing Systems (NeurIPS) (2022)
2022
-
[9]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Gal, R., Vinker, Y., Alaluf, Y., Bermano, A., Cohen-Or, D., Shamir, A., Chechik, G.: Breathing life into sketches using text-to-video priors. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 4325– 4336 (2024)
2024
-
[10]
Springer Science & Business Media (2005)
Geroimenko, V.: Visualizing Information Using SVG and X3D: XML-based Tech- nologies for the XML-based Web. Springer Science & Business Media (2005)
2005
-
[11]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Guo, D., Yang, D., Zhang, H., Song, J., Wang, P., Zhu, Q., Xu, R., Zhang, R., Ma, S., Bi, X., et al.: Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
In: International Conference on Learning Representations (ICLR) (2018),https://openreview
Ha, D., Eck, D.: A neural representation of sketch drawings. In: International Conference on Learning Representations (ICLR) (2018),https://openreview. net/forum?id=Hy6GHpkCW
2018
-
[13]
Advances in neural information processing systems30(2017)
Heusel,M.,Ramsauer,H.,Unterthiner,T.,Nessler,B.,Hochreiter,S.:Ganstrained by a two time-scale update rule converge to a local nash equilibrium. Advances in neural information processing systems30(2017)
2017
-
[14]
In: Proceedings of the AAAI Conference on Artificial In- telligence
Hirschorn, O., Jevnisek, A., Avidan, S.: Optimize & reduce: a top-down approach for image vectorization. In: Proceedings of the AAAI Conference on Artificial In- telligence. vol. 38, pp. 2148–2156 (2024)
2024
-
[15]
In: Advances inNeuralInformationProcessingSystems(NeurIPS).vol.33,pp.6840–6851(2020)
Ho, J., Jain, A., Abbeel, P.: Denoising diffusion probabilistic models. In: Advances inNeuralInformationProcessingSystems(NeurIPS).vol.33,pp.6840–6851(2020)
2020
-
[16]
In: 2025 IEEE International Conference on Multimedia and Expo (ICME)
Hu, J., Xing, X., Zhang, J., Yu, Q.: Vectorpainter: Advanced stylized vector graph- ics synthesis using stroke-style priors. In: 2025 IEEE International Conference on Multimedia and Expo (ICME). pp. 1–6. IEEE (2025)
2025
-
[17]
In: Proceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition
Hu, T., Yi, R., Qian, B., Zhang, J., Rosin, P.L., Lai, Y.K.: Supersvg: Superpixel- based scalable vector graphics synthesis. In: Proceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition. pp. 24892–24901 (2024)
2024
-
[18]
ACM Transactions on Graphics (TOG)42(4), 1–11 (2023)
Iluz, S., Vinker, Y., Hertz, A., Berio, D., Cohen-Or, D., Shamir, A.: Word-as- image for semantic typography. ACM Transactions on Graphics (TOG)42(4), 1–11 (2023)
2023
-
[19]
In: Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition
Jain, A., Xie, A., Abbeel, P.: Vectorfusion: Text-to-svg by abstracting pixel-based diffusion models. In: Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition. pp. 1911–1920 (2023)
1911
-
[20]
ACM Transactions on Graphics (TOG) 39(6), 1–15 (2020)
Li, T.M., Lukáč, M., Gharbi, M., Ragan-Kelley, J.: Differentiable vector graph- ics rasterization for editing and learning. ACM Transactions on Graphics (TOG) 39(6), 1–15 (2020)
2020
-
[21]
In: Proceedings of the 33rd ACM International Conference on Multimedia
Liang, G., Hu, J., Xing, X., Zhang, J., Yu, Q.: Multi-object sketch animation with grouping and motion trajectory priors. In: Proceedings of the 33rd ACM International Conference on Multimedia. pp. 9237–9246 (2025)
2025
-
[22]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Liu, J., Xin, Z., Fu, Y., Zhao, R., Lan, B., Li, X.: Multi-object sketch animation by scene decomposition and motion planning. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 11537–11546 (2025)
2025
-
[23]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Lopes, R.G., Ha, D., Eck, D., Shlens, J.: A learned representation for scalable vector graphics. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 7930–7939 (2019) Render-in-the-Loop 23
2019
-
[24]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Ma, X., Zhou, Y., Xu, X., Sun, B., Filev, V., Orlov, N., Fu, Y., Shi, H.: Towards layer-wise image vectorization. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 16314–16323 (2022)
2022
-
[25]
DINOv2: Learning Robust Visual Features without Supervision
Oquab, M., Darcet, T., Moutakanni, T., Vo, H., Szafraniec, M., Khalidov, V., Fernandez, P., Haziza, D., Massa, F., El-Nouby, A., et al.: Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[26]
In: The Eleventh International Conference on Learning Representations (ICLR) (2023)
Poole, B., Jain, A., Barron, J.T., Mildenhall, B.: Dreamfusion: Text-to-3d using 2d diffusion. In: The Eleventh International Conference on Learning Representations (ICLR) (2023)
2023
-
[27]
In: International Conference on Machine Learning (ICML)
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In: International Conference on Machine Learning (ICML). pp. 8748–8763. PMLR (2021)
2021
-
[28]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Reddy, P., Gharbi, M., Lukac, M., Mitra, N.J.: Im2vec: Synthesizing vector graph- ics without vector supervision. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 7342–7351 (2021)
2021
-
[29]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Rodriguez, J.A., Puri, A., Agarwal, S., Laradji, I.H., Rodriguez, P., Rajeswar, S., Vazquez, D., Pal, C., Pedersoli, M.: Starvector: Generating scalable vector graphics code from images and text. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 16175–16186 (2025)
2025
-
[30]
A., Zhang, H., Puri, A., Feizi, A., Pramanik, R., Wichmann, P., Mondal, A., Samsami, M
Rodriguez, J.A., Zhang, H., Puri, A., Feizi, A., Pramanik, R., Wichmann, P., Mondal, A., Samsami, M.R., Awal, R., Taslakian, P., et al.: Rendering-aware rein- forcement learning for vector graphics generation. arXiv preprint arXiv:2505.20793 (2025)
-
[31]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 10684–10695 (2022)
2022
-
[32]
Proximal Policy Optimization Algorithms
Schulman, J., Wolski, F., Dhariwal, P., Radford, A., Klimov, O.: Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[33]
In: International Conference on Machine Learning
Tang, Z., Wu, C., Zhang, Z., Ni, M., Yin, S., Liu, Y., Yang, Z., Wang, L., Liu, Z., Li, J., et al.: Strokenuwa: Tokenizing strokes for vector graphic synthesis. In: International Conference on Machine Learning. pp. 47830–47845. PMLR (2024)
2024
-
[34]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Thamizharasan, V., Liu, D., Fisher, M., Zhao, N., Kalogerakis, E., Lukac, M.: Nivel: Neural implicit vector layers for text-to-vector generation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 4589–4597 (2024)
2024
-
[35]
In: Proceedings of the IEEE/CVF Inter- national Conference on Computer Vision
Vinker, Y., Alaluf, Y., Cohen-Or, D., Shamir, A.: Clipascene: Scene sketching with different types and levels of abstraction. In: Proceedings of the IEEE/CVF Inter- national Conference on Computer Vision. pp. 4146–4156 (2023)
2023
-
[36]
ACM Transactions on Graphics (TOG)41(4), 1–11 (2022)
Vinker, Y., Pajouheshgar, E., Bo, J.Y., Bachmann, R.C., Bermano, A.H., Cohen- Or, D., Zamir, A., Shamir, A.: Clipasso: Semantically-aware object sketching. ACM Transactions on Graphics (TOG)41(4), 1–11 (2022)
2022
-
[37]
In: Proceedings of the Com- puter Vision and Pattern Recognition Conference
Vinker, Y., Shaham, T.R., Zheng, K., Zhao, A., E Fan, J., Torralba, A.: Sketcha- gent: Language-driven sequential sketch generation. In: Proceedings of the Com- puter Vision and Pattern Recognition Conference. pp. 23355–23368 (2025)
2025
-
[38]
Viewcraft3d: High-fidelity and view-consistent 3d vector graphics synthesis
Wang, C., Zhou, H., Luo, L., Yu, Q.: Viewcraft3d: High-fidelity and view-consistent 3d vector graphics synthesis. arXiv preprint arXiv:2505.19492 (2025)
-
[39]
In: Proceedings of the 33rd ACM International Conference on Multimedia
Wang,F.,Zhao,Z.,Liu,Y.,Zhang,D.,Gao,J.,Sun,H.,Li,X.:Svgen:Interpretable vector graphics generation with large language models. In: Proceedings of the 33rd ACM International Conference on Multimedia. pp. 9608–9617 (2025) 24 G. Liang et al
2025
-
[40]
arXiv preprint arXiv:2510.11341 (2025)
Wang, H., Yin, J., Wei, Q., Zeng, W., Gu, L., Ye, S., Gao, Z., Wang, Y., Zhang, Y., Li, Y., et al.: Internsvg: Towards unified svg tasks with multimodal large language models. arXiv preprint arXiv:2510.11341 (2025)
-
[41]
ACM Transactions on Graphics (TOG)40(6) (2021)
Wang, Y., Lian, Z.: Deepvecfont: Synthesizing high-quality vector fonts via dual- modality learning. ACM Transactions on Graphics (TOG)40(6) (2021)
2021
-
[42]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Wang, Z., Huang, J., Sun, Z., Gong, Y., Cohen-Or, D., Lu, M.: Layered image vectorization via semantic simplification. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 7728–7738 (2025)
2025
-
[43]
IEEE transactions on image processing 13(4), 600–612 (2004)
Wang, Z., Bovik, A.C., Sheikh, H.R., Simoncelli, E.P.: Image quality assessment: from error visibility to structural similarity. IEEE transactions on image processing 13(4), 600–612 (2004)
2004
-
[44]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Wu, R., Su, W., Liao, J.: Chat2svg: Vector graphics generation with large language models and image diffusion models. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 23690–23700 (2025)
2025
-
[45]
In: Proceedings of the SIGGRAPH Asia 2025 Conference Papers (2025)
Wu, R., Su, W., Liao, J.: Layerpeeler: Autoregressive peeling for layer-wise image vectorization. In: Proceedings of the SIGGRAPH Asia 2025 Conference Papers (2025)
2025
-
[46]
ACM Transactions on Graphics (TOG)42(6), 1–14 (2023)
Wu, R., Su, W., Ma, K., Liao, J.: Iconshop: Text-guided vector icon synthesis with autoregressive transformers. ACM Transactions on Graphics (TOG)42(6), 1–14 (2023)
2023
-
[47]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Wu, X., Sun, K., Zhu, F., Zhao, R., Li, H.: Human preference score: Better aligning text-to-image models with human preference. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 2096–2105 (2023)
2096
-
[48]
Xing, X., Guan, Y., Zhang, J., Xu, D., Yu, Q.: Reason-svg: Hybrid reward rl for aha-moments in vector graphics generation. arXiv preprint arXiv:2505.24499 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[49]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Xing, X., Hu, J., Liang, G., Zhang, J., Xu, D., Yu, Q.: Empowering llms to un- derstand and generate complex vector graphics. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 19487–19497 (2025)
2025
-
[50]
SVGFusion: A VAE-Diffusion Transformer for Vector Graphic Generation
Xing, X., Hu, J., Zhang, J., Xu, D., Yu, Q.: Svgfusion: Scalable text-to-svg gener- ation via vector space diffusion. arXiv preprint arXiv:2412.10437 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[51]
Advances in Neural Infor- mation Processing Systems36, 15869–15889 (2023)
Xing, X., Wang, C., Zhou, H., Zhang, J., Yu, Q., Xu, D.: Diffsketcher: Text guided vector sketch synthesis through latent diffusion models. Advances in Neural Infor- mation Processing Systems36, 15869–15889 (2023)
2023
-
[52]
IEEE Transactions on Pattern Analysis and Machine Intelligence (2025)
Xing, X., Yu, Q., Wang, C., Zhou, H., Zhang, J., Xu, D.: Svgdreamer++: Advanc- ing editability and diversity in text-guided svg generation. IEEE Transactions on Pattern Analysis and Machine Intelligence (2025)
2025
-
[53]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Xing, X., Zhou, H., Wang, C., Zhang, J., Xu, D., Yu, Q.: Svgdreamer: Text guided svg generation with diffusion model. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 4546–4555 (2024)
2024
-
[54]
Advances in Neural Information Processing Systems36, 15903–15935 (2023)
Xu, J., Liu, X., Wu, Y., Tong, Y., Li, Q., Ding, M., Tang, J., Dong, Y.: Imagere- ward: Learning and evaluating human preferences for text-to-image generation. Advances in Neural Information Processing Systems36, 15903–15935 (2023)
2023
-
[55]
In: Pro- ceedings of the eleventh international conference on 3D web technology
Yan, W.: Integrating web 2d and 3d technologies for architectural visualization: applications of svg and x3d/vrml in environmental behavior simulation. In: Pro- ceedings of the eleventh international conference on 3D web technology. pp. 37–45 (2006)
2006
-
[56]
In: The Thirty-ninth Annual Conference on Neural Information Processing Systems (2025) Render-in-the-Loop 25
Yang, Y., Cheng, W., Chen, S., Zeng, X., Yin, F., Zhang, J., Wang, L., Yu, G., Ma, X., Jiang, Y.G.: Omnisvg: A unified scalable vector graphics generation model. In: The Thirty-ninth Annual Conference on Neural Information Processing Systems (2025) Render-in-the-Loop 25
2025
-
[57]
Yue, Y., Chen, Z., Lu, R., Zhao, A., Wang, Z., Song, S., Huang, G.: Does rein- forcement learning really incentivize reasoning capacity in llms beyond the base model? arXiv preprint arXiv:2504.13837 (2025)
work page internal anchor Pith review arXiv 2025
-
[58]
arXiv preprint arXiv:2512.10894 (2025)
Zhang, P., Zhao, N., Fisher, M., Xu, Y., Liao, J., Liu, D.: Duetsvg: Uni- fied multimodal svg generation with internal visual guidance. arXiv preprint arXiv:2512.10894 (2025)
-
[59]
ACM Transactions on Graphics (TOG)43(4), 1–13 (2024)
Zhang, P., Zhao, N., Liao, J.: Text-to-vector generation with neural path represen- tation. ACM Transactions on Graphics (TOG)43(4), 1–13 (2024)
2024
-
[60]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Zhang, R., Isola, P., Efros, A.A., Shechtman, E., Wang, O.: The unreasonable effectiveness of deep features as a perceptual metric. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 586–595 (2018)
2018
-
[61]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Zhao, K., Bao, L., Li, Y., Su, X., Zhang, K., Qiao, X.: Less is more: Efficient image vectorization with adaptive parameterization. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 18166–18175 (2025)
2025
-
[62]
In: European Conference on Computer Vision
Zhou, H., Zhang, H., Wang, B.: Segmentation-guided layer-wise image vectoriza- tion with gradient fills. In: European Conference on Computer Vision. pp. 165–180. Springer (2024)
2024
-
[63]
In: ICASSP 2024- 2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)
Zhu, H., Chong, J.I., Hu, T., Yi, R., Lai, Y.K., Rosin, P.L.: Samvg: A multi-stage image vectorization model with the segment-anything model. In: ICASSP 2024- 2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). pp. 4350–4354. IEEE (2024)
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.