OmniPrism: Learning Disentangled Visual Concept for Image Generation
Pith reviewed 2026-05-23 06:40 UTC · model grok-4.3
The pith
OmniPrism separates multiple visual concepts from one reference image so diffusion models can apply chosen ones without mixing.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
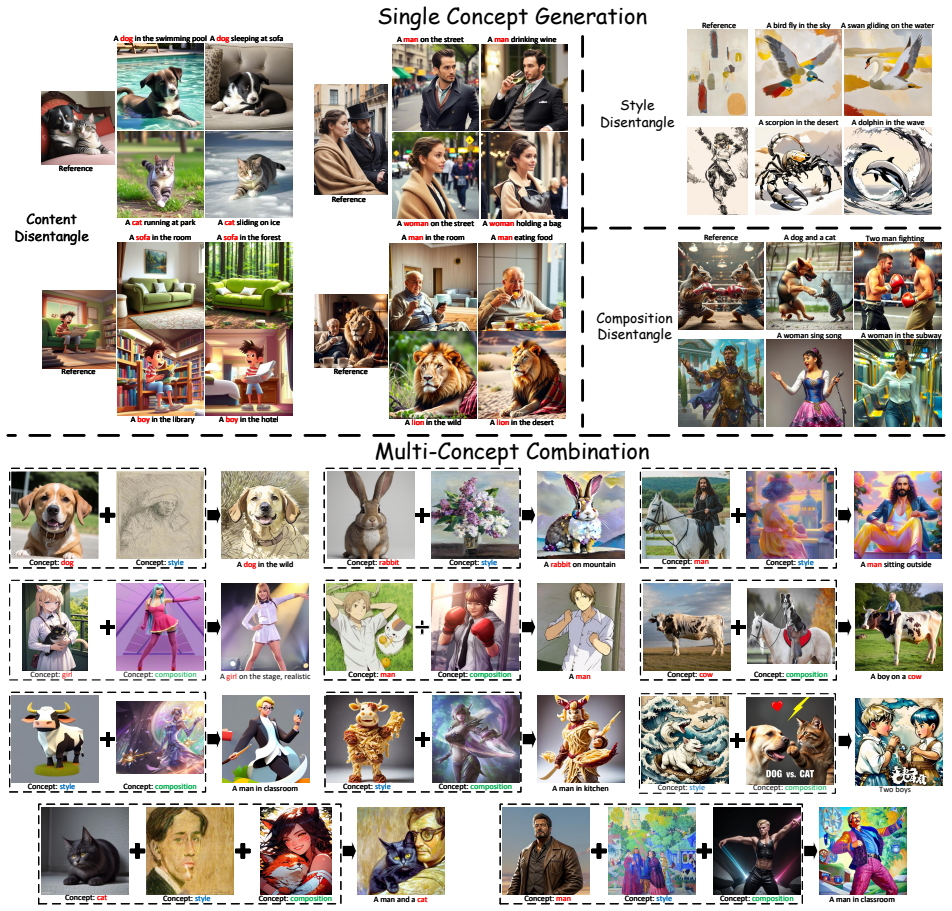
OmniPrism learns disentangled concept representations from reference images by leveraging a multimodal extractor and natural language guidance. It builds the PCD-200K dataset consisting of image pairs that share the same single concept in areas like content, style, or composition. Through the contrastive orthogonal disentangled training pipeline these representations are isolated and then injected into additional cross-attention layers of a diffusion model, with block embeddings adapting each layer to the appropriate concept domain, resulting in generated images that maintain high fidelity to the text prompt and the selected concepts.
What carries the argument
The contrastive orthogonal disentangled (COD) training pipeline that operates on the PCD-200K paired dataset to produce isolatable concept representations for injection into diffusion cross-attention layers.
If this is right
- Diffusion models gain the ability to incorporate only the desired concept from a reference while ignoring others.
- Generated images show improved fidelity to both the input text prompt and the explicitly chosen visual concepts.
- Multi-aspect creative generation becomes feasible without the concept confusion seen in prior single-aspect or entangled approaches.
- Block embeddings allow each diffusion layer to specialize in a particular concept domain during generation.
Where Pith is reading between the lines
- Similar paired-data construction and contrastive isolation could be tested on other generative architectures beyond diffusion.
- The method implies that disentanglement might reduce the need for heavy prompt engineering when transferring styles or contents.
- Extending the pairing idea to video frames or 3D assets could address temporal or geometric concept leakage in those domains.
Load-bearing premise
The PCD-200K paired dataset and multimodal extractor together supply clean unbiased signals that let the COD pipeline isolate concepts without residual entanglement or dataset artifacts.
What would settle it
Run the model on reference images containing overlapping or ambiguous concepts and check whether generated outputs still exhibit unintended mixing of non-selected concepts from the reference.
Figures















read the original abstract
Creative visual concept generation often draws inspiration from specific concepts in a reference image to produce relevant outcomes. However, existing methods are typically constrained to single-aspect concept generation or are easily disrupted by irrelevant concepts in multi-aspect concept scenarios, leading to concept confusion and hindering creative generation. To address this, we propose OmniPrism, a visual concept disentangling approach for creative image generation. Our method learns disentangled concept representations guided by natural language and trains a diffusion model to incorporate these concepts. We utilize the rich semantic space of a multimodal extractor to achieve concept disentanglement from given images and concept guidance. To disentangle concepts with different semantics, we construct a paired concept disentangled dataset (PCD-200K), where each pair shares the same concept such as content, style, and composition. We learn disentangled concept representations through our contrastive orthogonal disentangled (COD) training pipeline, which are then injected into additional diffusion cross-attention layers for generation. A set of block embeddings is designed to adapt each block's concept domain in the diffusion models. Extensive experiments demonstrate that our method can generate high-quality, concept-disentangled results with high fidelity to text prompts and desired concepts.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes OmniPrism for disentangling visual concepts (content, style, composition) from reference images to enable controlled creative generation in diffusion models. It constructs a paired dataset PCD-200K where image pairs share exactly one semantic concept, employs a multimodal extractor with a contrastive orthogonal disentangled (COD) training pipeline to learn representations, and injects these via additional cross-attention layers and block embeddings into the diffusion model.
Significance. If the disentanglement holds without residual correlations, the method could advance multi-aspect controllable generation by reducing concept confusion, offering a structured alternative to single-aspect or entangled approaches through large-scale paired data and orthogonal losses.
major comments (3)
- [PCD-200K construction] PCD-200K construction (described in the method section): the claim that each pair shares the same concept such as content, style, and composition and differs in exactly one axis lacks any quantitative validation (cross-axis correlation statistics, human verification rates, or extractor ablation). This assumption is load-bearing for the COD pipeline, as residual correlations would be encoded as 'disentangled' factors.
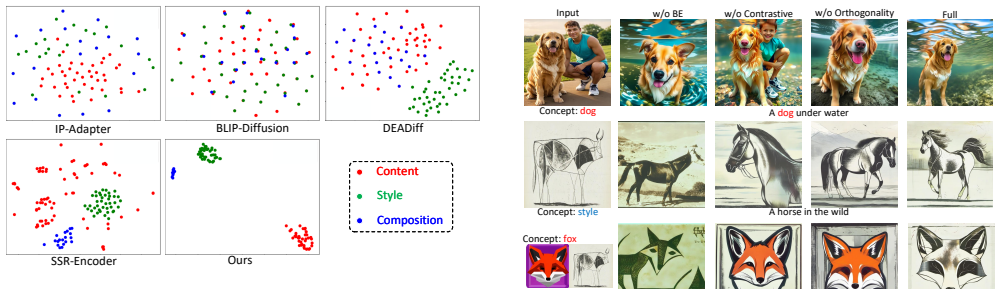
- [Experiments] Experiments and results: the abstract states that 'extensive experiments demonstrate' high-quality, concept-disentangled results with high fidelity, yet no quantitative metrics (FID, CLIP-based fidelity, disentanglement scores), baseline comparisons, or ablation details on COD components are referenced, leaving the central performance claim unsupported.
- [COD training pipeline] COD training pipeline: the contrastive orthogonal loss is presented as isolating concepts via the multimodal extractor, but without reported evidence that the extractor yields unbiased vectors or that the orthogonal term removes entanglement beyond what contrastive alone achieves, the isolation claim cannot be verified.
minor comments (1)
- [Abstract] The role of 'block embeddings' in adapting each block's concept domain is mentioned in the abstract but would benefit from an earlier definition or diagram reference for readers unfamiliar with the diffusion architecture modifications.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the PCD-200K dataset, experimental reporting, and COD pipeline. The comments identify areas where additional evidence would strengthen the manuscript, and we address each point below with plans for revision.
read point-by-point responses
-
Referee: [PCD-200K construction] PCD-200K construction (described in the method section): the claim that each pair shares the same concept such as content, style, and composition and differs in exactly one axis lacks any quantitative validation (cross-axis correlation statistics, human verification rates, or extractor ablation). This assumption is load-bearing for the COD pipeline, as residual correlations would be encoded as 'disentangled' factors.
Authors: We agree that the manuscript does not currently include quantitative validation (e.g., cross-axis correlations or human verification rates) for the PCD-200K pairs. This is a substantive concern given the central role of the dataset. In the revised manuscript we will add a validation subsection reporting correlation statistics across concept axes and human evaluation results on pair quality. revision: yes
-
Referee: [Experiments] Experiments and results: the abstract states that 'extensive experiments demonstrate' high-quality, concept-disentangled results with high fidelity, yet no quantitative metrics (FID, CLIP-based fidelity, disentanglement scores), baseline comparisons, or ablation details on COD components are referenced, leaving the central performance claim unsupported.
Authors: The referee is correct that the current manuscript references extensive experiments in the abstract but does not report quantitative metrics, baseline comparisons, or COD ablations. We will expand the experiments section in the revision to include FID, CLIP-based fidelity, disentanglement scores, baseline comparisons, and component ablations. revision: yes
-
Referee: [COD training pipeline] COD training pipeline: the contrastive orthogonal loss is presented as isolating concepts via the multimodal extractor, but without reported evidence that the extractor yields unbiased vectors or that the orthogonal term removes entanglement beyond what contrastive alone achieves, the isolation claim cannot be verified.
Authors: We acknowledge that the manuscript describes the COD loss but does not provide ablations or analyses demonstrating the orthogonal term's incremental benefit or the unbiased character of the extracted vectors. The revised version will include targeted ablations (contrastive-only vs. full COD) and supporting metrics or visualizations. revision: yes
Circularity Check
No circularity: derivation relies on external dataset construction and new loss, not self-referential fitting
full rationale
The paper constructs PCD-200K externally and defines a COD pipeline with contrastive-orthogonal loss to produce concept vectors that are then injected into diffusion cross-attention. No equation or claim equates a reported performance metric to a quantity defined by the model's own fitted parameters. The central claims rest on the dataset pairs and multimodal extractor as independent inputs rather than on any self-definition, fitted-input-as-prediction, or self-citation chain. This matches the default expectation of a non-circular empirical method.
Axiom & Free-Parameter Ledger
free parameters (1)
- block embeddings
axioms (1)
- domain assumption Multimodal extractor supplies rich semantic space sufficient for concept disentanglement
Forward citations
Cited by 1 Pith paper
-
CLAY: Conditional Visual Similarity Modulation in Vision-Language Embedding Space
CLAY reframes pretrained VLM embedding spaces as text-conditional similarity spaces for adaptive, multi-conditioned image retrieval without additional training.
Reference graph
Works this paper leans on
-
[1]
Aishwarya Agarwal, Srikrishna Karanam, Tripti Shukla, and Balaji Vasan Srinivasan. An image is worth multiple words: Multi-attribute inversion for constrained text-to-image syn- thesis. arXiv:2311.11919, 2023. 3, 5
-
[2]
Break-a-scene: Extracting multiple concepts from a single image
Omri Avrahami, Kfir Aberman, Ohad Fried, Daniel Cohen- Or, and Dani Lischinski. Break-a-scene: Extracting multiple concepts from a single image. In SIGGRAPH Asia, pages 1–12, 2023. 2, 3
work page 2023
-
[3]
Disenbooth: Disentangled parameter-efficient tuning for subject-driven text-to-image generation,
Hong Chen, Yipeng Zhang, Simin Wu, Xin Wang, Xuguang Duan, Yuwei Zhou, and Wenwu Zhu. Disenbooth: Identity- preserving disentangled tuning for subject-driven text-to- image generation. arXiv:2305.03374, 2023. 2
-
[4]
Anydoor: Zero-shot object-level im- age customization
Xi Chen, Lianghua Huang, Yu Liu, Yujun Shen, Deli Zhao, and Hengshuang Zhao. Anydoor: Zero-shot object-level im- age customization. arXiv:2307.09481, 2023. 3, 5
-
[5]
Anydoor: Zero-shot object-level im- age customization
Xi Chen, Lianghua Huang, Yu Liu, Yujun Shen, Deli Zhao, and Hengshuang Zhao. Anydoor: Zero-shot object-level im- age customization. In CVPR, pages 6593–6602, 2024. 2
work page 2024
-
[6]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy. An image is worth 16x16 words: Trans- formers for image recognition at scale. arXiv:2010.11929,
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[7]
An image is worth 16x16 words: Transformers for image recognition at scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Syl- vain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. In ICLR, 2021. 3
work page 2021
-
[8]
An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion
Rinon Gal, Yuval Alaluf, Yuval Atzmon, Or Patashnik, Amit H Bermano, Gal Chechik, and Daniel Cohen-Or. An image is worth one word: Personalizing text-to-image gen- eration using textual inversion. arXiv:2208.01618, 2022. 3, 5
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[9]
An image is worth one word: Personalizing text-to-image generation using textual inversion
Rinon Gal, Yuval Alaluf, Yuval Atzmon, Or Patashnik, Amit Haim Bermano, Gal Chechik, and Daniel Cohen-or. An image is worth one word: Personalizing text-to-image generation using textual inversion. In ICLR, 2023. 2
work page 2023
-
[10]
Style aligned image generation via shared atten- tion
Amir Hertz, Andrey V oynov, Shlomi Fruchter, and Daniel Cohen-Or. Style aligned image generation via shared atten- tion. In CVPR, pages 4775–4785, 2024. 2
work page 2024
-
[11]
Clipscore: A reference-free evaluation met- ric for image captioning
Jack Hessel, Ari Holtzman, Maxwell Forbes, Ronan Le Bras, and Yejin Choi. Clipscore: A reference-free evaluation met- ric for image captioning. In EMNLP, 2021. 5
work page 2021
-
[12]
Classifier-Free Diffusion Guidance
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance. arXiv:2207.12598, 2022. 4
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[13]
Learning disentangled iden- tifiers for action-customized text-to-image generation
Siteng Huang, Biao Gong, Yutong Feng, Xi Chen, Yuqian Fu, Yu Liu, and Donglin Wang. Learning disentangled iden- tifiers for action-customized text-to-image generation. In CVPR, pages 7797–7806, 2024. 2
work page 2024
-
[14]
Reversion: Diffusion-based relation inversion from images
Ziqi Huang, Tianxing Wu, Yuming Jiang, Kelvin CK Chan, and Ziwei Liu. Reversion: Diffusion-based relation inversion from images. arXiv:2303.13495, 2023. 2
-
[15]
Visual style prompting with swapping self- attention
Jaeseok Jeong, Junho Kim, Yunjey Choi, Gayoung Lee, and Youngjung Uh. Visual style prompting with swapping self- attention. arXiv:2402.12974, 2024. 2
-
[16]
Chen Jin, Ryutaro Tanno, Amrutha Saseendran, Tom Di- ethe, and Philip Alexander Teare. An image is worth mul- tiple words: Discovering object level concepts using multi- concept prompt learning. In ICML, 2024. 3
work page 2024
-
[17]
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer White- head, Alexander C. Berg, Wan-Yen Lo, Piotr Doll ´ar, and Ross Girshick. Segment anything. arXiv:2304.02643, 2023. 2
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[18]
Multi-concept customiza- tion of text-to-image diffusion
Nupur Kumari, Bingliang Zhang, Richard Zhang, Eli Shechtman, and Jun-Yan Zhu. Multi-concept customiza- tion of text-to-image diffusion. In CVPR, pages 1931–1941,
work page 1931
-
[19]
Dongxu Li, Junnan Li, and Steven Hoi. Blip-diffusion: Pre- trained subject representation for controllable text-to-image generation and editing. NeurIPS, 2024. 2, 3, 4, 5, 6, 7, 1
work page 2024
-
[20]
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. In ICML, pages 19730–19742. PMLR, 2023. 2, 3, 4, 5, 1
work page 2023
-
[21]
Pseudo numerical methods for diffusion models on manifolds
Luping Liu, Yi Ren, Zhijie Lin, and Zhou Zhao. Pseudo numerical methods for diffusion models on manifolds. arXiv:2202.09778, 2022. 4
-
[22]
Decoupled weight decay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. In ICLR, 2019. 5
work page 2019
-
[23]
Dpm-solver: A fast ode solver for diffusion probabilistic model sampling in around 10 steps
Cheng Lu, Yuhao Zhou, Fan Bao, Jianfei Chen, Chongxuan Li, and Jun Zhu. Dpm-solver: A fast ode solver for diffusion probabilistic model sampling in around 10 steps. NeurIPS, pages 5775–5787, 2022. 4
work page 2022
-
[24]
GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models
Alex Nichol, Prafulla Dhariwal, Aditya Ramesh, Pranav Shyam, Pamela Mishkin, Bob McGrew, Ilya Sutskever, and Mark Chen. Glide: Towards photorealistic image generation and editing with text-guided diffusion models. arXiv:2112.10741, 2021. 2
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[25]
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas M ¨uller, Joe Penna, and Robin Rombach. Sdxl: Improving latent diffusion mod- els for high-resolution image synthesis. arXiv:2307.01952,
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
Dead- iff: An efficient stylization diffusion model with disentan- gled representations
Tianhao Qi, Shancheng Fang, Yanze Wu, Hongtao Xie, Ji- awei Liu, Lang Chen, Qian He, and Yongdong Zhang. Dead- iff: An efficient stylization diffusion model with disentan- gled representations. arXiv:2403.06951, 2024. 2, 3, 4, 5, 6, 7, 1
-
[27]
Learn- ing transferable visual models from natural language super- vision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learn- ing transferable visual models from natural language super- vision. In ICML, 2021. 2, 3, 4, 5, 1
work page 2021
-
[28]
Hierarchical Text-Conditional Image Generation with CLIP Latents
Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen. Hierarchical text-conditional image gener- ation with clip latents. arXiv:2204.06125, 2022. 2 9
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[29]
High-resolution image syn- thesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj¨orn Ommer. High-resolution image syn- thesis with latent diffusion models. In CVPR, pages 10684– 10695, 2022. 2, 3, 6
work page 2022
-
[30]
Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation
Nataniel Ruiz, Yuanzhen Li, Varun Jampani, Yael Pritch, Michael Rubinstein, and Kfir Aberman. Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In CVPR, pages 22500–22510, 2023. 2, 3, 5
work page 2023
-
[31]
Photorealistic text-to-image diffusion models with deep language understanding
Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily L Denton, Kamyar Ghasemipour, Raphael Gontijo Lopes, Burcu Karagol Ayan, Tim Salimans, et al. Photorealistic text-to-image diffusion models with deep language understanding. NeurIPS, 35:36479–36494, 2022. 2
work page 2022
-
[32]
LAION-5B: an open large-scale dataset for training next generation image-text models
Christoph Schuhmann, Romain Beaumont, Richard Vencu, Cade Gordon, Ross Wightman, Mehdi Cherti, Theo Coombes, Aarush Katta, Clayton Mullis, Mitchell Worts- man, Patrick Schramowski, Srivatsa Kundurthy, Katherine Crowson, Ludwig Schmidt, Robert Kaczmarczyk, and Jenia Jitsev. LAION-5B: an open large-scale dataset for training next generation image-text model...
work page 2022
-
[33]
Instant- booth: Personalized text-to-image generation without test- time finetuning
Jing Shi, Wei Xiong, Zhe Lin, and Hyun Joon Jung. Instant- booth: Personalized text-to-image generation without test- time finetuning. In CVPR, pages 8543–8552, 2024. 2
work page 2024
-
[34]
Styledrop: Text-to-image synthesis of any style
Kihyuk Sohn, Lu Jiang, Jarred Barber, Kimin Lee, Nataniel Ruiz, Dilip Krishnan, Huiwen Chang, Yuanzhen Li, Irfan Essa, Michael Rubinstein, et al. Styledrop: Text-to-image synthesis of any style. NeurIPS, 2024. 2
work page 2024
-
[35]
Measuring style similarity in diffusion models.arXiv preprint arXiv:2404.01292, 2024
Gowthami Somepalli, Anubhav Gupta, Kamal Gupta, Shra- may Palta, Micah Goldblum, Jonas Geiping, Abhinav Shri- vastava, and Tom Goldstein. Measuring style similarity in diffusion models. arXiv:2404.01292, 2024. 5
-
[36]
Denoising Diffusion Implicit Models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denois- ing diffusion implicit models. arXiv:2010.02502, 2020. 4, 5
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[37]
Kolors: Effective training of diffusion model for photorealistic text-to-image synthesis
Kolors Team. Kolors: Effective training of diffusion model for photorealistic text-to-image synthesis. arXiv preprint,
-
[38]
Laurens Van der Maaten and Geoffrey Hinton. Visualizing data using t-sne. JMLR, 9(11), 2008. 8
work page 2008
-
[39]
Concept decomposition for visual exploration and inspiration
Yael Vinker, Andrey V oynov, Daniel Cohen-Or, and Ariel Shamir. Concept decomposition for visual exploration and inspiration. TOG, 2023. 2, 3
work page 2023
-
[40]
p+: Ex- tended textual conditioning in text-to-image generation,
Andrey V oynov, Qinghao Chu, Daniel Cohen-Or, and Kfir Aberman. P+: Extended textual conditioning in text-to- image generation. arXiv:2303.09522, 2023. 3, 4
-
[41]
Instantstyle: Free lunch towards style- preserving in text-to-image generation
Haofan Wang, Qixun Wang, Xu Bai, Zekui Qin, and Anthony Chen. Instantstyle: Free lunch towards style- preserving in text-to-image generation. arXiv:2404.02733,
-
[42]
Styleadapter: A single-pass lora-free model for stylized image generation
Zhouxia Wang, Xintao Wang, Liangbin Xie, Zhongang Qi, Ying Shan, Wenping Wang, and Ping Luo. Styleadapter: A single-pass lora-free model for stylized image generation. arXiv:2309.01770, 2023. 2
-
[43]
Elite: Encoding visual con- cepts into textual embeddings for customized text-to-image generation
Yuxiang Wei, Yabo Zhang, Zhilong Ji, Jinfeng Bai, Lei Zhang, and Wangmeng Zuo. Elite: Encoding visual con- cepts into textual embeddings for customized text-to-image generation. In ICCV, pages 15943–15953, 2023. 2, 3, 5
work page 2023
-
[44]
Cusconcept: Cus- tomized visual concept decomposition with diffusion mod- els
Zhi Xu, Shaozhe Hao, and Kai Han. Cusconcept: Cus- tomized visual concept decomposition with diffusion mod- els. arXiv:2410.00398, 2024. 2, 3
-
[45]
Paint by example: Exemplar-based image editing with diffusion mod- els
Binxin Yang, Shuyang Gu, Bo Zhang, Ting Zhang, Xuejin Chen, Xiaoyan Sun, Dong Chen, and Fang Wen. Paint by example: Exemplar-based image editing with diffusion mod- els. In CVPR, pages 18381–18391, 2023. 3, 5
work page 2023
-
[46]
IP-Adapter: Text Compatible Image Prompt Adapter for Text-to-Image Diffusion Models
Hu Ye, Jun Zhang, Sibo Liu, Xiao Han, and Wei Yang. Ip- adapter: Text compatible image prompt adapter for text-to- image diffusion models. arXiv:2308.06721, 2023. 3, 5, 6, 7, 1
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[47]
DINO: DETR with improved denoising anchor boxes for end-to-end object de- tection
Hao Zhang, Feng Li, Shilong Liu, Lei Zhang, Hang Su, Jun Zhu, Lionel Ni, and Heung-Yeung Shum. DINO: DETR with improved denoising anchor boxes for end-to-end object de- tection. In ICLR, 2023. 3
work page 2023
-
[48]
Adding conditional control to text-to-image diffusion models
Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. Adding conditional control to text-to-image diffusion models. In ICCV, pages 3836–3847, 2023. 2, 3, 5
work page 2023
-
[49]
Prospect: Prompt spec- trum for attribute-aware personalization of diffusion models
Yuxin Zhang, Weiming Dong, Fan Tang, Nisha Huang, Haibin Huang, Chongyang Ma, Tong-Yee Lee, Oliver Deussen, and Changsheng Xu. Prospect: Prompt spec- trum for attribute-aware personalization of diffusion models. TOG, 42(6):1–14, 2023. 3
work page 2023
-
[50]
Ssr-encoder: Encoding selective subject representation for subject-driven generation
Yuxuan Zhang, Yiren Song, Jiaming Liu, Rui Wang, Jinpeng Yu, Hao Tang, Huaxia Li, Xu Tang, Yao Hu, Han Pan, et al. Ssr-encoder: Encoding selective subject representation for subject-driven generation. In CVPR, 2024. 2, 3, 4, 5, 6, 7, 1
work page 2024
-
[51]
Yanbing Zhang, Mengping Yang, Qin Zhou, and Zhe Wang. Attention calibration for disentangled text-to-image person- alization. In CVPR, pages 4764–4774, 2024. 3 10 OmniPrism: Learning Disentangled Visual Concept for Image Generation Supplementary Material In the supplementary materials, we introduce more detailed analysis and additional results: • Sec. F p...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.