From Limited Labels to Open Domains:An Efficient Learning Method for Drone-view Geo-Localization
Pith reviewed 2026-05-23 00:28 UTC · model grok-4.3
The pith
CDIKTNet uses a small set of paired drone-satellite images to initialize invariant features that reduce confusion when learning from mostly unpaired data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
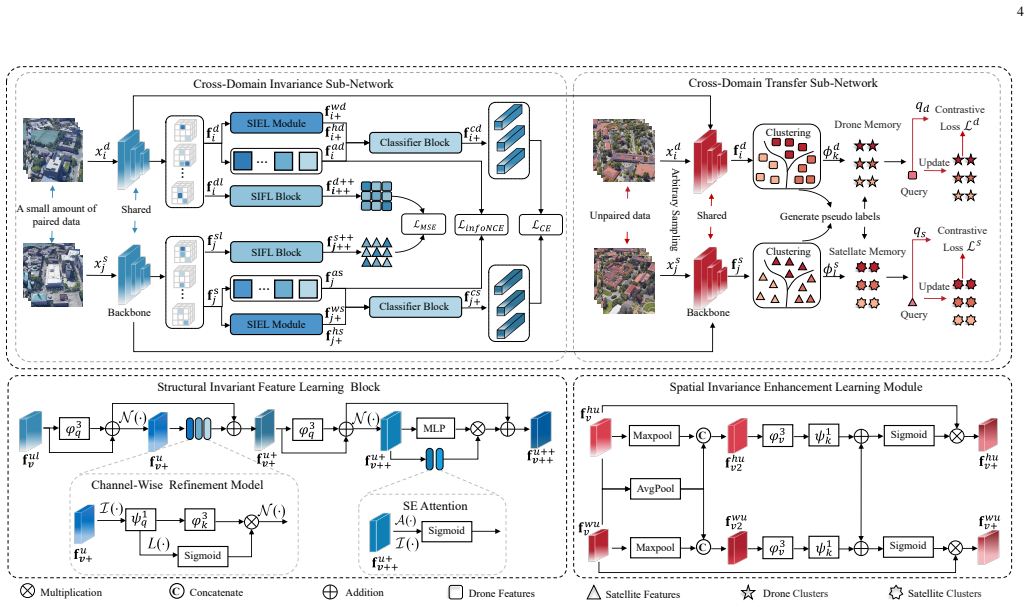
CDIKTNet, built from a cross-domain invariance sub-network (CDIS) and a cross-domain transfer sub-network (CDTS), learns cross-view structural and spatial invariance from a small amount of paired data that serves as prior knowledge; this endows the shared feature space of unpaired data with similar implicit cross-view correlations at initialization, which alleviates feature confusion, after which the CDTS employs dual-path contrastive learning to further optimize each subspace while preserving consistency.
What carries the argument
The cross-domain invariant knowledge transfer network (CDIKTNet) whose CDIS sub-network learns invariance from limited paired data to initialize the feature space and whose CDTS sub-network applies dual-path contrastive learning to optimize subspaces while maintaining shared-space consistency.
If this is right
- The method reaches state-of-the-art accuracy under full supervision compared with existing supervised drone-view geo-localization approaches.
- It surpasses current unsupervised methods when only few-shot paired data or cross-domain initialization is available.
- Deployment to a new domain no longer requires collecting and retraining on new paired data.
- Feature confusion from geographical similarity and spatial continuity is reduced by the initial invariance prior before contrastive optimization begins.
Where Pith is reading between the lines
- The same limited-pair initialization pattern could be tested on other cross-view matching problems such as satellite-to-ground retrieval or multi-modal image registration.
- If the choice of which few pairs to label proves critical, active selection strategies might further lower the labeling budget while preserving the reported gains.
- The closed-loop invariance-plus-contrastive structure suggests hybrid training may scale to additional sensor modalities without requiring domain-specific paired collections.
Load-bearing premise
A small amount of paired data can serve as prior knowledge that endows the shared feature space of unpaired data with similar implicit cross-view correlations at initialization, thereby alleviating feature confusion caused by geographical similarity and spatial continuity.
What would settle it
An experiment in which the paired-data initialization step is removed or replaced by random initialization and performance on unpaired cross-domain test sets remains equal to or better than the full CDIKTNet would falsify the central claim.
Figures






read the original abstract
Traditional supervised drone-view geo-localization (DVGL) methods heavily depend on paired training data and encounter difficulties in learning cross-view correlations from unpaired data. Moreover, when deployed in a new domain, these methods require obtaining the new paired data and subsequent retraining for model adaptation, which significantly increases computational overhead. Existing unsupervised methods have enabled to generate pseudo-labels based on cross-view similarity to infer the pairing relationships. However, geographical similarity and spatial continuity often cause visually analogous features at different geographical locations. The feature confusion compromises the reliability of pseudo-label generation, where incorrect pseudo-labels drive negative optimization. Given these challenges inherent in both supervised and unsupervised DVGL methods, we propose a novel cross-domain invariant knowledge transfer network (CDIKTNet) with limited supervision, whose architecture consists of a cross-domain invariance sub-network (CDIS) and a cross-domain transfer sub-network (CDTS). This architecture facilitates a closed-loop framework for invariance feature learning and knowledge transfer. The CDIS is designed to learn cross-view structural and spatial invariance from a small amount of paired data that serves as prior knowledge. It endows the shared feature space of unpaired data with similar implicit cross-view correlations at initialization, which alleviates feature confusion. Based on this, the CDTS employs dual-path contrastive learning to further optimize each subspace while preserving consistency in a shared feature space. Extensive experiments demonstrate that CDIKTNet achieves state-of-the-art performance under full supervision compared with those supervised methods, and further surpasses existing unsupervised methods in both few-shot and cross-domain initialization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes CDIKTNet for drone-view geo-localization under limited supervision. It consists of a Cross-domain Invariance Sub-network (CDIS) that learns structural and spatial invariance from a small amount of paired data to initialize the shared feature space of unpaired data with implicit cross-view correlations (reducing confusion from geographical similarity and spatial continuity), followed by a Cross-domain Transfer Sub-network (CDTS) that applies dual-path contrastive learning while preserving consistency. The authors claim this closed-loop architecture yields SOTA performance versus fully supervised methods and outperforms existing unsupervised methods in few-shot and cross-domain settings.
Significance. If the initialization mechanism in CDIS demonstrably transfers useful cross-view correlations and the reported gains hold under rigorous controls, the work would meaningfully reduce annotation requirements for DVGL while enabling better domain adaptation, bridging supervised and unsupervised regimes in a practically relevant computer vision task.
major comments (2)
- [Abstract and §3] Abstract and §3 (CDIS description): the central claim that limited paired data 'endows the shared feature space of unpaired data with similar implicit cross-view correlations at initialization, which alleviates feature confusion' is load-bearing for superiority over unsupervised baselines, yet no direct evidence (pre/post-initialization cross-view similarity metrics, feature confusion quantification, or t-SNE visualizations) is supplied to show the transfer imparts task-specific correlations rather than generic alignment.
- [Experiments] Experiments section: the abstract asserts 'extensive experiments' establishing SOTA under full supervision and gains in few-shot/cross-domain settings, but without reported dataset splits, training protocols, full quantitative tables, or ablations isolating the CDIS initialization effect, it is impossible to verify that performance differences arise from the proposed mechanism rather than pseudo-label noise or evaluation choices.
minor comments (1)
- [Abstract] The abstract contains a minor grammatical issue: 'Existing unsupervised methods have enabled to generate pseudo-labels' should be rephrased for clarity (e.g., 'have enabled generation of pseudo-labels').
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight areas where additional evidence and transparency can strengthen the manuscript. We address each major comment below and will incorporate revisions to provide the requested support for our claims.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (CDIS description): the central claim that limited paired data 'endows the shared feature space of unpaired data with similar implicit cross-view correlations at initialization, which alleviates feature confusion' is load-bearing for superiority over unsupervised baselines, yet no direct evidence (pre/post-initialization cross-view similarity metrics, feature confusion quantification, or t-SNE visualizations) is supplied to show the transfer imparts task-specific correlations rather than generic alignment.
Authors: We agree that direct empirical support for the initialization effect would strengthen the central claim. In the revised manuscript we will add t-SNE visualizations of the shared feature space before and after CDIS initialization on the same unpaired samples, together with quantitative cross-view similarity metrics (e.g., average cosine similarity between matched cross-view pairs) and a simple feature-confusion measure (e.g., intra-class vs. inter-class nearest-neighbor error). These additions will demonstrate that the limited paired data imparts task-specific correlations beyond generic alignment. revision: yes
-
Referee: [Experiments] Experiments section: the abstract asserts 'extensive experiments' establishing SOTA under full supervision and gains in few-shot/cross-domain settings, but without reported dataset splits, training protocols, full quantitative tables, or ablations isolating the CDIS initialization effect, it is impossible to verify that performance differences arise from the proposed mechanism rather than pseudo-label noise or evaluation choices.
Authors: We acknowledge that the current experimental section lacks sufficient detail for independent verification. The revised manuscript will include: (i) explicit train/validation/test splits for all datasets, (ii) complete hyper-parameter and training-protocol descriptions, (iii) full quantitative tables with all baselines and our method under identical settings, and (iv) dedicated ablation tables that isolate the CDIS initialization (e.g., CDTS-only vs. CDIS+CDTS) while controlling for pseudo-label generation. These changes will allow readers to attribute performance differences to the proposed mechanism. revision: yes
Circularity Check
No significant circularity; claims rest on proposed architecture and empirical validation
full rationale
The paper introduces CDIKTNet with CDIS (learning invariance from limited paired data as prior knowledge to initialize unpaired features) and CDTS (dual-path contrastive learning). Performance superiority is asserted via experiments against supervised and unsupervised baselines in full, few-shot, and cross-domain settings. No equations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text that would reduce the central claims to tautological inputs by construction. The initialization mechanism is a design hypothesis whose effect is externally tested rather than presupposed.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption A small amount of paired data supplies sufficient prior knowledge to initialize cross-view correlations in unpaired data and thereby reduce feature confusion
- domain assumption Dual-path contrastive learning can simultaneously optimize each subspace while preserving consistency in the shared feature space
invented entities (2)
-
Cross-domain invariance sub-network (CDIS)
no independent evidence
-
Cross-domain transfer sub-network (CDTS)
no independent evidence
Forward citations
Cited by 1 Pith paper
-
Satellite-Free Training for Drone-View Geo-Localization
A satellite-free training framework reconstructs 3D drone scenes via Gaussian splatting, generates geometry-normalized pseudo-orthophotos, and aggregates DINOv3 features with a Fisher vector model trained only on dron...
Reference graph
Works this paper leans on
-
[1]
Sample4Geo: Hard negative sampling for cross-view geo-localisation,
F. Deuser, K. Habel, and N. Oswald, “Sample4Geo: Hard negative sampling for cross-view geo-localisation,” inProc. IEEE Conf. Comput. Vis. Pattern Recognit., 2023, pp. 16 847–16 856
work page 2023
-
[2]
University-1652: A multi-view multi- source benchmark for drone-based geo-localization,
Z. Zheng, Y . Wei, and Y . Yang, “University-1652: A multi-view multi- source benchmark for drone-based geo-localization,” inProc. ACM Int. Conf. Multimedia, 2020, p. 1395–1403
work page 2020
-
[3]
SUES-200: A multi-height multi-scene cross-view image benchmark across drone and satellite,
R. Zhu, L. Yin, M. Yang, F. Wu, Y . Yang, and W. Hu, “SUES-200: A multi-height multi-scene cross-view image benchmark across drone and satellite,”IEEE Trans. Circuits Syst. Video Technol., vol. 33, no. 9, pp. 4825–4839, 2023
work page 2023
-
[4]
BEV-CV: Birds-eye-view transform for cross-view geo-localisation,
T. Shore, S. Hadfield, and O. Mendez, “BEV-CV: Birds-eye-view transform for cross-view geo-localisation,” inProc. IEEE/RSJ Int. Conf. Intell. Robots Syst., 2024, pp. 11 048–11 055
work page 2024
-
[5]
Ground-to-aerial image geo-localization with a hard exemplar reweighting triplet loss,
S. Cai, Y . Guo, S. Khan, J. Hu, and G. Wen, “Ground-to-aerial image geo-localization with a hard exemplar reweighting triplet loss,” inProc. IEEE Int. Conf. Comput. Vis., 2019, pp. 8391–8400
work page 2019
-
[6]
Multi-object tracking meets moving uav,
S. Liu, X. Li, H. Lu, and Y . He, “Multi-object tracking meets moving uav,” inProc. IEEE Conf. Comput. Vis. Pattern Recognit., 2022, pp. 8876–8885
work page 2022
-
[7]
Pvt++: A simple end-to-end latency-aware visual tracking framework,
B. Li, Z. Huang, J. Ye, Y . Li, S. Scherer, H. Zhao, and C. Fu, “Pvt++: A simple end-to-end latency-aware visual tracking framework,” inProc. IEEE Int. Conf. Comput. Vis., 2023, pp. 10 006–10 016
work page 2023
-
[8]
Multiple- environment self-adaptive network for aerial-view geo-localization,
T. Wang, Z. Zheng, Y . Sun, C. Yan, Y . Yang, and T.-S. Chua, “Multiple- environment self-adaptive network for aerial-view geo-localization,” Pattern Recognit., vol. 152, p. 110363, 2024
work page 2024
-
[9]
Q. Wu, Y . Wan, Z. Zheng, Y . Zhang, G. Wang, and Z. Zhao, “CAMP: Across-view geo-localization method using contrastive attributes mining and position-aware partitioning,”IEEE Trans. Geosci. Remote Sens., vol. 62, pp. 1–14, 2024
work page 2024
-
[10]
Z. Chen, Z.-X. Yang, and H.-J. Rong, “Multilevel embedding and alignment network with consistency and invariance learning for cross- view geo-localization,”IEEE Trans. Geosci. Remote Sens., vol. 63, pp. 1–15, 2025
work page 2025
-
[11]
MCCG: A convnext- based multiple-classifier method for cross-view geo-localization,
T. Shen, Y . Wei, L. Kang, S. Wan, and Y .-H. Yang, “MCCG: A convnext- based multiple-classifier method for cross-view geo-localization,”IEEE Trans. Circuits Syst. Video Technol., vol. 34, no. 3, pp. 1456–1468, 2023
work page 2023
-
[12]
CCR: A counterfactual causal reasoning- based method for cross-view geo-localization,
H. Du, J. He, and Y . Zhao, “CCR: A counterfactual causal reasoning- based method for cross-view geo-localization,”IEEE Trans. Circuits Syst. Video Technol., vol. 34, no. 11, pp. 11 630–11 643, 2024
work page 2024
-
[13]
Enhancing cross-view geo-localization with domain alignment and scene consistency,
P. Xia, Y . Wan, Z. Zheng, Y . Zhang, and J. Deng, “Enhancing cross-view geo-localization with domain alignment and scene consistency,”IEEE Trans. Circuits Syst. Video Technol., pp. 1–12, 2024. 12
work page 2024
-
[14]
Unsu- pervised multiview uav image geolocalization via iterative rendering,
H. Li, C. Xu, W. Yang, L. Mi, H. Yu, H. Zhang, and G.-S. Xia, “Unsu- pervised multiview uav image geolocalization via iterative rendering,” IEEE Trans. Geosci. Remote Sens., vol. 63, pp. 1–15, 2025
work page 2025
-
[15]
Learning cross- view visual geo-localization without ground truth,
H. Li, C. Xu, W. Yang, H. Yu, and G.-S. Xia, “Learning cross- view visual geo-localization without ground truth,”IEEE Trans. Geosci. Remote Sens., vol. 62, pp. 1–17, 2024
work page 2024
-
[16]
Lending orientation to neural networks for cross-view geo-localization,
L. Liu and H. Li, “Lending orientation to neural networks for cross-view geo-localization,” inProc. IEEE Conf. Comput. Vis. Pattern Recognit., 2019, p. 5624–5633
work page 2019
-
[17]
W. Hu, Y . Zhang, Y . Liang, Y . Yin, A. Georgescu, A. Tran, H. Kruppa, S.-K. Ng, and R. Zimmermann, “Beyond geo-localization: Fine-grained orientation of street-view images by cross-view matching with satellite imagery,” inProc. ACM Int. Conf. Multimedia, 2022, p. 6155–6164
work page 2022
-
[18]
Optimal feature transport for cross-view image geo-localization,
Y . Shi, X. Yu, L. Liu, T. Zhang, and H. Li, “Optimal feature transport for cross-view image geo-localization,” inProc. AAAI Conf. Artif. Intell., vol. 34, 2020, pp. 11 990–11 997
work page 2020
-
[19]
Spatial-aware feature aggregation for image based cross-view geo-localization,
Y . Shi, L. Liu, X. Yu, and H. Li, “Spatial-aware feature aggregation for image based cross-view geo-localization,”in Proc. Adv. Neural Inf. Process. Syst., vol. 32, p. 10090–10100, 2019
work page 2019
-
[20]
Cross-view geo- localization via learning disentangled geometric layout correspondence,
X. Zhang, X. Li, W. Sultani, Y . Zhou, and S. Wshah, “Cross-view geo- localization via learning disentangled geometric layout correspondence,” inProc. AAAI Conf. Artif. Intell., vol. 37, no. 3, 2023, pp. 3480–3488
work page 2023
-
[21]
Bridging viewpoints in cross-view geo-localization with siamese vision trans- former,
W.-J. Ahn, S.-Y . Park, D.-S. Pae, H.-D. Choi, and M.-T. Lim, “Bridging viewpoints in cross-view geo-localization with siamese vision trans- former,”IEEE Trans. Geosci. Remote Sens., vol. 62, pp. 1–12, 2024
work page 2024
-
[22]
Bridging the domain gap for ground-to-aerial image matching,
K. Regmi and M. Shah, “Bridging the domain gap for ground-to-aerial image matching,” inProc. IEEE Int. Conf. Comput. Vis., 2019, pp. 470– 479
work page 2019
-
[23]
Coming down to earth: Satellite-to-street view synthesis for geo-localization,
A. Toker, Q. Zhou, M. Maximov, and L. Leal-Taixe, “Coming down to earth: Satellite-to-street view synthesis for geo-localization,” inProc. IEEE Conf. Comput. Vis. Pattern Recognit., 2021, pp. 6488–6497
work page 2021
-
[24]
I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y . Bengio, “Generative adversarial nets,”in Proc. Adv. Neural Inf. Process. Syst., vol. 27, p. 2672–2680, 2014
work page 2014
-
[25]
UA V-satellite view synthesis for cross-view geo-localization,
X. Tian, J. Shao, D. Ouyang, and H. T. Shen, “UA V-satellite view synthesis for cross-view geo-localization,”IEEE Trans. Circuits Syst. Video Technol., vol. 32, no. 7, pp. 4804–4815, 2021
work page 2021
-
[26]
S. Cui, A. Ma, Y . Wan, Y . Zhong, B. Luo, and M. Xu, “Cross-modality image matching network with modality-invariant feature representation for airborne-ground thermal infrared and visible datasets,”IEEE Trans. Geosci. Remote Sens., vol. 60, pp. 1–14, 2021
work page 2021
-
[27]
F. Ge, Y . Zhang, Y . Liu, G. Wang, S. Coleman, D. Kerr, and L. Wang, “Multibranch joint representation learning based on information fusion strategy for cross-view geo-localization,”IEEE Trans. Geosci. Remote Sens., vol. 62, pp. 1–16, 2024
work page 2024
-
[28]
Direction-guided multi-scale feature fusion network for geo- localization,
H. Lv, H. Zhu, R. Zhu, F. Wu, C. Wang, M. Cai, and K. Zhang, “Direction-guided multi-scale feature fusion network for geo- localization,”IEEE Trans. Geosci. Remote Sens., vol. 62, pp. 1–13, 2024
work page 2024
-
[29]
Visible-infrared person re-identification via cross-modality interaction transformer,
Y . Feng, J. Yu, F. Chen, Y . Ji, F. Wu, S. Liu, and X.-Y . Jing, “Visible-infrared person re-identification via cross-modality interaction transformer,”IEEE Trans. Multimedia, vol. 25, pp. 7647–7659, 2023
work page 2023
-
[30]
Dsaf: Dual space alignment framework for visible-infrared person re-identification,
Y . Jiang, X. Cheng, H. Yu, X. Liu, H. Chen, and G. Zhao, “Dsaf: Dual space alignment framework for visible-infrared person re-identification,” IEEE Trans. Multimedia, vol. 27, pp. 5591–5603, 2025
work page 2025
-
[31]
Cross-modality semantic consistency learning for visible-infrared per- son re-identification,
M. Liu, Z. Zhang, Y . Bian, X. Wang, Y . Sun, B. Zhang, and Y . Wang, “Cross-modality semantic consistency learning for visible-infrared per- son re-identification,”IEEE Trans. Multimedia, vol. 27, pp. 568–580, 2025
work page 2025
-
[32]
Clip-driven semantic discovery network for visible-infrared person re-identification,
X. Yu, N. Dong, L. Zhu, H. Peng, and D. Tao, “Clip-driven semantic discovery network for visible-infrared person re-identification,”IEEE Trans. Multimedia, vol. 27, pp. 4137–4150, 2025
work page 2025
-
[33]
Occlusion-aware feature recover model for occluded person re-identification,
Y . Bian, M. Liu, X. Wang, Y . Tang, and Y . Wang, “Occlusion-aware feature recover model for occluded person re-identification,”IEEE Trans. Multimedia, vol. 26, pp. 5284–5295, 2024
work page 2024
-
[34]
Deep learning for person re-identification: A survey and outlook,
M. Ye, J. Shen, G. Lin, T. Xiang, L. Shao, and S. C. Hoi, “Deep learning for person re-identification: A survey and outlook,”IEEE Trans. Pattern Anal. Mach. Intell., vol. 44, no. 6, pp. 2872–2893, 2021
work page 2021
-
[35]
H. Zhou, T. Luo, J. Zhang, and L. Liu, “Exploring the essence of relationships for scene graph generation via causal features enhancement network,”IEEE Trans. Pattern Anal. Mach. Intell., vol. 47, no. 8, pp. 6616–6630, 2025
work page 2025
-
[36]
Nonconvex and discriminative transfer subspace learning for unsupervised domain adaptation,
Y . Liu and T. Luo, “Nonconvex and discriminative transfer subspace learning for unsupervised domain adaptation,”Front. Comput. Sci., vol. 19, no. 2, p. 192307, 2025
work page 2025
-
[37]
Cross-domain adaptive teacher for object detection,
Y .-J. Li, X. Dai, C.-Y . Ma, Y .-C. Liu, K. Chen, B. Wu, Z. He, K. Kitani, and P. Vajda, “Cross-domain adaptive teacher for object detection,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., 2022, pp. 7581–7590
work page 2022
-
[38]
Semi-supervised learning with label proportion,
N. Sun, T. Luo, W. Zhuge, H. Tao, C. Hou, and D. Hu, “Semi-supervised learning with label proportion,”IEEE Trans. Knowl. Data Eng., vol. 35, no. 1, pp. 877–890, 2021
work page 2021
-
[39]
Semi-supervised multiview feature selection with adaptive graph learning,
B. Jiang, X. Wu, X. Zhou, Y . Liu, A. G. Cohn, W. Sheng, and H. Chen, “Semi-supervised multiview feature selection with adaptive graph learning,”IEEE Trans. Neural Networks Learn. Syst., vol. 35, no. 3, pp. 3615–3629, 2022
work page 2022
-
[40]
Cross-domain gradient discrepancy minimization for unsupervised domain adaptation,
Z. Du, J. Li, H. Su, L. Zhu, and K. Lu, “Cross-domain gradient discrepancy minimization for unsupervised domain adaptation,” inProc. IEEE Conf. Comput. Vis. Pattern Recognit., 2021, pp. 3937–3946
work page 2021
-
[41]
Relation- preserving feature embedding for unsupervised person re-identification,
X. Wang, M. Liu, F. Wang, J. Dai, A.-A. Liu, and Y . Wang, “Relation- preserving feature embedding for unsupervised person re-identification,” IEEE Trans. Multimedia, vol. 26, pp. 714–723, 2024
work page 2024
-
[42]
Y . Tao, J. Zhang, J. Hong, and Y . Zhu, “Dreamt: Diversity enlarged mu- tual teaching for unsupervised domain adaptive person re-identification,” IEEE Trans. Multimedia, vol. 25, pp. 4586–4597, 2023
work page 2023
-
[43]
Camera invariant feature learn- ing for unsupervised person re-identification,
Z. Pang, L. Zhao, Q. Liu, and C. Wang, “Camera invariant feature learn- ing for unsupervised person re-identification,”IEEE Trans. Multimedia, vol. 25, pp. 6171–6182, 2023
work page 2023
-
[44]
Ice: Inter-instance contrastive encoding for unsupervised person re-identification,
H. Chen, B. Lagadec, and F. Bremond, “Ice: Inter-instance contrastive encoding for unsupervised person re-identification,” inProc. IEEE Int. Conf. Comput. Vis., 2021, pp. 14 960–14 969
work page 2021
-
[45]
Intra-inter camera similarity for unsupervised person re-identification,
S. Xuan and S. Zhang, “Intra-inter camera similarity for unsupervised person re-identification,” inProc. IEEE Conf. Comput. Vis. Pattern Recognit., 2021, pp. 11 926–11 935
work page 2021
-
[46]
Cluster contrast for unsupervised person re-identification,
Z. Dai, G. Wang, W. Yuan, S. Zhu, and P. Tan, “Cluster contrast for unsupervised person re-identification,” inProc. Asian Conf. Comput. Vis., 2022, pp. 1142–1160
work page 2022
-
[47]
A density-based algorithm for discovering clusters in large spatial databases with noise,
M. Ester, H.-P. Kriegel, J. Sander, X. Xuet al., “A density-based algorithm for discovering clusters in large spatial databases with noise,” inProc. ACM SIGKDD Int. Conf. Knowl. Discov. Data Min., vol. 96, no. 34, 1996, pp. 226–231
work page 1996
-
[48]
B. Yang, M. Ye, J. Chen, and Z. Wu, “Augmented dual-contrastive aggregation learning for unsupervised visible-infrared person re- identification,” inProc. ACM Int. Conf. Multimedia, 2022, pp. 2843– 2851
work page 2022
-
[49]
Shallow-deep collaborative learning for unsupervised visible-infrared person re-identification,
B. Yang, J. Chen, and M. Ye, “Shallow-deep collaborative learning for unsupervised visible-infrared person re-identification,” inProc. IEEE Conf. Comput. Vis. Pattern Recognit., 2024, pp. 16 870–16 879
work page 2024
-
[50]
Z. Liu, H. Mao, C.-Y . Wu, C. Feichtenhofer, T. Darrell, and S. Xie, “A convnet for the 2020s,” inProc. IEEE Conf. Comput. Vis. Pattern Recognit., 2022, pp. 11 976–11 986
work page 2022
-
[51]
Squeeze-and-excitation networks,
J. Hu, L. Shen, and G. Sun, “Squeeze-and-excitation networks,” inProc. IEEE Conf. Comput. Vis. Pattern Recognit., 2018, pp. 7132–7141
work page 2018
-
[52]
Representation Learning with Contrastive Predictive Coding
A. v. d. Oord, Y . Li, and O. Vinyals, “Representation learning with contrastive predictive coding,”arXiv preprint arXiv:1807.03748, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[53]
B. Yang, M. Ye, J. Chen, and Z. Wu, “Augmented dual-contrastive aggregation learning for unsupervised visible-infrared person re- identification,” inACM MM, 2022, p. 2843–2851
work page 2022
-
[54]
The global k-means clustering algorithm,
A. Likas, N. Vlassis, and J. J. Verbeek, “The global k-means clustering algorithm,”Pattern Recognit., vol. 36, no. 2, pp. 451–461, 2003
work page 2003
-
[55]
H. Zhao, K. Ren, T. Yue, C. Zhang, and S. Yuan, “TransFG: A cross- view geo-localization of satellite and UA Vs imagery pipeline using transformer-based feature aggregation and gradient guidance,”IEEE Trans. Geosci. Remote Sens., vol. 62, pp. 1–12, 2024
work page 2024
-
[56]
Revisit anything: Visual place recognition via image segment retrieval,
K. Garg, S. S. Puligilla, S. Kolathaya, M. Krishna, and S. Garg, “Revisit anything: Visual place recognition via image segment retrieval,” inProc. Eur . Conf. Comput. Vis., 2024, pp. 326–343
work page 2024
-
[57]
Anyloc: Towards universal visual place recognition,
N. Keetha, A. Mishra, J. Karhade, K. M. Jatavallabhula, S. Scherer, M. Krishna, and S. Garg, “Anyloc: Towards universal visual place recognition,”IEEE Rob. Autom. Lett, vol. 9, no. 2, pp. 1286–1293, 2023
work page 2023
-
[58]
Vision- based uav self-positioning in low-altitude urban environments,
M. Dai, E. Zheng, Z. Feng, L. Qi, J. Zhuang, and W. Yang, “Vision- based uav self-positioning in low-altitude urban environments,”IEEE Trans. Image Process., vol. 33, pp. 493–508, 2024
work page 2024
-
[59]
L. Van der Maaten and G. Hinton, “Visualizing data using t-SNE.”J. Mach. Learn. Res, vol. 9, no. 11, pp. 2579–2605, 2008
work page 2008
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.