Recognition: 2 theorem links
· Lean TheoremSatellite-Free Training for Drone-View Geo-Localization
Pith reviewed 2026-05-13 21:48 UTC · model grok-4.3
The pith
Drone geo-localization can be trained using only multi-view drone images by reconstructing 3D scenes and generating pseudo-orthophotos.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The satellite-free training (SFT) framework converts multi-view drone imagery into cross-view compatible representations through drone-side 3D scene reconstruction with 3D Gaussian splatting, PCA-guided orthographic projection to generate pseudo-orthophotos, lightweight geometry-guided inpainting, and Fisher vector aggregation of DINOv3 features learned solely from drone data for cross-view retrieval against satellite galleries.
What carries the argument
Geometry-normalized pseudo-orthophoto generation from 3D Gaussian splatting reconstructions of multi-view drone sequences, which preserves cross-view matching information without satellite supervision.
If this is right
- Enables geo-localization training in environments where satellite imagery is unavailable or restricted.
- Outperforms other satellite-free generalization baselines on University-1652 and SUES-200 datasets.
- Narrows the performance gap to methods that train with paired or aligned satellite imagery.
- Allows the learned Fisher vector model to encode satellite tiles directly at test time for retrieval.
- Supports practical deployment of drone geo-localization systems without external data dependencies.
Where Pith is reading between the lines
- Better 3D reconstruction algorithms could reduce the remaining gap to fully satellite-supervised performance.
- The approach could apply to other cross-view localization tasks if multi-view sequences from ground or other platforms are substituted for drone data.
- Lower dependence on satellite data may enable use in restricted airspace or privacy-sensitive regions.
- Testing on datasets with sparse drone coverage would reveal how reconstruction completeness affects retrieval success.
Load-bearing premise
The 3D scene reconstruction from multi-view drone images must be accurate and complete enough to produce pseudo-orthophotos that retain the necessary information for matching to satellite views.
What would settle it
If retrieval accuracy on University-1652 using the drone-trained model shows no improvement over satellite-free baselines when 3D reconstruction quality is degraded by limited input views or noisy geometry.
Figures







read the original abstract
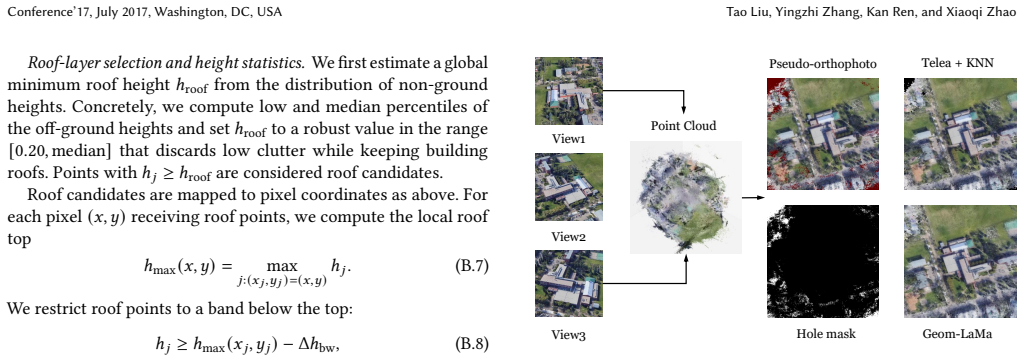
Drone-view geo-localization (DVGL) aims to determine the location of drones in GPS-denied environments by retrieving the corresponding geotagged satellite tile from a reference gallery given UAV observations of a location. In many existing formulations, these observations are represented by a single oblique UAV image. In contrast, our satellite-free setting is designed for multi-view UAV sequences, which are used to construct a geometry-normalized UAV-side location representation before cross-view retrieval. Existing approaches rely on satellite imagery during training, either through paired supervision or unsupervised alignment, which limits practical deployment when satellite data are unavailable or restricted. In this paper, we propose a satellite-free training (SFT) framework that converts drone imagery into cross-view compatible representations through three main stages: drone-side 3D scene reconstruction, geometry-based pseudo-orthophoto generation, and satellite-free feature aggregation for retrieval. Specifically, we first reconstruct dense 3D scenes from multi-view drone images using 3D Gaussian splatting and project the reconstructed geometry into pseudo-orthophotos via PCA-guided orthographic projection. This rendering stage operates directly on reconstructed scene geometry without requiring camera parameters at rendering time. Next, we refine these orthophotos with lightweight geometry-guided inpainting to obtain texture-complete drone-side views. Finally, we extract DINOv3 patch features from the generated orthophotos, learn a Fisher vector aggregation model solely from drone data, and reuse it at test time to encode satellite tiles for cross-view retrieval. Experimental results on University-1652 and SUES-200 show that our SFT framework substantially outperforms satellite-free generalization baselines and narrows the gap to methods trained with satellite imagery.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a satellite-free training (SFT) framework for drone-view geo-localization using multi-view UAV sequences. It reconstructs dense 3D scenes from drone images via 3D Gaussian splatting, generates geometry-normalized pseudo-orthophotos through PCA-guided orthographic projection and geometry-guided inpainting, extracts DINOv3 patch features, and trains a Fisher vector aggregation model exclusively on drone-derived data. This aggregator is then reused at test time to encode real satellite tiles for cross-view retrieval. Experiments on University-1652 and SUES-200 are reported to show substantial gains over satellite-free baselines while narrowing the gap to satellite-supervised methods.
Significance. If the reconstruction and projection pipeline reliably produces cross-view compatible representations, the work addresses a key practical barrier in DVGL by removing the need for satellite imagery during training. The integration of 3D Gaussian splatting for geometry normalization and DINOv3 features offers a timely approach that could enable deployment in restricted environments, provided the central assumption on reconstruction fidelity holds.
major comments (3)
- [§3.1] §3.1 (3D scene reconstruction): No quantitative metrics on reconstruction quality (e.g., completeness, PSNR, or geometric accuracy) are reported for the 3D Gaussian splatting step. This is load-bearing because the central claim that PCA-guided pseudo-orthophotos preserve cross-view matching information depends directly on dense, accurate geometry; incompleteness in textureless or occluded regions would undermine the satellite-free pipeline.
- [§3.2] §3.2 (pseudo-orthophoto generation): The PCA-guided orthographic projection is presented as operating without camera parameters at render time, yet no ablation or fidelity analysis quantifies projection distortions or their impact on DINOv3 feature alignment with real satellite tiles. This directly affects whether the geometry normalization enables the claimed retrieval performance.
- [Experimental results] Experimental results section: The abstract and results claim outperformance on University-1652 and SUES-200 without tables, ablation studies, error bars, or details on baseline re-implementations. This prevents verification of whether the gains are robust or affected by dataset-specific choices, weakening the central experimental claim.
minor comments (2)
- [§3.3] The description of the Fisher vector aggregation model lacks explicit equations for how drone-only training parameters are applied to satellite tiles at inference, which could clarify domain adaptation.
- Figure captions for the pipeline overview should explicitly label each stage (reconstruction, projection, inpainting) to improve readability.
Simulated Author's Rebuttal
We are grateful to the referee for their thorough review and valuable suggestions. We have carefully considered each comment and provide point-by-point responses below. We believe these revisions will strengthen the manuscript.
read point-by-point responses
-
Referee: [§3.1] §3.1 (3D scene reconstruction): No quantitative metrics on reconstruction quality (e.g., completeness, PSNR, or geometric accuracy) are reported for the 3D Gaussian splatting step. This is load-bearing because the central claim that PCA-guided pseudo-orthophotos preserve cross-view matching information depends directly on dense, accurate geometry; incompleteness in textureless or occluded regions would undermine the satellite-free pipeline.
Authors: We agree with the referee that providing quantitative metrics for the 3D Gaussian splatting reconstruction would enhance the credibility of our claims. In the revised manuscript, we will report PSNR, SSIM, and LPIPS on held-out drone views for the reconstructed scenes on University-1652 and SUES-200. We will also discuss any observed limitations in textureless regions and how the geometry-guided inpainting mitigates them. This addition will directly address the load-bearing nature of the reconstruction quality. revision: yes
-
Referee: [§3.2] §3.2 (pseudo-orthophoto generation): The PCA-guided orthographic projection is presented as operating without camera parameters at render time, yet no ablation or fidelity analysis quantifies projection distortions or their impact on DINOv3 feature alignment with real satellite tiles. This directly affects whether the geometry normalization enables the claimed retrieval performance.
Authors: We thank the referee for highlighting this aspect. While the PCA-guided projection is designed to normalize geometry without explicit camera parameters, we acknowledge the value of quantitative validation. In the revision, we will include an ablation study that compares retrieval performance with and without the PCA guidance, as well as fidelity metrics such as structural similarity between pseudo-orthophotos and corresponding satellite tiles. This will quantify the impact on DINOv3 feature alignment and support the effectiveness of the geometry normalization. revision: yes
-
Referee: Experimental results section: The abstract and results claim outperformance on University-1652 and SUES-200 without tables, ablation studies, error bars, or details on baseline re-implementations. This prevents verification of whether the gains are robust or affected by dataset-specific choices, weakening the central experimental claim.
Authors: We apologize if the experimental presentation was insufficiently detailed. The manuscript includes performance tables for University-1652 and SUES-200, but to improve clarity and verifiability, we will add comprehensive ablation studies for each module of the SFT framework, report standard deviations across multiple training runs as error bars, and provide detailed descriptions of baseline implementations including code references and hyperparameter settings. These enhancements will allow readers to better assess the robustness of the reported gains. revision: yes
Circularity Check
No significant circularity; self-contained drone-to-satellite transfer pipeline
full rationale
The derivation proceeds as: multi-view drone images are reconstructed via 3D Gaussian splatting into dense geometry; PCA-guided orthographic projection produces pseudo-orthophotos without camera parameters at render time; geometry-guided inpainting yields texture-complete views; DINOv3 patch features are extracted and a Fisher-vector aggregation model is learned exclusively from these drone-derived orthophotos; the same model is applied at test time to encode real satellite tiles for retrieval. No equation reduces the final cross-view matching score to a parameter fitted from satellite targets, no self-citation supplies a load-bearing uniqueness theorem or ansatz, and the Fisher-vector step is a standard transfer of a model trained on one domain to another rather than a definitional renaming. Experimental claims on University-1652 and SUES-200 are therefore independent of the training data source and do not collapse by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Dense 3D scenes can be reconstructed from multi-view drone images using 3D Gaussian splatting without external camera calibration at inference time.
- domain assumption PCA-guided orthographic projection of reconstructed geometry produces views that are compatible with satellite tiles for feature matching.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
reconstruct dense 3D scenes from multi-view drone images using 3D Gaussian splatting and project the reconstructed geometry into pseudo-orthophotos via PCA-guided orthographic projection
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
learn a Fisher vector aggregation model solely from drone data
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Zhongwei Chen, Zhao-Xu Yang, Hai-Jun Rong, and Jiawei Lang. 2025. From Limited Labels to Open Domains: An Efficient Learning Paradigm for UAV-view Geo-Localization.arXiv preprint arXiv:2503.07520(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [2]
-
[3]
Ming Dai, Jianhong Hu, Jiedong Zhuang, and Enhui Zheng. 2021. A transformer- based feature segmentation and region alignment method for UAV-view geo- localization.IEEE Transactions on Circuits and Systems for Video Technology32, 7 (2021), 4376–4389
work page 2021
-
[4]
Arthur P Dempster, Nan M Laird, and Donald B Rubin. 1977. Maximum likelihood from incomplete data via the EM algorithm.Journal of the royal statistical society: series B (methodological)39, 1 (1977), 1–22
work page 1977
-
[5]
Fabian Deuser, Konrad Habel, and Norbert Oswald. 2023. Sample4geo: Hard negative sampling for cross-view geo-localisation. InProceedings of the IEEE/CVF International Conference on Computer Vision. 16847–16856
work page 2023
-
[6]
Alexey Dosovitskiy. 2020. An image is worth 16x16 words: Transformers for image recognition at scale.arXiv preprint arXiv:2010.11929(2020)
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[7]
Martin A Fischler and Robert C Bolles. 1981. Random sample consensus: a paradigm for model fitting with applications to image analysis and automated cartography.Commun. ACM24, 6 (1981), 381–395
work page 1981
-
[8]
Fawei Ge, Yunzhou Zhang, Li Wang, Wei Liu, Yixiu Liu, Sonya Coleman, and Der- mot Kerr. 2024. Multilevel feedback joint representation learning network based on adaptive area elimination for cross-view geo-localization.IEEE transactions on geoscience and remote sensing62 (2024), 1–15
work page 2024
-
[9]
Ali Hatamizadeh and Jan Kautz. 2025. Mambavision: A hybrid mamba- transformer vision backbone. InProceedings of the Computer Vision and Pattern Recognition Conference. 25261–25270
work page 2025
-
[10]
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 2016. Deep residual learning for image recognition. InProceedings of the IEEE conference on computer vision and pattern recognition. 770–778
work page 2016
-
[11]
Alex Horton and Siobhán O’Grady. 2025. U.S. suspends commercial satellite imagery service to Ukraine. The Washington Post. https://www.washingtonpost. com/national-security/2025/03/07/maxar-ukraine-sateliite-imagery/
work page 2025
-
[12]
Arnold Irschara, Christopher Zach, Jan-Michael Frahm, and Horst Bischof. 2009. From structure-from-motion point clouds to fast location recognition. In2009 IEEE Conference on Computer Vision and Pattern Recognition. IEEE, 2599–2606
work page 2009
-
[13]
Howoong Jun, Hyeonwoo Yu, and Songhwai Oh. 2024. Renderable street view map-based localization: Leveraging 3d gaussian splatting for street-level position- ing. In2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 5635–5640
work page 2024
-
[14]
Nikhil Keetha, Avneesh Mishra, Jay Karhade, Krishna Murthy Jatavallabhula, Sebastian Scherer, Madhava Krishna, and Sourav Garg. 2023. Anyloc: Towards universal visual place recognition.IEEE Robotics and Automation Letters9, 2 (2023), 1286–1293
work page 2023
-
[15]
Bernhard Kerbl, Georgios Kopanas, Thomas Leimkühler, and George Drettakis
-
[16]
3D Gaussian splatting for real-time radiance field rendering.ACM Trans. Graph.42, 4 (2023), 139–1
work page 2023
-
[17]
Guopeng Li, Ming Qian, and Gui-Song Xia. 2024. Unleashing unlabeled data: A paradigm for cross-view geo-localization. InProceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition. 16719–16729
work page 2024
-
[18]
Haoyuan Li, Chang Xu, Wen Yang, Li Mi, Huai Yu, Haijian Zhang, and Gui-Song Xia. 2025. Unsupervised Multi-view UAV Image Geo-localization via Iterative Rendering.IEEE Transactions on Geoscience and Remote Sensing(2025)
work page 2025
-
[19]
Haoyuan Li, Chang Xu, Wen Yang, Huai Yu, and Gui-Song Xia. 2024. Learning cross-view visual geo-localization without ground truth.IEEE Transactions on Geoscience and Remote Sensing(2024)
work page 2024
-
[20]
Jinliang Lin, Zhiming Luo, Dazhen Lin, Shaozi Li, and Zhun Zhong. 2024. A self-adaptive feature extraction method for aerial-view geo-localization.IEEE Transactions on Image Processing(2024)
work page 2024
-
[21]
Tao Liu, Kan Ren, and Qian Chen. 2026. DiffusionUavLoc: Visually Prompted Diffusion for Cross-View UAV Localization.IEEE Internet of Things Journal (2026)
work page 2026
-
[22]
Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, and Saining Xie. 2022. A convnet for the 2020s. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 11976–11986
work page 2022
- [23]
-
[24]
Ben Mildenhall, Pratul P Srinivasan, Matthew Tancik, Jonathan T Barron, Ravi Ramamoorthi, and Ren Ng. 2021. Nerf: Representing scenes as neural radiance fields for view synthesis.Commun. ACM65, 1 (2021), 99–106
work page 2021
-
[25]
Arthur Moreau, Nathan Piasco, Dzmitry Tsishkou, Bogdan Stanciulescu, and Arnaud de La Fortelle. 2022. Lens: Localization enhanced by nerf synthesis. In Conference on Robot Learning. PMLR, 1347–1356
work page 2022
-
[26]
Illia Novikov and Jon Gambrell. 2025. Russia attacks Ukraine’s energy supplies as US cuts its access to satellite images. AP News. https://apnews.com/article/ 942d5fa7c9bdd42e6361e5fa7ddb3ae3
work page 2025
-
[27]
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy Vo, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El- Nouby, et al. 2023. Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[28]
Linfei Pan, Dániel Baráth, Marc Pollefeys, and Johannes L Schönberger. 2024. Global structure-from-motion revisited. InEuropean Conference on Computer Vision. Springer, 58–77
work page 2024
-
[29]
Florent Perronnin, Jorge Sánchez, and Thomas Mensink. 2010. Improving the fisher kernel for large-scale image classification. InEuropean conference on com- puter vision. Springer, 143–156
work page 2010
-
[30]
Tianrui Shen, Yingmei Wei, Lai Kang, Shanshan Wan, and Yee-Hong Yang
-
[31]
MCCG: A ConvNeXt-based multiple-classifier method for cross-view geo-localization.IEEE Transactions on Circuits and Systems for Video Technology 34, 3 (2023), 1456–1468
work page 2023
-
[32]
Oriane Siméoni, Huy V Vo, Maximilian Seitzer, Federico Baldassarre, Maxime Oquab, Cijo Jose, Vasil Khalidov, Marc Szafraniec, Seungeun Yi, Michaël Rama- monjisoa, et al. 2025. Dinov3.arXiv preprint arXiv:2508.10104(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
Jian Sun, Junlang Huang, Xinyu Jiang, Yimin Zhou, and Chi-Man VONG. 2025. CGSI: Context-Guided and UAV’s Status Informed Multimodal Framework for Generalizable Cross-View Geo-Localization.IEEE Transactions on Circuits and Systems for Video Technology(2025)
work page 2025
-
[34]
Jian Sun, Hao Sun, Lin Lei, Kefeng Ji, and Gangyao Kuang. 2024. TirSA: A three stage approach for UAV-satellite cross-view geo-localization based on self- supervised feature enhancement.IEEE Transactions on Circuits and Systems for Video Technology34, 9 (2024), 7882–7895
work page 2024
-
[35]
Roman Suvorov, Elizaveta Logacheva, Anton Mashikhin, Anastasia Remizova, Arsenii Ashukha, Aleksei Silvestrov, Naejin Kong, Harshith Goka, Kiwoong Park, and Victor Lempitsky. 2022. Resolution-robust large mask inpainting with fourier convolutions. InProceedings of the IEEE/CVF winter conference on applications of computer vision. 2149–2159
work page 2022
-
[36]
Alexandru Telea. 2004. An image inpainting technique based on the fast marching method.Journal of graphics tools9, 1 (2004), 23–34
work page 2004
-
[37]
Tingyu Wang, Zhedong Zheng, Chenggang Yan, Jiyong Zhang, Yaoqi Sun, Bolun Zheng, and Yi Yang. 2021. Each part matters: Local patterns facilitate cross-view geo-localization.IEEE Transactions on Circuits and Systems for Video Technology 32, 2 (2021), 867–879
work page 2021
-
[38]
Xueyi Wang, Lele Zhang, Zheng Fan, Yang Liu, Chen Chen, and Fang Deng. 2025. From Coarse to Fine: A Matching and Alignment Framework for Unsupervised Cross-View Geo-Localization. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 39. 8024–8032
work page 2025
-
[39]
Yuntao Wang, Jinpu Zhang, Ruonan Wei, Wenbo Gao, and Yuehuan Wang. 2024. Mfrgn: Multi-scale feature representation generalization network for ground-to- aerial geo-localization. InProceedings of the 32nd ACM International Conference on Multimedia. 2574–2583. Conference’17, July 2017, Washington, DC, USA Tao Liu, Yingzhi Zhang, Kan Ren, and Xiaoqi Zhao Tab...
work page 2024
-
[40]
Jiahao Wen, Hang Yu, and Zhedong Zheng. 2025. WeatherPrompt: Multi-modality Representation Learning for All-Weather Drone Visual Geo-Localization. In NeurIPS
work page 2025
-
[41]
Jian Yang, David Zhang, Alejandro F Frangi, and Jing-yu Yang. 2004. Two- dimensional PCA: a new approach to appearance-based face representation and recognition.IEEE transactions on pattern analysis and machine intelligence26, 1 (2004), 131–137
work page 2004
-
[42]
Patricia Zengerle. 2025. US government revokes some access to satellite imagery for Ukraine. Reuters. https://www.reuters.com/world/us-aerospace-firm-maxar- disables-satellite-photos-ukraine-2025-03-07/ Reporting by Patricia Zengerle; Editing by Daniel Wallis
work page 2025
-
[43]
Zichao Zhang, Torsten Sattler, and Davide Scaramuzza. 2021. Reference pose gen- eration for long-term visual localization via learned features and view synthesis. International Journal of Computer Vision129, 4 (2021), 821–844
work page 2021
-
[44]
Zhedong Zheng, Yunchao Wei, and Yi Yang. 2020. University-1652: A multi-view multi-source benchmark for drone-based geo-localization. InProceedings of the 28th ACM international conference on Multimedia. 1395–1403
work page 2020
-
[45]
Zhedong Zheng, Liang Zheng, Michael Garrett, Yi Yang, Mingliang Xu, and Yi-Dong Shen. 2020. Dual-path convolutional image-text embeddings with instance loss.ACM Transactions on Multimedia Computing, Communications, and Applications (TOMM)16, 2 (2020), 1–23
work page 2020
-
[46]
Qunjie Zhou, Maxim Maximov, Or Litany, and Laura Leal-Taixé. 2024. The nerfect match: Exploring nerf features for visual localization. InEuropean Conference on Computer Vision. Springer, 108–127
work page 2024
-
[47]
Xin Zhou, Xuerong Yang, and Yanchun Zhang. 2025. Cdm-net: A framework for cross-view geo-localization with multimodal data.IEEE Transactions on Geoscience and Remote Sensing(2025)
work page 2025
-
[48]
Runzhe Zhu, Ling Yin, Mingze Yang, Fei Wu, Yuncheng Yang, and Wenbo Hu
-
[49]
SUES-200: A multi-height multi-scene cross-view image benchmark across drone and satellite.IEEE Transactions on Circuits and Systems for Video Technology 33, 9 (2023), 4825–4839. A Details of 3DGS Reconstruction and Point-Cloud Conversion This appendix describes the implementation of the 3DGS [15] re- construction and the conversion from Gaussians to a de...
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.