Beyond Final Code: A Process-Oriented Error Analysis of Software Development Agents in Real-World GitHub Scenarios
Pith reviewed 2026-05-23 00:47 UTC · model grok-4.3
The pith
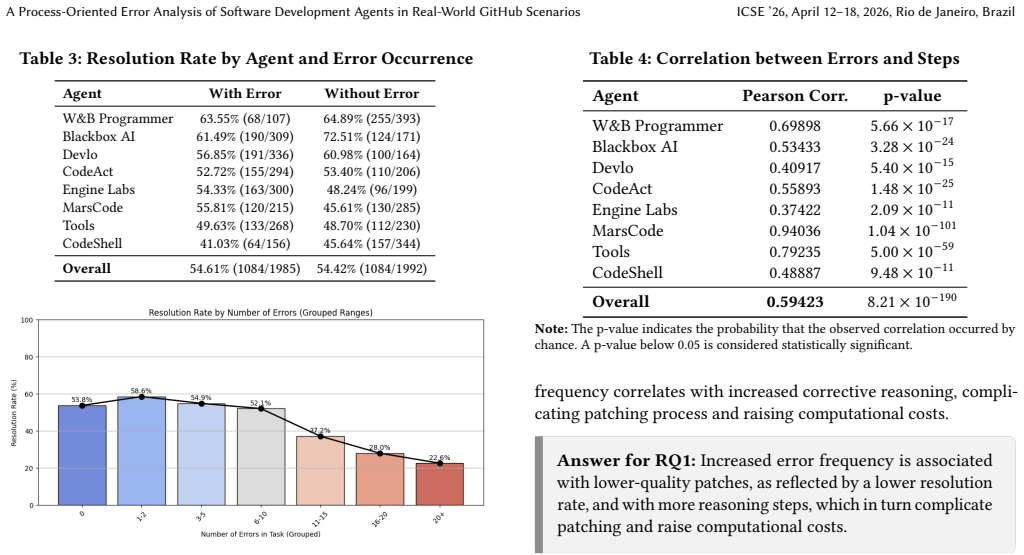
Python execution errors during agent issue resolution correlate with lower success rates and higher reasoning costs on GitHub tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Execution errors arising inside the multi-step resolution process of LLM-based software agents on repository-level GitHub issues correlate with lower resolution rates and increased reasoning overhead; the most frequent errors are ModuleNotFoundError and TypeError while OSError and IntegrityError demand the largest debugging effort, and three platform bugs that distort benchmark accuracy were identified and reported.
What carries the argument
Process-oriented analysis of solving-phase trajectories and testing-phase logs to extract Python execution errors and measure their correlation with resolution success and step count.
If this is right
- Agents that encounter ModuleNotFoundError or TypeError during editing show measurably lower final resolution rates.
- OSError and database-related errors require substantially more reasoning steps than other error classes.
- Three specific bugs in the SWE-Bench platform were shown to affect fairness and have been confirmed by maintainers.
- Public release of the trajectory dataset and analysis scripts enables direct replication and extension of the error patterns.
Where Pith is reading between the lines
- Targeted improvements in how agents detect and recover from the identified error classes could raise overall resolution rates.
- Static final-patch evaluation alone misses the process-level signals that predict failure.
- Benchmark maintainers may need to audit execution environments more rigorously to avoid hidden platform artifacts.
Load-bearing premise
The recorded trajectories and logs accurately reflect the agents' genuine dynamic problem-solving behavior on the GitHub issues without substantial distortion introduced by particular agent designs or benchmark setup choices.
What would settle it
Repeating the same error-correlation analysis on trajectories from a fresh set of agents or a different issue benchmark and observing no statistical link between the listed error types and resolution rates would falsify the central correlation claim.
Figures

read the original abstract
AI-driven software development has rapidly advanced with the emergence of software development agents that leverage large language models (LLMs) to tackle complex, repository-level software engineering tasks. These agents go beyond just generation of final code; they engage in multi-step reasoning, utilize various tools for code modification and debugging, and interact with execution environments to diagnose and iteratively resolve issues. However, most existing evaluations focus primarily on static analyses of final code outputs, yielding limited insights into the agents' dynamic problem-solving processes. To fill this gap, we conduct an in-depth empirical study on 3,977 solving-phase trajectories and 3,931 testing-phase logs from 8 top-ranked agents evaluated on 500 GitHub issues in the SWE-Bench benchmark. Our exploratory analysis shows that Python execution errors during the issue resolution phase correlate with lower resolution rates and increased reasoning overheads. We have identified the most prevalent errors -- such as ModuleNotFoundError and TypeError -- and highlighted particularly challenging errors like OSError and database-related issues (e.g., IntegrityError) that demand significantly more debugging effort. Furthermore, we have discovered 3 bugs in the SWE-Bench platform that affect benchmark fairness and accuracy; these issues have been reported to and confirmed by the maintainers. To promote transparency and foster future research, we publicly share our datasets and analysis scripts.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper performs an empirical analysis of 3,977 solving-phase trajectories and 3,931 testing-phase logs from eight agents on 500 SWE-Bench issues. It reports that Python execution errors during resolution correlate with lower success rates and higher reasoning overhead, catalogs frequent errors (e.g., ModuleNotFoundError, TypeError) and high-effort ones (e.g., OSError, IntegrityError), and documents three confirmed bugs in the SWE-Bench platform itself.
Significance. If the reported correlations and error distributions hold after full verification of the released datasets, the work supplies a process-level view of agent behavior that is currently missing from static final-code evaluations. Public release of trajectories, logs, and analysis scripts is a concrete strength that supports reproducibility and follow-on studies.
minor comments (2)
- [§4] §4 (Error Categorization): the description of how execution logs were parsed into error types should explicitly state the handling of multi-line tracebacks and repeated errors within a single trajectory to allow exact replication.
- [Table 2] Table 2: the column reporting 'average reasoning steps' for each error type would benefit from also showing the number of trajectories contributing to each mean, given the highly skewed error frequencies.
Simulated Author's Rebuttal
We thank the referee for their positive assessment of the manuscript, including recognition of the process-level insights, the public release of trajectories and scripts, and the recommendation to accept. No major comments were raised that require point-by-point rebuttal.
Circularity Check
No significant circularity
full rationale
The paper is a purely observational empirical study analyzing 3,977 solving-phase trajectories and 3,931 testing-phase logs from 8 agents on 500 SWE-Bench issues. It reports error frequencies, correlations with resolution rates and overheads, and identifies three platform bugs, all without equations, derivations, fitted parameters, or load-bearing self-citations. Claims rest on direct data inspection and public release of datasets/scripts; no step reduces to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption SWE-Bench provides representative GitHub issues and valid execution environments for measuring agent performance
Forward citations
Cited by 8 Pith papers
-
Counterfactual Trace Auditing of LLM Agent Skills
CTA framework detects 522 skill influence patterns in LLM agent traces across 49 tasks where average pass rate shifts only +0.3%, exposing evaluation gaps in behavioral effects like template copying and excess planning.
-
Debugging the Debuggers: Failure-Anchored Structured Recovery for Software Engineering Agents
PROBE structures runtime telemetry into diagnoses and evidence-grounded guidance, raising recovery rates by 12.45 points over baselines on 257 unresolved software repair and AIOps cases.
-
Reproduction Test Generation for Java SWE Issues
Presents the first benchmark and adapted solution for generating reproduction tests from Java software issues.
-
Beyond Resolution Rates: Behavioral Drivers of Coding Agent Success and Failure
Large-scale trajectory analysis of 19 coding agents on 500 tasks finds that LLM choice drives outcomes more than framework design and that context-gathering plus validation behaviors improve success beyond task diffic...
-
CodeOCR: On the Effectiveness of Vision Language Models in Code Understanding
Multimodal LLMs process code as images to achieve up to 8x token compression, with visual cues like syntax highlighting aiding tasks and clone detection remaining resilient or even improving under compression.
-
Reproduction Test Generation for Java SWE Issues
Introduces the first benchmark for Java reproduction test generation from repository issues and adapts a prior Python tool to produce high performance on it.
-
Can Old Tests Do New Tricks for Resolving SWE Issues?
TestPrune minimizes regression test suites to improve bug reproduction and patch validation in LLM-based agentic repair pipelines, delivering 6-13% relative gains on SWE-Bench benchmarks at low API cost.
-
PYTHALAB-MERA: Validation-Grounded Memory, Retrieval, and Acceptance Control for Frozen-LLM Coding Agents
An external controller for frozen LLMs raises strict validation success on three RL coding tasks from 0/9 to 8/9 by selecting memory records and skills, running fail-fast checks, and propagating credit via eligibility traces.
Reference graph
Works this paper leans on
-
[1]
Yuntong , Haifeng Ruan, Zhiyu Fan, and Abhik Roychoudhury. 2024. Au- toCodeRover: Autonomous Program Improvement. InProceedings of the 33rd ACM SIGSOFT International Symposium on Software Testing and Analysis(Vienna, Austria)(ISSTA 2024). Association for Computing Machinery, New York, NY, USA, 1592–1604. doi:10.1145/3650212.3680384
-
[2]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Floren- cia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. 2023. Gpt-4 technical report.arXiv preprint arXiv:2303.08774 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Toufique Ahmed and Premkumar Devanbu. 2022. Few-shot training llms for project-specific code-summarization. InProceedings of the 37th IEEE/ACM inter- national conference on automated software engineering. 1–5
work page 2022
-
[4]
2025.How Context7 MCP by Upstash Transformed My VSCode and Copilot Workflow
Matteo Ferruccio Andreoni. 2025.How Context7 MCP by Upstash Transformed My VSCode and Copilot Workflow. https://medium.com/@matteo28/how- context7-mcp-by-upstash-transformed-my-vscode-and-copilot-workflow- 1658a7826ec4 Online; accessed 2025-07-10
work page 2025
-
[5]
Owura Asare, Meiyappan Nagappan, and N Asokan. 2023. Is github’s copilot as bad as humans at introducing vulnerabilities in code?Empirical Software Engineering28, 6 (2023), 129
work page 2023
-
[6]
Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, et al. 2021. Program synthesis with large language models.arXiv preprint arXiv:2108.07732(2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[7]
Dongping Chen, Ruoxi Chen, Shilin Zhang, Yaochen Wang, Yinuo Liu, Huichi Zhou, Qihui Zhang, Yao Wan, Pan Zhou, and Lichao Sun. 2024. Mllm-as-a- judge: Assessing multimodal llm-as-a-judge with vision-language benchmark. In Forty-first International Conference on Machine Learning
work page 2024
-
[8]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde De Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. 2021. Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374(2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[9]
Zhi Chen and Lingxiao Jiang. 2024. Evaluating Software Development Agents: Patch Patterns, Code Quality, and Issue Complexity in Real-World GitHub Sce- narios. In32nd IEEE International Conference on Software Analysis, Evolution, and Reengineering (SANER 2025). arXivpreprintarXiv:2410.12468
-
[10]
Zhi Chen and Lingxiao Jiang. 2024. Promise and Peril of Collaborative Code Generation Models: Balancing Effectiveness and Memorization. InProceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering. 493–505
work page 2024
-
[11]
Zimin Chen, Steve Kommrusch, Michele Tufano, Louis-Noël Pouchet, Denys Poshyvanyk, and Martin Monperrus. 2019. Sequencer: Sequence-to-sequence learning for end-to-end program repair.IEEE Transactions on Software Engineering 47, 9 (2019), 1943–1959
work page 2019
-
[12]
Yiu Wai Chow, Luca Di Grazia, and Michael Pradel. 2024. Pyty: Repairing static type errors in python. InProceedings of the IEEE/ACM 46th International Confer- ence on Software Engineering. 1–13
work page 2024
-
[13]
Israel Cohen, Yiteng Huang, Jingdong Chen, Jacob Benesty, Jacob Benesty, Jing- dong Chen, Yiteng Huang, and Israel Cohen. 2009. Pearson correlation coefficient. Noise reduction in speech processing(2009), 1–4
work page 2009
-
[14]
Luís Cruz, Xavier Franch Gutierrez, and Silverio Martínez-Fernández. 2024. In- novating for Tomorrow: The Convergence of Software Engineering and Green AI.ACM Transactions on Software Engineering and Methodology(2024)
work page 2024
-
[15]
Zhangyin Feng, Daya Guo, Duyu Tang, Nan Duan, Xiaocheng Feng, Ming Gong, Linjun Shou, Bing Qin, Ting Liu, Daxin Jiang, and Ming Zhou. 2020. CodeBERT: A Pre-Trained Model for Programming and Natural Languages. InFindings of the Association for Computational Linguistics: EMNLP 2020, Trevor Cohn, Yulan He, and Yang Liu (Eds.). Association for Computational L...
work page 2020
-
[16]
doi:10.18653/v1/2020.findings-emnlp.139
-
[17]
Jinlan Fu, See-Kiong Ng, Zhengbao Jiang, and Pengfei Liu. 2023. Gptscore: Evaluate as you desire.arXiv preprint arXiv:2302.04166(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [18]
-
[19]
Deipali Vikram Gore, Mahima Binoj, Sayali Borate, Ritu Devnani, and Sakshi Gopale. 2023. Syntax Error Detection and Correction in Python Code using ML. Grenze International Journal of Engineering & Technology (GIJET)9, 2 (2023)
work page 2023
-
[20]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. 2024. The llama 3 herd of models.arXiv preprint arXiv:2407.21783 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al . 2025. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
Sivana Hamer, Marcelo d’Amorim, and Laurie Williams. 2024. Just another copy and paste? Comparing the security vulnerabilities of ChatGPT generated code and StackOverflow answers. In2024 IEEE Security and Privacy Workshops (SPW). IEEE, 87–94
work page 2024
-
[23]
Junda He, Christoph Treude, and David Lo. 2024. LLM-Based Multi-Agent Systems for Software Engineering: Literature Review, Vision and the Road Ahead.ACM Transactions on Software Engineering and Methodology(2024)
work page 2024
-
[24]
SU Hongjin, Ruoxi Sun, Jinsung Yoon, Pengcheng Yin, Tao Yu, and Sercan O Arik. [n. d.]. Learn-by-interact: A Data-Centric Framework For Self-Adaptive Agents in Realistic Environments. InThe Thirteenth International Conference on Learning Representations
-
[25]
Eric Horton and Chris Parnin. 2019. Dockerizeme: Automatic inference of environ- ment dependencies for python code snippets. In2019 IEEE/ACM 41st International Conference on Software Engineering (ICSE). IEEE, 328–338
work page 2019
-
[26]
Nan Jiang, Thibaud Lutellier, and Lin Tan. 2021. Cure: Code-aware neural machine translation for automatic program repair. In2021 IEEE/ACM 43rd International Conference on Software Engineering (ICSE). IEEE, 1161–1173
work page 2021
-
[27]
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik R Narasimhan. 2024. SWE-bench: Can Language Models Resolve Real-world Github Issues?. InThe Twelfth International Conference on Learning Representations. https://openreview.net/forum?id=VTF8yNQM66
work page 2024
- [28]
-
[29]
Wuxia Jin, Shuo Xu, Dawei Chen, Jiajun He, Dinghong Zhong, Ming Fan, Hongxu Chen, Huijia Zhang, and Ting Liu. 2024. PyAnalyzer: An Effective and Practical Approach for Dependency Extraction from Python Code. InProceedings of the IEEE/ACM 46th International Conference on Software Engineering. 1–12
work page 2024
-
[30]
Anant Kharkar, Roshanak Zilouchian Moghaddam, Matthew Jin, Xiaoyu Liu, Xin Shi, Colin Clement, and Neel Sundaresan. 2022. Learning to reduce false positives in analytic bug detectors. InProceedings of the 44th International Conference on Software Engineering. 1307–1316
work page 2022
-
[31]
Jiaolong Kong, Xiaofei Xie, and Shangqing Liu. 2025. Demystifying Memorization in LLM-Based Program Repair via a General Hypothesis Testing Framework. Proceedings of the ACM on Software Engineering2, FSE (2025), 2712–2734
work page 2025
-
[32]
Jia Li, Ge Li, Xuanming Zhang, Yunfei Zhao, Yihong Dong, Zhi Jin, Binhua Li, Fei Huang, and Yongbin Li. 2024. EvoCodeBench: An Evolving Code Generation Benchmark with Domain-Specific Evaluations. InThe Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track. https: //openreview.net/forum?id=kvjbFVHpny
work page 2024
-
[33]
Yi Li. 2020. Improving bug detection and fixing via code representation learn- ing. InProceedings of the ACM/IEEE 42nd International Conference on Software Engineering: Companion Proceedings. 137–139
work page 2020
-
[34]
Yi Li, Shaohua Wang, and Tien N Nguyen. 2020. Dlfix: Context-based code transformation learning for automated program repair. InProceedings of the ACM/IEEE 42nd international conference on software engineering. 602–614. A Process-Oriented Error Analysis of Software Development Agents in Real-World GitHub Scenarios ICSE ’26, April 12–18, 2026, Rio de Janei...
work page 2020
-
[35]
Jiawei Liu, Chunqiu Steven Xia, Yuyao Wang, and Lingming Zhang. 2023. Is your code generated by chatgpt really correct? rigorous evaluation of large language models for code generation.Advances in Neural Information Processing Systems 36 (2023), 21558–21572
work page 2023
-
[36]
Tianyang Liu, Canwen Xu, and Julian McAuley. 2024. RepoBench: Benchmark- ing Repository-Level Code Auto-Completion Systems. InThe Twelfth Interna- tional Conference on Learning Representations. https://openreview.net/forum?id= pPjZIOuQuF
work page 2024
- [37]
-
[38]
Yue Liu, Thanh Le-Cong, Ratnadira Widyasari, Chakkrit Tantithamthavorn, Li Li, Xuan-Bach D Le, and David Lo. 2024. Refining chatgpt-generated code: Characterizing and mitigating code quality issues.ACM Transactions on Software Engineering and Methodology33, 5 (2024), 1–26
work page 2024
-
[39]
Zhijie Liu, Yutian Tang, Xiapu Luo, Yuming Zhou, and Liang Feng Zhang. 2024. No need to lift a finger anymore? assessing the quality of code generation by chatgpt.IEEE Transactions on Software Engineering(2024)
work page 2024
-
[40]
Junyi Lu, Lei Yu, Xiaojia Li, Li Yang, and Chun Zuo. 2023. Llama-reviewer: Ad- vancing code review automation with large language models through parameter- efficient fine-tuning. In2023 IEEE 34th International Symposium on Software Reliability Engineering (ISSRE). IEEE, 647–658
work page 2023
- [41]
- [42]
-
[43]
Vahid Majdinasab, Michael Joshua Bishop, Shawn Rasheed, Arghavan Moradi- dakhel, Amjed Tahir, and Foutse Khomh. 2024. Assessing the Security of GitHub Copilot’s Generated Code-A Targeted Replication Study. In2024 IEEE Interna- tional Conference on Software Analysis, Evolution and Reengineering (SANER). IEEE, 435–444
work page 2024
-
[44]
Tina Marjanov, Ivan Pashchenko, and Fabio Massacci. 2022. Machine learning for source code vulnerability detection: What works and what isn’t there yet. IEEE Security & Privacy20, 5 (2022), 60–76
work page 2022
-
[45]
Suchita Mukherjee, Abigail Almanza, and Cindy Rubio-González. 2021. Fixing dependency errors for Python build reproducibility. InProceedings of the 30th ACM SIGSOFT international symposium on software testing and analysis. 439–451
work page 2021
-
[46]
Nhan Nguyen and Sarah Nadi. 2022. An empirical evaluation of GitHub copilot’s code suggestions. InProceedings of the 19th International Conference on Mining Software Repositories. 1–5
work page 2022
-
[47]
Wonseok Oh and Hakjoo Oh. 2024. Towards Effective Static Type-Error Detection for Python. InProceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering. 1808–1820
work page 2024
-
[48]
Hammond Pearce, Baleegh Ahmad, Benjamin Tan, Brendan Dolan-Gavitt, and Ramesh Karri. 2022. Asleep at the keyboard? assessing the security of github copilot’s code contributions. In2022 IEEE Symposium on Security and Privacy (SP). IEEE, 754–768
work page 2022
-
[49]
Yun Peng, Shuzheng Gao, Cuiyun Gao, Yintong Huo, and Michael Lyu. 2024. Domain knowledge matters: Improving prompts with fix templates for repairing python type errors. InProceedings of the 46th ieee/acm international conference on software engineering. 1–13
work page 2024
-
[50]
Md Fazle Rabbi, Arifa Islam Champa, Minhaz F Zibran, and Md Rakibul Islam
-
[51]
InProceedings of the 21st International Conference on Mining Software Repositories
AI writes, we analyze: The ChatGPT python code saga. InProceedings of the 21st International Conference on Mining Software Repositories. 177–181
-
[52]
Brian Randell and Jie Xu. 2025. Looking Back on Recovery Blocks and Conversa- tions.IEEE Transactions on Software Engineering(2025)
work page 2025
- [53]
-
[54]
Eddie Antonio Santos, Joshua Charles Campbell, Dhvani Patel, Abram Hindle, and José Nelson Amaral. 2018. Syntax and sensibility: Using language models to detect and correct syntax errors. In2018 IEEE 25th International Conference on Software Analysis, Evolution and Reengineering (SANER). IEEE, 311–322
work page 2018
-
[55]
Jieke Shi, Zhou Yang, and David Lo. 2024. Efficient and green large language models for software engineering: Vision and the road ahead.ACM Transactions on Software Engineering and Methodology(2024)
work page 2024
-
[56]
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. 2023. Reflexion: Language agents with verbal reinforcement learning. Advances in Neural Information Processing Systems36 (2023), 8634–8652
work page 2023
-
[57]
Mohammed Latif Siddiq, Lindsay Roney, Jiahao Zhang, and Joanna Cecilia Da Silva Santos. 2024. Quality Assessment of ChatGPT Generated Code and their Use by Developers. InProceedings of the 21st International Conference on Mining Software Repositories. 152–156
work page 2024
-
[58]
Mohammed Latif Siddiq and Joanna CS Santos. 2022. SecurityEval dataset: mining vulnerability examples to evaluate machine learning-based code generation techniques. InProceedings of the 1st International Workshop on Mining Software Repositories Applications for Privacy and Security. 29–33
work page 2022
-
[59]
Hongjin Su, Ruoxi Sun, Jinsung Yoon, Pengcheng Yin, Tao Yu, and Sercan Ö Arık
- [60]
-
[61]
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie Millican, et al. 2023. Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[62]
Valerio Terragni, Annie Vella, Partha Roop, and Kelly Blincoe. 2025. The Future of AI-Driven Software Engineering.ACM Transactions on Software Engineering and Methodology(2025)
work page 2025
-
[63]
Catherine Tony, Markus Mutas, Nicolás E Díaz Ferreyra, and Riccardo Scandariato
-
[64]
In2023 IEEE/ACM 20th International Conference on Mining Software Repositories (MSR)
Llmseceval: A dataset of natural language prompts for security evaluations. In2023 IEEE/ACM 20th International Conference on Mining Software Repositories (MSR). IEEE, 588–592
-
[65]
Carmine Vassallo, Sebastiano Panichella, Fabio Palomba, Sebastian Proksch, Har- ald C Gall, and Andy Zaidman. 2020. How developers engage with static analysis tools in different contexts.Empirical Software Engineering25 (2020), 1419–1457
work page 2020
-
[66]
Chao Wang, Rongxin Wu, Haohao Song, Jiwu Shu, and Guoqing Li. 2022. smart- pip: A smart approach to resolving python dependency conflict issues. InPro- ceedings of the 37th IEEE/ACM International Conference on Automated Software Engineering. 1–12
work page 2022
-
[67]
Xingyao Wang, Boxuan Li, Yufan Song, Frank F Xu, Xiangru Tang, Mingchen Zhuge, Jiayi Pan, Yueqi Song, Bowen Li, Jaskirat Singh, et al. 2024. Openhands: An open platform for ai software developers as generalist agents. InThe Thirteenth International Conference on Learning Representations
work page 2024
-
[68]
Yue Wang, Weishi Wang, Shafiq Joty, and Steven CH Hoi. 2021. Codet5: Identifier- aware unified pre-trained encoder-decoder models for code understanding and generation.arXiv preprint arXiv:2109.00859(2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[69]
Ying Wang, Ming Wen, Yepang Liu, Yibo Wang, Zhenming Li, Chao Wang, Hai Yu, Shing-Chi Cheung, Chang Xu, and Zhiliang Zhu. 2020. Watchman: Monitoring dependency conflicts for python library ecosystem. InProceedings of the ACM/IEEE 42nd international conference on software engineering. 125–135
work page 2020
-
[70]
Chunqiu Steven Xia, Yinlin Deng, Soren Dunn, and Lingming Zhang. 2024. Agentless: Demystifying llm-based software engineering agents.arXiv preprint arXiv:2407.01489(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[71]
Chunqiu Steven Xia and Lingming Zhang. 2024. Automated program repair via conversation: Fixing 162 out of 337 bugs for $0.42 each using ChatGPT. In Proceedings of the 33rd ACM SIGSOFT International Symposium on Software Testing and Analysis. 819–831
work page 2024
-
[72]
Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press
John Yang, Carlos E. Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press. 2024. SWE-agent: Agent-computer in- terfaces enable automated software engineering.Advances in Neural Information Processing Systems37 (2024), 50528–50652
work page 2024
-
[73]
Zhou Yang, Zhipeng Zhao, Chenyu Wang, Jieke Shi, Dongsun Kim, Donggyun Han, and David Lo. 2024. Unveiling memorization in code models. InProceedings of the IEEE/ACM 46th International Conference on Software Engineering. 1–13
work page 2024
-
[74]
Hongjie Ye, Wei Chen, Wensheng Dou, Guoquan Wu, and Jun Wei. 2022. Knowledge-based environment dependency inference for Python programs. In Proceedings of the 44th International Conference on Software Engineering. 1245– 1256
work page 2022
-
[75]
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, et al. 2023. Judging llm-as-a-judge with mt-bench and chatbot arena.Advances in Neural Information Processing Systems36 (2023), 46595–46623
work page 2023
-
[76]
Li Zhong and Zilong Wang. 2024. Can llm replace stack overflow? a study on robustness and reliability of large language model code generation. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 38. 21841–21849
work page 2024
-
[77]
Mingchen Zhuge, Changsheng Zhao, Dylan R. Ashley, Wenyi Wang, Dmitrii Khizbullin, Yunyang Xiong, Zechun Liu, Ernie Chang, Raghuraman Krishnamoor- thi, Yuandong Tian, Yangyang Shi, Vikas Chandra, and Jürgen Schmidhuber
-
[78]
Agent-as-a-Judge: Evaluating Agents with Agents. https://openreview. net/forum?id=DeVm3YUnpj
-
[79]
Terry Yue Zhuo, Vu Minh Chien, Jenny Chim, Han Hu, Wenhao Yu, Ratnadira Widyasari, Imam Nur Bani Yusuf, Haolan Zhan, Junda He, Indraneil Paul, Simon Brunner, Chen GONG, James Hoang, Armel Randy Zebaze, Xiaoheng Hong, Wen- Ding Li, Jean Kaddour, Ming Xu, Zhihan Zhang, Prateek Yadav, Naman Jain, Alex Gu, Zhoujun Cheng, Jiawei Liu, Qian Liu, Zijian Wang, Dav...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.