AccidentSim: Generating Vehicle Collision Videos with Physically Realistic Collision Trajectories from Real-World Accident Reports
Pith reviewed 2026-05-22 22:22 UTC · model grok-4.3
The pith
AccidentSim generates vehicle collision videos with physically realistic trajectories from real-world accident reports.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
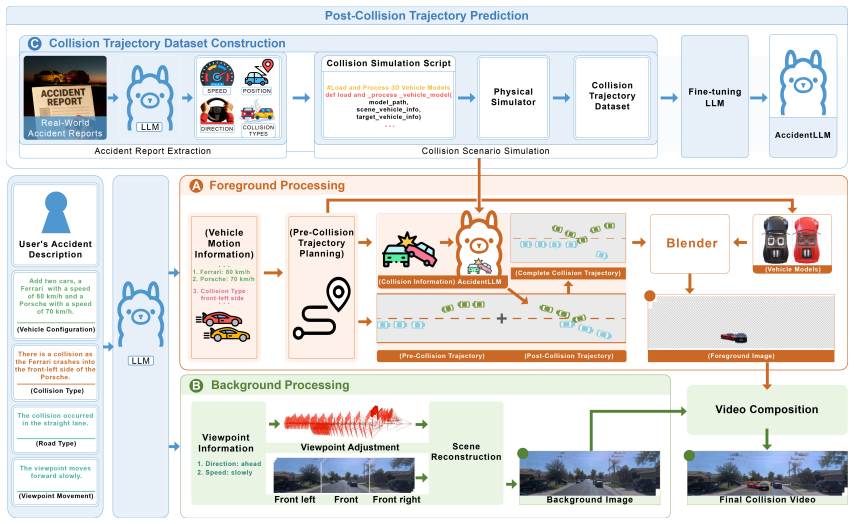
AccidentSim extracts physical and contextual details from real-world accident reports, feeds them into a reliable physical simulator to replicate post-collision trajectories, assembles the results into a training dataset, fine-tunes a language model to predict trajectories from user prompts, and combines the trajectories with Neural Radiance Fields backgrounds to output collision videos that exhibit both visual and physical authenticity.
What carries the argument
The AccidentSim pipeline: physical simulator that turns report data into trajectory dataset, language-model fine-tuning for prompt-based prediction, and NeRF rendering to composite foreground vehicles with backgrounds.
If this is right
- A new dataset of physically consistent collision trajectories becomes available from existing accident reports.
- Language models can be prompted to generate realistic post-collision behavior across varied driving scenarios.
- Generated videos supply training and testing material for autonomous driving systems on rare collision events.
- The method separates trajectory physics from visual rendering, allowing independent improvement of each part.
Where Pith is reading between the lines
- The same report-to-trajectory step could be applied to other accident types or vehicle classes if suitable reports exist.
- Fine-tuned models might support interactive scenario editing inside driving simulators.
- The approach could reduce reliance on expensive real-world crash data collection for edge-case testing.
Load-bearing premise
The physical clues and contextual information in real-world accident reports are sufficient for a reliable physical simulator to accurately replicate post-collision trajectories without needing additional real sensor data or validation measurements.
What would settle it
Direct comparison of the simulator-generated vehicle positions, velocities, and orientations over time against high-precision measurements from instrumented crash tests or detailed forensic reconstructions of the same reported accidents; large systematic deviations would falsify the replication claim.
Figures







read the original abstract
Collecting real-world vehicle accident videos for autonomous driving research is challenging due to their rarity and complexity. While existing driving video generation methods may produce visually realistic videos, they often fail to deliver physically realistic simulations because they lack the capability to generate accurate post-collision trajectories. In this paper, we introduce AccidentSim, a novel framework that generates physically realistic vehicle collision videos by extracting and utilizing the physical clues and contextual information available in real-world vehicle accident reports. Specifically, AccidentSim leverages a reliable physical simulator to replicate post-collision vehicle trajectories from the physical and contextual information in the accident reports and to build a vehicle collision trajectory dataset. This dataset is then used to fine-tune a language model, enabling it to respond to user prompts and predict physically consistent post-collision trajectories across various driving scenarios based on user descriptions. Finally, we employ Neural Radiance Fields (NeRF) to render high-quality backgrounds, merging them with the foreground vehicles that exhibit physically realistic trajectories to generate vehicle collision videos. Experimental results demonstrate that the videos produced by AccidentSim excel in both visual and physical authenticity.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces AccidentSim, a pipeline that extracts physical and contextual clues from real-world accident reports, feeds them into a physical simulator to generate post-collision trajectories and a corresponding dataset, fine-tunes a language model to predict trajectories from text prompts, and composites the resulting vehicle motions with NeRF-rendered backgrounds to produce collision videos. The central claim is that the resulting videos exhibit superior visual and physical authenticity compared to prior driving-video generation methods.
Significance. If the physical-authenticity claim is substantiated with quantitative validation, the work would address a clear gap in synthetic data generation for autonomous-driving research by supplying collision scenarios whose post-impact dynamics are derived from real reports rather than purely learned or heuristic motion models.
major comments (2)
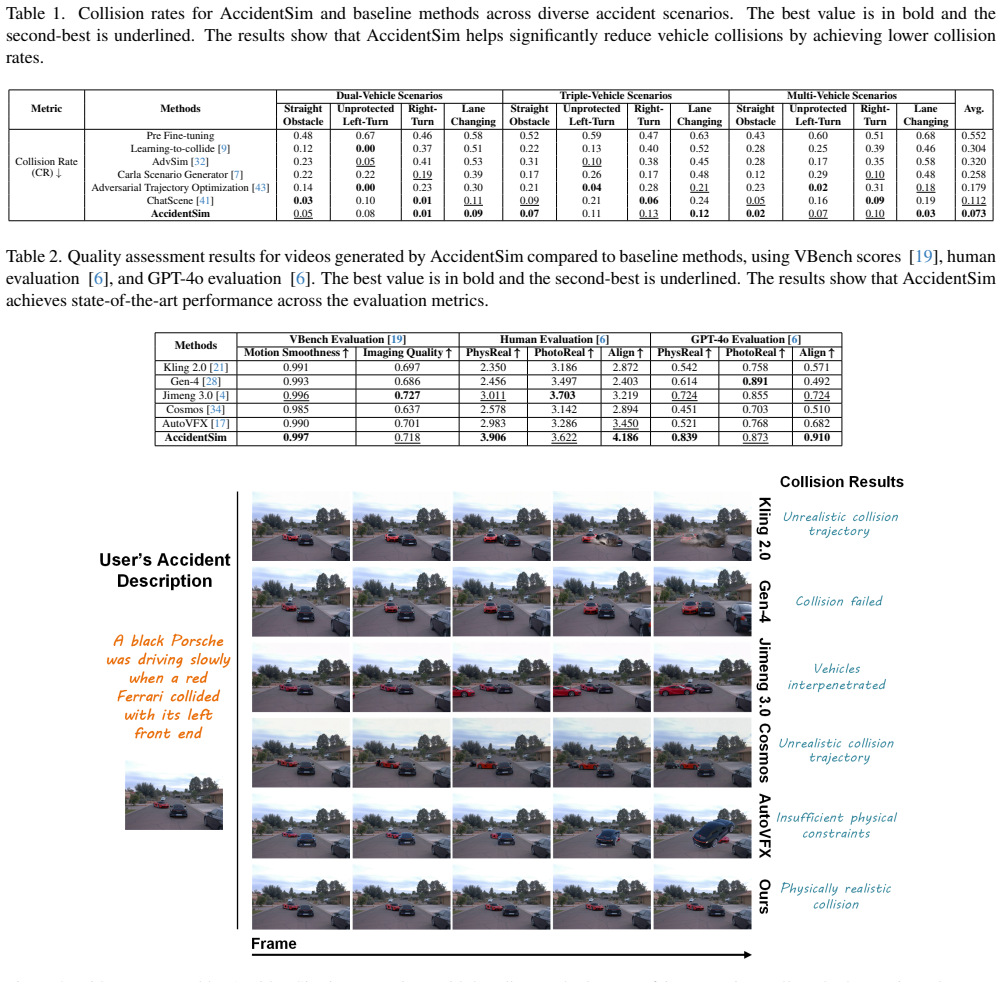
- [Abstract / Experimental Results] Abstract and Experimental Results section: the assertion that 'experimental results demonstrate that the videos produced by AccidentSim excel in both visual and physical authenticity' is unsupported; the manuscript supplies no quantitative metrics (e.g., trajectory error, velocity RMSE, collision impulse consistency), no baseline comparisons, and no description of how physical realism was measured or validated against any ground-truth post-collision sensor data.
- [Methods] Methods / Pipeline description: the claim that trajectories generated by the external simulator from report-derived clues are 'physically realistic' is load-bearing for the entire contribution, yet the text provides no ground-truth post-collision measurements (final positions, velocities, or contact forces) against which simulator outputs could be compared; any systematic mismatch between the simulator's multi-body contact model and real deformation/friction therefore remains invisible to both the LM fine-tuning stage and the downstream evaluation.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the need for stronger validation of physical realism. We address each major comment below and outline planned revisions.
read point-by-point responses
-
Referee: [Abstract / Experimental Results] Abstract and Experimental Results section: the assertion that 'experimental results demonstrate that the videos produced by AccidentSim excel in both visual and physical authenticity' is unsupported; the manuscript supplies no quantitative metrics (e.g., trajectory error, velocity RMSE, collision impulse consistency), no baseline comparisons, and no description of how physical realism was measured or validated against any ground-truth post-collision sensor data.
Authors: We agree the current manuscript lacks quantitative metrics, baseline comparisons, and explicit measurement protocols for physical realism; the Experimental Results section relies on qualitative video examples. We will revise the abstract to remove the unsupported claim and add a new subsection describing evaluation methodology, including trajectory consistency metrics against the simulator outputs and visual quality scores, plus comparisons to prior video generation methods. revision: yes
-
Referee: [Methods] Methods / Pipeline description: the claim that trajectories generated by the external simulator from report-derived clues are 'physically realistic' is load-bearing for the entire contribution, yet the text provides no ground-truth post-collision measurements (final positions, velocities, or contact forces) against which simulator outputs could be compared; any systematic mismatch between the simulator's multi-body contact model and real deformation/friction therefore remains invisible to both the LM fine-tuning stage and the downstream evaluation.
Authors: The simulator generates trajectories from parameters extracted from accident reports using established multi-body physics. We will revise the Methods section to explicitly note the absence of direct ground-truth post-collision measurements in the source reports and to discuss the simulator's modeling assumptions as a limitation. We will also add any feasible indirect checks, such as consistency with reported final vehicle positions where available in the reports. revision: partial
- Absence of ground-truth post-collision sensor data (positions, velocities, forces) in real-world accident reports, which prevents direct quantitative validation of simulator outputs against reality.
Circularity Check
No circularity in derivation chain
full rationale
The paper describes an engineering pipeline that extracts clues from accident reports, feeds them to an external physical simulator to generate trajectories, fine-tunes a language model on the resulting dataset, and renders with NeRF. No equations, parameter-fitting steps, or self-referential derivations appear in the abstract or described structure. The physical-authenticity claim rests on the simulator's external validity rather than any internal reduction of outputs to inputs by construction. No self-citation load-bearing steps or ansatz smuggling are present.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
AccidentSim leverages a reliable physical simulator to replicate post-collision vehicle trajectories from the physical and contextual information in the accident reports and to build a vehicle collision trajectory dataset. This dataset is then used to fine-tune a language model...
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Ltraj = 1/N Σ (‖p̂i − p∗i‖ + ‖θ̂i − θ∗i‖)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
Learning physically grounded traffic accident reconstruction from public accident reports
A multimodal learning model with a new dataset of 6,217 cases reconstructs lane-consistent pre-impact motion and collision interactions from public accident reports, outperforming baselines in accuracy and consistency.
Reference graph
Works this paper leans on
-
[1]
National Highway Traffic Safety Administration. Nmvccs (2005-2007) search. 2016. Retrieved November 15, 2023 fromhttps : / / crashviewer . nhtsa . dot . gov / LegacyNMVCCS/Search. 1, 4
work page 2005
-
[2]
Cosmos World Foundation Model Platform for Physical AI
Niket Agarwal, Arslan Ali, Maciej Bala, Yogesh Balaji, Erik Barker, Tiffany Cai, Prithvijit Chattopadhyay, Yongxin Chen, Yin Cui, Yifan Ding, et al. Cosmos world foun- dation model platform for physical ai.arXiv preprint arXiv:2501.03575, 2025. 1, 6
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Uncertainty-based traffic accident anticipation with spatio-temporal relational learn- ing
Wentao Bao, Qi Yu, and Yu Kong. Uncertainty-based traffic accident anticipation with spatio-temporal relational learn- ing. InACM Multimedia Conference, 2020. 3
work page 2020
- [4]
-
[5]
nuscenes: A multi- modal dataset for autonomous driving
Holger Caesar, Varun Bankiti, Alex H Lang, Sourabh V ora, Venice Erin Liong, Qiang Xu, Anush Krishnan, Yu Pan, Gi- ancarlo Baldan, and Oscar Beijbom. nuscenes: A multi- modal dataset for autonomous driving. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11621–11631, 2020. 1
work page 2020
-
[6]
Physgen3d: Crafting a miniature interactive world from a single image
Boyuan Chen, Hanxiao Jiang, Shaowei Liu, Saurabh Gupta, Yunzhu Li, Hao Zhao, and Shenlong Wang. Physgen3d: Crafting a miniature interactive world from a single image. InProceedings of the Computer Vision and Pattern Recogni- tion Conference, pages 6178–6189, 2025. 6, 7, 14
work page 2025
-
[7]
Scenario Runner Contributors. Carla scenario runner, 2019. 6, 7
work page 2019
-
[8]
The cityscapes dataset for semantic urban scene understanding
Marius Cordts, Mohamed Omran, Sebastian Ramos, Timo Rehfeld, Markus Enzweiler, Rodrigo Benenson, Uwe Franke, Stefan Roth, and Bernt Schiele. The cityscapes dataset for semantic urban scene understanding. InProceed- ings of the IEEE conference on computer vision and pattern recognition, pages 3213–3223, 2016. 1
work page 2016
-
[9]
Wenhao Ding, Minjun Xu, and Ding Zhao. Learning to collide: An adaptive safety-critical scenarios generating method.2020 IEEE/RSJ International Conference on Intel- ligent Robots and Systems (IROS), pages 2243–2250, 2020. 6, 7
work page 2020
-
[10]
CARLA: An open urban driving simulator
Alexey Dosovitskiy, German Ros, Felipe Codevilla, Antonio Lopez, and Vladlen Koltun. CARLA: An open urban driving simulator. InProceedings of the 1st Annual Conference on Robot Learning, pages 1–16, 2017. 2, 11, 13
work page 2017
-
[11]
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Ab- hishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Scenic: a language for scenario specification and scene generation
Daniel J Fremont, Tommaso Dreossi, Shromona Ghosh, Xi- angyu Yue, Alberto L Sangiovanni-Vincentelli, and Sanjit A Seshia. Scenic: a language for scenario specification and scene generation. InProceedings of the 40th ACM SIGPLAN conference on programming language design and implemen- tation, pages 63–78, 2019. 15
work page 2019
-
[13]
Ruiyuan Gao, Kai Chen, Enze Xie, Lanqing Hong, Zhenguo Li, Dit-Yan Yeung, and Qiang Xu. Magicdrive: Street view generation with diverse 3d geometry control.arXiv preprint arXiv:2310.02601, 2023. 3
-
[14]
Andreas Geiger, Philip Lenz, Christoph Stiller, and Raquel Urtasun. Vision meets robotics: The kitti dataset.The Inter- national Journal of Robotics Research, 32(11):1231–1237,
-
[15]
Sovar: Building generalizable sce- narios from accident reports for autonomous driving testing
An Guo, Yuan Zhou, Haoxiang Tian, Chunrong Fang, Yun- jian Sun, Weisong Sun, Xinyu Gao, Anh Tuan Luu, Yang Liu, and Zhenyu Chen. Sovar: Building generalizable sce- narios from accident reports for autonomous driving testing. arXiv preprint arXiv:2409.08081, 2024. 5, 11, 12, 13
-
[16]
Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor
Tuomas Haarnoja, Aurick Zhou, Pieter Abbeel, and Sergey Levine. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. InInterna- tional conference on machine learning, pages 1861–1870. PMLR, 2018. 15
work page 2018
-
[17]
Hao-Yu Hsu, Zhi-Hao Lin, Albert Zhai, Hongchi Xia, and Shenlong Wang. Autovfx: Physically realistic video edit- ing from natural language instructions.arXiv preprint arXiv:2411.02394, 2024. 6, 7, 8
-
[18]
LoRA: Low-Rank Adaptation of Large Language Models
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen- Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models.arXiv preprint arXiv:2106.09685, 2021. 5
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[19]
Vbench: Comprehensive bench- mark suite for video generative models
Ziqi Huang, Yinan He, Jiashuo Yu, Fan Zhang, Chenyang Si, Yuming Jiang, Yuanhan Zhang, Tianxing Wu, Qingyang Jin, Nattapol Chanpaisit, et al. Vbench: Comprehensive bench- mark suite for video generative models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21807–21818, 2024. 6, 7
work page 2024
-
[20]
Ac3r: auto- matically reconstructing car crashes from police reports
Tri Huynh, Alessio Gambi, and Gordon Fraser. Ac3r: auto- matically reconstructing car crashes from police reports. In 2019 IEEE/ACM 41st International Conference on Software Engineering: Companion Proceedings (ICSE-Companion), pages 31–34. IEEE, 2019. 11, 12
work page 2019
-
[21]
Kling 2.0, 2025.https : / / kling
Kuaishou. Kling 2.0, 2025.https : / / kling . kuaishou.com/en. 1, 6, 7
work page 2025
-
[22]
Xiaofan Li, Yifu Zhang, and Xiaoqing Ye. Drivingdif- fusion: Layout-guided multi-view driving scene video generation with latent diffusion model.arXiv preprint arXiv:2310.07771, 2023. 3
-
[23]
Curse of rarity for autonomous vehicles.nature communications, 15(1):4808, 2024
Henry X Liu and Shuo Feng. Curse of rarity for autonomous vehicles.nature communications, 15(1):4808, 2024. 1
work page 2024
-
[24]
Neuroncap: Photorealistic closed- loop safety testing for autonomous driving
William Ljungbergh, Adam Tonderski, Joakim Johnan- der, Holger Caesar, Kalle ˚Astr¨om, Michael Felsberg, and Christoffer Petersson. Neuroncap: Photorealistic closed- loop safety testing for autonomous driving. InEuropean Conference on Computer Vision, pages 161–177. Springer,
-
[25]
MathWorks. Roadrunner. 2020.https : / / www . mathworks.com/products/roadrunner.html. 5
work page 2020
-
[26]
OpenAI. Gpt-4o. 2024.https://openai.com/ index/hello-gpt-4o/. 6
work page 2024
-
[27]
Generating useful accident-prone driv- ing scenarios via a learned traffic prior
Davis Rempe, Jonah Philion, Leonidas J Guibas, Sanja Fi- dler, and Or Litany. Generating useful accident-prone driv- ing scenarios via a learned traffic prior. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 17305–17315, 2022. 3 9
work page 2022
-
[28]
Runway. Gen-4. 2025.https://runwayml.com/ research/introducing-runway-gen-4. 1, 6, 7
work page 2025
-
[29]
Cadp: A novel dataset for cctv traffic camera based accident analysis
Ankit Parag Shah, Jean-Bapstite Lamare, Tuan Nguyen-Anh, and Alexander Hauptmann. Cadp: A novel dataset for cctv traffic camera based accident analysis. In2018 15th IEEE In- ternational Conference on Advanced Video and Signal Based Surveillance (AVSS), pages 1–9, 2018. 3
work page 2018
-
[30]
Scalability in perception for autonomous driving: Waymo open dataset
Pei Sun, Henrik Kretzschmar, Xerxes Dotiwalla, Aurelien Chouard, Vijaysai Patnaik, Paul Tsui, James Guo, Yin Zhou, Yuning Chai, Benjamin Caine, et al. Scalability in perception for autonomous driving: Waymo open dataset. InProceed- ings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2446–2454, 2020. 1, 6
work page 2020
-
[31]
Language conditioned traffic generation.arXiv preprint arXiv:2307.07947, 2023
Shuhan Tan, Boris Ivanovic, Xinshuo Weng, Marco Pavone, and Philipp Kraehenbuehl. Language conditioned traffic generation.arXiv preprint arXiv:2307.07947, 2023. 3
-
[32]
Jingkang Wang, Ava Pun, James Tu, Sivabalan Mani- vasagam, Abbas Sadat, Sergio Casas, Mengye Ren, and Raquel Urtasun. Advsim: Generating safety-critical scenar- ios for self-driving vehicles.2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 9904–9913, 2021. 6, 7
work page 2021
-
[33]
Yuqi Wang, Jiawei He, Lue Fan, Hongxin Li, Yuntao Chen, and Zhaoxiang Zhang. Driving into the future: Multiview visual forecasting and planning with world model for au- tonomous driving. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 14749–14759, 2024. 1, 3
work page 2024
-
[34]
Editable scene simulation for autonomous driving via collaborative llm-agents
Yuxi Wei, Zi Wang, Yifan Lu, Chenxin Xu, Changxing Liu, Hao Zhao, Siheng Chen, and Yanfeng Wang. Editable scene simulation for autonomous driving via collaborative llm-agents. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15077– 15087, 2024. 5, 7, 13
work page 2024
-
[35]
Panacea: Panoramic and controllable video generation for autonomous driving
Yuqing Wen, Yucheng Zhao, Yingfei Liu, Fan Jia, Yanhui Wang, Chong Luo, Chi Zhang, Tiancai Wang, Xiaoyan Sun, and Xiangyu Zhang. Panacea: Panoramic and controllable video generation for autonomous driving. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6902–6912, 2024. 1, 3
work page 2024
-
[36]
Zehuan Wu, Jingcheng Ni, Xiaodong Wang, Yuxin Guo, Rui Chen, Lewei Lu, Jifeng Dai, and Yuwen Xiong. Holodrive: Holistic 2d-3d multi-modal street scene generation for au- tonomous driving.arXiv preprint arXiv:2412.01407, 2024. 1
-
[37]
S-nerf: Neural radiance fields for street views.arXiv preprint arXiv:2303.00749, 2023
Ziyang Xie, Junge Zhang, Wenye Li, Feihu Zhang, and Li Zhang. S-nerf: Neural radiance fields for street views.arXiv preprint arXiv:2303.00749, 2023. 3
-
[38]
Chejian Xu, Wenhao Ding, Weijie Lyu, Zuxin Liu, Shuai Wang, Yihan He, Hanjiang Hu, Ding Zhao, and Bo Li. Safebench: A benchmarking platform for safety evaluation of autonomous vehicles.Advances in Neural Information Processing Systems, 35:25667–25682, 2022. 6, 15
work page 2022
-
[39]
Bdd100k: A diverse driving dataset for heterogeneous multitask learning
Fisher Yu, Haofeng Chen, Xin Wang, Wenqi Xian, Yingying Chen, Fangchen Liu, Vashisht Madhavan, and Trevor Dar- rell. Bdd100k: A diverse driving dataset for heterogeneous multitask learning. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 2636–2645, 2020. 1
work page 2020
-
[40]
Is- safe: Improving semantic segmentation in accidents by fus- ing event-based data
Jiaming Zhang, Kailun Yang, and Rainer Stiefelhagen. Is- safe: Improving semantic segmentation in accidents by fus- ing event-based data. In2021 IEEE/RSJ International Con- ference on Intelligent Robots and Systems (IROS), pages 1132–1139, 2021. 3
work page 2021
-
[41]
Chatscene: Knowledge-enabled safety-critical scenario generation for autonomous vehicles
Jiawei Zhang, Chejian Xu, and Bo Li. Chatscene: Knowledge-enabled safety-critical scenario generation for autonomous vehicles. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 15459–15469, 2024. 6, 7, 15
work page 2024
-
[42]
Cat: Closed-loop adversarial training for safe end-to-end driving
Linrui Zhang, Zhenghao Peng, Quanyi Li, and Bolei Zhou. Cat: Closed-loop adversarial training for safe end-to-end driving. InConference on Robot Learning, pages 2357–
-
[43]
On adversarial robustness of tra- jectory prediction for autonomous vehicles
Qingzhao Zhang, Shengtuo Hu, Jiachen Sun, Qi Alfred Chen, and Z Morley Mao. On adversarial robustness of tra- jectory prediction for autonomous vehicles. InProceedings of the IEEE/CVF Conference on Computer Vision and Pat- tern Recognition, pages 15159–15168, 2022. 6, 7
work page 2022
-
[44]
Language-guided traffic simulation via scene-level diffusion
Ziyuan Zhong, Davis Rempe, Yuxiao Chen, Boris Ivanovic, Yulong Cao, Danfei Xu, Marco Pavone, and Baishakhi Ray. Language-guided traffic simulation via scene-level diffusion. InConference on Robot Learning, pages 144–177. PMLR,
-
[45]
Jing Zhou, Huei Peng, and Jianbo Lu. Collision model for vehicle motion prediction after light impacts.Vehicle System Dynamics, 46(S1):3–15, 2008. 8 AccidentSim: Generating Vehicle Collision Videos with Physically Realistic Collision Trajectories from Real-World Accident Reports 10 AccidentSim: Generating Vehicle Collision Videos with Physically Realistic...
work page 2008
-
[46]
Table of Contents •Pre-Collision Trajectory Planning •Information Extraction from Accident Reports •Physical Simulation of Accident Scenario •Additional Qualitative Analysis of Collision Dynamics •Human and GPT-4o Evaluation •Collision Reduction with AccidentSim A. Algorithm for Pre-Collision Trajectory Planning The proposed algorithm for pre-collision tr...
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.