Q-Agent: Quality-Driven Chain-of-Thought Image Restoration Agent through Robust Multimodal Large Language Model
Pith reviewed 2026-05-22 21:14 UTC · model grok-4.3
The pith
Q-Agent uses chain-of-thought in a fine-tuned MLLM plus IQA-driven greedy ordering to restore images with multiple degradations more effectively than all-in-one models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
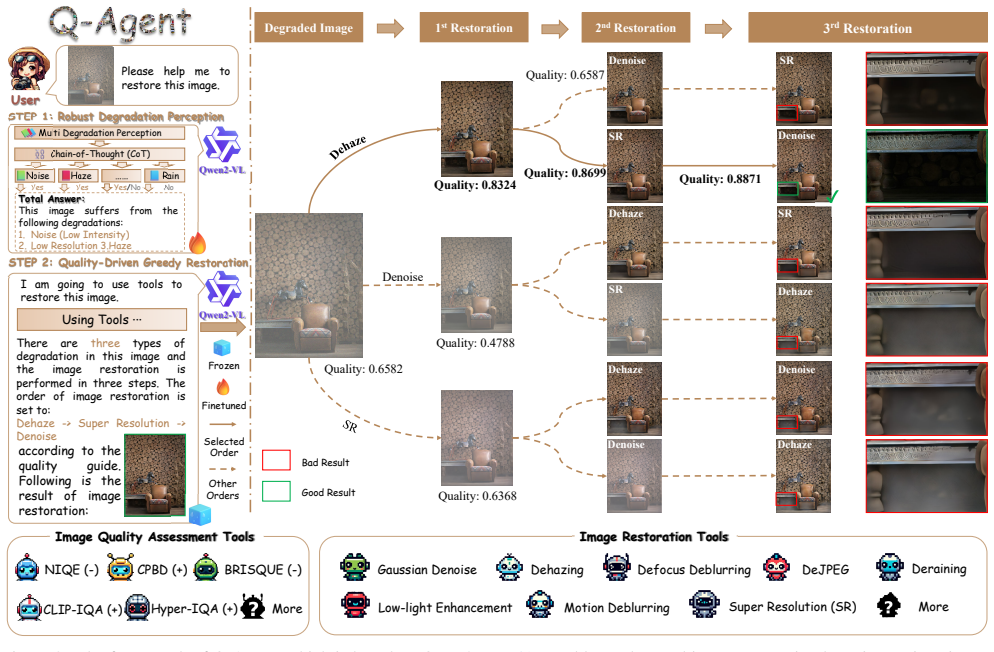
Q-Agent consists of robust degradation perception and quality-driven greedy restoration. The former fine-tunes the MLLM and uses CoT to decompose multi-degradation perception into single-degradation perception tasks. The latter employs objective IQA metrics to determine the optimal restoration sequence and execute the corresponding restoration algorithms, resulting in superior IR performance compared to existing All-in-One models.
What carries the argument
The quality-driven greedy restoration module that uses objective image quality assessment metrics to select and apply the optimal sequence of restoration algorithms.
If this is right
- More accurate perception of multiple simultaneous degradations without misinterpretation.
- Lower time and computational cost by skipping unnecessary restoration steps.
- Improved handling of degradation types not seen during training.
- Avoidance of the performance trade-offs that occur when a single model is trained on all degradation types at once.
Where Pith is reading between the lines
- The same CoT-plus-quality-feedback pattern could be applied to sequential tasks in other domains where the order of operations affects the final result.
- Replacing or augmenting the fixed IQA metrics with learned quality predictors might further improve the greedy selection.
- The decomposition strategy suggests that breaking complex perception problems into ordered single-factor subproblems can help other multimodal agents avoid confusion.
Load-bearing premise
Objective image quality assessment metrics can correctly identify the single best restoration order for any mix of degradations.
What would settle it
A collection of test images in which the restoration sequence chosen by the IQA-greedy module produces visibly or measurably worse final quality than an alternative order.
Figures






read the original abstract
Image restoration (IR) often faces various complex and unknown degradations in real-world scenarios, such as noise, blurring, compression artifacts, and low resolution, etc. Training specific models for specific degradation may lead to poor generalization. To handle multiple degradations simultaneously, All-in-One models might sacrifice performance on certain types of degradation and still struggle with unseen degradations during training. Existing IR agents rely on multimodal large language models (MLLM) and a time-consuming rolling-back selection strategy neglecting image quality. As a result, they may misinterpret degradations and have high time and computational costs to conduct unnecessary IR tasks with redundant order. To address these, we propose a Quality-Driven agent (Q-Agent) via Chain-of-Thought (CoT) restoration. Specifically, our Q-Agent consists of robust degradation perception and quality-driven greedy restoration. The former module first fine-tunes MLLM, and uses CoT to decompose multi-degradation perception into single-degradation perception tasks to enhance the perception of MLLMs. The latter employs objective image quality assessment (IQA) metrics to determine the optimal restoration sequence and execute the corresponding restoration algorithms. Experimental results demonstrate that our Q-Agent achieves superior IR performance compared to existing All-in-One models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Q-Agent, a quality-driven chain-of-thought image restoration agent based on a robust multimodal large language model. It features two main modules: robust degradation perception, which fine-tunes an MLLM and uses CoT to break down multi-degradation perception into single-degradation tasks, and quality-driven greedy restoration, which uses objective IQA metrics to determine the optimal sequence of restoration algorithms. The central claim is that this approach achieves superior image restoration performance compared to existing All-in-One models.
Significance. If the experimental results hold, this work could be significant for advancing all-in-one image restoration by leveraging the reasoning capabilities of MLLMs through CoT prompting and using IQA to optimize restoration order, potentially leading to better handling of complex, unknown degradations in real-world scenarios without sacrificing performance on specific types.
major comments (1)
- [Abstract] Abstract: The statement 'Experimental results demonstrate that our Q-Agent achieves superior IR performance compared to existing All-in-One models' is presented without any supporting quantitative metrics (e.g., PSNR, SSIM), dataset specifications, baseline methods, ablation studies, or error analysis. This absence is load-bearing for the central claim of superiority and prevents assessment of whether the proposed modules deliver the asserted improvements.
minor comments (1)
- [Abstract] Abstract: The phrase 'noise, blurring, compression artifacts, and low resolution, etc.' could be expanded for clarity on the range of degradations considered.
Simulated Author's Rebuttal
We thank the referee for their careful reading and constructive feedback on our manuscript. We address the major comment point-by-point below and will incorporate revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract: The statement 'Experimental results demonstrate that our Q-Agent achieves superior IR performance compared to existing All-in-One models' is presented without any supporting quantitative metrics (e.g., PSNR, SSIM), dataset specifications, baseline methods, ablation studies, or error analysis. This absence is load-bearing for the central claim of superiority and prevents assessment of whether the proposed modules deliver the asserted improvements.
Authors: We agree that the abstract would benefit from including concrete quantitative support for the superiority claim to make it self-contained. The full manuscript already contains detailed experimental results (Tables 1-4, Figures 3-6, and Sections 4.2-4.4) reporting PSNR/SSIM on DIV2K, RealSR, and synthetic multi-degradation benchmarks, with comparisons to All-in-One baselines such as AirNet, PromptIR, and Restormer, plus ablations on the CoT and IQA modules. To address the referee's concern directly, we will revise the abstract in the next version to concisely include key metrics (e.g., average PSNR gains of X dB over the strongest baseline on Y datasets) while preserving length constraints. This change strengthens the presentation without altering the underlying claims or results. revision: yes
Circularity Check
No significant circularity
full rationale
The paper presents an empirical method for image restoration using an MLLM with CoT decomposition and external objective IQA metrics to guide a greedy restoration sequence. No equations, derivations, fitted parameters, or self-referential definitions appear in the provided text. The central claim of superior performance is asserted via experimental results against All-in-One models, relying on standard external components rather than any internal reduction to inputs by construction. This matches the default expectation of no circularity for method-description papers without mathematical self-reference.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Fine-tuning an MLLM with CoT decomposition improves its perception of multiple simultaneous degradations
- domain assumption Objective IQA metrics can be used to determine an optimal restoration sequence
invented entities (1)
-
Q-Agent
no independent evidence
Forward citations
Cited by 5 Pith papers
-
EvoIR-Agent: Self-Evolving Image Restoration Agentic System via Experience-Driven Learning
EvoIR-Agent formulates experience components into a hierarchical pool with a self-evolving update mechanism to improve performance and efficiency of training-free MLLM image restoration agents over prior paradigms.
-
RIRF: Reasoning Image Restoration Framework
R&R couples structured diagnostic reasoning from a fine-tuned Qwen3-VL model with reinforcement learning guided by degradation severity to achieve state-of-the-art universal image restoration with added interpretability.
-
Task-Guided Prompting for Unified Remote Sensing Image Restoration
TGPNet unifies denoising, cloud removal, shadow removal, deblurring, and SAR despeckling into one model via task-guided prompting and reports state-of-the-art results on a new multi-modal benchmark.
-
Restore-R1: Efficient Image Restoration Agents via Reinforcement Learning with Multimodal LLM Perceptual Feedback
An RL-trained lightweight agent uses MLLM perceptual rewards to perform efficient label-free image restoration, matching SOTA on full-reference metrics and surpassing prior work on no-reference metrics.
-
OPERA: An Agent for Image Restoration with End-to-End Joint Planning-Execution Optimization
OPERA jointly optimizes restoration planning via RL over tool compositions and execution via agent-guided co-training of tools, claiming consistent gains over all-in-one models and prior agent methods on multi-degrada...
Reference graph
Works this paper leans on
-
[1]
Defocus de- blurring using dual-pixel data
Abdullah Abuolaim and Michael S Brown. Defocus de- blurring using dual-pixel data. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23– 28, 2020, Proceedings, Part X 16, pages 111–126. Springer,
work page 2020
-
[2]
Contour detection and hierarchical image seg- mentation
Pablo Arbelaez, Michael Maire, Charless Fowlkes, and Ji- tendra Malik. Contour detection and hierarchical image seg- mentation. IEEE transactions on pattern analysis and ma- chine intelligence, 33(5):898–916, 2010. 5
work page 2010
-
[3]
Retinexformer: One-stage retinex- based transformer for low-light image enhancement
Yuanhao Cai, Hao Bian, Jing Lin, Haoqian Wang, Radu Tim- ofte, and Yulun Zhang. Retinexformer: One-stage retinex- based transformer for low-light image enhancement. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 12504–12513, 2023. 1, 2, 5
work page 2023
-
[4]
Restoreagent: Autonomous image restoration agent via multimodal large language models
Haoyu Chen, Wenbo Li, Jinjin Gu, Jingjing Ren, Sixi- ang Chen, Tian Ye, Renjing Pei, Kaiwen Zhou, Fenglong Song, and Lei Zhu. Restoreagent: Autonomous image restoration agent via multimodal large language models. Advances in Neural Information Processing Systems , 37: 110643–110666, 2025. 1, 3, 4, 6, 7
work page 2025
-
[5]
Shikra: Unleashing Multimodal LLM's Referential Dialogue Magic
Keqin Chen, Zhao Zhang, Weili Zeng, Richong Zhang, Feng Zhu, and Rui Zhao. Shikra: Unleashing multi- modal llm’s referential dialogue magic. arXiv preprint arXiv:2306.15195, 2023. 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
Internvl: Scaling up vision foundation mod- els and aligning for generic visual-linguistic tasks
Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, et al. Internvl: Scaling up vision foundation mod- els and aligning for generic visual-linguistic tasks. In Pro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 24185–24198, 2024. 3
work page 2024
-
[7]
High- quality image restoration following human instructions
Marcos V Conde, Gregor Geigle, and Radu Timofte. High- quality image restoration following human instructions. arXiv e-prints, pages arXiv–2401, 2024. 2, 8
work page 2024
-
[8]
InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning
Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung, and Steven Hoi. Instructblip: Towards general- purpose vision-language models with instruction tuning. arXiv preprint arXiv:2305.06500, 2023. 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[9]
Image quality assessment: Unifying structure and texture similarity
Keyan Ding, Kede Ma, Shiqi Wang, and Eero P Simoncelli. Image quality assessment: Unifying structure and texture similarity. IEEE transactions on pattern analysis and ma- chine intelligence, 44(5):2567–2581, 2020. 6
work page 2020
-
[10]
Kodak lossless true color image suite
Rich Franzen. Kodak lossless true color image suite. http: //r0k.us/graphics/kodak, 1999. 2, 5
work page 1999
-
[11]
ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools
Team GLM, Aohan Zeng, Bin Xu, Bowen Wang, Chenhui Zhang, Da Yin, Diego Rojas, Guanyu Feng, Hanlin Zhao, Hanyu Lai, Hao Yu, Hongning Wang, Jiadai Sun, Jiajie Zhang, Jiale Cheng, Jiayi Gui, Jie Tang, Jing Zhang, Juanzi Li, Lei Zhao, Lindong Wu, Lucen Zhong, Mingdao Liu, Minlie Huang, Peng Zhang, Qinkai Zheng, Rui Lu, Shuaiqi Duan, Shudan Zhang, Shulin Cao, ...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
Lora: Low-rank adaptation of large language models
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen- Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models. ICLR, 1(2):3, 2022. 3
work page 2022
-
[13]
Qidong Huang, Xiaoyi Dong, Pan Zhang, Bin Wang, Con- ghui He, Jiaqi Wang, Dahua Lin, Weiming Zhang, and Nenghai Yu. Opera: Alleviating hallucination in multi- modal large language models via over-trust penalty and retrospection-allocation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages 13418–13427, 2024. 1
work page 2024
-
[14]
Autodir: Automatic all-in-one image restoration with latent diffusion
Yitong Jiang, Zhaoyang Zhang, Tianfan Xue, and Jinwei Gu. Autodir: Automatic all-in-one image restoration with latent diffusion. In European Conference on Computer Vi- sion, pages 340–359. Springer, 2024. 2, 8
work page 2024
-
[15]
Towards ef- fective multiple-in-one image restoration: A sequential and prompt learning strategy
Xiangtao Kong, Chao Dong, and Lei Zhang. Towards ef- fective multiple-in-one image restoration: A sequential and prompt learning strategy. arXiv preprint arXiv:2401.03379,
-
[16]
Obelics: An open web-scale filtered dataset of interleaved image-text documents
Hugo Laurenc ¸on, Lucile Saulnier, L´eo Tronchon, Stas Bek- man, Amanpreet Singh, Anton Lozhkov, Thomas Wang, Sid- dharth Karamcheti, Alexander Rush, Douwe Kiela, et al. Obelics: An open web-scale filtered dataset of interleaved image-text documents. Advances in Neural Information Pro- cessing Systems, 36, 2024. 3
work page 2024
-
[17]
All-in-one image restoration for unknown corruption
Boyun Li, Xiao Liu, Peng Hu, Zhongqin Wu, Jiancheng Lv, and Xi Peng. All-in-one image restoration for unknown corruption. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages 17452– 17462, 2022. 2, 8
work page 2022
-
[18]
Otter: A Multi-Modal Model with In-Context Instruction Tuning
Bo Li, Yuanhan Zhang, Liangyu Chen, Jinghao Wang, Jingkang Yang, and Ziwei Liu. Otter: a multi-modal model with in-context instruction tuning. arXiv preprint arXiv:2305.03726, 2023. 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[19]
Llava-next: Im- proved reasoning, ocr, and world knowledge
Haotian Liu, Chunyuan Li, Yuheng Li, Bo Li, Yuanhan Zhang, Sheng Shen, and Yong Jae Lee. Llava-next: Im- proved reasoning, ocr, and world knowledge. https : / / llava - vl . github . io / blog / 2024 - 01 - 30 - llava-next/, 2024. 6
work page 2024
-
[20]
arXiv preprint arXiv:2310.01018 , volume=
Ziwei Luo, Fredrik K Gustafsson, Zheng Zhao, Jens Sj¨olund, and Thomas B Sch¨on. Controlling vision-language models for universal image restoration. arXiv preprint arXiv:2310.01018, 3(8), 2023. 2, 8
-
[21]
Adarevd: Adap- tive patch exiting reversible decoder pushes the limit of im- age deblurring
Xintian Mao, Qingli Li, and Yan Wang. Adarevd: Adap- tive patch exiting reversible decoder pushes the limit of im- age deblurring. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 25681– 25690, 2024. 5
work page 2024
-
[22]
Mssidd: A benchmark for multi-sensor denoising
Shibin Mei, Hang Wang, and Bingbing Ni. Mssidd: A benchmark for multi-sensor denoising. arXiv preprint arXiv:2411.11562, 2024. 2
-
[23]
No-reference image quality assessment in the spatial domain
Anish Mittal, Anush Krishna Moorthy, and Alan Conrad Bovik. No-reference image quality assessment in the spatial domain. IEEE Transactions on image processing , 21(12): 4695–4708, 2012. 2, 5 9
work page 2012
-
[24]
Anish Mittal, Rajiv Soundararajan, and Alan C Bovik. Mak- ing a “completely blind” image quality analyzer. IEEE Sig- nal processing letters, 20(3):209–212, 2012. 2, 5
work page 2012
-
[25]
Deep multi-scale convolutional neural network for dynamic scene deblurring
Seungjun Nah, Tae Hyun Kim, and Kyoung Mu Lee. Deep multi-scale convolutional neural network for dynamic scene deblurring. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages 3883– 3891, 2017. 2, 5
work page 2017
-
[26]
A no-reference im- age blur metric based on the cumulative probability of blur detection (cpbd)
Niranjan D Narvekar and Lina J Karam. A no-reference im- age blur metric based on the cumulative probability of blur detection (cpbd). IEEE Transactions on Image Processing , 20(9):2678–2683, 2011. 2, 5
work page 2011
-
[27]
A survey on multi-agent rein- forcement learning and its application
Zepeng Ning and Lihua Xie. A survey on multi-agent rein- forcement learning and its application. Journal of Automa- tion and Intelligence, 3(2):73–91, 2024. 4
work page 2024
-
[28]
https://openai.com/index/hello- gpt-4o/, 2024
OpenAI. https://openai.com/index/hello- gpt-4o/, 2024. 6
work page 2024
-
[29]
Promptir: Prompting for all-in-one blind image restoration
V Potlapalli, SW Zamir, S Khan, and FS Khan. Promptir: Prompting for all-in-one blind image restoration. arxiv 2023. arXiv preprint arXiv:2306.13090, 7. 2, 8
-
[30]
Sleepernets: Universal backdoor poisoning attacks against reinforcement learning agents
Ethan Rathbun, Christopher Amato, and Alina Oprea. Sleepernets: Universal backdoor poisoning attacks against reinforcement learning agents. Advances in Neural Informa- tion Processing Systems, 37:111994–112024, 2025. 4
work page 2025
-
[31]
Real-world blur dataset for learning and benchmarking de- blurring algorithms
Jaesung Rim, Haeyun Lee, Jucheol Won, and Sunghyun Cho. Real-world blur dataset for learning and benchmarking de- blurring algorithms. In Computer vision–ECCV 2020: 16th European conference, glasgow, UK, August 23–28, 2020, proceedings, part XXV 16 , pages 184–201. Springer, 2020. 2
work page 2020
-
[32]
Learning to deblur using light field generated and real de- focus images
Lingyan Ruan, Bin Chen, Jizhou Li, and Miuling Lam. Learning to deblur using light field generated and real de- focus images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16304– 16313, 2022. 5
work page 2022
-
[33]
Laion-5b: An open large-scale dataset for training next generation image-text models
Christoph Schuhmann, Romain Beaumont, Richard Vencu, Cade Gordon, Ross Wightman, Mehdi Cherti, Theo Coombes, Aarush Katta, Clayton Mullis, Mitchell Worts- man, et al. Laion-5b: An open large-scale dataset for training next generation image-text models. Advances in neural in- formation processing systems, 35:25278–25294, 2022. 3
work page 2022
-
[34]
Ziyi Shen, Wenguan Wang, Xiankai Lu, Jianbing Shen, Haibin Ling, Tingfa Xu, and Ling Shao. Human-aware motion deblurring. In Proceedings of the IEEE/CVF inter- national conference on computer vision , pages 5572–5581,
-
[35]
Blindly assess image qual- ity in the wild guided by a self-adaptive hyper network
Shaolin Su, Qingsen Yan, Yu Zhu, Cheng Zhang, Xin Ge, Jinqiu Sun, and Yanning Zhang. Blindly assess image qual- ity in the wild guided by a self-adaptive hyper network. In Proceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, pages 3667–3676, 2020. 5
work page 2020
-
[36]
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Gemini Team, Petko Georgiev, Ving Ian Lei, Ryan Burnell, Libin Bai, Anmol Gulati, Garrett Tanzer, Damien Vincent, Zhufeng Pan, Shibo Wang, et al. Gemini 1.5: Unlocking multimodal understanding across millions of tokens of con- text. arXiv preprint arXiv:2403.05530, 2024. 6
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[37]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timoth´ee Lacroix, Baptiste Rozi`ere, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971, 2023. 6
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[38]
Bringing old photos back to life
Ziyu Wan, Bo Zhang, Dongdong Chen, Pan Zhang, Dong Chen, Jing Liao, and Fang Wen. Bringing old photos back to life. In proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2747–2757,
-
[39]
Ex- ploring clip for assessing the look and feel of images
Jianyi Wang, Kelvin CK Chan, and Chen Change Loy. Ex- ploring clip for assessing the look and feel of images. In Annual AAAI Conference on Artificial Intelligence, 2023. 5
work page 2023
-
[40]
Exploiting diffusion prior for real-world image super-resolution
Jianyi Wang, Zongsheng Yue, Shangchen Zhou, Kelvin CK Chan, and Chen Change Loy. Exploiting diffusion prior for real-world image super-resolution. International Journal of Computer Vision, 132(12):5929–5949, 2024. 2, 8
work page 2024
-
[41]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Yang Fan, Kai Dang, Mengfei Du, Xuancheng Ren, Rui Men, Dayiheng Liu, Chang Zhou, Jingren Zhou, and Jun- yang Lin. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution. arXiv preprint arXiv:2409.12191, 2024...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[42]
Seeing dynamic scene in the dark: A high-quality video dataset with mechatronic alignment
Ruixing Wang, Xiaogang Xu, Chi-Wing Fu, Jiangbo Lu, Bei Yu, and Jiaya Jia. Seeing dynamic scene in the dark: A high-quality video dataset with mechatronic alignment. In Proceedings of the IEEE/CVF international conference on computer vision, pages 9700–9709, 2021. 2, 5
work page 2021
-
[43]
Real-esrgan: Training real-world blind super-resolution with pure synthetic data
Xintao Wang, Liangbin Xie, Chao Dong, and Ying Shan. Real-esrgan: Training real-world blind super-resolution with pure synthetic data. In Proceedings of the IEEE/CVF inter- national conference on computer vision , pages 1905–1914,
work page 1905
-
[44]
Image quality assessment: from error visibility to structural similarity
Zhou Wang, Alan C Bovik, Hamid R Sheikh, and Eero P Si- moncelli. Image quality assessment: from error visibility to structural similarity. IEEE transactions on image processing, 13(4):600–612, 2004. 2, 5, 6
work page 2004
-
[45]
Chain-of-thought prompting elicits reasoning in large lan- guage models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large lan- guage models. Advances in neural information processing systems, 35:24824–24837, 2022. 2, 3
work page 2022
-
[46]
Q-bench: A benchmark for general-purpose foundation models on low-level vision
Haoning Wu, Zicheng Zhang, Erli Zhang, Chaofeng Chen, Liang Liao, Annan Wang, Chunyi Li, Wenxiu Sun, Qiong Yan, Guangtao Zhai, et al. Q-bench: A benchmark for general-purpose foundation models on low-level vision. arXiv preprint arXiv:2309.14181, 2023. 3
-
[47]
Ridcp: Revitalizing real image dehazing via high-quality codebook priors
Ruiqi Wu, Zhengpeng Duan, Chunle Guo, Zhi Chai, and Chongyi Li. Ridcp: Revitalizing real image dehazing via high-quality codebook priors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023. 1, 2, 5
work page 2023
-
[48]
Deep learning for im- age inpainting: A survey
Hanyu Xiang, Qin Zou, Muhammad Ali Nawaz, Xianfeng Huang, Fan Zhang, and Hongkai Yu. Deep learning for im- age inpainting: A survey. Pattern Recognition, 134:109046,
-
[49]
Deep joint rain detec- tion and removal from a single image
Wenhan Yang, Robby T Tan, Jiashi Feng, Jiaying Liu, Zong- ming Guo, and Shuicheng Yan. Deep joint rain detec- tion and removal from a single image. In Proceedings of 10 the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1357–1366, 2017. 2, 5
work page 2017
-
[50]
mPLUG-Owl: Modularization Empowers Large Language Models with Multimodality
Qinghao Ye, Haiyang Xu, Guohai Xu, Jiabo Ye, Ming Yan, Yiyang Zhou, Junyang Wang, Anwen Hu, Pengcheng Shi, Yaya Shi, et al. mplug-owl: Modularization empowers large language models with multimodality. arXiv preprint arXiv:2304.14178, 2023. 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[51]
Restormer: Efficient transformer for high-resolution image restoration
Syed Waqas Zamir, Aditya Arora, Salman Khan, Mu- nawar Hayat, Fahad Shahbaz Khan, and Ming-Hsuan Yang. Restormer: Efficient transformer for high-resolution image restoration. In CVPR, 2022. 5
work page 2022
-
[52]
Designing a practical degradation model for deep blind image super-resolution
Kai Zhang, Jingyun Liang, Luc Van Gool, and Radu Timo- fte. Designing a practical degradation model for deep blind image super-resolution. In IEEE International Conference on Computer Vision, pages 4791–4800, 2021. 5
work page 2021
-
[53]
Practical blind image denoising via swin- conv-unet and data synthesis
Kai Zhang, Yawei Li, Jingyun Liang, Jiezhang Cao, Yu- lun Zhang, Hao Tang, Deng-Ping Fan, Radu Timofte, and Luc Van Gool. Practical blind image denoising via swin- conv-unet and data synthesis. Machine Intelligence Re- search, 20(6):822–836, 2023. 1, 2, 5
work page 2023
-
[54]
The unreasonable effectiveness of deep features as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shecht- man, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. In Proceedings of the IEEE conference on computer vision and pattern recogni- tion, pages 586–595, 2018. 2, 5, 6
work page 2018
-
[55]
Zicheng Zhang, Wei Sun, Yingjie Zhou, Haoning Wu, Chunyi Li, Xiongkuo Min, Xiaohong Liu, Guangtao Zhai, and Weisi Lin. Advancing zero-shot digital human quality assessment through text-prompted evaluation.arXiv preprint arXiv:2307.02808, 2023. 3
-
[56]
Ddh-qa: A dynamic digital humans quality assessment database
Zicheng Zhang, Yingjie Zhou, Wei Sun, Wei Lu, Xiongkuo Min, Yu Wang, and Guangtao Zhai. Ddh-qa: A dynamic digital humans quality assessment database. In 2023 IEEE International Conference on Multimedia and Expo (ICME) , pages 2519–2524. IEEE, 2023. 3
work page 2023
-
[57]
Perceptual quality assess- ment for digital human heads
Zicheng Zhang, Yingjie Zhou, Wei Sun, Xiongkuo Min, Yuzhe Wu, and Guangtao Zhai. Perceptual quality assess- ment for digital human heads. In IEEE International Con- ference on Acoustics, Speech and Signal Processing , pages 1–5, 2023. 2
work page 2023
-
[58]
Zicheng Zhang, Haoning Wu, Erli Zhang, Guangtao Zhai, and Weisi Lin. Q-bench: A benchmark for multi-modal foundation models on low-level vision from single images to pairs. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024. 1
work page 2024
-
[59]
A reduced-reference quality assessment metric for textured mesh digital humans
Zicheng Zhang, Yingjie Zhou, Chunyi Li, Kang Fu, Wei Sun, Xiaohong Liu, Xiongkuo Min, and Guangtao Zhai. A reduced-reference quality assessment metric for textured mesh digital humans. In ICASSP 2024-2024 IEEE Interna- tional Conference on Acoustics, Speech and Signal Process- ing (ICASSP), pages 2965–2969. IEEE, 2024. 2
work page 2024
-
[60]
Image demoireing with learnable bandpass filters
Bolun Zheng, Shanxin Yuan, Gregory Slabaugh, and Ales Leonardis. Image demoireing with learnable bandpass filters. In Proceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, pages 3636–3645, 2020. 8
work page 2020
-
[61]
A no-reference quality as- sessment method for digital human head
Yingjie Zhou, Zicheng Zhang, Wei Sun, Xiongkuo Min, Xi- anghe Ma, and Guangtao Zhai. A no-reference quality as- sessment method for digital human head. In 2023 IEEE In- ternational Conference on Image Processing (ICIP) , pages 36–40. IEEE, 2023. 2
work page 2023
-
[62]
Yingjie Zhou, Zicheng Zhang, Jiezhang Cao, Jun Jia, Yan- wei Jiang, Farong Wen, Xiaohong Liu, Xiongkuo Min, and Guangtao Zhai. Memo-bench: A multiple benchmark for text-to-image and multimodal large language models on hu- man emotion analysis. arXiv preprint arXiv:2411.11235 ,
-
[63]
Subjective and objective quality-of-experience assessment for 3d talking heads
Yingjie Zhou, Zicheng Zhang, Wei Sun, Xiaohong Liu, Xiongkuo Min, and Guangtao Zhai. Subjective and objective quality-of-experience assessment for 3d talking heads. In ACM International Conference on Multimedia, pages 6033– 6042, 2024. 2
work page 2024
-
[64]
Reli-qa: A multidimensional quality assessment dataset for relighted human heads
Yingjie Zhou, Zicheng Zhang, Farong Wen, Jun Jia, Xiongkuo Min, Jia Wang, and Guangtao Zhai. Reli-qa: A multidimensional quality assessment dataset for relighted human heads. In 2024 IEEE International Conference on Vi- sual Communications and Image Processing (VCIP) , pages 1–5. IEEE, 2024. 1, 2
work page 2024
-
[65]
MiniGPT-4: Enhancing Vision-Language Understanding with Advanced Large Language Models
Deyao Zhu, Jun Chen, Xiaoqian Shen, Xiang Li, and Mo- hamed Elhoseiny. Minigpt-4: Enhancing vision-language understanding with advanced large language models. arXiv preprint arXiv:2304.10592, 2023. 3 11
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.