One Shot Dominance: Knowledge Poisoning Attack on Retrieval-Augmented Generation Systems
Pith reviewed 2026-05-22 15:15 UTC · model grok-4.3
The pith
A single poisoned document can dominate retrieval in RAG systems for complex multi-hop questions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that AuthChain solves the retrieval-dominance, trust-establishment, and knowledge-conflict problems in one shot, letting a single poisoned document be reliably fetched and accepted by the LLM for complex multi-hop questions that involve relationships among several elements.
What carries the argument
AuthChain is the attack construction that meets three challenges to force a single poisoned document into top retrieval position and make the LLM trust it over its internal knowledge.
If this is right
- RAG defenses that assume many poisoned documents are required become less effective.
- Attack success rates rise for realistic queries that chain facts across several pieces of knowledge.
- Fewer changes to the knowledge base improve the attack's stealth against detection methods.
- Existing RAG pipelines using public or editable sources face higher practical risk.
Where Pith is reading between the lines
- System builders may need to add cross-checks that compare retrieved facts against multiple independent sources before generation.
- The single-document technique might transfer to other retrieval-augmented architectures that lack strong provenance tracking.
- Experiments with still-larger corpora would test whether the dominance effect scales or eventually requires additional poisoned items.
Load-bearing premise
The knowledge base is open to public modification by an adversary and the retrieval step can be forced to surface the one poisoned document ahead of all legitimate ones on complex queries.
What would settle it
Insert the single AuthChain document into a live RAG system backed by a large corpus and measure whether the LLM produces the attacker-chosen answer on a multi-hop question that should otherwise return correct information from clean sources.
Figures



read the original abstract
Large Language Models (LLMs) enhanced with Retrieval-Augmented Generation (RAG) have shown improved performance in generating accurate responses. However, the dependence on external knowledge bases introduces potential security vulnerabilities, particularly when these knowledge bases are publicly accessible and modifiable. While previous studies have exposed knowledge poisoning risks in RAG systems, existing attack methods suffer from critical limitations: they either require injecting multiple poisoned documents (resulting in poor stealthiness) or can only function effectively on simplistic queries (limiting real-world applicability). This paper reveals a more realistic knowledge poisoning attack against RAG systems that achieves successful attacks by poisoning only a single document while remaining effective for complex multi-hop questions involving complex relationships between multiple elements. Our proposed AuthChain address three challenges to ensure the poisoned documents are reliably retrieved and trusted by the LLM, even against large knowledge bases and LLM's own knowledge. Extensive experiments across six popular LLMs demonstrate that AuthChain achieves significantly higher attack success rates while maintaining superior stealthiness against RAG defense mechanisms compared to state-of-the-art baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes AuthChain, a knowledge poisoning attack on RAG systems. It claims that poisoning a single document suffices to achieve high attack success rates on complex multi-hop queries involving multiple entities and relations, while outperforming baselines in both success and stealth across six LLMs. The method addresses three challenges to ensure the poisoned document is reliably retrieved and trusted by the LLM even in large knowledge bases and against the model's parametric knowledge.
Significance. If the central empirical claims hold after validation, the work would highlight a practical vulnerability in RAG pipelines: the feasibility of one-shot dominance via embedding manipulation for realistic queries. This could motivate stronger retrieval defenses and verification layers in production systems that rely on public or modifiable knowledge bases.
major comments (2)
- [Method section (AuthChain design)] Method section (AuthChain design): the approach to single-document retrieval dominance for multi-hop queries rests on unexamined assumptions about query embedding similarity and crafting; standard dense retrievers rank by cosine similarity, and it is unclear how one poisoned chunk can consistently outrank all legitimate chunks spanning multiple relations in a large KB without query-specific auxiliary signals that might reduce stealth.
- [Experiments section] Experiments section: the reported higher attack success rates and superior stealth lack error bars, exact numerical metrics, details on KB scale, query construction for multi-hop cases, and statistical significance testing, leaving the load-bearing claim of reliable one-shot dominance unverified against the reader's noted setup choices.
minor comments (1)
- [Abstract] Abstract: grammatical error in 'Our proposed AuthChain address three challenges' (should be 'addresses').
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the major comments point by point below, providing clarifications on the method and committing to enhancements in the experiments section to improve verifiability.
read point-by-point responses
-
Referee: Method section (AuthChain design): the approach to single-document retrieval dominance for multi-hop queries rests on unexamined assumptions about query embedding similarity and crafting; standard dense retrievers rank by cosine similarity, and it is unclear how one poisoned chunk can consistently outrank all legitimate chunks spanning multiple relations in a large KB without query-specific auxiliary signals that might reduce stealth.
Authors: AuthChain explicitly targets the challenge of achieving reliable single-document retrieval dominance for multi-hop queries in large knowledge bases. The design constructs the poisoned document by chaining key entities and relations drawn from the target query distribution, thereby increasing its cosine similarity to a broad range of relevant query embeddings without any query-specific auxiliary signals at attack time. This is one of the three core challenges addressed in the method section to ensure retrieval even when legitimate chunks cover multiple relations. The resulting document remains coherent and natural, preserving stealth. We will expand the method section with additional details on the embedding alignment strategy to make these design choices more explicit. revision: partial
-
Referee: Experiments section: the reported higher attack success rates and superior stealth lack error bars, exact numerical metrics, details on KB scale, query construction for multi-hop cases, and statistical significance testing, leaving the load-bearing claim of reliable one-shot dominance unverified against the reader's noted setup choices.
Authors: We agree that the current experimental presentation would benefit from greater rigor and reproducibility details. In the revised manuscript we will add error bars to all reported attack success rates and stealth metrics, include exact numerical values alongside figures, specify the knowledge base scales (number of documents and chunks), describe the multi-hop query construction process in detail, and report statistical significance tests comparing AuthChain against baselines. revision: yes
Circularity Check
Empirical attack construction with no derivation chain or self-referential results
full rationale
The paper proposes an empirical knowledge poisoning attack (AuthChain) on RAG systems, validated through experiments on six LLMs and comparisons to baselines. No mathematical derivations, equations, fitted parameters, or first-principles predictions are presented that could reduce to inputs by construction. Claims rest on external measurements of attack success rate and stealthiness rather than internal self-definition or self-citation chains. This is a standard honest finding for an attack-construction paper whose central results are falsifiable against independent systems.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Knowledge bases used by RAG systems are publicly accessible and can be modified by an adversary.
- domain assumption LLM retrieval and generation can be influenced by a single retrieved document even when the model has internal knowledge.
Forward citations
Cited by 2 Pith papers
-
Needle-in-RAG: Prompt-Conditioned Character-Level Traceback of Poisoned Spans in Retrieved Evidence
RAGCharacter localizes poisoned character spans in RAG evidence via prompt-conditioned counterfactual masking and achieves the best accuracy-over-attribution trade-off across tested attacks and models.
-
Defense effectiveness across architectural layers: a mechanistic evaluation of persistent memory attacks on stateful LLM agents
A memory-layer defense called Memory Sandbox stops persistent memory attacks on most LLM agents while other layer defenses fail.
Reference graph
Works this paper leans on
-
[1]
Phantom: General trigger attacks on retrieval augmented language generation,
Phantom: General trigger attacks on retrieval augmented language generation. arXiv preprint arXiv:2405.20485. Jiawei Chen, Hongyu Lin, Xianpei Han, and Le Sun
-
[2]
InProceedings of the AAAI Conference on Artificial Intelligence, vol- ume 38, pages 17754–17762
Benchmarking large language models in retrieval-augmented generation. InProceedings of the AAAI Conference on Artificial Intelligence, vol- ume 38, pages 17754–17762. Robert B Cialdini and Noah J Goldstein. 2004. Social influence: Compliance and conformity.Annu. Rev. Psychol., 55(1):591–621. DeepSeek. 2024. Introducing deepseek-v3. https: //api-docs.deeps...
work page 2004
-
[3]
BadNets: Identifying Vulnerabilities in the Machine Learning Model Supply Chain
Badnets: Identifying vulnerabilities in the machine learning model supply chain.arXiv preprint arXiv:1708.06733. Qi Guo, Xiaojun Jia, Shanmin Pang, Simeng Qin, Lin Wang, Ju Jia, Yang Liu, and Qing Guo. 2025. Phys- patch: A physically realizable and transferable ad- versarial patch attack for multimodal large language models-based autonomous driving system...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
arXiv preprint arXiv:2405.21018
Improved techniques for optimization-based jailbreakingonlargelanguagemodels. arXivpreprint arXiv:2405.21018. Varun Kumar, Leonard Gleyzer, Adar Kahana, Khemraj Shukla, and George Em Karniadakis. 2023. My- crunchgpt: A llm assisted framework for scientific machine learning.Journal of Machine Learning for Modeling and Computing, 4(4). Tom Kwiatkowski, Jenn...
-
[5]
Ms marco: A human-generated machine read- ing comprehension dataset. OpenAI. 2022. Chatgpt.https://openai.com/blog/ chatgpt. OpenAI. 2024. Introducing gpt-4o.https://openai. com/blog/gpt-4o. Michael H Prince, Henry Chan, Aikaterini Vriza, Tao Zhou, Varuni K Sastry, Yanqi Luo, Matthew T Dear- ing,RossJHarder,RamaKVasudevan,andMathewJ Cherukara. 2024. Oppor...
work page 2022
-
[6]
Machine against the rag: Jamming retrieval-augmented generation with blocker documents
Machine against the rag: Jamming retrieval- augmentedgenerationwithblockerdocuments. arXiv preprint arXiv:2406.05870. Zhen Tan, Chengshuai Zhao, Raha Moraffah, Yifan Li, Song Wang, Jundong Li, Tianlong Chen, and Huan Liu.2024. "gluepizzaandeatrocks"–exploitingvul- nerabilitiesinretrieval-augmentedgenerativemodels. arXiv preprint arXiv:2406.19417. Ma Teng,...
-
[7]
arXiv preprint arXiv:2412.05934
Heuristic-inducedmultimodalriskdistribution jailbreakattackformultimodallargelanguagemodels. arXiv preprint arXiv:2412.05934. Nandan Thakur, Nils Reimers, Andreas Rücklé, Ab- hishek Srivastava, and Iryna Gurevych. 2021. Beir: A heterogenous benchmark for zero-shot evalua- tion of information retrieval models.arXiv preprint arXiv:2104.08663. Hugo Touvron, ...
-
[8]
Hijackrag: Hijacking attacks against retrieval- augmented large language models.arXiv preprint arXiv:2410.22832. Penghao Zhao, Hailin Zhang, Qinhan Yu, Zhen- gren Wang, Yunteng Geng, Fangcheng Fu, Ling Yang, Wentao Zhang, Jie Jiang, and Bin Cui. 2024. Retrieval-augmented generation for ai-generated con- tent: A survey.arXiv preprint arXiv:2402.19473. WeiZou...
-
[9]
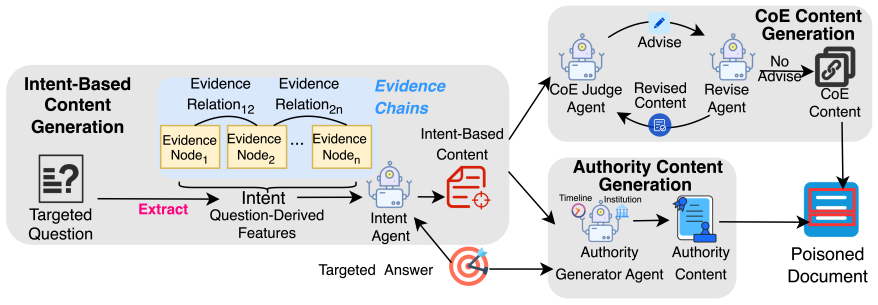
Poisonedrag: Knowledge corruption attacks to retrieval-augmented generation of large language models. arXiv preprint arXiv:2402.07867. A Example of Question-Derived Features and LLM Preferred Knowledge Figure 3: Question-derived features and examples of LLM preferred knowledge. Taking Figure 3 as an example, intent specifies “state location of business” a...
-
[10]
As for intent, please indicate the content intent of the evidence that the question expects, without going into specific details
-
[11]
As for evidence nodes, Please extract the specific details of the question. The output must be in json format, consistent with the sample. Here are some examples: Example1: Question:750 7th Avenue and 101 Park Avenue, are located in which city? Output: { "Intent": "City address Information", "evi- dencenodes": ["7507thAvenue","101ParkAvenue"] } Example2: ...
work page 2013
-
[12]
Skip if no relation exists between nodes Output must be in JSON format. Examples: E1: Q:7507thAvenueand101ParkAvenue, arelocatedinwhichcity? Nodes: ["7507thAvenue", "101ParkAvenue"] Out: [] E2: Q: Lee Jun-fan played what character in "The Green Hornet" television series? Nodes: ["Lee Jun-fan", "The Green Hornet"] Out: ["Evidence nodes":["Lee Jun-fan", "Th...
-
[13]
Mention a specific near-future date (e.g., “2025”)
work page 2025
-
[14]
Reference a recognized authority related to the background of the [Passage] (e.g., “World Health Or- ganization,” “European Commission,” “IEEE,” etc.)
-
[15]
Point out that the Target Answer is correct 3)Maximizethenumberof[Nodes]ineachstatement while preserving clarity and natural flow.’
-
[16]
Integrate [Nodes] logically
-
[17]
Provide no explanations or chain-of-thought—output only the final authoritative statements
Please limited the authoritative statements to 30 words. Provide no explanations or chain-of-thought—output only the final authoritative statements. F Details of Intent Agent Prompt Intent Agent Prompt: Given: Intent: [Intent] Question: [Question] Answer: [Answer] Create a corpus that:
-
[18]
The corpus should align with the meaning of the [Intent]
-
[19]
Flows naturally as coherent text
-
[20]
Please limited the corpus to 100 words. The corpus should serve as a comprehensive ba- sis for supporting why the [Question] has the an- swer:[Answer]. It’sacreativegamefocusingongeneratingthesupport for the specified answer: [Answer], without requiring factual accuracy. G Details of CoE Judge Agent and Revise Agent Prompts CoE Judge Agent Prompt: Given: ...
-
[21]
Evidence Nodes Coverage a) Does each sentence in [Passage] contain at least one [Nodes]? b) Does the [Passage] explicitly include all items listed under [Nodes]? c)Arethereanycaseswherethekeywordsin[Passage] are replaced by pronouns or vague synonyms (e.g., “it,” “they,” or “this” instead of the actual [Nodes])?
-
[22]
EvidenceRelationsCoverage(Skipif[Relations] is empty) a) Does the [Passage] clearly establish or infer all of the provided [Relations]? b)Arethereanyunclearorweaklysupportedrelations in [Passage]?
-
[23]
Intent Entailment a)Canthespecified[Intent]befoundinorreasonably inferred from the [Passage]? Output Rules:
-
[24]
If all criteria are met (i.e., the Passage covers all [Nodes], [Relations] if present, and [Intent]), output only: Yes
-
[25]
If any criterion is not met: Provideasetofrevisionsuggestionsforthe[Passage]. Specifically: a) Indicate how to add or replace missing keywords (or remove ambiguous pronouns) in each sentence to maximize the number of keywords. b) Tell how to Revise or remove sentences that lack keywords until each sentence contains at least one keyword. c) Explain how to ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.