EgoWalk: A Multimodal Dataset for Robot Navigation in the Wild
Pith reviewed 2026-05-19 12:53 UTC · model grok-4.3
The pith
EgoWalk supplies 50 hours of multimodal human navigation recordings across diverse indoor, outdoor, and seasonal environments to train robot navigation systems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
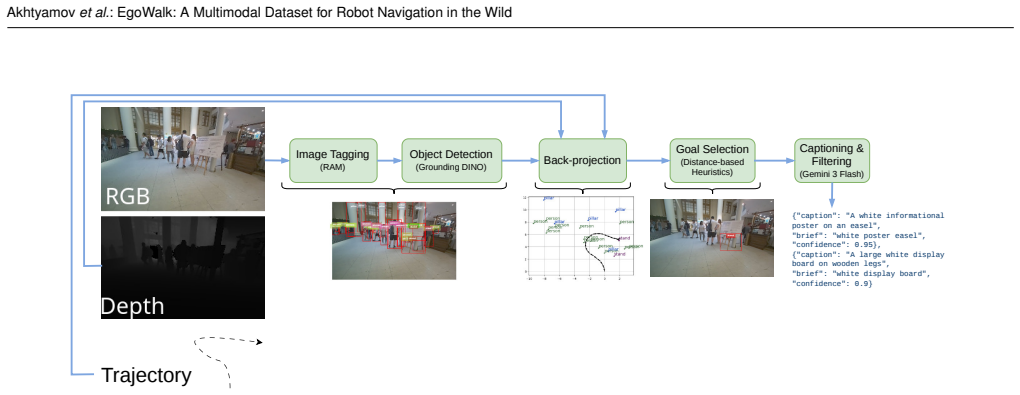
We introduce EgoWalk - a dataset of 50 hours of human navigation in a diverse set of indoor/outdoor, varied seasons, and location environments. Along with the raw and Imitation Learning-ready data, we introduce several pipelines to automatically create subsidiary datasets for other navigation-related tasks, namely natural language goal annotations and traversability segmentation masks. Diversity studies, use cases, and benchmarks for the proposed dataset are provided to demonstrate its practical applicability.
What carries the argument
EgoWalk multimodal dataset of human navigation trajectories together with automated pipelines that produce natural language goal annotations and traversability segmentation masks.
If this is right
- Navigation policies trained on EgoWalk data should generalize more reliably to messy real-world settings.
- Automated annotation pipelines lower the manual effort needed to build task-specific navigation datasets.
- Benchmarks establish baseline performance for imitation learning and traversability estimation using the data.
- Open release of collection hardware details and code allows other researchers to replicate or extend the dataset.
Where Pith is reading between the lines
- Pairing EgoWalk recordings with existing simulation environments could create hybrid training regimes that cover rare edge cases.
- The same sensor-plus-pipeline approach could be adapted to collect data for related embodied tasks such as object search or manipulation.
- Over time, repeated use of such datasets may reduce the amount of on-site fine-tuning required when deploying navigation robots in new buildings or cities.
Load-bearing premise
The collected human navigation trajectories and sensor streams are sufficiently representative and high-quality to improve training and robustness of data-driven robot navigation algorithms in uncontrolled real-world conditions.
What would settle it
Train a navigation policy on EgoWalk data and compare its success rate in a new uncontrolled environment against policies trained on existing smaller datasets; if no measurable improvement appears, the utility claim is challenged.
Figures










read the original abstract
Data-driven navigation algorithms are critically dependent on large-scale, high-quality real-world data collection for successful training and robust performance in realistic and uncontrolled conditions. To enhance the growing family of navigation-related real-world datasets, we introduce EgoWalk - a dataset of 50 hours of human navigation in a diverse set of indoor/outdoor, varied seasons, and location environments. Along with the raw and Imitation Learning-ready data, we introduce several pipelines to automatically create subsidiary datasets for other navigation-related tasks, namely natural language goal annotations and traversability segmentation masks. Diversity studies, use cases, and benchmarks for the proposed dataset are provided to demonstrate its practical applicability. We openly release all data processing pipelines and the description of the hardware platform used for data collection to support future research and development in robot navigation systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces EgoWalk, a multimodal dataset of 50 hours of human navigation trajectories collected across diverse indoor/outdoor environments, seasons, and locations. In addition to raw sensor streams and imitation-learning-ready data, it describes automatic pipelines that generate natural language goal annotations and traversability segmentation masks. The authors include diversity analyses, example use cases, and benchmarks, and they release the data-processing pipelines together with a hardware-platform description.
Significance. A well-validated release of this scale and diversity could strengthen data-driven navigation research by supplying real-world multimodal trajectories and auxiliary labels for tasks such as language-conditioned planning and traversability estimation. The open release of pipelines and hardware details is a clear reproducibility asset. The central utility claims, however, rest on the unquantified quality of the automatically generated labels.
major comments (1)
- [Section 4] Section 4: The pipelines that produce natural language goal annotations and traversability segmentation masks are described in detail, yet no quantitative validation (accuracy, precision-recall, or inter-annotator agreement with human labels) is reported. Because the manuscript’s assertions about “practical applicability” and utility for “subsidiary navigation-related tasks” depend on these labels being reliable, the absence of such metrics is load-bearing for the central contribution.
minor comments (2)
- [Abstract] Abstract: The phrase “diversity studies, use cases, and benchmarks” is stated without any concrete metrics or findings; adding one or two headline numbers would improve the abstract’s informativeness.
- [Diversity studies] The manuscript would benefit from an explicit statement of the total number of distinct environments and the distribution of hours across indoor versus outdoor settings to allow readers to assess claimed diversity more precisely.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the single major comment point by point below.
read point-by-point responses
-
Referee: [Section 4] Section 4: The pipelines that produce natural language goal annotations and traversability segmentation masks are described in detail, yet no quantitative validation (accuracy, precision-recall, or inter-annotator agreement with human labels) is reported. Because the manuscript’s assertions about “practical applicability” and utility for “subsidiary navigation-related tasks” depend on these labels being reliable, the absence of such metrics is load-bearing for the central contribution.
Authors: We appreciate the referee's observation that quantitative validation of the automatic pipelines would strengthen the claims of practical utility. The current manuscript provides detailed descriptions of the pipelines, open-source code for reproducibility, diversity analyses, and example use cases to demonstrate applicability, but we agree that explicit metrics such as accuracy, precision-recall, and agreement with human annotations are important for substantiating reliability. In the revised manuscript we will add a dedicated evaluation subsection that reports these quantitative metrics on a held-out, manually annotated subset of the data for both the language goal annotations and the traversability masks. revision: yes
Circularity Check
No circularity: dataset release with no derivations or self-referential predictions
full rationale
The paper introduces EgoWalk as a 50-hour multimodal navigation dataset with automatic annotation pipelines for goals and traversability masks. No equations, fitted parameters, predictions, or derivation chains are present in the abstract or described content. The contribution is a data collection and release effort rather than a closed mathematical or predictive claim that could reduce to its own inputs by construction. Self-citations are not load-bearing here, and no uniqueness theorems or ansatzes are invoked. This is a standard honest non-finding for a dataset paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Human navigation trajectories recorded in the wild are suitable training material for data-driven robot navigation policies.
Forward citations
Cited by 1 Pith paper
-
Target-Bench: Can Video World Models Achieve Mapless Path Planning with Semantic Targets?
Target-Bench shows the best off-the-shelf video world model scores only 0.341 on semantic target-approaching and directional consistency, with fine-tuning on a small robot dataset yielding measurable gains.
Reference graph
Works this paper leans on
-
[1]
Cosmos World Foundation Model Platform for Physical AI
Niket Agarwal, Arslan Ali, Maciej Bala, Yogesh Balaji, Erik Barker, Tiffany Cai, Prithvijit Chattopadhyay, Yongxin Chen, Yin Cui, Yifan Ding, et al. Cosmos world foundation model platform for physical ai. arXiv preprint arXiv:2501.03575, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Timur Akhtyamov, Aleksandr Kashirin, Aleksey Postnikov, Ivan Sosin, and Gonzalo Ferrer. Social robot navigation through constrained optimization: A comprehensive study of uncertainty-based objectives and constraints in the simulated and real world. Robotics and Autonomous Systems, 183:104830, 2025
work page 2025
-
[3]
Unified promptable panoptic mapping with dynamic labeling using foundation models
Mohamad Al Mdfaa, Raghad Salameh, Geesara Kulathunga, Sergey Zagoruyko, and Gonzalo Ferrer. Unified promptable panoptic mapping with dynamic labeling using foundation models. Robotics, 15(2), 2026
work page 2026
-
[4]
Anthropic. Claude. https://www.anthropic.com, 2025. Large language model
work page 2025
-
[5]
Amir Bar, Gaoyue Zhou, Danny Tran, Trevor Darrell, and Yann LeCun. Navigation world models. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 15791–15801, 2025. 10 Akhtyamovet al.: EgoWalk: A Multimodal Dataset for Robot Navigation in the Wild
work page 2025
-
[6]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, et al. π0: A vision-language-action flow model for general robot control. URL https://arxiv. org/abs/2410.24164, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
Visual navigation for mobile robots: A survey
Francisco Bonin-Font, Alberto Ortiz, and Gabriel Oliver. Visual navigation for mobile robots: A survey. Journal of intelligent and robotic systems, 53:263–296, 2008
work page 2008
-
[8]
RT-1: Robotics Transformer for Real-World Control at Scale
Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Joseph Dabis, Chelsea Finn, Keerthana Gopalakrishnan, Karol Hausman, Alex Herzog, Jasmine Hsu, et al. Rt-1: Robotics transformer for real-world control at scale. arXiv preprint arXiv:2212.06817, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[9]
Encoder-decoder with atrous separable convolution for semantic image segmentation
Liang-Chieh Chen, Yukun Zhu, George Papandreou, Florian Schroff, and Hartwig Adam. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European conference on computer vision (ECCV), pages 801–818, 2018
work page 2018
-
[10]
A Survey of Sim-to-Real Methods in RL: Progress, Prospects and Challenges with Foundation Models
Longchao Da, Justin Turnau, Thirulogasankar Pranav Kutralingam, Alvaro Velasquez, Paulo Shakarian, and Hua Wei. A survey of sim-to-real methods in rl: Progress, prospects and challenges with foundation models. arXiv preprint arXiv:2502.13187, 2025
-
[11]
Deep writer AI writing assistant
Deep Writer. Deep writer AI writing assistant. https://deepwriter.com, 2025
work page 2025
-
[12]
Scaling cross-embodied learning: One policy for manipulation, navigation, locomotion and aviation
Ria Doshi, Homer Walke, Oier Mees, Sudeep Dasari, and Sergey Levine. Scaling cross-embodied learning: One policy for manipulation, navigation, locomotion and aviation. In Conference on Robot Learning, 2024
work page 2024
-
[13]
Flownav: Combining flow matching and depth priors for efficient navigation,
Samiran Gode, Abhijeet Nayak, and Wolfram Burgard. Flownav: Learning efficient navigation policies via conditional flow matching. arXiv preprint arXiv:2411.09524, 2024
-
[14]
Google DeepMind. Gemini 3 flash model card. Technical report, Google DeepMind, December 2025
work page 2025
-
[15]
Vision- and-language navigation: A survey of tasks, methods, and future directions
Jing Gu, Eliana Stefani, Qi Wu, Jesse Thomason, and Xin Wang. Vision- and-language navigation: A survey of tasks, methods, and future directions. In Smaranda Muresan, Preslav Nakov, and Aline Villavicencio, editors, Pro- ceedings of the 60th Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), pages 7606–7623, Dublin, ...
work page 2022
-
[16]
Conceptgraphs: Open-vocabulary 3d scene graphs for perception and planning
Qiao Gu, Ali Kuwajerwala, Sacha Morin, Krishna Murthy Jatavallabhula, Bipasha Sen, Aditya Agarwal, Corban Rivera, William Paul, Kirsty Ellis, Rama Chellappa, et al. Conceptgraphs: Open-vocabulary 3d scene graphs for perception and planning. In 2024 IEEE International Conference on Robotics and Automation (ICRA), pages 5021–5028. IEEE, 2024
work page 2024
-
[17]
From seeing to experiencing: Scaling navigation foundation models with reinforcement learning
Honglin He, Yukai Ma, Wayne Wu, and Bolei Zhou. From seeing to experiencing: Scaling navigation foundation models with reinforcement learning. arXiv preprint arXiv:2507.22028, 2025
-
[18]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016
work page 2016
-
[19]
Lelan: Learning a language-conditioned navigation policy from in- the-wild video
Noriaki Hirose, Catherine Glossop, Ajay Sridhar, Oier Mees, and Sergey Levine. Lelan: Learning a language-conditioned navigation policy from in- the-wild video. In Pulkit Agrawal, Oliver Kroemer, and Wolfram Burgard, editors, Proceedings of The 8th Conference on Robot Learning, volume 270 of Proceedings of Machine Learning Research, pages 666–688. PMLR, 0...
work page 2025
-
[20]
Sacson: Scalable autonomous control for social navigation
Noriaki Hirose, Dhruv Shah, Ajay Sridhar, and Sergey Levine. Sacson: Scalable autonomous control for social navigation. IEEE Robotics and Automation Letters, 9(1):49–56, 2023
work page 2023
-
[21]
CogVLM2: Visual Language Models for Image and Video Understanding
Wenyi Hong, Weihan Wang, Ming Ding, Wenmeng Yu, Qingsong Lv, Yan Wang, Yean Cheng, Shiyu Huang, Junhui Ji, Zhao Xue, et al. Cogvlm2: Visual language models for image and video understanding. arXiv preprint arXiv:2408.16500, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
Pavel Iakubovskii. Segmentation models pytorch. https://github.com/ qubvel/segmentation_models.pytorch, 2019
work page 2019
-
[23]
Rellis- 3d dataset: Data, benchmarks and analysis
Peng Jiang, Philip Osteen, Maggie Wigness, and Srikanth Saripalli. Rellis- 3d dataset: Data, benchmarks and analysis. In 2021 IEEE international conference on robotics and automation (ICRA), pages 1110–1116. IEEE, 2021
work page 2021
-
[24]
V-strong: Visual self-supervised traversability learning for off- road navigation
Sanghun Jung, JoonHo Lee, Xiangyun Meng, Byron Boots, and Alexander Lambert. V-strong: Visual self-supervised traversability learning for off- road navigation. In 2024 IEEE International Conference on Robotics and Automation (ICRA), pages 1766–1773. IEEE, 2024
work page 2024
-
[25]
Socially Compliant Navigation Dataset (SCAND), 2022
Haresh Karnan, Anirudh Nair, Xuesu Xiao, Garrett Warnell, Soeren Pirk, Alexander Toshev, Justin Hart, Joydeep Biswas, and Peter Stone. Socially Compliant Navigation Dataset (SCAND), 2022
work page 2022
-
[26]
Mapanything: Universal feed-forward metric 3d reconstruction
Nikhil Varma Keetha, Norman Müller, Johannes Schönberger, Lorenzo Porzi, Yuchen Zhang, Tobias Fischer, Arno Knapitsch, Duncan Zauss, Ethan Weber, Nelson Antunes, Jonathon Luiten, Manuel Lopez-Antequera, Samuel Rota Bulò, Christian Richardt, Deva Ramanan, Sebastian Scherer, and Peter Kontschieder. Mapanything: Universal feed-forward metric 3d reconstructio...
work page 2026
-
[27]
3d gaussian splatting for real-time radiance field rendering
Bernhard Kerbl, Georgios Kopanas, Thomas Leimkuehler, and George Drettakis. 3d gaussian splatting for real-time radiance field rendering. ACM Transactions on Graphics (TOG), 42(4):1–14, 2023
work page 2023
-
[28]
Droid: A large-scale in-the-wild robot manipulation dataset
Alexander Khazatsky, Karl Pertsch, Suraj Nair, Ashwin Balakrishna, Sudeep Dasari, Siddharth Karamcheti, Soroush Nasiriany, Mohan Srirama, Lawrence Chen, Kirsty Ellis, Peter Fagan, Joey Hejna, Masha Itkina, Marion Lepert, Yecheng Ma, Patrick Miller, Jimmy Wu, Suneel Belkhale, Shivin Dass, and Chelsea Finn. Droid: A large-scale in-the-wild robot manipulatio...
-
[29]
Robotics: Science and Systems, R:SS ; Conference date: 15-07-2024 Through 19-07-2024
work page 2024
-
[30]
Transformer- based deep imitation learning for dual-arm robot manipulation
Heecheol Kim, Yoshiyuki Ohmura, and Yasuo Kuniyoshi. Transformer- based deep imitation learning for dual-arm robot manipulation. In 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 8965–8972. IEEE, 2021
work page 2021
-
[31]
Learning semantic traversabil- ity with egocentric video and automated annotation strategy
Yunho Kim, Jeong Hyun Lee, Choongin Lee, Juhyeok Mun, Donghoon Youm, Jeongsoo Park, and Jemin Hwangbo. Learning semantic traversabil- ity with egocentric video and automated annotation strategy. IEEE Robotics and Automation Letters, 2024
work page 2024
-
[32]
A unified architecture for instance and semantic segmentation
Alexander Kirillov, Kaiming He, Ross Girshick, and Piotr Dollár. A unified architecture for instance and semantic segmentation. In Computer Vision and Pattern Recognition Conference. CVPR, 2017
work page 2017
-
[33]
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C Berg, Wan- Yen Lo, et al. Segment anything. In Proceedings of the IEEE/CVF international conference on computer vision, pages 4015–4026, 2023
work page 2023
-
[34]
Pathdreamer: A world model for indoor navigation
Jing Yu Koh, Honglak Lee, Yinfei Yang, Jason Baldridge, and Peter Anderson. Pathdreamer: A world model for indoor navigation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 14738–14748, 2021
work page 2021
-
[35]
Visual navigation in real-world indoor environments using end-to-end deep reinforcement learning
Jonáš Kulhánek, Erik Derner, and Robert Babuška. Visual navigation in real-world indoor environments using end-to-end deep reinforcement learning. IEEE Robotics and Automation Letters, 6(3):4345–4352, 2021
work page 2021
-
[36]
When humans aren’t optimal: Robots that collaborate with risk-aware humans
Minae Kwon, Erdem Biyik, Aditi Talati, Karan Bhasin, Dylan P Losey, and Dorsa Sadigh. When humans aren’t optimal: Robots that collaborate with risk-aware humans. In Proceedings of the 2020 ACM/IEEE international conference on human-robot interaction, pages 43–52, 2020
work page 2020
-
[37]
Depth Anything 3: Recovering the Visual Space from Any Views
Haotong Lin, Sili Chen, Junhao Liew, Donny Y Chen, Zhenyu Li, Guang Shi, Jiashi Feng, and Bingyi Kang. Depth anything 3: Recovering the visual space from any views. arXiv preprint arXiv:2511.10647, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[38]
Urbanverse: Scaling urban simulation by watching city-tour videos
Mingxuan Liu, Honglin He, Elisa Ricci, Wayne Wu, and Bolei Zhou. Urbanverse: Scaling urban simulation by watching city-tour videos. In The Fourteenth International Conference on Learning Representations, 2026
work page 2026
-
[39]
Grounding dino: Marrying dino with grounded pre-training for open-set object detection
Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Qing Jiang, Chunyuan Li, Jianwei Yang, Hang Su, et al. Grounding dino: Marrying dino with grounded pre-training for open-set object detection. In European Conference on Computer Vision, pages 38–55. Springer, 2024
work page 2024
-
[40]
Citywalker: Learning embodied urban navigation from web-scale videos
Xinhao Liu, Jintong Li, Yicheng Jiang, Niranjan Sujay, Zhicheng Yang, Juexiao Zhang, John Abanes, Jing Zhang, and Chen Feng. Citywalker: Learning embodied urban navigation from web-scale videos. arXiv preprint arXiv:2411.17820, 2024
-
[41]
Performance of optical flow techniques for indoor navigation with a mobile robot
Chris McCarthy and Nick Bames. Performance of optical flow techniques for indoor navigation with a mobile robot. In IEEE International Conference on Robotics and Automation, 2004. Proceedings. ICRA’04. 2004, volume 5, pages 5093–5098. IEEE, 2004
work page 2004
-
[42]
Nerf: Representing scenes as neural radiance fields for view synthesis
Ben Mildenhall, Pratul P Srinivasan, Matthew Tancik, Jonathan T Barron, Ravi Ramamoorthi, and Ren Ng. Nerf: Representing scenes as neural radiance fields for view synthesis. Communications of the ACM, 65(1):99– 106, 2021
work page 2021
-
[43]
Simple open-vocabulary object detection
Matthias Minderer, Alexey Gritsenko, Austin Stone, Maxim Neumann, Dirk Weissenborn, Alexey Dosovitskiy, Aravindh Mahendran, Anurag Arnab, Mostafa Dehghani, Zhuoran Shen, et al. Simple open-vocabulary object detection. In European conference on computer vision, pages 728–755. Springer, 2022
work page 2022
-
[44]
Duc M Nguyen, Mohammad Nazeri, Amirreza Payandeh, Aniket Datar, and Xuesu Xiao. Toward human-like social robot navigation: A large- scale, multi-modal, social human navigation dataset. In 2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 7442–7447. IEEE, 2023. 11 Akhtyamovet al.: EgoWalk: A Multimodal Dataset for Robot...
work page 2023
-
[45]
Visual navigation of mobile robot using optical flow and visual potential field
Naoya Ohnishi and Atsushi Imiya. Visual navigation of mobile robot using optical flow and visual potential field. In International Workshop on Robot Vision, pages 412–426. Springer, 2008
work page 2008
-
[46]
Visual language navigation: A survey and open challenges
Sang-Min Park and Young-Gab Kim. Visual language navigation: A survey and open challenges. Artificial Intelligence Review, 56(1):365–427, 2023
work page 2023
-
[47]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. In International conference on machine learning, pages 8748–
-
[48]
Robert Riener, Luca Rabezzana, and Yves Zimmermann. Do robots outperform humans in human-centered domains? Frontiers in Robotics and AI, 10:1223946, 2023
work page 2023
-
[49]
U-net: Convolutional networks for biomedical image segmentation
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-net: Convolutional networks for biomedical image segmentation. In International Conference on Medical image computing and computer-assisted intervention, pages 234–241. Springer, 2015
work page 2015
-
[50]
ViKiNG: Vision-Based Kilometer-Scale Navigation with Geographic Hints
Dhruv Shah and Sergey Levine. ViKiNG: Vision-Based Kilometer-Scale Navigation with Geographic Hints. In Proceedings of Robotics: Science and Systems, 2022
work page 2022
-
[51]
Gnm: A general navigation model to drive any robot
Dhruv Shah, Ajay Sridhar, Arjun Bhorkar, Noriaki Hirose, and Sergey Levine. Gnm: A general navigation model to drive any robot. In 2023 IEEE International Conference on Robotics and Automation (ICRA), pages 7226–7233. IEEE, 2023
work page 2023
-
[52]
Vint: A foundation model for visual navigation
Dhruv Shah, Ajay Sridhar, Nitish Dashora, Kyle Stachowicz, Kevin Black, Noriaki Hirose, and Sergey Levine. Vint: A foundation model for visual navigation. In Jie Tan, Marc Toussaint, and Kourosh Darvish, editors, Proceedings of The 7th Conference on Robot Learning, volume 229 of Proceedings of Machine Learning Research, pages 711–733. PMLR, 06–09 Nov 2023
work page 2023
-
[53]
Nomad: Goal masked diffusion policies for navigation and exploration
Ajay Sridhar, Dhruv Shah, Catherine Glossop, and Sergey Levine. Nomad: Goal masked diffusion policies for navigation and exploration. In 2024 IEEE International Conference on Robotics and Automation (ICRA), pages 63–70. IEEE, 2024
work page 2024
-
[54]
Efficientnet: Rethinking model scaling for convolutional neural networks
Mingxing Tan and Quoc Le. Efficientnet: Rethinking model scaling for convolutional neural networks. In International conference on machine learning, pages 6105–6114. PMLR, 2019
work page 2019
-
[55]
Annan Tang, Takuma Hiraoka, Naoki Hiraoka, Fan Shi, Kento Kawa- harazuka, Kunio Kojima, Kei Okada, and Masayuki Inaba. Humanmimic: Learning natural locomotion and transitions for humanoid robot via wasserstein adversarial imitation. In 2024 IEEE International Conference on Robotics and Automation (ICRA), pages 13107–13114. IEEE, 2024
work page 2024
-
[56]
Open x-embodiment: Robotic learning datasets and rt-x models
Quan Vuong, Sergey Levine, Homer Rich Walke, Karl Pertsch, Anikait Singh, Ria Doshi, Charles Xu, Jianlan Luo, Liam Tan, Dhruv Shah, et al. Open x-embodiment: Robotic learning datasets and rt-x models. In Towards Generalist Robots: Learning Paradigms for Scalable Skill Acquisition@ CoRL2023, 2023
work page 2023
-
[57]
Sagar M. Waghmare, Kimberly Wilber, Dave Hawkey, Xuan Yang, Matthew Wilson, Stephanie Debats, Cattalyya Nuengsigkapian, Astuti Sharma, Lars Pandikow, Huisheng Wang, Hartwig Adam, and Mikhail Sirotenko. Sanpo: A scene understanding, accessibility and human navigation dataset. In 2025 IEEE/CVF Winter Conference on Applications of Computer Vision (W ACV), pa...
work page 2025
-
[58]
Bridgedata v2: A dataset for robot learning at scale
Homer Rich Walke, Kevin Black, Tony Z Zhao, Quan Vuong, Chongyi Zheng, Philippe Hansen-Estruch, Andre Wang He, Vivek Myers, Moo Jin Kim, Max Du, et al. Bridgedata v2: A dataset for robot learning at scale. In Conference on Robot Learning, pages 1723–1736. PMLR, 2023
work page 2023
-
[59]
Vggt: Visual geometry grounded trans- former
Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rupprecht, and David Novotny. Vggt: Visual geometry grounded trans- former. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 5294–5306, 2025
work page 2025
-
[60]
Difix3d+: Improving 3d reconstructions with single-step diffusion models
Jay Zhangjie Wu, Yuxuan Zhang, Haithem Turki, Xuanchi Ren, Jun Gao, Mike Zheng Shou, Sanja Fidler, Zan Gojcic, and Huan Ling. Difix3d+: Improving 3d reconstructions with single-step diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 26024–26035, 2025
work page 2025
-
[61]
Vision- language navigation: a survey and taxonomy
Wansen Wu, Tao Chang, Xinmeng Li, Quanjun Yin, and Yue Hu. Vision- language navigation: a survey and taxonomy. Neural Computing and Applications, 36(7):3291–3316, 2024
work page 2024
-
[62]
Segformer: Simple and efficient design for semantic segmentation with transformers
Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M Alvarez, and Ping Luo. Segformer: Simple and efficient design for semantic segmentation with transformers. Advances in neural information processing systems, 34:12077–12090, 2021
work page 2021
-
[63]
Deep imitation learning for bimanual robotic manipulation
Fan Xie, Alexander Chowdhury, M De Paolis Kaluza, Linfeng Zhao, Lawson Wong, and Rose Yu. Deep imitation learning for bimanual robotic manipulation. Advances in neural information processing systems, 33:2327– 2337, 2020
work page 2020
-
[64]
Vid2sim: Realistic and interactive simulation from video for urban navi- gation
Ziyang Xie, Zhizheng Liu, Zhenghao Peng, Wayne Wu, and Bolei Zhou. Vid2sim: Realistic and interactive simulation from video for urban navi- gation. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 1581–1591, 2025
work page 2025
-
[65]
Zewen Xu, Yijia He, Hao Wei, Bo Xu, BinJian Xie, and Yihong Wu. An accurate and real-time relative pose estimation from triple point-line images by decoupling rotation and translation. arXiv preprint arXiv:2403.11639, 2024
-
[66]
Generalized predictive model for autonomous driving
Jiazhi Yang, Shenyuan Gao, Yihang Qiu, Li Chen, Tianyu Li, Bo Dai, Kashyap Chitta, Penghao Wu, Jia Zeng, Ping Luo, et al. Generalized predictive model for autonomous driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14662– 14672, 2024
work page 2024
-
[67]
Autonomous visual navigation for mobile robots: A systematic literature review
Yuri DV Yasuda, Luiz Eduardo G Martins, and Fabio AM Cappabianco. Autonomous visual navigation for mobile robots: A systematic literature review. ACM Computing Surveys (CSUR), 53(1):1–34, 2020
work page 2020
-
[68]
A survey on visual navigation for artificial agents with deep reinforcement learning
Fanyu Zeng, Chen Wang, and Shuzhi Sam Ge. A survey on visual navigation for artificial agents with deep reinforcement learning. IEEE Access, 8:135426–135442, 2020
work page 2020
-
[69]
A survey of visual navigation: From geometry to embodied ai
Tianyao Zhang, Xiaoguang Hu, Jin Xiao, and Guofeng Zhang. A survey of visual navigation: From geometry to embodied ai. Engineering Applications of Artificial Intelligence, 114:105036, 2022
work page 2022
-
[70]
Recognize anything: A strong image tagging model
Youcai Zhang, Xinyu Huang, Jinyu Ma, Zhaoyang Li, Zhaochuan Luo, Yanchun Xie, Yuzhuo Qin, Tong Luo, Yaqian Li, Shilong Liu, et al. Recognize anything: A strong image tagging model. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1724–1732, 2024
work page 2024
-
[71]
Unet++: A nested u-net architecture for medical image segmentation
Zongwei Zhou, Md Mahfuzur Rahman Siddiquee, Nima Tajbakhsh, and Jianming Liang. Unet++: A nested u-net architecture for medical image segmentation. In International workshop on deep learning in medical image analysis, pages 3–11. Springer, 2018
work page 2018
-
[72]
Vr-robo: A real-to-sim-to-real framework for visual robot navigation and locomotion
Shaoting Zhu, Linzhan Mou, Derun Li, Baijun Ye, Runhan Huang, and Hang Zhao. Vr-robo: A real-to-sim-to-real framework for visual robot navigation and locomotion. IEEE Robotics and Automation Letters, 10(8):7875–7882, 2025. TIMUR AKHTY AMOVreceived the B.Sc. degree from Bauman Moscow State Technical University and the M.Sc. degree from the Skolkovo Institu...
work page 2025
-
[73]
His early research focused on hand prosthesis development and EEG-based control systems for prosthetic devices. He is currently a researcher at the Robotics Center, Moscow, Russia, where he works on the development and application of artificial intelligence methods for advanced robotic navigation and autonomous systems. His research interests include deep...
work page 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.