Ivy-Fake: A Unified Explainable Framework and Benchmark for Image and Video AIGC Detection
Pith reviewed 2026-05-19 11:20 UTC · model grok-4.3
The pith
Ivy-Fake benchmark and Ivy-xDetector add explainable reasoning to AIGC detection while raising benchmark accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
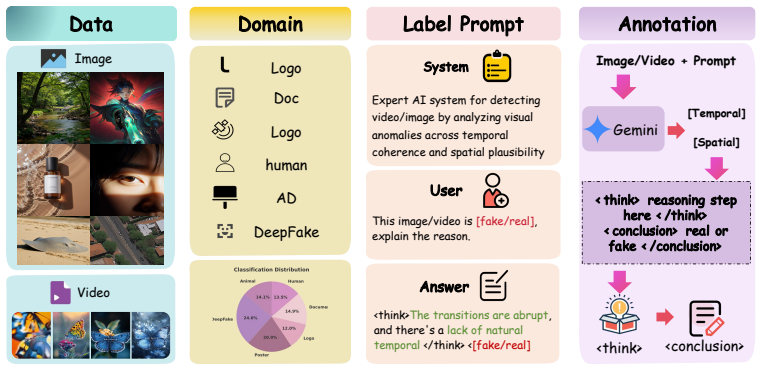
The paper presents Ivy-Fake as the first large-scale multimodal benchmark for explainable AIGC detection, containing over 106K richly annotated training samples and 5,000 manually verified evaluation examples sourced from multiple generative models. It further proposes Ivy-xDetector, a reinforcement learning model based on Group Relative Policy Optimization capable of producing explainable reasoning chains, which demonstrates robust performance and improves results on GenImage from 86.88% to 96.32%, surpassing prior state-of-the-art methods.
What carries the argument
Ivy-xDetector, the reinforcement learning model using Group Relative Policy Optimization (GRPO) to generate explainable reasoning chains for forgery detection in the Ivy-Fake framework.
If this is right
- Detectors gain the ability to output multidimensional explanations rather than simple binary classifications.
- Unified handling of both image and video AIGC content becomes possible within one framework.
- Performance gains appear across multiple synthetic content detection benchmarks beyond the reported GenImage improvement.
Where Pith is reading between the lines
- Similar annotation pipelines could be adapted to improve explainability in related areas such as deepfake video analysis or misinformation detection.
- The manually verified 5,000 examples might become a standard test set for evaluating the quality of model-generated explanations.
- If the reasoning chains prove consistent with human analysis, this approach could reduce reliance on purely statistical detectors in high-stakes moderation decisions.
Load-bearing premise
The carefully designed pipeline produces diverse, high-quality, multidimensional annotations that accurately capture explainable forgery features, and the 5,000 manually verified examples are representative without annotation errors.
What would settle it
Testing Ivy-xDetector on a fresh collection of images and videos generated by previously unseen AIGC models and verifying whether the accuracy remains near 96 percent while the reasoning steps match independent human judgments of the forgery clues.
Figures










read the original abstract
The rapid development of Artificial Intelligence Generated Content (AIGC) techniques has enabled the creation of high-quality synthetic content, but it also raises significant security concerns. Current detection methods face two major limitations: (1) the lack of multidimensional explainable datasets for generated images and videos. Existing open-source datasets (e.g., WildFake, GenVideo) rely on oversimplified binary annotations, which restrict the explainability and trustworthiness of trained detectors. (2) Prior MLLM-based forgery detectors (e.g., FakeVLM) exhibit insufficiently fine-grained interpretability in their step-by-step reasoning, which hinders reliable localization and explanation. To address these challenges, we introduce Ivy-Fake, the first large-scale multimodal benchmark for explainable AIGC detection. It consists of over 106K richly annotated training samples (images and videos) and 5,000 manually verified evaluation examples, sourced from multiple generative models and real world datasets through a carefully designed pipeline to ensure both diversity and quality. Furthermore, we propose Ivy-xDetector, a reinforcement learning model based on Group Relative Policy Optimization (GRPO), capable of producing explainable reasoning chains and achieving robust performance across multiple synthetic content detection benchmarks. Extensive experiments demonstrate the superiority of our dataset and confirm the effectiveness of our approach. Notably, our method improves performance on GenImage from 86.88% to 96.32%, surpassing prior state-of-the-art methods by a clear margin.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Ivy-Fake, a large-scale multimodal benchmark for explainable AIGC detection comprising over 106K richly annotated training samples (images and videos) and 5,000 manually verified evaluation examples sourced via a designed pipeline from multiple generative models. It further proposes Ivy-xDetector, a Group Relative Policy Optimization (GRPO) reinforcement learning model that generates explainable reasoning chains and reports robust detection performance, including an improvement on the GenImage benchmark from 86.88% to 96.32% that surpasses prior state-of-the-art methods.
Significance. If the reported gains prove robust, the work supplies a valuable new resource for training interpretable AIGC detectors and demonstrates the utility of RL-based fine-grained reasoning for forgery localization. The scale of the annotated dataset and the explicit focus on multidimensional explainability address documented limitations in existing binary-labeled corpora and MLLM detectors, potentially supporting more trustworthy deployment in content verification pipelines.
major comments (2)
- [§4.2 and Table 2] §4.2 and Table 2: the 9.44 percentage-point lift on GenImage is presented as evidence of superiority, yet the manuscript does not report standard deviations across multiple random seeds or statistical significance tests; without these, it is unclear whether the margin over prior SOTA is stable or sensitive to evaluation splits.
- [§3.1] §3.1: the pipeline for producing multidimensional annotations is described at a high level, but no quantitative analysis (e.g., inter-annotator agreement or error rate on the 5,000 verified examples) is supplied; this weakens the claim that the annotations accurately capture explainable forgery features and are free of systematic bias.
minor comments (2)
- [§5.1] §5.1: the GRPO reward formulation is given, but the relative weighting of the explainability and detection terms is not ablated; a short sensitivity study would clarify whether the reported reasoning quality is robust to these hyperparameters.
- [Figure 5] Figure 5: the qualitative reasoning-chain examples are helpful, yet the font size and contrast in the video frames make some forgery-localization arrows difficult to read; higher-resolution insets would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and positive overall assessment of our manuscript. We address each major comment in detail below and will revise the paper to incorporate additional analyses that strengthen the presentation of results and dataset quality.
read point-by-point responses
-
Referee: [§4.2 and Table 2] §4.2 and Table 2: the 9.44 percentage-point lift on GenImage is presented as evidence of superiority, yet the manuscript does not report standard deviations across multiple random seeds or statistical significance tests; without these, it is unclear whether the margin over prior SOTA is stable or sensitive to evaluation splits.
Authors: We agree that reporting variability and statistical significance would further substantiate the robustness of the reported gains. In the revised manuscript we will rerun the GenImage evaluation using five independent random seeds, reporting mean accuracy together with standard deviation. We will also add a paired statistical significance test (e.g., Wilcoxon signed-rank test) against the prior state-of-the-art method to confirm that the 9.44-point improvement is statistically significant. These results and the corresponding discussion will be inserted into Section 4.2 and updated in Table 2. revision: yes
-
Referee: [§3.1] §3.1: the pipeline for producing multidimensional annotations is described at a high level, but no quantitative analysis (e.g., inter-annotator agreement or error rate on the 5,000 verified examples) is supplied; this weakens the claim that the annotations accurately capture explainable forgery features and are free of systematic bias.
Authors: We concur that quantitative validation of annotation reliability is essential. For the 5,000 manually verified evaluation examples we will compute and report inter-annotator agreement using Fleiss’ kappa across the multiple annotators involved in the verification stage. We will additionally include an error-rate estimate derived from the verification process and any resolved discrepancies. These metrics and a brief discussion of their implications will be added to Section 3.1 of the revised manuscript. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper introduces the Ivy-Fake dataset and Ivy-xDetector model, with the central empirical claim being an accuracy improvement on the external GenImage benchmark (86.88% to 96.32%) plus other standard benchmarks. No equations, fitted parameters, or self-citations reduce this performance result to quantities defined or fitted inside the same training data by construction. The derivation relies on external evaluation sets, manually verified examples, and comparisons to prior methods, remaining self-contained.
Axiom & Free-Parameter Ledger
free parameters (1)
- GRPO training hyperparameters
axioms (1)
- domain assumption Rich multidimensional annotations in the new dataset correctly capture forgery cues that binary labels miss.
Forward citations
Cited by 5 Pith papers
-
Venus-DeFakerOne: Unified Fake Image Detection & Localization
DeFakerOne integrates InternVL2 and SAM2 into a single model that achieves state-of-the-art results on 39 detection and 9 localization benchmarks for unified fake image detection and localization.
-
Detecting AI-Generated Videos with Spiking Neural Networks
MAST with spiking neural networks achieves 93.14% mean accuracy detecting AI-generated videos from 10 unseen generators by exploiting smoother pixel residuals and compact semantic trajectories.
-
Fake-HR1: Rethinking Reasoning of Vision Language Model for Synthetic Image Detection
Fake-HR1 is a hybrid-reasoning VLM that adaptively selects reasoning modes for synthetic image detection via two-stage HFT and HGRPO training, improving both accuracy and efficiency over standard LLMs.
-
Skyra: AI-Generated Video Detection via Grounded Artifact Reasoning
Skyra is an MLLM that detects AI-generated videos by identifying and reasoning over grounded visual artifacts, supported by a new annotated dataset and benchmark.
-
TOBench: A Task-Oriented Omni-Modal Benchmark for Real-World Tool-Using Agents
MM-ToolBench introduces 100 closed-loop multimodal tasks across two domains with 27 MCP servers and 324 tools, where agents must execute, inspect artifacts, and revise before final output.
Reference graph
Works this paper leans on
-
[1]
460–470. Bai Shuai, Chen Keqin, Liu Xuejing, Wang Jialin, Ge Wenbin, Song Sibo, Dang Kai, Wang Peng, Wang Shijie, Tang Jun, others. Qwen2.5-VL Technical Report // arXiv:2502.13923. 2025. Betker James, Goh Gabriel, Jing Li, Brooks Tim, Wang Jianfeng, Li Linjie, Ouyang Long, Zhuang Juntang, Lee Joyce, Guo Yufei, others . Improving image generation with bett...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
1. 8. Cao Bin, Yuan Jianhao, Liu Yexin, Li Jian, Sun Shuyang, Liu Jing, Zhao Bo . Synartifact: Classi- fying and alleviating artifacts in synthetic images via vision-language model // arXiv preprint arXiv:2402.18068. 2024. Chen Haoxing, Hong Yan, Huang Zizheng, Xu Zhuoer, Gu Zhangxuan, Li Yaohui, Lan Jun, Zhu Huijia, Zhang Jianfu, Wang Weiqiang, Li Huaxio...
-
[3]
Gemini: A Family of Highly Capable Multimodal Models
115, 3. 211–252. 11 Saharia Chitwan, Chan William, Saxena Saurabh, Li Lala, Whang Jay, Denton Emily L, Ghasemipour Kamyar, Gontijo Lopes Raphael, Karagol Ayan Burcu, Salimans Tim, others. Photorealistic text- to-image diffusion models with deep language understanding // Advances in neural information processing systems. 2022. 35. 36479–36494. Tan Chuangch...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[4]
Spatial Analysis - Analyze static features (e.g., lighting, text, objects)
-
[5]
- real: Contains verifiable capture device signatures and natural physical imperfections
Conclusion: Only real or fake. - real: Contains verifiable capture device signatures and natural physical imperfections. - fake: Exhibits synthetic fingerprints including but not limited to over-regularized textures and non-physical light interactions. The assistant first thinks about the reasoning step in the mind and then provides the user with the reas...
-
[6]
Temporal Analysis - Track dynamic features across frames (e.g., shadows, expressions)
-
[7]
Spatial Analysis - Analyze static features per frame (e.g., lighting, text, objects)
-
[8]
- real: Contains verifiable capture device signatures and natural physical imperfections
Conclusion: Only real or fake. - real: Contains verifiable capture device signatures and natural physical imperfections. - fake: Exhibits synthetic fingerprints including but not limited to over-regularized textures and non-physical light interactions. The assistant first thinks about the reasoning step in the mind and then provides the user with the reas...
-
[9]
- Incomplete or partially aligned answers should receive lower scores
Completeness - Does the ModelOutput address all aspects covered in the GroundTruth? - More complete responses should include all relevant information, especially key ¨golden clues¨. - Incomplete or partially aligned answers should receive lower scores
-
[10]
- Penalize if irrelevant aspects are introduced or relevant ones are missing
Relevance - Does the ModelOutput discuss the same detection dimensions as in the GroundTruth? - Temporal features include: - Luminance discrepancy - Duplicated components - Awkward facial expressions - Motion inconsistency - Spatial features include: - Abnormal texture - Distorted or omitted components - Chromatic irregularity - Impractical luminosity - L...
-
[11]
- Penalize vague or generic responses that lack specific observations
Level of Detail - Does the ModelOutput describe fine-grained visual cues in each dimension? - High scores require specific subcomponent elaboration, not just general terms. - Penalize vague or generic responses that lack specific observations
-
[12]
- Penalize if the conclusion contradicts the reasoning or lacks support
Explanation - Is the reasoning in <think> logically consistent with the <conclusion>? - The explanation should provide clear, causally-linked justifications. - Penalize if the conclusion contradicts the reasoning or lacks support. Figure 9: GPT Assisted Evaluation Prompt 5 Figure 10: Image example 1 where Ivy-xDetector successfully detects subtle spatial ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.