R3D2: Realistic 3D Asset Insertion via Diffusion for Autonomous Driving Simulation
Pith reviewed 2026-05-19 10:18 UTC · model grok-4.3
The pith
R3D2 uses a one-step diffusion model to insert complete 3D assets into driving scenes while generating matching shadows and lighting.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
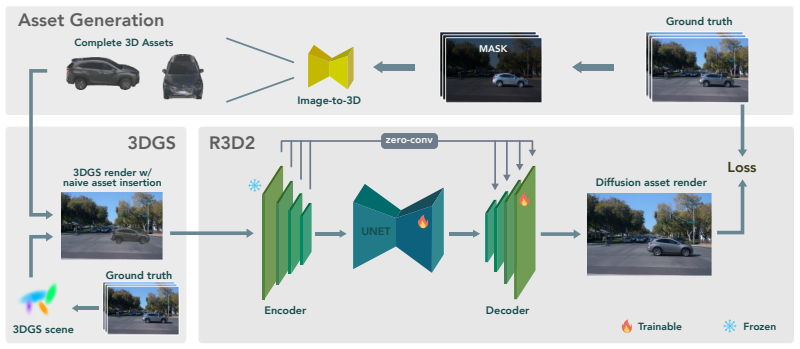
R3D2 is a lightweight one-step diffusion model trained on synthetic placements of 3DGS-generated assets into neural rendering environments; once trained it generates the shadows, lighting, and other rendering effects required to insert complete reusable 3D assets into existing driving scenes in real time.
What carries the argument
R3D2, a one-step diffusion model that predicts the additional rendering effects needed to blend inserted 3D assets into a scene.
If this is right
- Enables text-to-3D asset creation followed by realistic insertion into any reconstructed scene.
- Supports moving the same 3D object from one driving dataset or scene to another while preserving appearance consistency.
- Increases the number of controllable safety-critical test scenarios that can be generated from a fixed set of base scenes.
- Reduces reliance on per-scene manual adjustment of lighting when building simulation environments for autonomous driving validation.
Where Pith is reading between the lines
- The same insertion technique could be applied to create rare-event test cases by compositing objects recorded in separate real drives.
- Extending the model to handle object motion across video frames would allow simulation of dynamic interactions such as overtaking or merging.
- Releasing the trained model and dataset may let other groups adapt the approach to non-driving domains like indoor robotics or urban planning.
Load-bearing premise
The lighting and shadow patterns learned from synthetically placed 3D assets in neural environments match the patterns that appear when the same assets are inserted into real captured driving scenes.
What would settle it
Insert the same 3D assets into a set of real-world driving images and measure whether the generated shadows and illumination from R3D2 match the actual captured shadows and lighting; large mismatches would show the model has not learned the real distribution.
Figures










read the original abstract
Validating autonomous driving (AD) systems requires diverse and safety-critical testing, making photorealistic virtual environments essential. Traditional simulation platforms, while controllable, are resource-intensive to scale and often suffer from a domain gap with real-world data. In contrast, neural reconstruction methods like 3D Gaussian Splatting (3DGS) offer a scalable solution for creating photorealistic digital twins of real-world driving scenes. However, they struggle with dynamic object manipulation and reusability as their per-scene optimization-based methodology tends to result in incomplete object models with integrated illumination effects. This paper introduces R3D2, a lightweight, one-step diffusion model designed to overcome these limitations and enable realistic insertion of complete 3D assets into existing scenes by generating plausible rendering effects-such as shadows and consistent lighting-in real time. This is achieved by training R3D2 on a novel dataset: 3DGS object assets are generated from in-the-wild AD data using an image-conditioned 3D generative model, and then synthetically placed into neural rendering-based virtual environments, allowing R3D2 to learn realistic integration. Quantitative and qualitative evaluations demonstrate that R3D2 significantly enhances the realism of inserted assets, enabling use-cases like text-to-3D asset insertion and cross-scene/dataset object transfer, allowing for true scalability in AD validation. To promote further research in scalable and realistic AD simulation, we release our code, see https://research.zenseact.com/publications/R3D2/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces R3D2, a lightweight one-step diffusion model for inserting complete 3D assets into existing neural-reconstructed driving scenes while generating plausible shadows, lighting, and other rendering effects in real time. Assets are created via image-conditioned 3D generative models from in-the-wild AD data, then placed synthetically into neural rendering environments to form the training set; the model is evaluated quantitatively and qualitatively on realism improvements and demonstrated on applications including text-to-3D insertion and cross-scene transfer. Code is released.
Significance. If the central claims hold, R3D2 would offer a practical route to scalable, controllable, and photorealistic AD simulation by overcoming the static-object limitation of 3DGS reconstructions. The explicit code release is a clear strength that supports reproducibility and community follow-up on synthetic-to-real generalization.
major comments (2)
- [Abstract] Abstract: the statement that 'Quantitative and qualitative evaluations demonstrate that R3D2 significantly enhances the realism of inserted assets' is not supported by any named metrics (FID, LPIPS, user-study scores, etc.), baseline methods, or ablation tables. Without these details it is impossible to judge whether the reported gains are robust or merely reflect the synthetic training distribution.
- [Dataset construction and §4] Dataset construction and §4 (Experiments): the training data are generated entirely inside a closed synthetic loop (3DGS assets placed into neural rendering environments). No quantitative analysis or held-out test on real captured driving scenes with ground-truth inserted objects is described, so the domain gap in illumination, inter-reflections, and sensor noise remains unmeasured. This assumption is load-bearing for the claim that R3D2 produces realistic insertions usable for downstream AD validation.
minor comments (1)
- [Abstract / Conclusion] The link to the released code is given but the manuscript does not state whether the synthetic dataset generation pipeline and evaluation scripts are included; adding this clarification would strengthen reproducibility.
Simulated Author's Rebuttal
We thank the referee for their thorough review and constructive feedback on our work. We have addressed each of the major comments below and outline the revisions we plan to make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the statement that 'Quantitative and qualitative evaluations demonstrate that R3D2 significantly enhances the realism of inserted assets' is not supported by any named metrics (FID, LPIPS, user-study scores, etc.), baseline methods, or ablation tables. Without these details it is impossible to judge whether the reported gains are robust or merely reflect the synthetic training distribution.
Authors: We appreciate this observation. The quantitative metrics, including FID and LPIPS scores, along with comparisons to baseline methods and ablation studies, are detailed in Section 4 (Experiments) of the manuscript. To improve clarity and allow immediate assessment of our results, we will revise the abstract to specify these metrics and baselines. This change will be incorporated in the revised version. revision: yes
-
Referee: [Dataset construction and §4] Dataset construction and §4 (Experiments): the training data are generated entirely inside a closed synthetic loop (3DGS assets placed into neural rendering environments). No quantitative analysis or held-out test on real captured driving scenes with ground-truth inserted objects is described, so the domain gap in illumination, inter-reflections, and sensor noise remains unmeasured. This assumption is load-bearing for the claim that R3D2 produces realistic insertions usable for downstream AD validation.
Authors: We agree that the training data is constructed synthetically, as this enables the creation of a large-scale dataset with controlled placements and ground-truth rendering effects, which would be impractical to obtain from real-world captures. In the experiments, we evaluate on held-out synthetic test sets quantitatively and provide qualitative results on real scenes to show the model's ability to generalize. We recognize the importance of quantifying the domain gap and will add a new subsection in the discussion or limitations to analyze potential gaps in illumination and sensor characteristics, along with suggestions for future real-world validation studies. However, performing quantitative tests with ground-truth insertions in real scenes is beyond the current scope due to the lack of such paired real data. revision: partial
Circularity Check
No significant circularity; derivation is self-contained via external synthetic data pipeline
full rationale
The paper describes training a one-step diffusion model on a dataset constructed by generating 3DGS assets via an image-conditioned generative model and inserting them into neural rendering environments. This pipeline relies on external components (3DGS, image-conditioned models, neural renderers) rather than defining the target realism metric in terms of the model's own outputs. No equations, fitted parameters renamed as predictions, or self-citation chains are presented that reduce the central claim (plausible shadow/lighting generation) to the training inputs by construction. The method is evaluated for enhancements in realism and use-cases like cross-scene transfer, with the synthetic data serving as a proxy rather than a closed definitional loop. This is a standard training-on-synthetic setup without load-bearing self-referential reductions.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Image-conditioned 3D generative models can produce complete object assets from in-the-wild driving images without baked-in scene illumination.
- domain assumption Neural rendering environments provide a sufficiently accurate base scene for learning insertion effects.
Forward citations
Cited by 3 Pith papers
-
ChopGrad: Pixel-Wise Losses for Latent Video Diffusion via Truncated Backpropagation
ChopGrad truncates backpropagation to local frame windows in video diffusion models, reducing memory from linear in frame count to constant while enabling pixel-wise loss fine-tuning.
-
CityRAG: Stepping Into a City via Spatially-Grounded Video Generation
CityRAG generates minutes-long 3D-consistent videos of real-world cities by grounding outputs in geo-registered data and using temporally unaligned training to disentangle fixed scenes from transient elements like weather.
-
Unposed-to-3D: Learning Simulation-Ready Vehicles from Real-World Images
Unposed-to-3D learns simulation-ready 3D vehicle models from unposed real images by predicting camera parameters for photometric self-supervision, then adding scale prediction and harmonization.
Reference graph
Works this paper leans on
-
[1]
Zenseact open dataset: A large-scale and diverse multimodal dataset for autonomous driving
Mina Alibeigi, William Ljungbergh, Adam Tonderski, Georg Hess, Adam Lilja, Carl Lindström, Daria Motorniuk, Junsheng Fu, Jenny Widahl, and Christoffer Petersson. Zenseact open dataset: A large-scale and diverse multimodal dataset for autonomous driving. In ICCV, 2023
work page 2023
-
[2]
Tiny autoencoder for stable diffusion
Ollin Boer Bohan. Tiny autoencoder for stable diffusion. https://github.com/madebyollin/taesd, 2023
work page 2023
-
[3]
Tim Brooks, Aleksander Holynski, and Alexei A. Efros. Instructpix2pix: Learning to follow image editing instructions. In CVPR, June 2023
work page 2023
-
[4]
nuscenes: A multimodal dataset for autonomous driving
Holger Caesar, Varun Bankiti, Alex H Lang, Sourabh V ora, Venice Erin Liong, Qiang Xu, Anush Krishnan, Yu Pan, Giancarlo Baldan, and Oscar Beijbom. nuscenes: A multimodal dataset for autonomous driving. In CVPR, 2020
work page 2020
-
[5]
Junsong Chen, Shuchen Xue, Yuyang Zhao, Jincheng Yu, Sayak Paul, Junyu Chen, Han Cai, Enze Xie, and Song Han. Sana-sprint: One-step diffusion with continuous-time consistency distillation. arXiv preprint arXiv:2503.09641, 2025
-
[6]
Ankit Dhiman, Manan Shah, Rishubh Parihar, Yash Bhalgat, Lokesh R. Boregowda, and R. Venkatesh Babu. Reflecting reality: Enabling diffusion models to produce faithful mirror reflections. ArXiv, 2024
work page 2024
-
[7]
Carla: An open urban driving simulator
Alexey Dosovitskiy, German Ros, Felipe Codevilla, Antonio Lopez, and Vladlen Koltun. Carla: An open urban driving simulator. In CoRL, 2017
work page 2017
-
[8]
Scaling rectified flow transformers for high-resolution image synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Müller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, Dustin Podell, Tim Dockhorn, Zion English, and Robin Rombach. Scaling rectified flow transformers for high-resolution image synthesis. In ICML, 2024
work page 2024
-
[9]
Splatad: Real-time lidar and camera rendering with 3d gaussian splatting for autonomous driving
Georg Hess, Carl Lindström, Maryam Fatemi, Christoffer Petersson, and Lennart Svensson. Splatad: Real-time lidar and camera rendering with 3d gaussian splatting for autonomous driving. In CVPR, 2025
work page 2025
-
[10]
Gans trained by a two time-scale update rule converge to a local nash equilibrium
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium. In NeurIPS, 2017
work page 2017
-
[11]
Denoising diffusion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. Advances in neural information processing systems, 2020
work page 2020
-
[12]
Lora: Low-rank adaptation of large language models
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models. ICLR, 2022
work page 2022
-
[13]
Smartedit: Exploring complex instruction-based image editing with multimodal large language models
Yuzhou Huang, Liangbin Xie, Xintao Wang, Ziyang Yuan, Xiaodong Cun, Yixiao Ge, Jiantao Zhou, Chao Dong, Rui Huang, Ruimao Zhang, et al. Smartedit: Exploring complex instruction-based image editing with multimodal large language models. In CVPR, 2024
work page 2024
-
[14]
3d gaussian splatting for real-time radiance field rendering
Bernhard Kerbl, Georgios Kopanas, Thomas Leimkühler, and George Drettakis. 3d gaussian splatting for real-time radiance field rendering. TOG, 2023
work page 2023
-
[15]
Photorealistic object insertion with diffusion-guided inverse rendering
Ruofan Liang, Zan Gojcic, Merlin Nimier-David, David Acuna, Nandita Vijaykumar, Sanja Fidler, and Zian Wang. Photorealistic object insertion with diffusion-guided inverse rendering. In ECCV, 2024. 10
work page 2024
-
[16]
Are nerfs ready for autonomous driving? towards closing the real-to-simulation gap
Carl Lindström, Georg Hess, Adam Lilja, Maryam Fatemi, Lars Hammarstrand, Christoffer Petersson, and Lennart Svensson. Are nerfs ready for autonomous driving? towards closing the real-to-simulation gap. In CVPRW, 2024
work page 2024
-
[17]
3dgs-enhancer: Enhancing unbounded 3d gaussian splatting with view-consistent 2d diffusion priors
Xi Liu, Chaoyi Zhou, and Siyu Huang. 3dgs-enhancer: Enhancing unbounded 3d gaussian splatting with view-consistent 2d diffusion priors. In NeurIPS, 2024
work page 2024
-
[18]
Neuroncap: Photorealistic closed-loop safety testing for autonomous driving
William Ljungbergh, Adam Tonderski, Joakim Johnander, Holger Caesar, Kalle Åström, Michael Felsberg, and Christoffer Petersson. Neuroncap: Photorealistic closed-loop safety testing for autonomous driving. In ECCV, 2025
work page 2025
-
[19]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[20]
SDEdit: Guided image synthesis and editing with stochastic differential equations
Chenlin Meng, Yutong He, Yang Song, Jiaming Song, Jiajun Wu, Jun-Yan Zhu, and Stefano Ermon. SDEdit: Guided image synthesis and editing with stochastic differential equations. In ICLR, 2022
work page 2022
-
[21]
Srinivasan, Matthew Tancik, Jonathan T
Ben Mildenhall, Pratul P. Srinivasan, Matthew Tancik, Jonathan T. Barron, Ravi Ramamoorthi, and Ren Ng. Nerf: Representing scenes as neural radiance fields for view synthesis. In ECCV, 2020
work page 2020
-
[22]
Image generated using chatgpt with dalle model
OpenAI. Image generated using chatgpt with dalle model. https://chat.openai.com, 2025. Accessed May 15, 2025
work page 2025
-
[23]
pix2gestalt: Amodal segmentation by synthesizing wholes
Ege Ozguroglu, Ruoshi Liu, Dídac Sur´s, Dian Chen, Achal Dave, Pavel Tokmakov, and Carl V ondrick. pix2gestalt: Amodal segmentation by synthesizing wholes. CVPR, 2024
work page 2024
-
[24]
One-step image translation with text-to-image models,
Gaurav Parmar, Taesung Park, Srinivasa Narasimhan, and Jun-Yan Zhu. One-step image translation with text-to-image models. arXiv preprint arXiv:2403.12036, 2024
-
[25]
Physically based rendering: From theory to implementa- tion
Matt Pharr, Wenzel Jakob, and Greg Humphreys. Physically based rendering: From theory to implementa- tion. MIT Press, 2023
work page 2023
-
[26]
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas Müller, Joe Penna, and Robin Rombach. Sdxl: Improving latent diffusion models for high-resolution image synthesis. arXiv preprint arXiv:2307.01952, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[27]
Hierarchical Text-Conditional Image Generation with CLIP Latents
Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen. Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:2204.06125, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[28]
Film: Frame interpolation for large motion
Fitsum Reda, Janne Kontkanen, Eric Tabellion, Deqing Sun, Caroline Pantofaru, and Brian Curless. Film: Frame interpolation for large motion. In ECCV, 2022
work page 2022
-
[29]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models. In CVPR, 2022
work page 2022
-
[30]
Dream- booth: Fine tuning text-to-image diffusion models for subject-driven generation
Nataniel Ruiz, Yuanzhen Li, Varun Jampani, Yael Pritch, Michael Rubinstein, and Kfir Aberman. Dream- booth: Fine tuning text-to-image diffusion models for subject-driven generation. In CVPR, 2023
work page 2023
-
[31]
Palette: Image-to-image diffusion models
Chitwan Saharia, William Chan, Huiwen Chang, Chris Lee, Jonathan Ho, Tim Salimans, David Fleet, and Mohammad Norouzi. Palette: Image-to-image diffusion models. In SIGGRAPH, 2022
work page 2022
-
[32]
Sara Mahdavi, Raphael Gontijo-Lopes, Tim Salimans, Jonathan Ho, David J Fleet, and Mohammad Norouzi
Chitwan Saharia, William Chan, Saurabh Saxena, Lala Lit, Jay Whang, Emily Denton, Seyed Kamyar Seyed Ghasemipour, Burcu Karagol Ayan, S. Sara Mahdavi, Raphael Gontijo-Lopes, Tim Salimans, Jonathan Ho, David J Fleet, and Mohammad Norouzi. Photorealistic text-to-image diffusion models with deep language understanding. In NeurIPS, 2022
work page 2022
-
[33]
Fast high-resolution image synthesis with latent adversarial diffusion distillation
Axel Sauer, Frederic Boesel, Tim Dockhorn, Andreas Blattmann, Patrick Esser, and Robin Rombach. Fast high-resolution image synthesis with latent adversarial diffusion distillation. In SIGGRAPH, 2024
work page 2024
-
[34]
Airsim: High-fidelity visual and physical simulation for autonomous vehicles
Shital Shah, Debadeepta Dey, Chris Lovett, and Ashish Kapoor. Airsim: High-fidelity visual and physical simulation for autonomous vehicles. In Field and Service Robotics: Results of the 11th International Conference, 2018
work page 2018
-
[35]
Gina-3d: Learning to generate implicit neural assets in the wild
Bokui Shen, Xinchen Yan, Charles R Qi, Mahyar Najibi, Boyang Deng, Leonidas Guibas, Yin Zhou, and Dragomir Anguelov. Gina-3d: Learning to generate implicit neural assets in the wild. In CVPR, 2023
work page 2023
-
[36]
Emu edit: Precise image editing via recognition and generation tasks
Shelly Sheynin, Adam Polyak, Uriel Singer, Yuval Kirstain, Amit Zohar, Oron Ashual, Devi Parikh, and Yaniv Taigman. Emu edit: Precise image editing via recognition and generation tasks. In CVPR, 2024. 11
work page 2024
-
[37]
Scalability in perception for autonomous driving: Waymo open dataset
Pei Sun, Henrik Kretzschmar, Xerxes Dotiwalla, Aurelien Chouard, Vijaysai Patnaik, Paul Tsui, James Guo, Yin Zhou, Yuning Chai, Benjamin Caine, Vijay Vasudevan, Wei Han, Jiquan Ngiam, Hang Zhao, Aleksei Timofeev, Scott Ettinger, Maxim Krivokon, Amy Gao, Aditya Joshi, Yu Zhang, Jonathon Shlens, Zhifeng Chen, and Dragomir Anguelov. Scalability in perception...
work page 2020
-
[38]
Neurad: Neural rendering for autonomous driving
Adam Tonderski, Carl Lindström, Georg Hess, William Ljungbergh, Lennart Svensson, and Christoffer Petersson. Neurad: Neural rendering for autonomous driving. In CVPR, 2024
work page 2024
-
[39]
Suds: Scalable urban dynamic scenes
Haithem Turki, Jason Y Zhang, Francesco Ferroni, and Deva Ramanan. Suds: Scalable urban dynamic scenes. In CVPR, 2023
work page 2023
-
[40]
Image quality assessment: from error visibility to structural similarity
Zhou Wang, Alan C Bovik, Hamid R Sheikh, and Eero P Simoncelli. Image quality assessment: from error visibility to structural similarity. IEEE TIP, 2004
work page 2004
-
[41]
Neural light field estimation for street scenes with differentiable virtual object insertion
Zian Wang, Wenzheng Chen, David Acuna, Jan Kautz, and Sanja Fidler. Neural light field estimation for street scenes with differentiable virtual object insertion. In ECCV, 2022
work page 2022
-
[42]
Objectdrop: Bootstrapping counterfactuals for photorealistic object removal and insertion
Daniel Winter, Matan Cohen, Shlomi Fruchter, Yael Pritch, Alex Rav-Acha, and Yedid Hoshen. Objectdrop: Bootstrapping counterfactuals for photorealistic object removal and insertion. In ECCV, 2024
work page 2024
-
[43]
Difix3d+: Improving 3d reconstructions with single-step diffusion models
Jay Zhangjie Wu, Yuxuan Zhang, Haithem Turki, Xuanchi Ren, Jun Gao, Mike Zheng Shou, Sanja Fidler, Zan Gojcic, and Huan Ling. Difix3d+: Improving 3d reconstructions with single-step diffusion models. In CVPR, 2025
work page 2025
-
[44]
Amodal3r: Amodal 3d reconstruction from occluded 2d images
Tianhao Wu, Chuanxia Zheng, Frank Guan, Andrea Vedaldi, and Tat-Jen Cham. Amodal3r: Amodal 3d reconstruction from occluded 2d images. arXiv preprint arXiv:2503.13439, 2025
-
[45]
Structured 3d latents for scalable and versatile 3d generation
Jianfeng Xiang, Zelong Lv, Sicheng Xu, Yu Deng, Ruicheng Wang, Bowen Zhang, Dong Chen, Xin Tong, and Jiaolong Yang. Structured 3d latents for scalable and versatile 3d generation. In CVPR, 2025
work page 2025
-
[46]
Pandaset: Advanced sensor suite dataset for autonomous driving
Pengchuan Xiao, Zhenlei Shao, Steven Hao, Zishuo Zhang, Xiaolin Chai, Judy Jiao, Zesong Li, Jian Wu, Kai Sun, Kun Jiang, Yunlong Wang, and Diange Yang. Pandaset: Advanced sensor suite dataset for autonomous driving. In ITSC, 2021
work page 2021
-
[47]
Street gaussians for modeling dynamic urban scenes
Yunzhi Yan, Haotong Lin, Chenxu Zhou, Weijie Wang, Haiyang Sun, Kun Zhan, Xianpeng Lang, Xiaowei Zhou, and Sida Peng. Street gaussians for modeling dynamic urban scenes. In ECCV, 2024
work page 2024
-
[48]
EmerneRF: Emergent spatial-temporal scene decomposition via self-supervision
Jiawei Yang, Boris Ivanovic, Or Litany, Xinshuo Weng, Seung Wook Kim, Boyi Li, Tong Che, Danfei Xu, Sanja Fidler, Marco Pavone, and Yue Wang. EmerneRF: Emergent spatial-temporal scene decomposition via self-supervision. In ICLR, 2024
work page 2024
-
[49]
Unisim: A neural closed-loop sensor simulator
Ze Yang, Yun Chen, Jingkang Wang, Sivabalan Manivasagam, Wei-Chiu Ma, Anqi Joyce Yang, and Raquel Urtasun. Unisim: A neural closed-loop sensor simulator. In CVPR, 2023
work page 2023
-
[50]
Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. Scaling in-the-wild training for diffusion-based illumination harmonization and editing by imposing consistent light transport. In ICLR, 2025
work page 2025
-
[51]
The unreasonable effectiveness of deep features as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. In CVPR, 2018
work page 2018
-
[52]
Make the cars in the image realistic with shadows and good lighting
Xiaoyu Zhou, Zhiwei Lin, Xiaojun Shan, Yongtao Wang, Deqing Sun, and Ming-Hsuan Yang. Driving- gaussian: Composite gaussian splatting for surrounding dynamic autonomous driving scenes. In CVPR, 2024. 12 Supplementary material A Implementation details A.1 Model architecture As described in Sec. 3.2, R3D2 builds upon the work of [ 24], with key differences ...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.