Recognition: 2 theorem links
· Lean TheoremChopGrad: Pixel-Wise Losses for Latent Video Diffusion via Truncated Backpropagation
Pith reviewed 2026-05-15 09:40 UTC · model grok-4.3
The pith
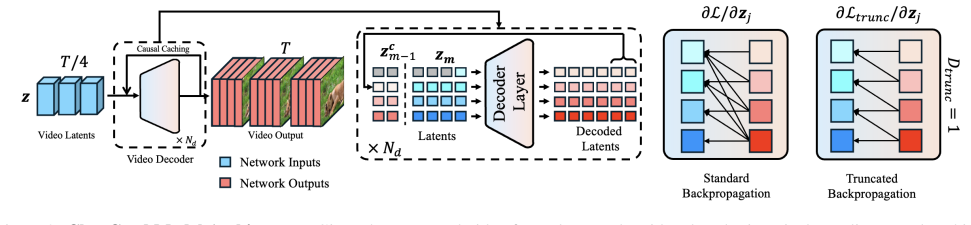
ChopGrad truncates gradients to local frame windows in recurrent video diffusion, reducing memory use to constant while supporting pixel-wise loss fine-tuning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that limiting gradient computation to local temporal windows during backpropagation through a recurrent video decoder is sufficient to preserve global consistency, enabling constant-memory training with frame-wise pixel losses that were previously intractable for long or high-resolution sequences.
What carries the argument
ChopGrad, a truncated backpropagation procedure that restricts gradient flow to fixed-size sliding windows of consecutive frames while the forward pass still uses the full recurrent conditioning chain.
If this is right
- Memory footprint for training becomes independent of video length, allowing arbitrarily long clips on fixed hardware.
- Pixel-wise losses such as L1, perceptual, or reconstruction objectives become practical for fine-tuning latent video diffusion models.
- The same truncated schedule applies to any recurrent decoder, not just diffusion, that conditions each frame on predecessors.
- Conditional tasks including super-resolution, inpainting, and scene enhancement can now use direct pixel supervision at high resolution.
Where Pith is reading between the lines
- The window-size hyperparameter could be scheduled to grow during training, starting small for stability and widening for finer global coherence.
- ChopGrad may combine naturally with other memory-saving methods such as activation checkpointing or mixed-precision to reach even longer sequences.
- Because the forward pass remains fully recurrent, inference cost and quality are unchanged; only training memory is affected.
- The approach opens the door to fine-tuning video models on consumer GPUs for domain-specific tasks like medical imaging sequences or autonomous-driving logs.
Load-bearing premise
Limiting gradient computation to local frame windows is sufficient to maintain global consistency in the recurrent video generation process without introducing significant artifacts or instability.
What would settle it
Run identical fine-tuning on short video clips with both full backpropagation and ChopGrad; if the full-backprop version produces measurably lower pixel error or visibly fewer temporal inconsistencies on held-out long sequences, the truncation approximation is falsified.
Figures


















read the original abstract
Recent video diffusion models achieve high-quality generation through recurrent frame processing where each frame generation depends on previous frames. However, this recurrent mechanism means that training such models in the pixel domain incurs prohibitive memory costs, as activations accumulate across the entire video sequence. This fundamental limitation also makes fine-tuning these models with pixel-wise losses computationally intractable for long or high-resolution videos. This paper introduces ChopGrad, a truncated backpropagation scheme for video decoding, limiting gradient computation to local frame windows while maintaining global consistency. We provide a theoretical analysis of this approximation and show that it enables efficient fine-tuning with frame-wise losses. ChopGrad reduces training memory from scaling linearly with the number of video frames (full backpropagation) to constant memory, and compares favorably to existing state-of-the-art video diffusion models across a suite of conditional video generation tasks with pixel-wise losses, including video super-resolution, video inpainting, video enhancement of neural-rendered scenes, and controlled driving video generation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ChopGrad, a truncated backpropagation scheme for recurrent latent video diffusion models that limits gradient flow to local frame windows during training with pixel-wise losses. It claims this reduces memory from linear scaling with video length to constant memory, supported by a theoretical analysis of the approximation and favorable empirical results on conditional video generation tasks including super-resolution, inpainting, neural-rendered scene enhancement, and controlled driving video generation.
Significance. If the approximation error remains bounded and global consistency is preserved, ChopGrad would make fine-tuning of recurrent video diffusion models with dense pixel losses tractable for long or high-resolution sequences, addressing a core computational barrier in the field and enabling broader use of such models in practical applications.
major comments (2)
- [§4] §4 (theoretical analysis): The error bound for the truncated backpropagation approximation must be shown to control accumulation of discrepancies across recurrent steps that span multiple local windows, as the central claim of maintained global consistency for pixel-wise losses depends on this; without an explicit multi-step recurrence analysis or bound on hidden-state drift, the reduction to constant memory risks being offset by instability.
- [§5.3] §5.3 and Table 3 (experiments on driving videos): The reported metrics do not include long-horizon temporal consistency measures (e.g., optical-flow drift or temporal FID over >64 frames), which are required to substantiate that local-window gradients suffice for global coherence in recurrent generation; current results on shorter clips leave the weakest assumption untested.
minor comments (2)
- [§3.2] §3.2: Clarify the exact window size hyperparameter and its interaction with the recurrent hidden state update; the notation for the chop point in the backprop graph is ambiguous in the current diagram.
- [Figure 4] Figure 4: The memory scaling plot should include error bars from multiple runs and a direct comparison against gradient checkpointing baselines to make the constant-memory claim visually precise.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive report. We address each major comment point by point below. Where the comments identify gaps in the current analysis or experiments, we will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [§4] §4 (theoretical analysis): The error bound for the truncated backpropagation approximation must be shown to control accumulation of discrepancies across recurrent steps that span multiple local windows, as the central claim of maintained global consistency for pixel-wise losses depends on this; without an explicit multi-step recurrence analysis or bound on hidden-state drift, the reduction to constant memory risks being offset by instability.
Authors: We appreciate the referee's emphasis on multi-step accumulation. Section 4 already establishes a per-window error bound using the Lipschitz constant of the latent decoder and shows that truncation introduces only a controlled local discrepancy. To directly address cross-window drift, the revised manuscript will include an additional recurrence analysis: we bound the hidden-state deviation over an arbitrary number of windows by a geometric series whose ratio is strictly less than one under the contraction property of the diffusion process. This explicitly confirms that global consistency is preserved and that memory reduction does not introduce instability. revision: yes
-
Referee: [§5.3] §5.3 and Table 3 (experiments on driving videos): The reported metrics do not include long-horizon temporal consistency measures (e.g., optical-flow drift or temporal FID over >64 frames), which are required to substantiate that local-window gradients suffice for global coherence in recurrent generation; current results on shorter clips leave the weakest assumption untested.
Authors: We agree that long-horizon metrics provide stronger evidence for global coherence. The experiments in §5.3 and Table 3 already demonstrate competitive performance and visual consistency on driving sequences of length 64, consistent with the local-window design. In the revision we will augment the evaluation with optical-flow drift and temporal FID computed on extended sequences (>64 frames) generated by the fine-tuned model, thereby directly testing the assumption that local gradients suffice for long-term stability. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper introduces ChopGrad as a truncated backpropagation method with an explicit theoretical analysis of the approximation error for local frame windows. No load-bearing step reduces by construction to a fitted parameter, self-citation chain, or renamed input; the memory reduction claim follows directly from the truncation definition and is validated against external benchmarks in experiments on super-resolution and driving videos. The central consistency argument rests on the provided analysis rather than prior self-citations or ansatzes.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
ChopGrad reduces training memory from scaling linearly with the number of video frames to constant memory
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
In: Uncer- tainty in Artificial Intelligence
Aicher, C., Foti, N.J., Fox, E.B.: Adaptively truncating back- propagation through time to control gradient bias. In: Uncer- tainty in Artificial Intelligence. pp. 799–808. PMLR (2020)
work page 2020
-
[2]
arXiv preprint arXiv:2304.08477 (2023)
An, J., Zhang, S., Yang, H., Gupta, S., Huang, J.B., Luo, J., Yin, X.: Latent-Shift: Latent diffusion with temporal shift for efficient text-to-video generation. arXiv preprint arXiv:2304.08477 (2023)
-
[3]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Blattmann, A., Dockhorn, T., Kulal, S., Mendelevitch, D., Kilian, M., Lorenz, D., Levi, Y ., English, Z., V oleti, V ., Letts, A., et al.: Stable video diffusion: Scaling latent video diffusion models to large datasets. arXiv preprint arXiv:2311.15127 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
In: Proceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition
Blattmann, A., Rombach, R., Ling, H., Dockhorn, T., Kim, S.W., Fidler, S., Kreis, K.: Align Your Latents: High- resolution video synthesis with latent diffusion models. In: Proceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition. pp. 22563–22575 (2023)
work page 2023
-
[5]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Ceylan, D., Huang, C.H.P., Mitra, N.J.: Pix2Video: Video editing using image diffusion. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 23206–23217 (2023)
work page 2023
-
[6]
In: Proceedings of the AAAI Con- ference on Artificial Intelligence
Chadebec, C., Tasar, O., Benaroche, E., Aubin, B.: Flash dif- fusion: Accelerating any conditional diffusion model for few steps image generation. In: Proceedings of the AAAI Con- ference on Artificial Intelligence. vol. 39, pp. 15686–15695 (2025)
work page 2025
-
[7]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Chan, K.C., Zhou, S., Xu, X., Loy, C.C.: Investigating trade- offs in real-world video super-resolution. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 5962–5971 (2022)
work page 2022
-
[8]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Chen, H., Zhang, Y ., Cun, X., Xia, M., Wang, X., Weng, C., Shan, Y .: VideoCrafter2: Overcoming data limitations for high-quality video diffusion models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 7310–7320 (2024)
work page 2024
-
[9]
arXiv preprint arXiv:2409.01199 (2024)
Chen, L., Li, Z., Lin, B., Zhu, B., Wang, Q., Yuan, S., Zhou, X., Cheng, X., Yuan, L.: OD-V AE: An omni- dimensional video compressor for improving latent video diffusion model. arXiv preprint arXiv:2409.01199 (2024)
-
[10]
In: Proceedings of the IEEE/CVF International Con- ference on Computer Vision
Chen, S., Ye, T., Lin, Y ., Jin, Y ., Yang, Y ., Chen, H., Lai, J., Fei, S., Xing, Z., Tsung, F., et al.: Genhaze: Pioneering con- trollable one-step realistic haze generation for real-world de- hazing. In: Proceedings of the IEEE/CVF International Con- ference on Computer Vision. pp. 9194–9205 (2025)
work page 2025
-
[11]
Advances in Neural Information Process- ing Systems37, 107064–107086 (2024)
Chen, Y ., Zheng, C., Xu, H., Zhuang, B., Vedaldi, A., Cham, T.J., Cai, J.: MVSplat360: Feed-forward 360 scene synthesis from sparse views. Advances in Neural Information Process- ing Systems37, 107064–107086 (2024)
work page 2024
-
[12]
In: The Thirty-ninth An- nual Conference on Neural Information Processing Systems (2025)
Chen, Z., Zou, Z., Zhang, K., Su, X., Yuan, X., Guo, Y ., Zhang, Y .: DOVE: Efficient one-step diffusion model for real-world video super-resolution. In: The Thirty-ninth An- nual Conference on Neural Information Processing Systems (2025)
work page 2025
-
[13]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Danier, D., Zhang, F., Bull, D.: LDMVFI: Video frame in- terpolation with latent diffusion models. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 38, pp. 1472–1480 (2024)
work page 2024
-
[14]
Autoencoder with recurrent neural networks for video forgery detection
D’Avino, D., Cozzolino, D., Poggi, G., Verdoliva, L.: Au- toencoder with recurrent neural networks for video forgery detection. arXiv preprint arXiv:1708.08754 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[15]
CoRR abs/2004.07728(2020),https://arxiv.org/abs/ 2004.07728
Ding, K., Ma, K., Wang, S., Simoncelli, E.P.: Image quality assessment: Unifying structure and texture similarity. CoRR abs/2004.07728(2020),https://arxiv.org/abs/ 2004.07728
-
[16]
arXiv preprint arXiv:2601.14161 (2026) 10
Dong, Y ., Zhang, Q., Jiang, M., Wu, Z., Fan, Q., Feng, Y ., Zhang, H., Bao, H., Zhang, G.: One-shot refiner: Boost- ing feed-forward novel view synthesis via one-step diffusion. arXiv preprint arXiv:2601.14161 (2026) 10
-
[17]
arXiv preprint arXiv:2411.16375 (2024)
Gao, K., Shi, J., Zhang, H., Wang, C., Xiao, J., Chen, L.: Ca2-VDM: Efficient autoregressive video diffusion model with causal generation and cache sharing. arXiv preprint arXiv:2411.16375 (2024)
-
[18]
In: Proceedings of the Asian Conference on Computer Vi- sion (2020)
Golinski, A., Pourreza, R., Yang, Y ., Sautiere, G., Cohen, T.S.: Feedback recurrent autoencoder for video compression. In: Proceedings of the Asian Conference on Computer Vi- sion (2020)
work page 2020
-
[19]
LTX-Video: Realtime Video Latent Diffusion
HaCohen, Y ., Chiprut, N., Brazowski, B., Shalem, D., Moshe, D., Richardson, E., Levin, E., Shiran, G., Zabari, N., Gordon, O., et al.: LTX-Video: Realtime video latent diffusion. arXiv preprint arXiv:2501.00103 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
arXiv preprint arXiv:2407.07667 (2024)
He, J., Xue, T., Liu, D., Lin, X., Gao, P., Lin, D., Qiao, Y ., Ouyang, W., Liu, Z.: VEnhancer: Generative space-time enhancement for video generation. arXiv preprint arXiv:2407.07667 (2024)
-
[21]
arXiv preprint arXiv:2408.07476 (2024)
He, X., Tang, H., Tu, Z., Zhang, J., Cheng, K., Chen, H., Guo, Y ., Zhu, M., Wang, N., Gao, X., et al.: One step diffusion-based super-resolution with time-aware distil- lation. arXiv preprint arXiv:2408.07476 (2024)
-
[22]
Latent Video Diffusion Models for High-Fidelity Long Video Generation
He, Y ., Yang, T., Zhang, Y ., Shan, Y ., Chen, Q.: Latent video diffusion models for high-fidelity long video genera- tion. arXiv preprint arXiv:2211.13221 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[23]
In: Proceed- ings of the Computer Vision and Pattern Recognition Con- ference
Hess, G., Lindstr ¨om, C., Fatemi, M., Petersson, C., Svens- son, L.: Splatad: Real-time lidar and camera rendering with 3d gaussian splatting for autonomous driving. In: Proceed- ings of the Computer Vision and Pattern Recognition Con- ference. pp. 11982–11992 (2025)
work page 2025
-
[24]
Imagen Video: High Definition Video Generation with Diffusion Models
Ho, J., Chan, W., Saharia, C., Whang, J., Gao, R., Gritsenko, A., Kingma, D.P., Poole, B., Norouzi, M., Fleet, D.J., et al.: Imagen video: High definition video generation with diffu- sion models. arXiv preprint arXiv:2210.02303 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[25]
Advances in neural in- formation processing systems35, 8633–8646 (2022)
Ho, J., Salimans, T., Gritsenko, A., Chan, W., Norouzi, M., Fleet, D.J.: Video diffusion models. Advances in neural in- formation processing systems35, 8633–8646 (2022)
work page 2022
-
[26]
Self Forcing: Bridging the Train-Test Gap in Autoregressive Video Diffusion
Huang, X., Li, Z., He, G., Zhou, M., Shechtman, E.: Self forcing: Bridging the train-test gap in autoregressive video diffusion. arXiv preprint arXiv:2506.08009 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
In: Pro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2024)
Huang, Z., He, Y ., Yu, J., Zhang, F., Si, C., Jiang, Y ., Zhang, Y ., Wu, T., Jin, Q., Chanpaisit, N., Wang, Y ., Chen, X., Wang, L., Lin, D., Qiao, Y ., Liu, Z.: VBench: Comprehen- sive benchmark suite for video generative models. In: Pro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2024)
work page 2024
-
[28]
In: Proceedings of the IEEE/CVF International Conference on Computer Vi- sion
Jiang, Z., Han, Z., Mao, C., Zhang, J., Pan, Y ., Liu, Y .: Vace: All-in-one video creation and editing. In: Proceedings of the IEEE/CVF International Conference on Computer Vi- sion. pp. 17191–17202 (2025)
work page 2025
- [29]
-
[30]
arXiv preprint arXiv:2503.15056 (2025)
Lee, S., Kim, K., Ye, J.C.: Single-step bidirectional unpaired image translation using implicit bridge consistency distilla- tion. arXiv preprint arXiv:2503.15056 (2025)
-
[31]
In: European Conference on Computer Vi- sion
Li, X., Zhang, Y ., Ye, X.: DrivingDiffusion: Layout-guided multi-view driving scenarios video generation with latent diffusion model. In: European Conference on Computer Vi- sion. pp. 469–485. Springer (2024)
work page 2024
-
[32]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Li, Z., Lin, B., Ye, Y ., Chen, L., Cheng, X., Yuan, S., Yuan, L.: WF-V AE: Enhancing video V AE by wavelet-driven en- ergy flow for latent video diffusion model. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 17778–17788 (2025)
work page 2025
-
[33]
In: Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition (2024)
Ling, L., Sheng, Y ., Tu, Z., Zhao, W., Xin, C., Wan, K., Yu, L., Guo, Q., Yu, Z., Lu, Y ., et al.: DL3DV-10k: A large- scale scene dataset for deep learning-based 3D vision. In: Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition (2024)
work page 2024
-
[34]
R3D2: Realistic 3D Asset Insertion via Diffusion for Autonomous Driving Simulation
Ljungbergh, W., Taveira, B., Zheng, W., Tonderski, A., Peng, C., Kahl, F., Petersson, C., Felsberg, M., Keutzer, K., Tomizuka, M., et al.: R3d2: Realistic 3d asset insertion via diffusion for autonomous driving simulation. arXiv preprint arXiv:2506.07826 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
In: European Conference on Computer Vision
Ljungbergh, W., Tonderski, A., Johnander, J., Caesar, H., ˚Astr¨om, K., Felsberg, M., Petersson, C.: Neuroncap: Photo- realistic closed-loop safety testing for autonomous driving. In: European Conference on Computer Vision. pp. 161–177. Springer (2024)
work page 2024
-
[36]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Mao, X., Jiang, Z., Wang, F.Y ., Zhang, J., Chen, H., Chi, M., Wang, Y ., Luo, W.: Osv: One step is enough for high- quality image to video generation. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 12585–12594 (2025)
work page 2025
-
[37]
arXiv preprint arXiv:2405.03150 (2024)
Melnik, A., Ljubljanac, M., Lu, C., Yan, Q., Ren, W., Rit- ter, H.: Video diffusion models: A survey. arXiv preprint arXiv:2405.03150 (2024)
-
[38]
Communications of the ACM65(1) (2021)
Mildenhall, B., Srinivasan, P.P., Tancik, M., Barron, J.T., Ra- mamoorthi, R., Ng, R.: Nerf: Representing scenes as neural radiance fields for view synthesis. Communications of the ACM65(1) (2021)
work page 2021
-
[39]
In: European Confer- ence on Computer Vision
Noroozi, M., Hadji, I., Martinez, B., Bulat, A., Tzimiropou- los, G.: You only need one step: Fast super-resolution with stable diffusion via scale distillation. In: European Confer- ence on Computer Vision. pp. 145–161. Springer (2024)
work page 2024
-
[40]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Ost, J., Mannan, F., Thuerey, N., Knodt, J., Heide, F.: Neu- ral scene graphs for dynamic scenes. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 2856–2865 (2021)
work page 2021
-
[41]
arXiv preprint arXiv:2403.12036 (2024)
Parmar, G., Park, T., Narasimhan, S., Zhu, J.Y .: One-step image translation with text-to-image models. arXiv preprint arXiv:2403.12036 (2024)
-
[42]
In: International confer- ence on machine learning
Pascanu, R., Mikolov, T., Bengio, Y .: On the difficulty of training recurrent neural networks. In: International confer- ence on machine learning. pp. 1310–1318. Pmlr (2013)
work page 2013
-
[43]
Rumelhart, D.E., Hinton, G.E., Williams, R.J.: Learning in- ternal representations by error propagation. Tech. rep., Insti- tute of Cognitive Science (1985)
work page 1985
-
[44]
Recent Advances in Recurrent Neural Networks
Salehinejad, H., Sankar, S., Barfett, J., Colak, E., Valaee, S.: Recent advances in recurrent neural networks. arXiv preprint arXiv:1801.01078 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[45]
In: SIGGRAPH Asia 2024 Conference Papers
Sauer, A., Boesel, F., Dockhorn, T., Blattmann, A., Esser, P., Rombach, R.: Fast high-resolution image synthesis with latent adversarial diffusion distillation. In: SIGGRAPH Asia 2024 Conference Papers. pp. 1–11 (2024) 11
work page 2024
-
[46]
In: European Conference on Computer Vision
Sauer, A., Lorenz, D., Blattmann, A., Rombach, R.: Ad- versarial diffusion distillation. In: European Conference on Computer Vision. Springer (2024)
work page 2024
-
[47]
Make-A-Video: Text-to-Video Generation without Text-Video Data
Singer, U., Polyak, A., Hayes, T., Yin, X., An, J., Zhang, S., Hu, Q., Yang, H., Ashual, O., Gafni, O., et al.: Make- A-Video: Text-to-video generation without text-video data. arXiv preprint arXiv:2209.14792 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[48]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Sun, P., Kretzschmar, H., Dotiwalla, X., Chouard, A., Pat- naik, V ., Tsui, P., Guo, J., Zhou, Y ., Chai, Y ., Caine, B., et al.: Scalability in perception for autonomous driving: Waymo open dataset. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 2446–2454 (2020)
work page 2020
-
[49]
In: The IEEE International Conference on Computer Vision (ICCV) (Oct 2017)
Tao, X., Gao, H., Liao, R., Wang, J., Jia, J.: Detail-revealing deep video super-resolution. In: The IEEE International Conference on Computer Vision (ICCV) (Oct 2017)
work page 2017
-
[50]
arXiv preprint arXiv:2511.06953 (2025)
Teng, S., Gao, G., Danier, D., Jiang, Y ., Zhang, F., Davis, T., Liu, Z., Bull, D.: Gfix: Perceptually en- hanced gaussian splatting video compression. arXiv preprint arXiv:2511.06953 (2025)
-
[51]
Wan: Open and Advanced Large-Scale Video Generative Models
Wan, T., Wang, A., Ai, B., Wen, B., Mao, C., Xie, C.W., Chen, D., Yu, F., Zhao, H., Yang, J., et al.: W AN: Open and advanced large-scale video generative models. arXiv preprint arXiv:2503.20314 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[52]
In: 2025 IEEE/CVF Conference on Computer Vision and Pat- tern Recognition (CVPR)
Wang, H., Liu, F., Chi, J., Duan, Y .: Videoscene: Distilling video diffusion model to generate 3d scenes in one step. In: 2025 IEEE/CVF Conference on Computer Vision and Pat- tern Recognition (CVPR). pp. 16475–16485. IEEE (2025)
work page 2025
-
[53]
arXiv preprint arXiv:2506.05301 (2025)
Wang, J., Lin, S., Lin, Z., Ren, Y ., Wei, M., Yue, Z., Zhou, S., Chen, H., Zhao, Y ., Yang, C., et al.: Seedvr2: One- step video restoration via diffusion adversarial post-training. arXiv preprint arXiv:2506.05301 (2025)
-
[54]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (2023)
Wang, R., Liu, X., Zhang, Z., Wu, X., Feng, C.M., Zhang, L., Zuo, W.: Benchmark dataset and effective inter-frame align- ment for real-world video super-resolution. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (2023)
work page 2023
-
[55]
arXiv preprint arXiv:2512.24227 (2025)
Wang, S., Sun, H., Wang, B., Ye, H., Yu, X.: Mirage: One- step video diffusion for photorealistic and coherent asset editing in driving scenes. arXiv preprint arXiv:2512.24227 (2025)
-
[56]
In: Proceedings of the IEEE/CVF international conference on computer vision
Wang, X., Xie, L., Dong, C., Shan, Y .: Real-ESRGAN: Training real-world blind super-resolution with pure syn- thetic data. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 1905–1914 (2021)
work page 1905
-
[57]
In- ternational Journal of Computer Vision133(5), 3059–3078 (2025)
Wang, Y ., Chen, X., Ma, X., Zhou, S., Huang, Z., Wang, Y ., Yang, C., He, Y ., Yu, J., Yang, P., et al.: LA VIE: High-quality video generation with cascaded latent diffusion models. In- ternational Journal of Computer Vision133(5), 3059–3078 (2025)
work page 2025
-
[58]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Wang, Y ., Yang, W., Chen, X., Wang, Y ., Guo, L., Chau, L.P., Liu, Z., Qiao, Y ., Kot, A.C., Wen, B.: Sinsr: diffusion-based image super-resolution in a single step. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 25796–25805 (2024)
work page 2024
-
[59]
arXiv preprint arXiv:2412.18605 (2024)
Wang, Z., Zhang, Z., Pang, T., Du, C., Zhao, H., Zhao, Z.: Orient anything: Learning robust object orienta- tion estimation from rendering 3d models. arXiv preprint arXiv:2412.18605 (2024)
-
[60]
Williams, R.J., Zipser, D.: Gradient-based learning algo- rithms for recurrent networks and their computational com- plexity. In: Backpropagation, pp. 433–486. Psychology Press (2013)
work page 2013
-
[61]
In: Pro- ceedings of the Computer Vision and Pattern Recognition Conference (2025)
Wu, J.Z., Zhang, Y ., Turki, H., Ren, X., Gao, J., Shou, M.Z., Fidler, S., Gojcic, Z., Ling, H.: Difix3D+: Improving 3D reconstructions with single-step diffusion models. In: Pro- ceedings of the Computer Vision and Pattern Recognition Conference (2025)
work page 2025
-
[62]
In: Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition
Wu, J., Li, X., Si, C., Zhou, S., Yang, J., Zhang, J., Li, Y ., Chen, K., Tong, Y ., Liu, Z., et al.: Towards language-driven video inpainting via multimodal large language models. In: Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition. pp. 12501–12511 (2024)
work page 2024
-
[63]
In: Proceedings of the Computer Vision and Pattern Recog- nition Conference
Wu, P., Zhu, K., Liu, Y ., Zhao, L., Zhai, W., Cao, Y ., Zha, Z.J.: Improved video V AE for latent video diffusion model. In: Proceedings of the Computer Vision and Pattern Recog- nition Conference. pp. 18124–18133 (2025)
work page 2025
-
[64]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recog- nition
Xiang, J., Lv, Z., Xu, S., Deng, Y ., Wang, R., Zhang, B., Chen, D., Tong, X., Yang, J.: Structured 3d latents for scalable and versatile 3d generation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recog- nition. pp. 21469–21480 (2025)
work page 2025
-
[65]
arXiv preprint arXiv:2501.02976 (2025)
Xie, R., Liu, Y ., Zhou, P., Zhao, C., Zhou, J., Zhang, K., Zhang, Z., Yang, J., Yang, Z., Tai, Y .: STAR: Spatial-temporal augmentation with text-to-video mod- els for real-world video super-resolution. arXiv preprint arXiv:2501.02976 (2025)
-
[66]
ACM Computing Surveys57(2), 1–42 (2024)
Xing, Z., Feng, Q., Chen, H., Dai, Q., Hu, H., Xu, H., Wu, Z., Jiang, Y .G.: A survey on video diffusion models. ACM Computing Surveys57(2), 1–42 (2024)
work page 2024
-
[67]
In: European conference on computer vision
Yang, X., He, C., Ma, J., Zhang, L.: Motion-Guided latent diffusion for temporally consistent real-world video super- resolution. In: European conference on computer vision. pp. 224–242. Springer (2024)
work page 2024
-
[68]
Y ANG, X., Xiang, W., Zeng, H., Zhang, L.: Real-world video super-resolution: A benchmark dataset and a decom- position based learning scheme. ICCV (2021)
work page 2021
-
[69]
arXiv preprint arXiv:2511.01419 (2025)
Yang, Y ., Huang, H., Peng, X., Hu, X., Luo, D., Zhang, J., Wang, C., Wu, Y .: Towards one-step causal video generation via adversarial self-distillation. arXiv preprint arXiv:2511.01419 (2025)
-
[70]
CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer
Yang, Z., Teng, J., Zheng, W., Ding, M., Huang, S., Xu, J., Yang, Y ., Hong, W., Zhang, X., Feng, G., et al.: CogVideoX: Text-to-video diffusion models with an expert transformer. arXiv preprint arXiv:2408.06072 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[71]
Journal of Ma- chine Learning Research26(34) (2025)
Ye, V ., Li, R., Kerr, J., Turkulainen, M., Yi, B., Pan, Z., Seiskari, O., Ye, J., Hu, J., Tancik, M., et al.: gsplat: An open-source library for gaussian splatting. Journal of Ma- chine Learning Research26(34) (2025)
work page 2025
-
[72]
IEEE Transactions on Circuits and Systems for Video Tech- nology30(8) (2019) 12
Yi, P., Wang, Z., Jiang, K., Shao, Z., Ma, J.: Multi-temporal ultra dense memory network for video super-resolution. IEEE Transactions on Circuits and Systems for Video Tech- nology30(8) (2019) 12
work page 2019
-
[73]
Advances in neural informa- tion processing systems37, 47455–47487 (2024)
Yin, T., Gharbi, M., Park, T., Zhang, R., Shechtman, E., Du- rand, F., Freeman, B.: Improved distribution matching distil- lation for fast image synthesis. Advances in neural informa- tion processing systems37, 47455–47487 (2024)
work page 2024
-
[74]
Language Model Beats Diffusion -- Tokenizer is Key to Visual Generation
Yu, L., Lezama, J., Gundavarapu, N.B., Versari, L., Sohn, K., Minnen, D., Cheng, Y ., Birodkar, V ., Gupta, A., Gu, X., et al.: Language model beats diffusion–Tokenizer is key to visual generation. arXiv preprint arXiv:2310.05737 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[75]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Yu, S., Sohn, K., Kim, S., Shin, J.: Video probabilistic dif- fusion models in projected latent space. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 18456–18466 (2023)
work page 2023
-
[76]
ViewCrafter: Taming Video Diffusion Models for High-fidelity Novel View Synthesis
Yu, W., Xing, J., Yuan, L., Hu, W., Li, X., Huang, Z., Gao, X., Wong, T.T., Shan, Y ., Tian, Y .: ViewCrafter: Taming video diffusion models for high-fidelity novel view synthe- sis. arXiv preprint arXiv:2409.02048 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[77]
Advances in Neural Information Processing Systems36, 13294–13307 (2023)
Yue, Z., Wang, J., Loy, C.C.: ResShift: Efficient diffu- sion model for image super-resolution by residual shifting. Advances in Neural Information Processing Systems36, 13294–13307 (2023)
work page 2023
-
[78]
In: Proceedings of the IEEE conference on com- puter vision and pattern recognition
Zhang, R., Isola, P., Efros, A.A., Shechtman, E., Wang, O.: The unreasonable effectiveness of deep features as a percep- tual metric. In: Proceedings of the IEEE conference on com- puter vision and pattern recognition. pp. 586–595 (2018)
work page 2018
-
[79]
PyTorch FSDP: Experiences on Scaling Fully Sharded Data Parallel
Zhao, Y ., Gu, A., Varma, R., Luo, L., Huang, C.C., Xu, M., Wright, L., Shojanazeri, H., Ott, M., Shleifer, S., et al.: Py- Torch FSDP: Experiences on scaling fully sharded data par- allel. arXiv preprint arXiv:2304.11277 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[80]
Open-Sora: Democratizing Efficient Video Production for All
Zheng, Z., Peng, X., Yang, T., Shen, C., Li, S., Liu, H., Zhou, Y ., Li, T., You, Y .: Open-Sora: Democratizing efficient video production for all. arXiv preprint arXiv:2412.20404 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.