EXPEREPAIR: Dual-Memory Enhanced LLM-based Repository-Level Program Repair
Pith reviewed 2026-05-19 10:05 UTC · model grok-4.3
The pith
ExpeRepair improves LLM repository-level repair by storing past fixes in episodic and semantic memories to build dynamic prompts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
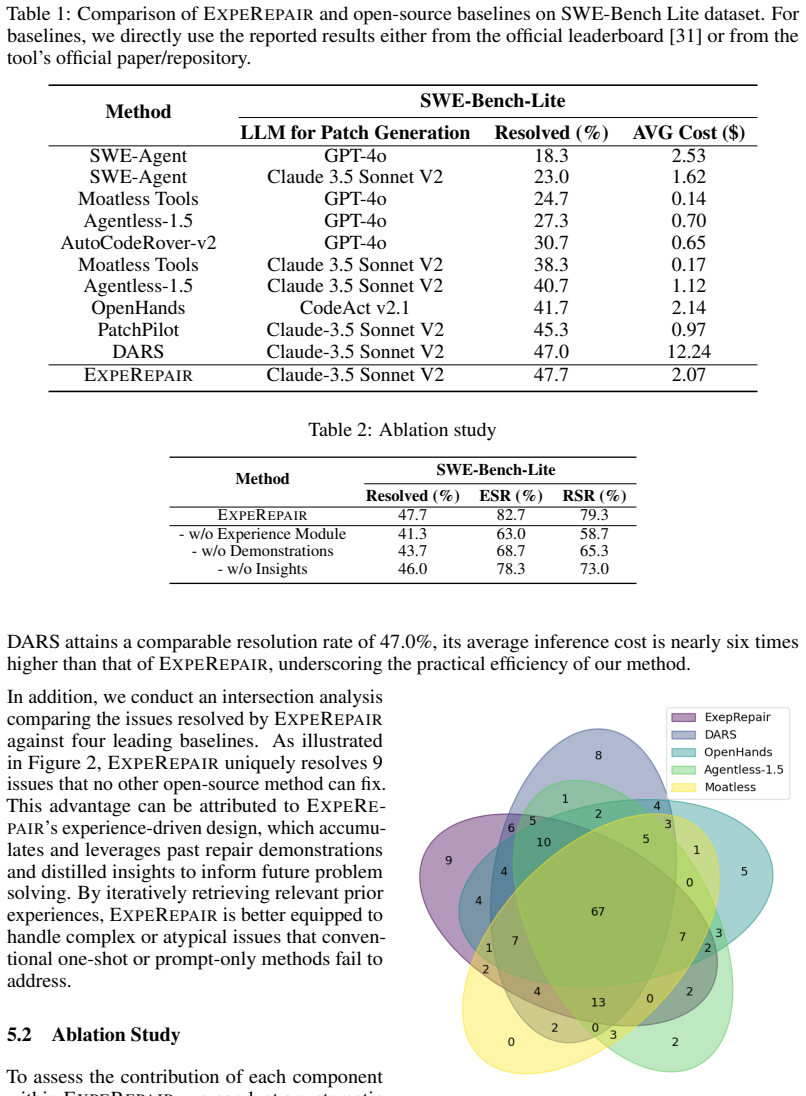
ExpeRepair organizes prior repair knowledge into episodic memory that stores concrete repair demonstrations and semantic memory that encodes abstract reflective insights; at inference it retrieves relevant demonstrations and insights from both memories and integrates them via dynamic prompt composition to replace static prompts with context-aware ones, producing pass@1 scores of 60.3 percent on SWE-Bench Lite and 74.6 percent on SWE-Bench Verified, the best among evaluated open-source methods.
What carries the argument
Dual-memory knowledge accumulation with episodic memory for concrete demonstrations, semantic memory for abstract insights, retrieval activation of both, and dynamic prompt composition that adapts prompts from accumulated experience.
Load-bearing premise
Retrieval from the episodic and semantic memories plus dynamic prompt composition will reliably surface useful prior repair knowledge for previously unseen issues rather than introducing noise or irrelevant context.
What would settle it
Disabling the memory retrieval and dynamic composition steps and measuring whether pass@1 scores on SWE-Bench Lite and Verified fall to the level of a static-prompt baseline.
Figures







read the original abstract
Automatically repairing software issues remains a fundamental challenge at the intersection of software engineering and AI. Although recent advances in Large Language Models (LLMs) have demonstrated potential for repository-level repair tasks, current methods exhibit two notable limitations: (1) they often address issues in isolation, neglecting to incorporate insights from previously resolved issues, and (2) they rely on static, rigid prompting strategies that constrain their ability to generalize across diverse and evolving contexts. We propose ExpeRepair, a novel LLM-based program repair framework inspired by the dual-memory systems of human cognition, where episodic and semantic memory synergistically support learning and decision-making. Unlike existing methods, ExpeRepair continuously learns from historical repair experiences via dual-channel knowledge accumulation, enabling it to adaptively reuse past knowledge during inference. Specifically, ExpeRepair organizes prior repair knowledge into two complementary memories: an episodic memory that stores concrete repair demonstrations, and a semantic memory that encodes abstract, reflective insights. At inference time, ExpeRepair activates both memory systems by retrieving relevant demonstrations from episodic memory and recalling high-level repair insights from semantic memory. It further enhances adaptability through dynamic prompt composition, integrating both memory types to replace static prompts with context-aware, experience-driven prompts. We evaluate ExpeRepair on two benchmarks: SWE-Bench Lite and SWE-Bench Verified. Experimental results show that ExpeRepair achieves pass@1 scores of 60.3% and 74.6% on the two benchmarks, respectively, achieving the best performance among the evaluated open-source methods. We have open-sourced ExpeRepair at https://github.com/ExpeRepair/ExpeRepair.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ExpeRepair, a dual-memory LLM framework for repository-level program repair. It maintains an episodic memory of concrete repair demonstrations and a semantic memory of abstract insights, retrieved at inference time and combined via dynamic prompt composition to replace static prompts. Evaluated on SWE-Bench Lite and SWE-Bench Verified, it reports pass@1 scores of 60.3% and 74.6% respectively, claiming the best results among evaluated open-source methods, with the code open-sourced.
Significance. If the performance gains are shown to stem from genuine out-of-distribution knowledge reuse rather than retrieval artifacts or leakage, the dual-memory design offers a cognitively motivated alternative to static prompting in LLM-based repair. The open-sourcing and concrete benchmark numbers are positive for reproducibility; the work could influence follow-on research on experience-driven adaptation in software engineering tasks.
major comments (3)
- [§3.2] §3.2 (Memory Construction): The manuscript does not specify the exact corpus, repositories, or historical issues used to seed the episodic and semantic memories. Without explicit confirmation that SWE-Bench test issues and same-repository bugs were excluded from memory population, the reported gains cannot be confidently attributed to generalization rather than data leakage or prompt inflation.
- [§4.2–4.3] §4.2–4.3 (Experimental Results and Ablations): The evaluation lacks detailed ablation controls isolating the contribution of episodic retrieval, semantic insights, and dynamic prompt composition. The headline pass@1 numbers are therefore difficult to interpret as evidence for the dual-memory claim versus other factors such as base LLM choice or prompt engineering.
- [§3.3] §3.3 (Retrieval and Prompt Composition): The similarity function, retrieval threshold, and memory-update rules are not described. This omission prevents verification that retrieved content is relevant and non-noisy for previously unseen issues, directly bearing on the central claim that dual-memory retrieval improves repair over prior open-source baselines.
minor comments (3)
- [Abstract] Abstract: The statement that ExpeRepair achieves the 'best performance among the evaluated open-source methods' should be supported by an explicit list or table of compared systems and their scores.
- [Related Work] Related Work section: Additional citations to prior LLM repository repair systems (e.g., those using retrieval-augmented generation) would better situate the dual-memory contribution.
- [Figure 2] Figure 2 (architecture diagram): Labels distinguishing episodic vs. semantic memory flows and the dynamic composition step should be enlarged for clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We address each major comment point by point below, indicating where revisions will be made to improve clarity and strengthen the presentation of our results.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Memory Construction): The manuscript does not specify the exact corpus, repositories, or historical issues used to seed the episodic and semantic memories. Without explicit confirmation that SWE-Bench test issues and same-repository bugs were excluded from memory population, the reported gains cannot be confidently attributed to generalization rather than data leakage or prompt inflation.
Authors: We agree that additional specificity on memory construction is needed to fully address concerns about potential leakage. In the revised manuscript we will expand §3.2 to explicitly describe the corpus: episodic memory is populated with concrete repair demonstrations drawn from historical GitHub issues and pull requests across a broad set of open-source repositories, while semantic memory is constructed via abstraction and reflection over those same experiences. We will add a clear statement confirming that the memory population process excluded all SWE-Bench test issues as well as any bugs from the same repositories appearing in the evaluation sets. This clarification will allow readers to attribute performance gains to out-of-distribution knowledge reuse. revision: yes
-
Referee: [§4.2–4.3] §4.2–4.3 (Experimental Results and Ablations): The evaluation lacks detailed ablation controls isolating the contribution of episodic retrieval, semantic insights, and dynamic prompt composition. The headline pass@1 numbers are therefore difficult to interpret as evidence for the dual-memory claim versus other factors such as base LLM choice or prompt engineering.
Authors: We acknowledge that more granular ablations would help isolate the contributions of each component. We will revise §§4.2–4.3 to include additional ablation experiments that separately disable episodic retrieval, semantic memory, and dynamic prompt composition while keeping the base LLM and other factors fixed. The updated results will be presented in a new table and accompanying analysis to demonstrate the incremental benefit of the full dual-memory design over partial configurations and static prompting baselines. revision: yes
-
Referee: [§3.3] §3.3 (Retrieval and Prompt Composition): The similarity function, retrieval threshold, and memory-update rules are not described. This omission prevents verification that retrieved content is relevant and non-noisy for previously unseen issues, directly bearing on the central claim that dual-memory retrieval improves repair over prior open-source baselines.
Authors: We thank the referee for noting this omission. In the revised §3.3 we will provide a complete technical description of the retrieval process, including the embedding model and cosine similarity function used for both memory types, the specific similarity threshold applied to select relevant items, and the memory-update rules that govern how new experiences are incorporated and how episodic content is periodically distilled into semantic insights. These details will enable independent verification that retrieved memories remain relevant and low-noise for unseen issues. revision: yes
Circularity Check
No circularity: empirical results on external benchmarks with design choices independent of fitted inputs
full rationale
The paper presents ExpeRepair as an engineering framework that organizes prior repair knowledge into episodic and semantic memories and uses dynamic prompt composition at inference time. The central results are pass@1 scores measured directly on the external SWE-Bench Lite and Verified benchmarks rather than any internally derived predictions or reductions. No equations, fitted parameters renamed as predictions, self-definitional loops, or load-bearing self-citations appear in the derivation chain; the dual-memory design is explicitly described as an inspirational choice from human cognition, not a mathematical necessity derived from prior results by construction. The evaluation therefore remains self-contained against public benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Prior repair experiences contain transferable knowledge that can be stored and retrieved to improve future repairs.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.lean (Jcost uniqueness); Foundation/AlexanderDuality.lean (D=3); Foundation/ArithmeticFromLogic.lean (LogicNat orbit)reality_from_one_distinction; washburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
EXPE REPAIR organizes historical repair experiences into two complementary memories: an episodic memory that stores concrete repair demonstrations, and a semantic memory that encodes abstract, reflective insights... dynamic prompt composition
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 4 Pith papers
-
ARISE: A Repository-level Graph Representation and Toolset for Agentic Fault Localization and Program Repair
ARISE adds a data-flow-augmented repository graph and three-tier tool API to LLM agents, raising Function Recall@1 by 17 points, Line Recall@1 by 15 points, and Pass@1 repair rate to 22% on SWE-bench Lite.
-
Dynamic analysis enhances issue resolution
DAIRA integrates dynamic tracing into LLM agents to achieve 79.4% resolution rate on SWE-bench Verified for code defect repair.
-
Beyond Fixed Tests: Repository-Level Issue Resolution as Coevolution of Code and Behavioral Constraints
Agent-CoEvo is a multi-agent LLM framework that coevolves code patches and test patches to resolve repository-level issues, outperforming fixed-test baselines on SWE-bench Lite and SWT-bench Lite.
-
Rethinking the Value of Agent-Generated Tests for LLM-Based Software Engineering Agents
Agent-generated tests mainly act as observational feedback channels and do not meaningfully improve issue resolution success in current LLM software engineering agents.
Reference graph
Works this paper leans on
-
[1]
DARS: dynamic action re-sampling to enhance coding agent performance by adaptive tree traversal
Vaibhav Aggarwal, Ojasv Kamal, Abhinav Japesh, Zhijing Jin, and Bernhard Schölkopf. DARS: dynamic action re-sampling to enhance coding agent performance by adaptive tree traversal. CoRR, abs/2503.14269, 2025
-
[2]
anthropic. Claude 3.5 sonnet v2. https://www.anthropic.com/news/ claude-3-5-sonnet , 2025
work page 2025
-
[3]
anthropic. Claude 3.7 sonnet. https://www.anthropic.com/claude/sonnet, 2025
work page 2025
-
[4]
RepairAgent: An Autonomous, LLM-Based Agent for Program Repair
Islem Bouzenia, Premkumar Devanbu, and Michael Pradel. Repairagent: An autonomous, llm-based agent for program repair. arXiv preprint arXiv:2403.17134, 2024
work page internal anchor Pith review arXiv 2024
-
[5]
Yuxiao Chen, Jingzheng Wu, Xiang Ling, Changjiang Li, Zhiqing Rui, Tianyue Luo, and Yanjun Wu. When large language models confront repository-level automatic program repair: How well they done? In Proceedings of the 2024 IEEE/ACM 46th International Conference on Software Engineering: Companion Proceedings, pages 459–471, 2024
work page 2024
-
[6]
Yuxiao Chen, Jingzheng Wu, Xiang Ling, Changjiang Li, Zhiqing Rui, Tianyue Luo, and Yanjun Wu. When large language models confront repository-level automatic program repair: How well they done? In Proceedings of the 2024 IEEE/ACM 46th International Conference on Software Engineering: Companion Proceedings, ICSE Companion 2024, Lisbon, Portugal, April 14-2...
work page 2024
-
[7]
DARS. Dars. https://github.com/vaibhavagg303/DARS-Agent?tab= readme-ov-file, Feb 2025
work page 2025
- [8]
-
[9]
Dual-process theories of higher cognition: Advancing the debate
Jonathan St BT Evans and Keith E Stanovich. Dual-process theories of higher cognition: Advancing the debate. Perspectives on psychological science, 8(3):223–241, 2013
work page 2013
-
[10]
ExpeRepair. Experepair project. https://github.com/ExpeRepair/ExpeRepair, 2025
work page 2025
-
[11]
Dual-process and dual-system theories of reasoning
Keith Frankish. Dual-process and dual-system theories of reasoning. Philosophy Compass, 5(10):914–926, 2010
work page 2010
-
[12]
Automatic software repair: A survey
Luca Gazzola, Daniela Micucci, and Leonardo Mariani. Automatic software repair: A survey. In Proceedings of the 40th International Conference on Software Engineering, pages 1219–1219, 2018
work page 2018
-
[13]
Daya Guo, Qihao Zhu, Dejian Yang, Zhenda Xie, Kai Dong, Wentao Zhang, Guanting Chen, Xiao Bi, Y . Wu, Y . K. Li, Fuli Luo, Yingfei Xiong, and Wenfeng Liang. Deepseek-coder: When the large language model meets programming - the rise of code intelligence. CoRR, abs/2401.14196, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
Large Language Model based Multi-Agents: A Survey of Progress and Challenges
Taicheng Guo, Xiuying Chen, Yaqi Wang, Ruidi Chang, Shichao Pei, Nitesh V Chawla, Olaf Wiest, and Xiangliang Zhang. Large language model based multi-agents: A survey of progress and challenges. arXiv preprint arXiv:2402.01680, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
Gísli R. Hjaltason and Hanan Samet. Properties of embedding methods for similarity searching in metric spaces. IEEE Trans. Pattern Anal. Mach. Intell., 25(5):530–549, 2003
work page 2003
-
[16]
Self-evolving multi-agent collaboration networks for software development
Yue Hu, Yuzhu Cai, Yaxin Du, Xinyu Zhu, Xiangrui Liu, Zijie Yu, Yuchen Hou, Shuo Tang, and Siheng Chen. Self-evolving multi-agent collaboration networks for software development. In The Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025. OpenReview.net, 2025
work page 2025
-
[17]
SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. Swe-bench: Can language models resolve real-world github issues? arXiv preprint arXiv:2310.06770, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[18]
Claire Le Goues, Michael Pradel, and Abhik Roychoudhury. Automated program repair. Communications of the ACM, 62(12):56–65, 2019. 10
work page 2019
-
[19]
Patchpilot: A stable and cost-efficient agentic patching framework
Hongwei Li, Yuheng Tang, Shiqi Wang, and Wenbo Guo. Patchpilot: A stable and cost-efficient agentic patching framework. arXiv preprint arXiv:2502.02747, 2025
-
[20]
Llms as continuous learners: Improving the reproduction of defective code in software issues
Yalan Lin, Yingwei Ma, Rongyu Cao, Binhua Li, Fei Huang, Xiaodong Gu, and Yongbin Li. Llms as continuous learners: Improving the reproduction of defective code in software issues. CoRR, abs/2411.13941, 2024
-
[21]
Dynamine: finding common error patterns by mining software revision histories
Benjamin Livshits and Thomas Zimmermann. Dynamine: finding common error patterns by mining software revision histories. ACM SIGSOFT Software Engineering Notes, 30(5):296–305, 2005
work page 2005
-
[22]
Alibaba lingmaagent: Improving automated issue resolution via comprehensive repository exploration
Yingwei Ma, Qingping Yang, Rongyu Cao, Binhua Li, Fei Huang, and Yongbin Li. Alibaba lingmaagent: Improving automated issue resolution via comprehensive repository exploration. arXiv preprint arXiv:2406.01422, 2024
-
[23]
Ragfix: Enhancing llm code repair using rag and stack overflow posts
Elijah Mansur, Johnson Chen, Muhammad Anas Raza, and Mohammad Wardat. Ragfix: Enhancing llm code repair using rag and stack overflow posts. In 2024 IEEE International Conference on Big Data (BigData), pages 7491–7496. IEEE, 2024
work page 2024
-
[24]
OpenAI. Openai o1-mini. https://openai.com/index/ openai-o1-mini-advancing-cost-efficient-reasoning/ , 2025
work page 2025
-
[25]
An analysis of patch plausibility and correctness for generate-and-validate patch generation systems
Zichao Qi, Fan Long, Sara Achour, and Martin Rinard. An analysis of patch plausibility and correctness for generate-and-validate patch generation systems. In Proceedings of the 2015 international symposium on software testing and analysis, pages 24–36, 2015
work page 2015
-
[26]
Stephen E. Robertson and Hugo Zaragoza. The probabilistic relevance framework: BM25 and beyond. Found. Trends Inf. Retr., 3(4):333–389, 2009
work page 2009
-
[27]
Code Llama: Open Foundation Models for Code
Baptiste Rozière, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiaoqing Ellen Tan, Yossi Adi, Jingyu Liu, Tal Remez, Jérémy Rapin, Artyom Kozhevnikov, Ivan Evtimov, Joanna Bitton, Manish Bhatt, Cristian Canton-Ferrer, Aaron Grattafiori, Wenhan Xiong, Alexandre Défossez, Jade Copet, Faisal Azhar, Hugo Touvron, Louis Martin, Nicolas Usunier, Thoma...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[28]
A Systematic Survey of Prompt Engineering in Large Language Models: Techniques and Applications
Pranab Sahoo, Ayush Kumar Singh, Sriparna Saha, Vinija Jain, Samrat Mondal, and Aman Chadha. A systematic survey of prompt engineering in large language models: Techniques and applications. CoRR, abs/2402.07927, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[29]
Logan IV , Eric Wallace, and Sameer Singh
Taylor Shin, Yasaman Razeghi, Robert L. Logan IV , Eric Wallace, and Sameer Singh. Au- toprompt: Eliciting knowledge from language models with automatically generated prompts. In Bonnie Webber, Trevor Cohn, Yulan He, and Yang Liu, editors, Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing, EMNLP 2020, Online, November ...
work page 2020
-
[30]
Repairllama: Efficient representations and fine-tuned adapters for program repair
André Silva, Sen Fang, and Martin Monperrus. Repairllama: Efficient representations and fine-tuned adapters for program repair. arXiv preprint arXiv:2312.15698, 2023
- [31]
-
[32]
Openhands: An open platform for ai software developers as generalist agents
Xingyao Wang, Boxuan Li, Yufan Song, Frank F Xu, Xiangru Tang, Mingchen Zhuge, Jiayi Pan, Yueqi Song, Bowen Li, Jaskirat Singh, et al. Openhands: An open platform for ai software developers as generalist agents. In The Thirteenth International Conference on Learning Representations, 2024
work page 2024
- [33]
-
[34]
Strago: Harnessing strategic guidance for prompt optimization
Yurong Wu, Yan Gao, Bin Zhu, Zineng Zhou, Xiaodi Sun, Sheng Yang, Jian-Guang Lou, Zhiming Ding, and Linjun Yang. Strago: Harnessing strategic guidance for prompt optimization. In Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen, editors,Findings of the Association for Computational Linguistics: EMNLP 2024, Miami, Florida, USA, November 12-16, 2024, pages...
work page 2024
-
[35]
Agentless: Demystifying LLM-based Software Engineering Agents
Chunqiu Steven Xia, Yinlin Deng, Soren Dunn, and Lingming Zhang. Agentless: Demystifying llm-based software engineering agents. arXiv preprint arXiv:2407.01489, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[36]
Swe-agent: Agent-computer interfaces enable automated software engineering
John Yang, Carlos Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press. Swe-agent: Agent-computer interfaces enable automated software engineering. Advances in Neural Information Processing Systems, 37:50528–50652, 2024
work page 2024
-
[37]
React: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. In International Conference on Learning Representations (ICLR), 2023
work page 2023
-
[38]
Autocoderover: Au- tonomous program improvement, 2024
Yuntong Zhang, Haifeng Ruan, Zhiyu Fan, and Abhik Roychoudhury. Autocoderover: Au- tonomous program improvement, 2024
work page 2024
-
[39]
Expel: LLM agents are experiential learners
Andrew Zhao, Daniel Huang, Quentin Xu, Matthieu Lin, Yong-Jin Liu, and Gao Huang. Expel: LLM agents are experiential learners. In Michael J. Wooldridge, Jennifer G. Dy, and Sriraam Natarajan, editors, Thirty-Eighth AAAI Conference on Artificial Intelligence, AAAI 2024, Thirty- Sixth Conference on Innovative Applications of Artificial Intelligence, IAAI 20...
work page 2024
-
[40]
Albert Örwall. Moatless tools. https://github.com/aorwall/moatless-tools, June 2024. A Appendix A.1 Implementation Test and Patch Generation. For each issue instance, EXPE REPAIR first uses the test agent to generate a reproduction script capable of triggering the issue. We set an iteration limit of 3 for script generation, producing at most one reproduct...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.