U-ViLAR: Uncertainty-Aware Visual Localization for Autonomous Driving via Differentiable Association and Registration
Pith reviewed 2026-05-19 05:44 UTC · model grok-4.3
The pith
A visual localization system for autonomous driving guides map association and registration using estimates of perceptual and localization uncertainty.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
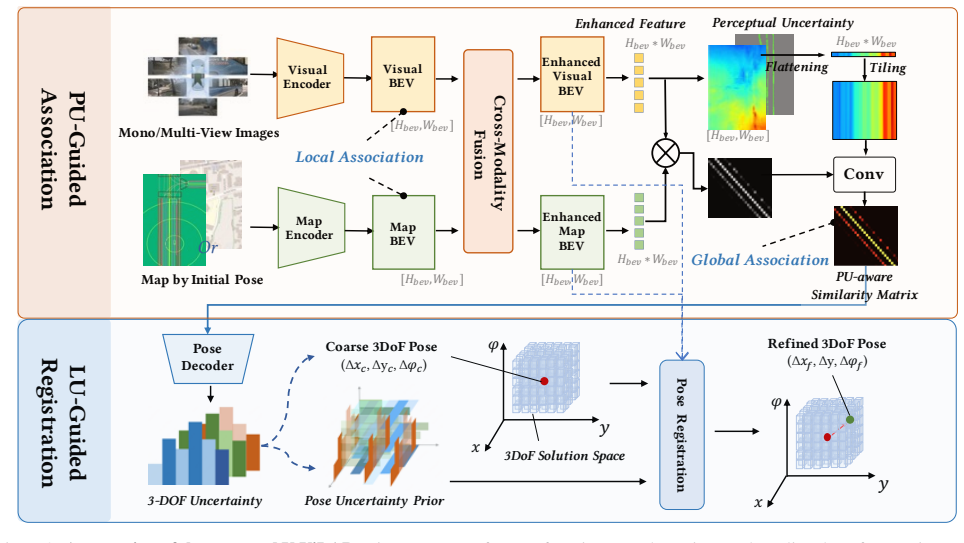
By mapping visual features into BEV space and then using perceptual uncertainty to steer differentiable association while using localization uncertainty to steer differentiable registration, the framework balances large-scale coarse localization with fine-grained precise alignment, thereby achieving robust and accurate results with HD or navigation maps.
What carries the argument
Perceptual-uncertainty-guided association and localization-uncertainty-guided registration operating on BEV-projected visual features to align with map inputs.
If this is right
- The combined association-plus-registration pipeline reaches state-of-the-art accuracy on multiple visual localization benchmarks.
- The system adapts to either detailed HD maps or coarser navigation maps without retraining.
- Real fleet deployments in challenging urban scenes maintain stable localization when GNSS is unavailable.
- Uncertainty estimates directly reduce errors that would otherwise propagate from perception or from pose drift.
Where Pith is reading between the lines
- Similar uncertainty-weighted matching could be applied to other map-relative tasks such as online map updating or semantic road segmentation.
- If uncertainty maps prove reliable, the method might lower the frequency of map refreshes needed in rapidly changing construction zones.
- Extending the same uncertainty guidance to multi-camera or camera-plus-LiDAR fusion would be a direct next test of the framework.
Load-bearing premise
Mapping camera features into bird's-eye view meaningfully improves spatial consistency with the map and the estimated uncertainties can steer association and registration without creating new errors or needing heavy parameter tuning.
What would settle it
A controlled ablation that removes either the BEV projection or the uncertainty weighting and shows no drop or an improvement in localization error on the same urban driving datasets would falsify the necessity of the proposed mechanisms.
Figures




read the original abstract
Accurate localization using visual information is a critical yet challenging task, especially in urban environments where nearby buildings and construction sites significantly degrade GNSS (Global Navigation Satellite System) signal quality. This issue underscores the importance of visual localization techniques in scenarios where GNSS signals are unreliable. This paper proposes U-ViLAR, a novel uncertainty-aware visual localization framework designed to address these challenges while enabling adaptive localization using high-definition (HD) maps or navigation maps. Specifically, our method first extracts features from the input visual data and maps them into Bird's-Eye-View (BEV) space to enhance spatial consistency with the map input. Subsequently, we introduce: a) Perceptual Uncertainty-guided Association, which mitigates errors caused by perception uncertainty, and b) Localization Uncertainty-guided Registration, which reduces errors introduced by localization uncertainty. By effectively balancing the coarse-grained large-scale localization capability of association with the fine-grained precise localization capability of registration, our approach achieves robust and accurate localization. Experimental results demonstrate that our method achieves state-of-the-art performance across multiple localization tasks. Furthermore, our model has undergone rigorous testing on large-scale autonomous driving fleets and has demonstrated stable performance in various challenging urban scenarios.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes U-ViLAR, an uncertainty-aware visual localization framework for autonomous driving in GNSS-challenged urban environments. It extracts features from visual input, maps them into BEV space to improve spatial consistency with HD or navigation maps, introduces perceptual uncertainty-guided association to mitigate perception errors, and localization uncertainty-guided registration to reduce localization errors. By balancing the coarse-grained association with fine-grained registration, the method claims robust accurate localization, SOTA performance across tasks, and stable results from large-scale fleet testing in challenging scenarios.
Significance. If the uncertainty estimates are shown to be calibrated and the balancing mechanism yields measurable gains over standard differentiable matching, the work could meaningfully improve visual localization robustness for autonomous vehicles, particularly in fleet-scale urban deployments where perception and pose uncertainties are prevalent.
major comments (2)
- [Abstract] Abstract: the central claim that perceptual and localization uncertainties can be estimated from features and directly used to guide association/registration without introducing new error sources or dataset-specific tuning is load-bearing, yet the abstract provides no formulation, loss term, or calibration evidence (e.g., negative log-likelihood on held-out pose residuals) to support it.
- [Abstract] Abstract: the assertion of SOTA performance and fleet validation is presented without quantitative metrics, baselines, error bars, or ablation studies, preventing verification that the uncertainty-guided balancing actually improves upon standard association-plus-registration pipelines.
minor comments (1)
- [Abstract] Abstract: the phrasing 'introduced to mitigate errors' is vague; a brief statement of how the uncertainty heads are trained or regularized would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment point by point below, with proposed revisions to strengthen the presentation of our contributions in the abstract while preserving its conciseness.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that perceptual and localization uncertainties can be estimated from features and directly used to guide association/registration without introducing new error sources or dataset-specific tuning is load-bearing, yet the abstract provides no formulation, loss term, or calibration evidence (e.g., negative log-likelihood on held-out pose residuals) to support it.
Authors: We agree that the abstract's brevity limits its ability to convey the technical details of uncertainty estimation and guidance. The manuscript details the perceptual uncertainty estimation from BEV features and its use in differentiable association (Section 3.2), along with localization uncertainty-guided registration (Section 3.3), using a balancing mechanism that avoids dataset-specific tuning by relying on learned uncertainty maps. Supporting evidence, including performance gains and stability under uncertainty, appears in the experimental results. To address the concern, we will revise the abstract to briefly reference the uncertainty estimation from features and the guidance mechanisms without adding new error sources. revision: yes
-
Referee: [Abstract] Abstract: the assertion of SOTA performance and fleet validation is presented without quantitative metrics, baselines, error bars, or ablation studies, preventing verification that the uncertainty-guided balancing actually improves upon standard association-plus-registration pipelines.
Authors: The abstract summarizes the outcomes, while the full quantitative metrics, baselines, error bars, and ablation studies demonstrating the benefits of uncertainty-guided balancing over standard pipelines are provided in Section 4, including large-scale fleet testing results in challenging urban scenarios (Section 4.5). We acknowledge that incorporating brief quantitative context in the abstract would aid verification. In the revision, we will add concise references to the performance improvements and the role of the balancing mechanism while remaining within abstract length constraints. revision: yes
Circularity Check
No significant circularity; forward method pipeline with independent components
full rationale
The paper describes a sequential pipeline of feature extraction into BEV space followed by two introduced modules (perceptual uncertainty-guided association and localization uncertainty-guided registration) whose integration is presented as a design choice for balancing coarse and fine localization. No equations or claims reduce a performance metric or result by construction to a fitted parameter, self-citation chain, or renamed input; the uncertainty estimates are positioned as novel additions rather than derived from the target outputs. Experimental SOTA claims are treated as empirical validation outside the derivation itself, rendering the central framework self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Mapping visual features to BEV space enhances spatial consistency with the map input
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Perceptual Uncertainty-guided Association... Localization Uncertainty-guided Registration... 3DoF joint probability space via Cartesian product
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Shannon entropy U_d = -sum p log p for each DoF; Gaussian soft supervision matrix G
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Alexandre Alahi, Raphael Ortiz, and Pierre Vandergheynst. Freak: Fast retina keypoint. In CVPR, pages 510–517, 2012. 1
work page 2012
-
[2]
Learning to localize using a lidar intensity map
Ioan Andrei B ˆarsan, Shenlong Wang, Andrei Pokrovsky, and Raquel Urtasun. Learning to localize using a lidar intensity map. 2018. 1
work page 2018
-
[3]
Surf: Speeded up robust features
Herbert Bay, Tinne Tuytelaars, and Luc Van Gool. Surf: Speeded up robust features. In ECCV, pages 404–417. Springer, 2006. 1
work page 2006
-
[4]
Vizard: Reliable visual localization for autonomous vehicles in urban outdoor environments
Mathias B¨ urki, Lukas Schaupp, Marcin Dymczyk, Renaud Dub´e, Cesar Cadena, Roland Siegwart, and Juan Nieto. Vizard: Reliable visual localization for autonomous vehicles in urban outdoor environments. pages 1124–1130. IEEE,
-
[5]
nuscenes: A mul- timodal dataset for autonomous driving
Holger Caesar, Varun Bankiti, Alex H Lang, Sourabh Vora, Venice Erin Liong, Qiang Xu, Anush Krishnan, Yu Pan, Giancarlo Baldan, and Oscar Beijbom. nuscenes: A mul- timodal dataset for autonomous driving. In CVPR, pages 11621–11631, 2020. 6
work page 2020
-
[6]
Brief: Binary robust independent elementary features
Michael Calonder, Vincent Lepetit, Christoph Strecha, and Pascal Fua. Brief: Binary robust independent elementary features. In ECCV, pages 778–792. Springer, 2010. 1
work page 2010
-
[7]
U-bev: Height- aware bird’s-eye-view segmentation and neural map-based relocalization
Andrea Boscolo Camiletto, Alfredo Bochicchio, Alexander Liniger, Dengxin Dai, and Abel Gawel. U-bev: Height- aware bird’s-eye-view segmentation and neural map-based relocalization. 2024. 7
work page 2024
-
[8]
I2d-loc: Camera localization via image to lidar depth flow
Kuangyi Chen, Huai Yu, Wen Yang, Lei Yu, Sebastian Scherer, and Gui-Song Xia. I2d-loc: Camera localization via image to lidar depth flow. ISPRS Journal of Photogram- metry and Remote Sensing, 194:209–221, 2022. 3
work page 2022
-
[9]
Superpoint: Self-supervised interest point detection and description
Daniel DeTone, Tomasz Malisiewicz, and Andrew Rabi- novich. Superpoint: Self-supervised interest point detection and description. pages 224–236, 2018. 1, 2
work page 2018
-
[10]
Uncertainty-aware vision-based metric cross-view geolocalization
Florian Fervers, Sebastian Bullinger, Christoph Bodensteiner, Michael Arens, and Rainer Stiefelhagen. Uncertainty-aware vision-based metric cross-view geolocalization. In CVPR, pages 21621–21631, 2023. 2
work page 2023
-
[11]
Vision meets robotics: The KITTI dataset
Andreas Geiger, Philip Lenz, Christoph Stiller, and Raquel Urtasun. Vision meets robotics: The KITTI dataset. In CVPR, 2013. 6
work page 2013
-
[12]
Gitnet: Geometric prior- based transformation for birds-eye-view segmentation
Shi Gong, Xiaoqing Ye, Xiao Tan, Jingdong Wang, Errui Ding, Yu Zhou, and Xiang Bai. Gitnet: Geometric prior- based transformation for birds-eye-view segmentation. In ECCV, 2022. 2
work page 2022
-
[13]
Openstreetmap: User- generated street maps
Mordechai Haklay and Patrick Weber. Openstreetmap: User- generated street maps. IEEE Pervasive computing, 7(4):12– 18, 2008. 2, 3
work page 2008
-
[14]
Zhang, Shaoqing Ren, and Jian Sun
Kaiming He, X. Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. Proceedings of the IEEE Conference on Computer Vision and Pattern Recogni- tion (CVPR), pages 770–778, 2016. 3
work page 2016
-
[15]
Egovm: Achieving precise ego-localization using lightweight vectorized maps
Yuzhe He, Shuang Liang, Xiaofei Rui, Chengying Cai, and Guowei Wan. Egovm: Achieving precise ego-localization using lightweight vectorized maps. 2024. 3
work page 2024
-
[16]
BEVDet: High-performance Multi-camera 3D Object Detection in Bird-Eye-View
Junjie Huang, Guan Huang, Zheng Zhu, and Dalong Du. Bevdet: High-performance multi-camera 3d object detection in bird-eye-view. arXiv preprint arXiv:2112.11790, 2021. 2
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[17]
Posenet: A convolutional network for real-time 6-dof camera relocalization
Alex Kendall, Matthew Grimes, and Roberto Cipolla. Posenet: A convolutional network for real-time 6-dof camera relocalization. In ICCV, 2015. 2
work page 2015
-
[18]
Slicematch: Geometry-guided aggregation for cross-view pose estimation
Ted Lentsch, Zimin Xia, Holger Caesar, and Julian FP Kooij. Slicematch: Geometry-guided aggregation for cross-view pose estimation. In CVPR, pages 17225–17234, 2023. 2
work page 2023
-
[19]
Map-based precision vehicle localization in urban environ- ments
Jesse Levinson, Michael Montemerlo, and Sebastian Thrun. Map-based precision vehicle localization in urban environ- ments. volume 4, page 1, 2007. 2
work page 2007
-
[20]
Robust vehicle localiza- tion in urban environments using probabilistic maps
Jesse Levinson and Sebastian Thrun. Robust vehicle localiza- tion in urban environments using probabilistic maps. pages 4372–4378, May 2010. 2
work page 2010
-
[21]
Bevdepth: Acquisition of reliable depth for multi-view 3d object detec- tion
Yinhao Li, Zheng Ge, Guanyi Yu, Jinrong Yang, Zengran Wang, Yukang Shi, Jianjian Sun, and Zeming Li. Bevdepth: Acquisition of reliable depth for multi-view 3d object detec- tion. In AAAI, volume 37, pages 1477–1485, 2023. 2
work page 2023
-
[22]
Worldwide pose estimation using 3d point clouds
Yunpeng Li, Noah Snavely, Daniel P Huttenlocher, and Pas- cal Fua. Worldwide pose estimation using 3d point clouds. Large-Scale Visual Geo-Localization, pages 147–163, 2016. 2
work page 2016
-
[23]
Zhiqi Li, Wenhai Wang, Hongyang Li, Enze Xie, Chonghao Sima, Tong Lu, Yu Qiao, and Jifeng Dai. Bevformer: Learn- ing bird’s-eye-view representation from multi-camera images via spatiotemporal transformers. In Computer Vision–ECCV 2022: 17th European Conference, Tel Aviv, Israel, October 23–27, 2022, Proceedings, Part IX , pages 1–18. Springer,
work page 2022
-
[24]
Pixel-perfect structure-from-motion with featuremetric refinement
Philipp Lindenberger, Paul-Edouard Sarlin, Viktor Larsson, and Marc Pollefeys. Pixel-perfect structure-from-motion with featuremetric refinement. In ICCV, pages 5987–5997, 2021. 2
work page 2021
-
[25]
Chris Linegar, Winston Churchill, and Paul Newman. Work smart, not hard: Recalling relevant experiences for vast-scale but time-constrained localisation. pages 90–97, 2015. 1
work page 2015
-
[26]
Gift: A real-time and scalable 3d spatial feature de- scriptor
Yong Liu, Lingjing Fan, Sen Xiang, Jiaqi Pan, Mingliang Cheng, Jinhui Tang, Fei Zhao, Zilei Wang, and Qingxiong Zhao. Gift: A real-time and scalable 3d spatial feature de- scriptor. In CVPR, pages 6783–6791, 2017. 1 9
work page 2017
-
[27]
Petr: Position embedding transformation for multi-view 3d object detection
Yingfei Liu, Tiancai Wang, Xiangyu Zhang, and Jian Sun. Petr: Position embedding transformation for multi-view 3d object detection. In ECCV, pages 531–548, 2022. 2
work page 2022
-
[28]
Vectormapnet: End-to-end vectorized hd map learning
Yicheng Liu, Tianyuan Yuan, Yue Wang, Yilun Wang, and Hang Zhao. Vectormapnet: End-to-end vectorized hd map learning. pages 22352–22369, 2023. 2
work page 2023
-
[29]
Distinctive image features from scale- invariant keypoints
David G Lowe. Distinctive image features from scale- invariant keypoints. IJCV, 60(2):91–110, 2004. 1
work page 2004
-
[30]
Automated map reading: image based localisation in 2-d maps using binary semantic descriptors
Pilailuck Panphattarasap and Andrew Calway. Automated map reading: image based localisation in 2-d maps using binary semantic descriptors. pages 6341–6348, 2018. 2
work page 2018
-
[31]
Monocular localization in hd maps by combining semantic segmentation and distance transform
Jan-Hendrik Pauls, K¨ ursat Petek, Fabian Poggenhans, and Christoph Stiller. Monocular localization in hd maps by combining semantic segmentation and distance transform. In 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 4595–4601. IEEE, 2020. 2
work page 2020
-
[32]
Lift, splat, shoot: Encoding images from arbitrary camera rigs by implicitly unprojecting to 3d
Jonah Philion and Sanja Fidler. Lift, splat, shoot: Encoding images from arbitrary camera rigs by implicitly unprojecting to 3d. In ECCV, pages 194–210, 2020. 2
work page 2020
-
[33]
Lennart Reiher, Bastian Lampe, and Lutz Eckstein. A sim2real deep learning approach for the transformation of images from multiple vehicle-mounted cameras to a seman- tically segmented image in bird’s eye view. In International Conference on Intelligent Transportation Systems (ITSC) , pages 1–7, 2020. 2
work page 2020
-
[34]
R2d2: Reliable and repeatable detectors and descriptors
Jerome Revaud, Philippe Weinzaepfel, Ce ´esar de Souza, Noe´e Pion, Gabriela Csurka, Yann Cabon, and Martin Hu- menberger. R2d2: Reliable and repeatable detectors and descriptors. In Advances in Neural Information Processing Systems (NeurIPS), pages 12405–12415, 2019. 1, 2
work page 2019
-
[35]
U- net: Convolutional networks for biomedical image segmen- tation
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U- net: Convolutional networks for biomedical image segmen- tation. In Medical Image Computing and Computer-Assisted Intervention–MICCAI, pages 234–241, 2015. 3
work page 2015
-
[36]
Orb: An efficient alternative to sift or surf
Ethan Rublee, Vincent Rabaud, Kurt Konolige, and Gary Bradski. Orb: An efficient alternative to sift or surf. In 2011 International conference on computer vision , pages 2564–
work page 2011
-
[37]
You are here: Geolocation by embedding maps and images
Noe Samano, Mengjie Zhou, and Andrew Calway. You are here: Geolocation by embedding maps and images. InECCV, pages 502–518. Springer, 2020. 2
work page 2020
-
[38]
Superglue: Learning feature match- ing with graph neural networks
Paul-Edouard Sarlin, Daniel DeTone, Tomasz Malisiewicz, and Andrew Rabinovich. Superglue: Learning feature match- ing with graph neural networks. InCVPR, pages 4938–4947,
-
[39]
Orienternet: Visual localization in 2d public maps with neural matching
Paul-Edouard Sarlin, Daniel DeTone, Tsun-Yi Yang, Armen Avetisyan, Julian Straub, Tomasz Malisiewicz, Samuel Rota Bul`o, Richard Newcombe, Peter Kontschieder, and Vasileios Balntas. Orienternet: Visual localization in 2d public maps with neural matching. In CVPR, pages 21632–21642, 2023. 2, 3
work page 2023
-
[40]
Large- scale direct monocular slam
Torsten Sattler, Laura Leal-Taix´e, and Marc Pollefeys. Large- scale direct monocular slam. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), 2017. 2
work page 2017
-
[41]
Beyond cross-view image retrieval: Highly accurate vehicle localization using satellite image
Yujiao Shi and Hongdong Li. Beyond cross-view image retrieval: Highly accurate vehicle localization using satellite image. In CVPR, pages 17010–17020, 2022. 6
work page 2022
-
[42]
Scene co- ordinate regression forests for camera relocalization in rgb-d images
Jamie Shotton, Ben Glocker, Christopher Zach, Shahram Izadi, Antonio Criminisi, and Andrew Fitzgibbon. Scene co- ordinate regression forests for camera relocalization in rgb-d images. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 2930–2937, 2013. 2
work page 2013
-
[43]
Sensor fusion-based low-cost vehicle localization system for complex urban environments
Jae Kyu Suhr, Jeungin Jang, Daehong Min, and Ho Gi Jung. Sensor fusion-based low-cost vehicle localization system for complex urban environments. 18(5):1078–1086, 2016. 2
work page 2016
-
[44]
Loftr: Detector-free local feature matching with transformers
Jiaming Sun, Zehong Shen, Yuang Wang, Hujun Bao, and Xiaowei Zhou. Loftr: Detector-free local feature matching with transformers. In CVPR, pages 8922–8931, 2021. 2
work page 2021
-
[45]
Visual semantic localization based on hd map for autonomous vehicles in urban scenarios
Huayou Wang, Changliang Xue, Yanxing Zhou, Feng Wen, and Hongbo Zhang. Visual semantic localization based on hd map for autonomous vehicles in urban scenarios. pages 11255–11261, 2021. 2
work page 2021
-
[46]
Detr3d: 3d object detection from multi-view images via 3d-to-2d queries
Yue Wang, Vitor Campagnolo Guizilini, Tianyuan Zhang, Yilun Wang, Hang Zhao, and Justin Solomon. Detr3d: 3d object detection from multi-view images via 3d-to-2d queries. pages 180–191, 2022. 2
work page 2022
-
[47]
Maplocnet: Coarse-to-fine feature registration for visual re-localization in navigation maps
Hang Wu, Zhenghao Zhang, Siyuan Lin, Xiangru Mu, Qiang Zhao, Ming Yang, and Tong Qin. Maplocnet: Coarse-to-fine feature registration for visual re-localization in navigation maps. pages 13198–13205. IEEE, 2024. 2
work page 2024
-
[48]
Uncertainty-aware learning for video frame interpola- tion
Haoqiang Zhang, Wenhan Luo, Wenxiu Yu, and Xiaoyong Yang. Uncertainty-aware learning for video frame interpola- tion. pages 10543–10554, 2022. 4
work page 2022
-
[49]
Bev-locator: An end-to-end visual semantic localization network using multi-view im- ages
Zhihuang Zhang, Meng Xu, Wenqiang Zhou, Tao Peng, Liang Li, and Stefan Poslad. Bev-locator: An end-to-end visual semantic localization network using multi-view im- ages. In ECCV, 2022. 2, 3 10
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.