MaPPO: Maximum a Posteriori Preference Optimization with Prior Knowledge
Pith reviewed 2026-05-19 02:55 UTC · model grok-4.3
The pith
MaPPO integrates prior reward estimates into a Maximum a Posteriori objective to generalize and strengthen Direct Preference Optimization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
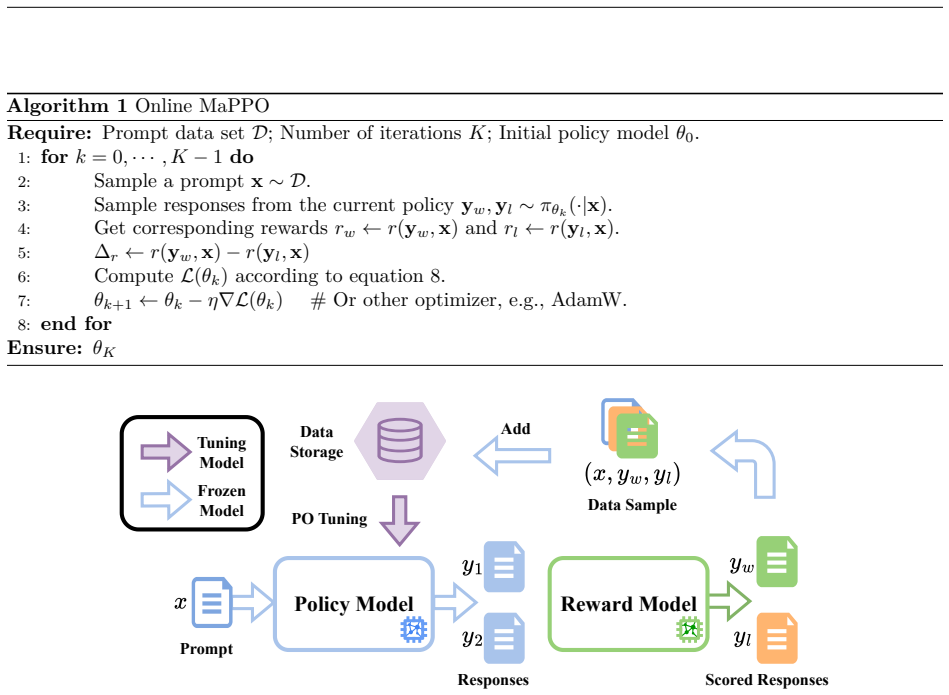
MaPPO integrates prior reward estimates into a principled Maximum a Posteriori (MaP) objective. This generalizes DPO and its variants, mitigates the oversimplified binary classification of responses, requires no additional hyperparameters, and supports preference optimization in both offline and online settings. When used as a plugin for SimPO, IPO, and CPO it produces consistent gains on MT-Bench, AlpacaEval 2.0, and Arena-Hard across model sizes and families.
What carries the argument
The Maximum a Posteriori (MaP) objective that incorporates an external prior reward estimate to guide the optimization away from pure maximum-likelihood binary preference modeling.
If this is right
- Consistent gains on MT-Bench, AlpacaEval 2.0, and Arena-Hard without extra computational cost.
- Seamless use in both offline and online preference optimization regimes.
- Direct compatibility as a plugin that lifts SimPO, IPO, and CPO performance.
- No new hyperparameters are introduced by the MaP formulation.
Where Pith is reading between the lines
- If the prior reward signal is reliable, fewer human preference labels may suffice for comparable alignment quality.
- The Bayesian framing could be adapted to other alignment objectives that currently rely on maximum-likelihood losses.
- Systematic variation of prior quality across model scales would clarify how sensitive the gains are to the accuracy of the external reward estimate.
Load-bearing premise
An external prior reward estimate of usable quality must be available and its inclusion must not introduce biases or instabilities that outweigh the reported gains.
What would settle it
Applying MaPPO with a deliberately low-quality or random prior reward model on the same benchmarks and observing performance that falls below standard DPO would show the prior integration is not beneficial.
Figures





read the original abstract
As the era of large language models (LLMs) unfolds, Preference Optimization (PO) methods have become a central approach to aligning LLMs with human preferences and improving performance. We propose Maximum a Posteriori Preference Optimization (MaPPO), a methodology for learning from preferences that explicitly incorporates prior reward knowledge into the optimization objective. Building on the paradigm employed by Direct Preference Optimization (DPO) and its variants of treating preference learning as a Maximum Likelihood Estimation (MLE) problem, MaPPO integrates prior reward estimates into a principled Maximum a Posteriori (MaP) objective. This not only generalizes DPO and its variants, but also enhances alignment by mitigating the oversimplified binary classification of responses. Additionally, MaPPO introduces no additional hyperparameters, and supports preference optimization in both offline and online settings. In addition, MaPPO can be used as a plugin for DPO variants, including widely used SimPO, IPO and CPO, and produce consistent improvements. Extensive empirical evaluations of different model sizes and model series on three standard benchmarks (MT-Bench, AlpacaEval 2.0, and Arena-Hard) demonstrate consistent improvements in alignment performance without sacrificing computational efficiency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes MaPPO, a preference optimization approach for LLM alignment that folds external prior reward estimates into a Maximum a Posteriori objective. It claims to generalize DPO and variants such as SimPO, IPO and CPO, to require no extra hyperparameters, to work in both offline and online regimes, and to deliver consistent gains on MT-Bench, AlpacaEval 2.0 and Arena-Hard across model sizes and families.
Significance. If the central empirical claims prove robust, the work would supply a practical Bayesian extension to the DPO family that incorporates prior knowledge without increasing hyper-parameter count. The plugin compatibility with existing methods is a clear engineering advantage.
major comments (2)
- [Abstract] Abstract: the statement that MaPPO 'introduces no additional hyperparameters' while 'explicitly incorporat[ing] prior reward knowledge' is not supported by any derivation or specification of how the prior is obtained, normalized, or regularized; because the prior is treated as an external input whose quality directly determines the reported gains, this omission is load-bearing for the generalization and 'no-extra-hyperparameters' claims.
- [Experimental Evaluation] Experimental section: the abstract asserts 'consistent improvements' on three benchmarks yet supplies neither ablation tables isolating the contribution of the MaP term, nor error bars, nor any validation of prior quality; without these the robustness of the central empirical claim cannot be assessed.
minor comments (1)
- [Abstract] The phrase 'mitigating the oversimplified binary classification of responses' would benefit from a short concrete illustration of how the MaP objective differs from the standard DPO likelihood in this respect.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each of the major comments in detail below and outline the revisions we plan to make.
read point-by-point responses
-
Referee: [Abstract] Abstract: the statement that MaPPO 'introduces no additional hyperparameters' while 'explicitly incorporat[ing] prior reward knowledge' is not supported by any derivation or specification of how the prior is obtained, normalized, or regularized; because the prior is treated as an external input whose quality directly determines the reported gains, this omission is load-bearing for the generalization and 'no-extra-hyperparameters' claims.
Authors: We appreciate the referee pointing out the need for clearer specification regarding the prior. In Section 3 of the manuscript, we present the derivation of the MaPPO objective from the MAP framework, where the prior reward estimate enters the objective as an additive term in the log-posterior. This prior is provided externally, analogous to the use of a pre-trained reward model in RLHF, and the optimization procedure does not require tuning any new hyperparameters beyond those of the base method (e.g., learning rate, batch size). We acknowledge that the manuscript could benefit from more explicit discussion on how the prior is normalized and regularized in practice. In the revised version, we will expand the method section to include a detailed explanation of prior integration, including normalization procedures, to better support the claims. revision: partial
-
Referee: [Experimental Evaluation] Experimental section: the abstract asserts 'consistent improvements' on three benchmarks yet supplies neither ablation tables isolating the contribution of the MaP term, nor error bars, nor any validation of prior quality; without these the robustness of the central empirical claim cannot be assessed.
Authors: We agree that the empirical evaluation would be strengthened by additional analyses. The reported results show that MaPPO, when applied as a plugin to DPO, SimPO, IPO, and CPO, yields improvements on MT-Bench, AlpacaEval 2.0, and Arena-Hard across different model sizes. However, the current version lacks dedicated ablation tables for the MaP component, error bars from multiple seeds, and explicit validation metrics for the prior estimates. We will address this in the revision by adding ablation studies that isolate the effect of the prior term, reporting mean and standard deviation over multiple runs where feasible, and including a subsection validating the quality of the priors used in the experiments. revision: yes
Circularity Check
No significant circularity; derivation treats prior as external input
full rationale
The paper frames MaPPO as a generalization of DPO that folds an external prior reward estimate into a Maximum a Posteriori objective. No quoted equation or derivation step reduces the loss, the MAP formulation, or the reported benchmark gains directly to a parameter fitted from the target preference data by construction. The prior is presented as an independent input rather than derived internally, empirical results are reported on separate benchmarks (MT-Bench, AlpacaEval 2.0, Arena-Hard), and no load-bearing self-citation chain or self-definitional loop is exhibited in the abstract or described method. The central claim therefore remains self-contained against external evaluation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption An external prior reward estimate of sufficient quality exists and can be treated as independent of the current preference dataset.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
MaPPO integrates prior reward estimates into a principled Maximum a Posteriori (MaP) objective... LMaP(θ) = E[−log σ(β log πθ(yw|x)/πref(yw|x) − Δr β log πθ(yl|x)/πref(yl|x))]
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
no additional hyperparameter... supports both offline and online settings
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 3 Pith papers
-
Alternating Reinforcement Learning with Contextual Rubric Rewards: Beyond the Scalarization Strategy
ARL-RR alternates optimization over rubric meta-classes with dynamic selection to avoid fixed scalarization, outperforming baselines on HealthBench.
-
Zero-Shot Vulnerability Detection in Low-Resource Smart Contracts Through Solidity-Only Training
Sol2Vy transfers vulnerability detection from Solidity to Vyper in zero-shot fashion, outperforming prior methods on reentrancy, weak randomness, and unchecked transfers.
-
Reinforcement Learning for Scalable and Trustworthy Intelligent Systems
Reinforcement learning is advanced for communication-efficient federated optimization and for preference-aligned, contextually safe policies in large language models.
Reference graph
Works this paper leans on
-
[1]
Let the gradient operator be defined as τθ:= ∇LMaP(θ)
The score function is Lipschitz continuous as∥∇logπθ(y|x)−∇logπθ′(y|x)∥≤Mg. Let the gradient operator be defined as τθ:= ∇LMaP(θ). (25) Then, the gradient operatorτis Lipschitz continuous with ∥τθ−τθ′∥≤LMaP∥θ−θ′∥, (26) where LMaP =β(1−σ(u))(1 + ∆r)Mg <β(1 + ∆r)Mg. 17 Proof. We have τθ= −β(1−σ(u)) ( ∇logπθ(yw|x)−∆ r∇logπθ(yl|x) ) . (27) The norm of the gra...
-
[2]
Combiningthe Mg Lipschitzofthescorefunction ∇logπθ(y|x), we have ∥τθ−τθ′∥≤β(1−σ(u))(1 + ∆r)Mg∥θ−θ′∥:= LMaP∥θ−θ′∥. (29) In contrast, in DPO, the gradient is Lipschitz continuous as ∥τθ−τθ′∥≤LDPO∥θ−θ′∥, (30) where LDPO = 2β(1−σ(u))Mg < 2βMg. The Lipschitz constant of the gradients in DPO is larger than that in MaPPO, which shows the gradients have less stab...
-
[4]
The difference of their squares:x2−y2 = 44 Step 2: Factorize the Difference of Squares Recall that the difference of squares can be factored as: x2−y2 = (x +y)(x−y) Substitute the given sumx +y = 22 into the factored form: 44 = 22(x−y) Step 3: Solve forx−y Divide both sides by 22: x−y = 2 Step 4: Solve the System of Linear Equations Now, we have the syste...
-
[5]
The sum of the two integers is 22: x +y = 22
-
[6]
The difference of their squares is 44: x2−y2 = 44 We can use the identity for the difference of squares,x2−y2 = (x +y)(x−y), to rewrite the second equation. Substitutingx +y = 22 into the identity gives: (x +y)(x−y) = 44 =⇒22(x−y) = 44 Dividing both sides by 22: x−y = 2 Now we have a system of linear equations: { x +y = 22 x−y = 2 Adding these two equatio...
-
[7]
The sum of two positive integersx and y is 22
-
[8]
We need to determine the product of these two integers
The difference of their squares is 44. We need to determine the product of these two integers. Step-by-Step Solution:
-
[9]
Setting up Equations: - From the first condition: x +y = 22 - From the second condition (expressing the difference of squares): x2−y2 = 44 We know thatx2−y2 can be factored using the difference of squares formula: x2−y2 = (x +y)(x−y)
-
[10]
Substitutex +y: - Using the known value from equation (1) in the factored form of the difference of squares: x2−y2 = (x +y)(x−y) =⇒44 = 22(x−y) - Solve forx−y: 22(x−y) = 44 =⇒x−y = 2
-
[11]
Solving the System of Linear Equations: - Now, we have the system of equations: x +y = 22 x−y = 2 - Add these two equations to eliminatey: (x +y) + (x−y) = 22 + 2 2x = 24 =⇒x = 12 - Substitutex = 12 back intox +y = 22 to findy: 12 +y = 22 =⇒y = 10
-
[12]
Finding the Product: - Withx = 12 and y = 10, calculate the product: xy = 12×10 = 120 Thus, the product of the two integers is120 . 21 Response yl, r = 0.43 Step 1: Interpret the problem and set up equations based on the given information. Given that the sum of two positive integers is 22 and the difference of their squares is 44, we need to find these in...
-
[13]
Substitute a = 12 back into the first equation to solve forb: 12 +b = 22 =⇒b = 10
a−b = 2 Add the two equations together to eliminateb: (a +b) + (a−b) = 22 + 2 =⇒2a = 24 =⇒a = 12. Substitute a = 12 back into the first equation to solve forb: 12 +b = 22 =⇒b = 10. Step 6: Find the product ofa and b. The product of the two integersa and b is: ab = 12×10 = 120. Step 7: Box the final answer. 120 Figure 5: After MLE optimization, the model d...
-
[14]
The sum of the two integers:x +y = 22
-
[15]
The difference of their squares:x2−y2 = 44 Step 1: Express the Difference of Squares We know from algebra that: x2−y2 = (x +y)(x−y) Givenx +y = 22, we substitute this into the equation: 44 = 22(x−y) Step 2: Solve forx−y Divide both sides by 22: x−y = 2 Step 3: Solve the System of Linear Equations Now, we have a system of linear equations:
-
[16]
x−y = 2 Add these two equations to eliminatey: (x +y) + (x−y) = 22 + 2 2x = 24 x = 12 Subtract the second equation from the first to eliminatex: (x +y)−(x−y) = 22−2 2y = 20 y = 10 Step 4: Calculate the Product of the Two Integers Now that we havex = 12 and y = 10, we find their product: xy = 12×10 = 120 Thus, the product of the two integers is: 120 23 Res...
-
[17]
Define Variables: Let the two positive integers bex and y, withx>y
-
[18]
Set Up Equations Based on Given Information: - The sum of the two integers is 22: x +y = 22 - The difference of their squares is 44: x2−y2 = 44
-
[19]
Therefore: (x +y)(x−y) = 44 Substitute x +y = 22 into the equation: 22(x−y) = 44
Factor the Difference of Squares: Recall thatx2−y2 can be factored as(x +y)(x−y). Therefore: (x +y)(x−y) = 44 Substitute x +y = 22 into the equation: 22(x−y) = 44
-
[20]
Solve forx−y: Divide both sides by 22: x−y = 2
-
[21]
Set Up a System of Linear Equations: We now have the system: { x +y = 22 x−y = 2
-
[22]
Add the Two Equations to Solve forx: Adding the equations eliminatesy: (x +y) + (x−y) = 22 + 2 Simplifies to: 2x = 24 =⇒x = 12
-
[23]
Substitutex = 12 Back to Findy: Using x +y = 22: 12 +y = 22 =⇒y = 10
-
[24]
24 C Supplementary Experiments C.1 Supplementary Experimental Settings Hyperparameter settings
Calculate the Product of the Two Integers: The product ofx and y is: x·y = 12·10 = 120 The answer is 120 Figure 6: After MaP optimization, the model consistently generates high quality outputs with promptx. 24 C Supplementary Experiments C.1 Supplementary Experimental Settings Hyperparameter settings. We follow the standard settings and list the hyperpara...
work page 2007
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.