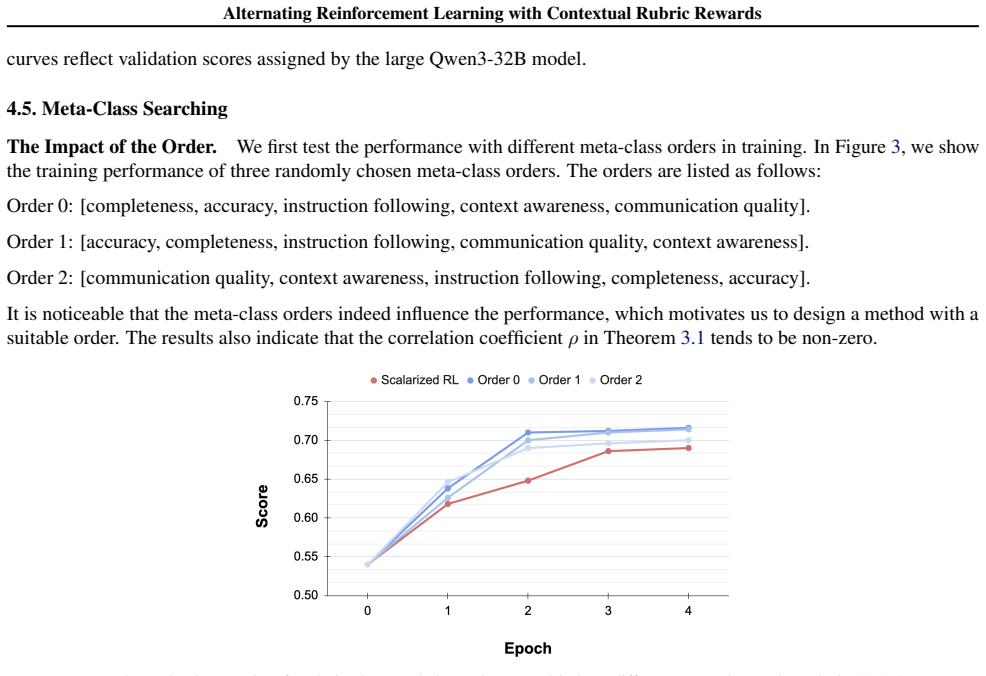
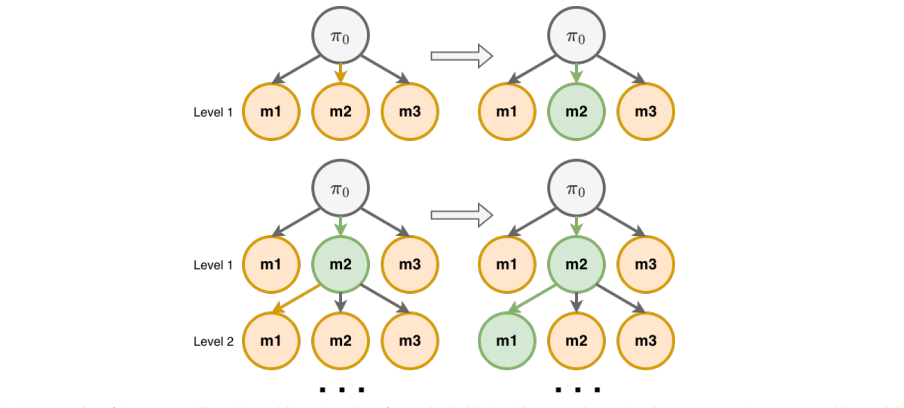
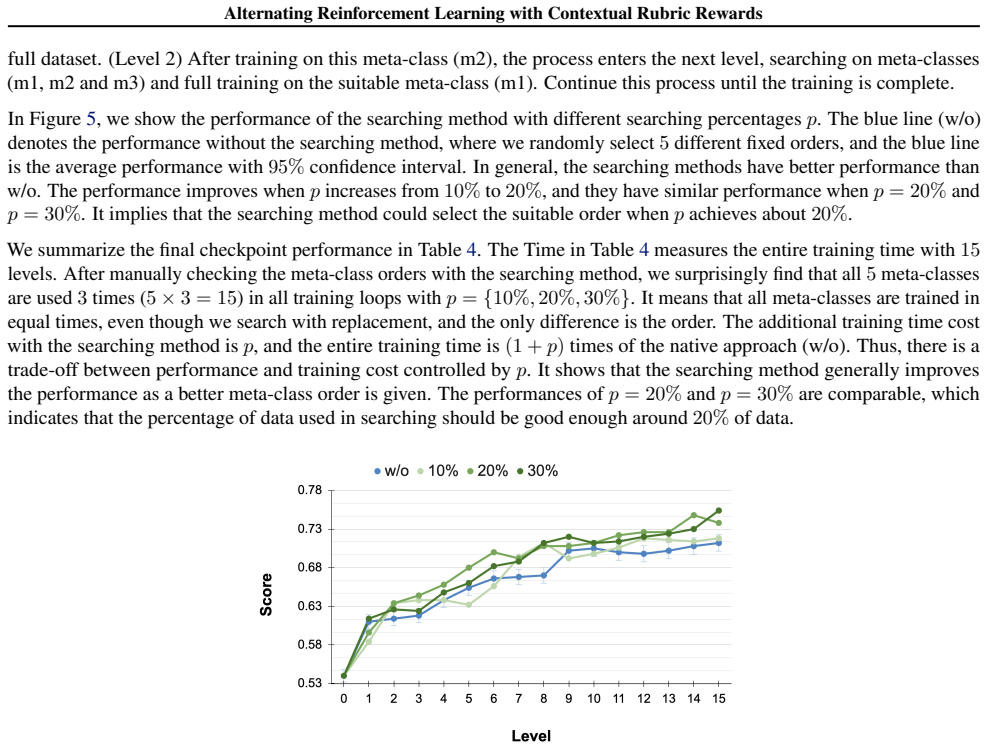
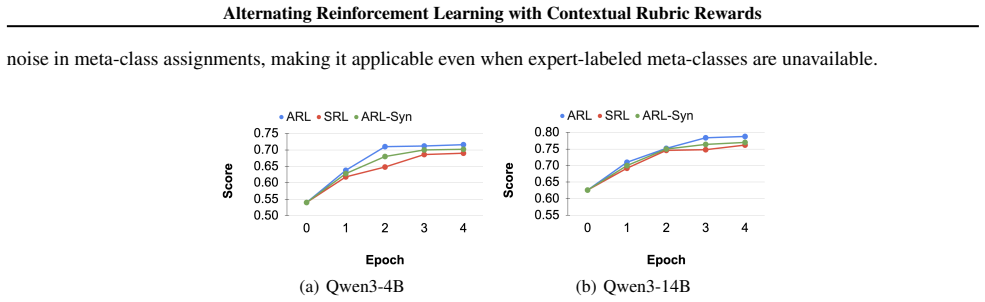
Recognition: no theorem link
Alternating Reinforcement Learning with Contextual Rubric Rewards: Beyond the Scalarization Strategy
Pith reviewed 2026-05-15 17:04 UTC · model grok-4.3
The pith
By alternating optimization across rubric meta-classes, ARL-RR surpasses fixed scalarization in both performance and efficiency for multi-dimensional reward reinforcement learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ARL-RR eliminates the need for fixed scalarization by optimizing one rubric meta-class at a time using a lightweight search-based adaptation to select the next focus based on performance, capturing inter-dimension correlations better and yielding gains explained by variance contraction in aggregation.
What carries the argument
Search-based dynamic selection of rubric meta-classes for sequential optimization in the ARL-RR framework, which alternates the training focus to emphasize critical objectives without fixed weights.
Load-bearing premise
That dynamically switching optimization across rubric meta-classes via search reliably captures correlations among reward dimensions better than fixed linear scalarization without adding instabilities or biases.
What would settle it
Run ARL-RR and scalarized baselines on a synthetic task where reward dimensions are known to be independent with no correlations; if ARL-RR does not outperform or underperforms, the core advantage does not hold.
Figures



read the original abstract
Reinforcement Learning with Rubric Rewards (RLRR) is a framework that extends conventional reinforcement learning from human feedback (RLHF) and verifiable rewards (RLVR) by replacing scalar preference signals with structured, multi-dimensional, contextual rubric-based evaluations. However, existing approaches in RLRR are limited to linearly compressing vector rewards into a scalar reward with a fixed weightings, which is sensitive to artificial score design and fails to capture correlations among reward dimensions. To overcome the limitations of reward aggregation, this work proposes Alternating Reinforcement Learning with Rubric Rewards (ARL-RR), a framework that eliminates the need for a fixed scalarization by optimizing one semantic rubric meta-class at a time. Theoretically, we show that reward aggregation induces a variance contraction effect, which helps explain the performance gains. We further introduce a lightweight, search-based adaptation procedure that selects the next meta-class dynamically based on task performance, enabling the policy to emphasize critical objectives and thereby improve the model performance. Empirically, our experiments on the HealthBench dataset with experts annotations demonstrate that ARL-RR uniformly outperforms scalarized methods in both model performance and training efficiency across different model scales (1.7B, 4B, 8B, and 14B).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Alternating Reinforcement Learning with Rubric Rewards (ARL-RR), which replaces fixed linear scalarization of multi-dimensional rubric rewards with alternating optimization over one semantic rubric meta-class at a time, selected via a lightweight search-based adaptation procedure driven by task performance. It asserts a theoretical variance contraction effect induced by reward aggregation to explain performance gains and reports uniform empirical outperformance over scalarized baselines on the HealthBench dataset (with expert annotations) in both model performance and training efficiency across scales from 1.7B to 14B parameters.
Significance. If the variance contraction result and the attribution of gains to the alternating-plus-adaptation mechanism can be rigorously established, the work would address a recognized limitation of scalarization in RLHF/RLVR and offer a practical route to better capture inter-dimension correlations in structured reward settings, with particular relevance to domains such as healthcare evaluation.
major comments (3)
- [Abstract] Abstract: the variance contraction effect is asserted as the explanation for performance gains, yet no equation, derivation, or section reference is supplied; without this the theoretical claim cannot be evaluated and remains load-bearing for the central argument.
- [Abstract / Experiments] Abstract / Experiments section: the uniform outperformance claim on HealthBench is stated without statistical details, error bars, number of runs, or any ablation that holds the alternating schedule fixed while disabling the search-based selector (e.g., round-robin or random meta-class order); this leaves open whether reported gains arise from the proposed adaptation or from an implicit selection bias.
- [Method] Method: the search-based adaptation is described as selecting the next meta-class 'based on task performance,' but no formal guarantee or analysis is given against myopic selection or run-to-run variance inflation; an explicit comparison isolating the scheduler from the alternation benefit is required to support the claim that the procedure reliably captures correlations better than fixed scalarization.
minor comments (2)
- [Abstract] Abstract: 'experts annotations' is mentioned without describing the annotation protocol, rubric meta-class definitions, or inter-annotator reliability metrics, which would improve reproducibility.
- [Introduction] Notation: the distinction between individual rubric dimensions and the higher-level 'meta-classes' used for alternation should be clarified with an explicit example or table early in the paper.
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive feedback. We address each major comment below and will revise the manuscript to strengthen the presentation of the theoretical claim, add statistical details and ablations, and provide further analysis of the adaptation procedure.
read point-by-point responses
-
Referee: [Abstract] Abstract: the variance contraction effect is asserted as the explanation for performance gains, yet no equation, derivation, or section reference is supplied; without this the theoretical claim cannot be evaluated and remains load-bearing for the central argument.
Authors: The variance contraction effect is formally derived in Section 3.2 of the manuscript (Equation 5), where we show that sequential optimization over meta-classes contracts the variance of the aggregated reward by a factor of 1/K for K meta-classes under standard assumptions on reward independence. We will revise the abstract to include a direct reference to Section 3.2 and a concise statement of the contraction result. revision: yes
-
Referee: [Abstract / Experiments] Abstract / Experiments section: the uniform outperformance claim on HealthBench is stated without statistical details, error bars, number of runs, or any ablation that holds the alternating schedule fixed while disabling the search-based selector (e.g., round-robin or random meta-class order); this leaves open whether reported gains arise from the proposed adaptation or from an implicit selection bias.
Authors: We agree that the current presentation lacks sufficient statistical detail. In the revision we will report means and standard deviations over 5 independent runs with error bars, explicitly state the number of runs, and add an ablation that fixes the alternating schedule while replacing the search-based selector with round-robin and random meta-class ordering. This will isolate the contribution of the dynamic adaptation. revision: yes
-
Referee: [Method] Method: the search-based adaptation is described as selecting the next meta-class 'based on task performance,' but no formal guarantee or analysis is given against myopic selection or run-to-run variance inflation; an explicit comparison isolating the scheduler from the alternation benefit is required to support the claim that the procedure reliably captures correlations better than fixed scalarization.
Authors: We will add an explicit ablation in the experiments section that holds alternation fixed and varies only the selection policy (dynamic search vs. round-robin vs. random), directly addressing isolation of the scheduler. While the current manuscript does not contain a formal guarantee against myopic selection, the empirical results show consistent variance reduction; we will expand the discussion to analyze potential myopic risks and their empirical mitigation. revision: partial
Circularity Check
No significant circularity; derivation remains self-contained
full rationale
The paper's core argument proceeds from the definition of ARL-RR (alternating single-meta-class optimization plus search-based selection) to a variance-contraction claim and empirical gains on HealthBench. No equation or procedure is shown to reduce by construction to its own fitted inputs; the adaptation rule is presented as performance-driven rather than post-hoc tuned to the reported metric. No self-citation chain is invoked to establish uniqueness or to smuggle an ansatz. The theoretical variance effect is stated as a consequence of aggregation, not as a renaming of the method itself. The derivation therefore stands on independent empirical and analytic content.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
Reinforcement Learning for Scalable and Trustworthy Intelligent Systems
Reinforcement learning is advanced for communication-efficient federated optimization and for preference-aligned, contextually safe policies in large language models.
Reference graph
Works this paper leans on
-
[1]
Anschel, O., Shoshan, A., Botach, A., Hakimi, S. H., Gendler, A., Baruch, E. B., Bhonker, N., Kviatkovsky, I., Aggarwal, M., and Medioni, G. Group-aware reinforcement learning for output diversity in large language models. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing (EMNLP), pp. 32382–32403,
work page 2025
-
[2]
HealthBench: Evaluating Large Language Models Towards Improved Human Health
Arora, R. K., Wei, J., Hicks, R. S., Bowman, P., Qui˜nonero-Candela, J., Tsimpourlas, F., Sharman, M., Shah, M., Vallone, A., Beutel, A., et al. HealthBench: Evaluating large language models towards improved human health.arXiv preprint arXiv:2505.08775,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Constitutional AI: Harmlessness from AI Feedback
Bai, Y ., Kadavath, S., Kundu, S., Askell, A., Kernion, J., Jones, A., Chen, A., Goldie, A., Mirhoseini, A., McKinnon, C., et al. Constitutional AI: Harmlessness from AI feedback.arXiv preprint arXiv:2212.08073,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Bamba, U., Fang, M., Yu, Y ., Zheng, H., and Lai, F. XRPO: Pushing the limits of GRPO with targeted exploration and exploitation.arXiv preprint arXiv:2510.06672,
-
[5]
Language models that think, chat better.arXiv preprint arXiv:2509.20357,
Bhaskar, A., Ye, X., and Chen, D. Language models that think, chat better.arXiv preprint arXiv:2509.20357,
-
[6]
Rubrics as Rewards: Reinforcement Learning Beyond Verifiable Domains
Gunjal, A., Wang, A., Lau, E., Nath, V ., He, Y ., Liu, B., and Hendryx, S. Rubrics as rewards: Reinforcement learning beyond verifiable domains.arXiv preprint arXiv:2507.17746,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
He, Y ., Li, W., Zhang, H., Li, S., Mandyam, K., Khosla, S., Xiong, Y ., Wang, N., Peng, S., Li, B., et al. Rubric-based benchmarking and reinforcement learning for advancing LLM instruction following.arXiv preprint arXiv:2511.10507,
-
[8]
Reinforcement learning with rubric anchors.arXiv preprint arXiv:2508.12790,
Huang, Z., Zhuang, Y ., Lu, G., Qin, Z., Xu, H., Zhao, T., Peng, R., Hu, J., Shen, Z., Hu, X., et al. Reinforcement learning with rubric anchors.arXiv preprint arXiv:2508.12790,
-
[9]
MaPPO: Maximum a Posteriori Preference Optimization with Prior Knowledge
Lan, G., Inan, H. A., Abdelnabi, S., Kulkarni, J., Wutschitz, L., Shokri, R., Brinton, C., and Sim, R. Contextual integrity in LLMs via reasoning and reinforcement learning. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems (NeurIPS), 2025a. Lan, G., Zhang, S., Wang, T., Zhang, Y ., Zhang, D., Wei, X., Pan, X., Zhang, H., Han, ...
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Li, C., Zhang, H., Xu, Y ., Xue, H., Ao, X., and He, Q. Gradient-adaptive policy optimization: Towards multi-objective alignment of large language models.arXiv preprint arXiv:2507.01915, 2025a. Li, T., Zhang, Y ., Yu, P., Saha, S., Khashabi, D., Weston, J., Lanchantin, J., and Wang, T. Jointly reinforcing diversity and quality in language model generation...
-
[11]
Lu, Y ., Wang, Z., Li, S., Liu, X., Yu, C., Yin, Q., Shi, Z., Zhang, Z., and Jiang, M. Learning to optimize multi-objective alignment through dynamic reward weighting.arXiv preprint arXiv:2509.11452,
- [12]
-
[13]
Proximal Policy Optimization Algorithms
12 Alternating Reinforcement Learning with Contextual Rubric Rewards Schulman, J., Wolski, F., Dhariwal, P., Radford, A., and Klimov, O. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Z., Ivison, H., Kishore, V ., Zhuo, J., Zhao, X., Park, M., Finlayson, S
Shao, R., Asai, A., Shen, S. Z., Ivison, H., Kishore, V ., Zhuo, J., Zhao, X., Park, M., Finlayson, S. G., Sontag, D., et al. DR Tulu: Reinforcement learning with evolving rubrics for deep research.arXiv preprint arXiv:2511.19399,
-
[15]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Shao, Z., Wang, P., Zhu, Q., Xu, R., Song, J., Bi, X., Zhang, H., Zhang, M., Li, Y ., Wu, Y ., et al. DeepSeekMath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
HybridFlow: A Flexible and Efficient RLHF Framework
Sheng, G., Zhang, C., Ye, Z., Wu, X., Zhang, W., Zhang, R., Peng, Y ., Lin, H., and Wu, C. HybridFlow: A flexible and efficient RLHF framework.arXiv preprint arXiv:2409.19256,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Wang, B., Lee, C., Lee, N., Lin, S.-C., Dai, W., Chen, Y ., Chen, Y ., Yang, Z., Liu, Z., Shoeybi, M., et al. Nemotron-Cascade: Scaling cascaded reinforcement learning for general-purpose reasoning models.arXiv preprint arXiv:2512.13607,
-
[18]
Xu, R., Liu, T., Dong, Z., You, T., Hong, I., Yang, C., Zhang, L., Zhao, T., and Wang, H. Alternating reinforcement learning for rubric-based reward modeling in non-verifiable LLM post-training.arXiv preprint arXiv:2602.01511,
-
[19]
Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Gao, C., Huang, C., Lv, C., et al. Qwen3 technical report. arXiv preprint arXiv:2505.09388,
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
M., Jeong, J., Veitch, V ., Wang, W., He, Y ., Liu, B., and Jin, L
Zhang, J., Wang, Z., Gui, L., Sathyendra, S. M., Jeong, J., Veitch, V ., Wang, W., He, Y ., Liu, B., and Jin, L. Chasing the tail: Effective rubric-based reward modeling for large language model post-training.arXiv preprint arXiv:2509.21500,
-
[21]
Group Sequence Policy Optimization
Zheng, C., Liu, S., Li, M., Chen, X.-H., Yu, B., Gao, C., Dang, K., Liu, Y ., Men, R., Yang, A., et al. Group sequence policy optimization.arXiv preprint arXiv:2507.18071,
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Zhou, Y ., Li, S., Liu, S., Fang, W., Zhang, K., Zhao, J., Yang, J., Zhou, Y ., Lv, J., Zheng, T., et al. Breaking the exploration bottleneck: Rubric-scaffolded reinforcement learning for general LLM reasoning.arXiv preprint arXiv:2508.16949,
-
[23]
I’m an emergency medicine physician
Prompt Meta-Class Criterion Points Total Points I’m a 39 year old female. I’m an emergency medicine physician. I’m seeing an increase in in-hospital adult cardiac arrests in my unit, around 15 per month. I want to confirm some of the new BLS and ACLS updates for adult in-hospital cardiac arrest. Specifically, I’d like the recommended compression depth cha...
work page 2023
-
[24]
Your job is to look at a conversation and criterions, and classify the criterion items (i.e., classify each criterion item into the given classes). # Conversation{conversation} # Criterion{criterions} # Classes {"accuracy", "completeness", "instruction following", "communication quality", "context awareness"} # Instructions Return a list object with the c...
work page 2023
-
[25]
You should classify each criterion into the given Classes and return a list like this: “‘list [ { “criterion”: “Correctly states that compression depth remains at 2-2.4 inches (5-6 cm) with no changes in the 2023 update.”, “points”: 10, “tags”: [ “axis:accuracy” ]}, { “criterion”: ”Cites standard epinephrine dosing of 1 mg IV/IO every 3-5 minutes (Class 1...
work page 2023
-
[26]
The results of Scalarized RL are in color black and Alternating RL in colorblue. Llama-3.1-8B-Instruct starts at 0.34 and achieves 0.70, while Qwen3-8B starts at a higher score0.58and achieves0.76. ARL-RR uniformly outperforms SRL-RR in both model series, and reduces time cost at the same time. Table 7.Evaluation results across different model series, whe...
work page 2025
-
[27]
The base model is Qwen3-8B. In ARL, we use the fixed meta-class Order 0: [completeness, accuracy, instruction following, context awareness, communication quality]. The results of Scalarized RL are in color black and Alternating RL in color blue. The performances are comparable across different RL algorithms, and ARL uniformly outperforms SRL. Table 8.Eval...
work page 2094
-
[28]
The precision format is bfloat16 for rollout, model parameter, and gradient, where the optimizer has the float32 precision. The maximum response length is set to 2048, and the temperature in LLM sampling is set to 1.0 in the training process. In the evaluation process, the temperature is set to 0 for the widely used pass@1 accuracy in the evaluation of RL...
work page 2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.