ChemDFM-R: A Chemical Reasoning LLM Enhanced with Atomized Chemical Knowledge
Pith reviewed 2026-05-19 03:26 UTC · model grok-4.3
The pith
Explicit functional group annotations in a new dataset let an LLM reason about chemistry at the level of top commercial models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
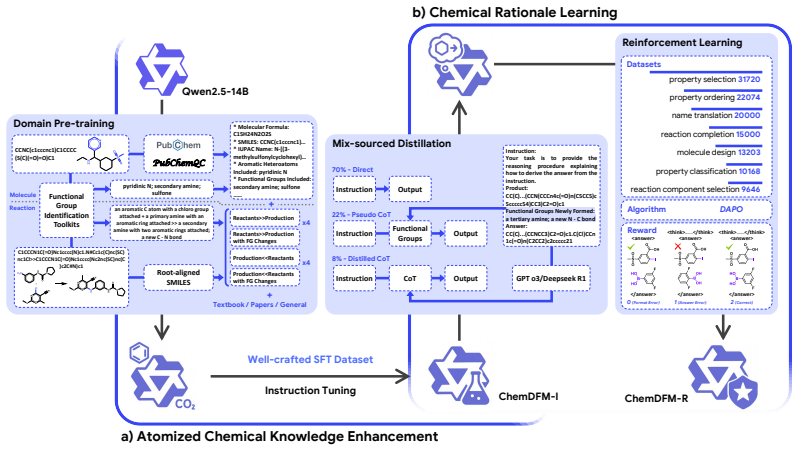
ChemDFM-R, constructed by first annotating functional groups and their transformations in the ChemFG dataset and then applying mixed-source distillation followed by a four-stage training pipeline, delivers cutting-edge results on diverse chemical benchmarks, generates interpretable rationale-driven outputs, outperforms both general-domain and domain-specific chemical LLMs, and reaches performance comparable or superior to frontier commercial models such as o4-mini.
What carries the argument
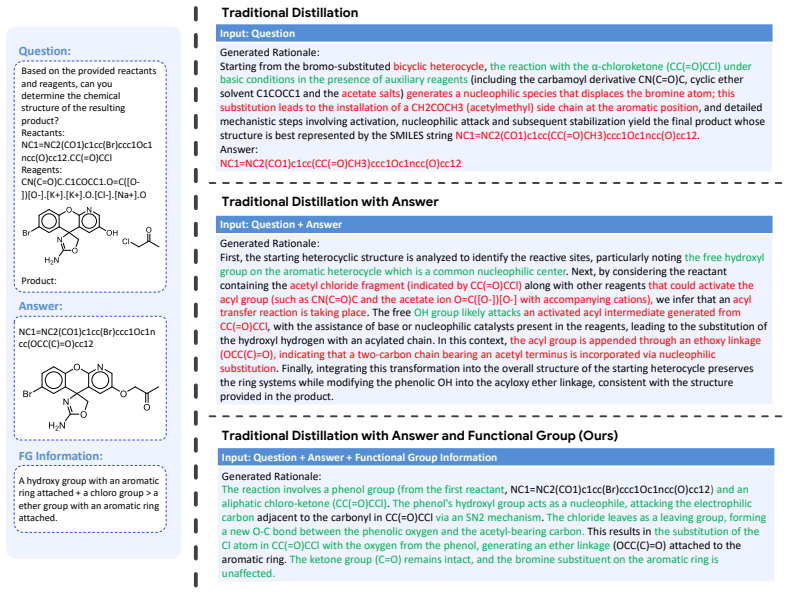
The ChemFG dataset that annotates the presence of functional groups in molecules and their changes during reactions, used inside a four-stage training pipeline that first initializes reasoning with distilled data and then injects atomized chemical knowledge.
If this is right
- The model produces explicit reasoning chains that increase reliability and transparency for human-AI collaboration in chemistry tasks.
- ChemDFM-R surpasses both general-domain LLMs and existing domain-specific chemical LLMs on standard benchmarks.
- Performance reaches or exceeds that of cutting-edge commercial LLMs such as o4-mini while remaining open and interpretable.
- The same atomized-knowledge approach can be extended to additional chemical reasoning problems beyond the tested benchmarks.
Where Pith is reading between the lines
- Similar explicit annotation of intermediate structures could improve reasoning in other data-sparse scientific domains such as materials or biology.
- The interpretability gains may reduce costly mistakes when the model is used to propose new reactions or molecules for laboratory validation.
- A controlled ablation removing only the functional-group layer while keeping data volume fixed would isolate whether the atomized format itself is the active ingredient.
Load-bearing premise
That the explicit functional-group annotations and the four-stage training pipeline create genuine gains in chemical reasoning rather than simply supplying more or better training data that any sufficiently large general model could also exploit.
What would settle it
Train an otherwise identical LLM on the same total volume of chemical text and reaction examples but without the functional-group annotations and check whether it matches ChemDFM-R on the same benchmarks while producing comparable reasoning chains.
Figures










read the original abstract
Atomized chemical knowledge, such as functional group information of molecules and reactions, plays a pivotal intermediate role in the reasoning process that connects molecular structures with their properties and reactivities. While large language models (LLMs) have achieved impressive progress, the absence of atomized chemical knowledge results in their superficial understanding of chemistry and limited chemical reasoning capabilities. In this work, to tackle this problem, we develop a Chemical Reasoning LLM, ChemDFM-R. We first construct a comprehensive dataset of atomized chemical knowledge, ChemFG, annotating the presence of functional groups in molecules and the changes of functional groups during chemical reactions, to enhance the model's understanding of the fundamental principles and internal logic of chemistry. Then, we propose a mixed-source distillation method that initializes the model's reasoning capability with limited distilled data, and develop a four-stage training pipeline to equip the model with atomized chemical knowledge and chemical reasoning logic. Experiments on diverse chemical benchmarks demonstrate that ChemDFM-R achieves cutting-edge performance while providing interpretable, rationale-driven outputs, surpassing both the general-domain LLMs and domain-specific chemical LLMs. Moreover, ChemDFM-R achieves comparable or superior performance compared with cutting-edge commercial LLMs, such as o4-mini. Further case studies illustrate how explicit reasoning chains significantly improve the model's reliability, transparency, and practicality in real-world human-AI collaboration scenarios.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces ChemDFM-R, a specialized LLM for chemical reasoning. It constructs the ChemFG dataset annotating functional groups in molecules and reactions, employs mixed-source distillation and a four-stage training pipeline to incorporate atomized chemical knowledge. The model is evaluated on diverse chemical benchmarks, claiming to surpass general-domain and domain-specific LLMs while achieving performance comparable to advanced commercial models like o4-mini, with interpretable rationale-driven outputs.
Significance. If the performance gains are attributable to the explicit incorporation of atomized chemical knowledge rather than data scaling effects, this work would represent a meaningful step toward more transparent and reliable AI systems for chemistry. It could facilitate better human-AI collaboration in chemical research by providing explicit reasoning chains.
major comments (2)
- [Experiments] Experiments section: The reported benchmark results claim superiority over baselines but provide no quantitative details on ChemFG dataset size, train/test splits, number of examples per benchmark, or statistical significance of improvements. This information is required to verify that gains are robust and not artifacts of evaluation setup.
- [Method] Four-stage training pipeline (Section 3): The central attribution of improved chemical reasoning to explicit functional-group annotations in ChemFG lacks supporting ablations. No experiments hold total training tokens or data quality fixed while removing or randomizing the functional-group labels, so it remains possible that observed gains reflect data volume or general chemical text quality rather than the atomized format.
minor comments (2)
- [Abstract] Abstract: Claims of 'cutting-edge performance' and comparability to o4-mini are stated without naming the specific benchmarks or reporting any numeric scores, reducing immediate clarity for readers.
- [Dataset Construction] Notation for functional-group changes during reactions could be formalized with a small example table to improve reproducibility of the ChemFG construction process.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the major comments point by point below and will revise the manuscript accordingly to improve transparency and rigor.
read point-by-point responses
-
Referee: [Experiments] Experiments section: The reported benchmark results claim superiority over baselines but provide no quantitative details on ChemFG dataset size, train/test splits, number of examples per benchmark, or statistical significance of improvements. This information is required to verify that gains are robust and not artifacts of evaluation setup.
Authors: We agree that these details are essential for reproducibility and assessing robustness. The current manuscript describes the ChemFG construction and benchmark evaluations at a high level but omits precise numbers. In the revision we will add: the total size of ChemFG (number of annotated molecules and reactions), the train/validation/test split ratios used during the four-stage pipeline, the exact number of examples per benchmark, and statistical significance (standard deviations across multiple runs or appropriate significance tests). revision: yes
-
Referee: [Method] Four-stage training pipeline (Section 3): The central attribution of improved chemical reasoning to explicit functional-group annotations in ChemFG lacks supporting ablations. No experiments hold total training tokens or data quality fixed while removing or randomizing the functional-group labels, so it remains possible that observed gains reflect data volume or general chemical text quality rather than the atomized format.
Authors: This is a fair criticism. Our design uses mixed-source distillation followed by progressive stages that explicitly target functional-group recognition and reaction logic, and the largest gains appear on chemistry-specific tasks. However, we did not run the precise controlled ablation that holds token count and data quality fixed while randomizing labels. We will expand Section 3 to provide a stronger methodological justification and, if computationally feasible, include a limited ablation study or at minimum a discussion of this limitation and planned future controls. revision: partial
Circularity Check
No circularity: empirical training pipeline with external benchmarks
full rationale
The paper constructs the ChemFG dataset with functional-group annotations and applies a four-stage training pipeline, then evaluates on external chemical benchmarks. No mathematical derivation, first-principles result, or prediction is claimed that reduces by construction to fitted parameters or self-citations. Performance claims rest on held-out benchmark scores rather than any internal equivalence between inputs and outputs. The work is therefore self-contained against external evaluation and exhibits no load-bearing circular steps of the enumerated kinds.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Functional groups are a sufficient and interpretable intermediate representation that connects molecular structure to properties and reactivity.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We develop a toolkit to identify the functional groups of molecules and the changes of functional groups during reactions... constructed a 101 billion-token domain pretraining corpus, named ChemFG, featuring atomized functional-group-level knowledge in chemistry.
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanalpha_pin_under_high_calibration unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
four-stage training pipeline... mix-sourced distillation... domain-specific reinforcement learning
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 2 Pith papers
-
MolDeTox: Evaluating Language Model's Stepwise Fragment Editing for Molecular Detoxification
MolDeTox is a new benchmark that shows fragment-level stepwise editing by LLMs and VLMs improves structural validity and detoxification quality over prior toxicity-focused evaluations.
-
Mol-Debate: Multi-Agent Debate Improves Structural Reasoning in Molecular Design
Mol-Debate applies multi-agent debate in an iterative loop with perspective orchestration to achieve state-of-the-art text-guided molecular design, scoring 59.82% exact match on ChEBI-20 and 50.52% weighted success on...
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report. arXiv preprint arXiv:2303.08774,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Language models are few-shot learners
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. Advances in neural information processing systems , 33:1877–1901,
work page 1901
-
[3]
Evaluating Large Language Models Trained on Code
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde De Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities. arXiv preprint arXiv:2507.06261,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Shihan Dou, Yan Liu, Haoxiang Jia, Limao Xiong, Enyu Zhou, Wei Shen, Junjie Shan, Caishuang Huang, Xiao Wang, Xiaoran Fan, et al. Stepcoder: Improve code generation with reinforcement learning from compiler feedback. arXiv preprint arXiv:2402.01391,
-
[6]
URL https://openreview.net/pdf?id= Tlsdsb6l9n. Kehua Feng, Keyan Ding, Weijie Wang, Xiang Zhuang, Zeyuan Wang, Ming Qin, Yu Zhao, Jianhua Yao, Qiang Zhang, and Huajun Chen. Sciknoweval: Evaluating multi-level scientific knowledge of large language models. arXiv preprint arXiv:2406.09098,
-
[7]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Measuring Massive Multitask Language Understanding
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding. arXiv preprint arXiv:2009.03300,
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[9]
Chemeval: a comprehensive multi-level chemical evaluation for large language models
Yuqing Huang, Rongyang Zhang, Xuesong He, Xuyang Zhi, Hao Wang, Xin Li, Feiyang Xu, Deguang Liu, Huadong Liang, Yi Li, et al. Chemeval: a comprehensive multi-level chemical evaluation for large language models. arXiv preprint arXiv:2409.13989,
-
[10]
Binyuan Hui, Jian Yang, Zeyu Cui, Jiaxi Yang, Dayiheng Liu, Lei Zhang, Tianyu Liu, Jiajun Zhang, Bowen Yu, Keming Lu, et al. Qwen2. 5-coder technical report. arXiv preprint arXiv:2409.12186,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Os- trow, Akila Welihinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card. arXiv preprint arXiv:2410.21276,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Aaron Jaech, Adam Kalai, Adam Lerer, Adam Richardson, Ahmed El-Kishky, Aiden Low, Alec Helyar, Aleksander Madry, Alex Beutel, Alex Carney, et al. Openai o1 system card. arXiv preprint arXiv:2412.16720,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
A survey on speech large language models
URL https://arxiv.org/abs/2410.18908. Nadine Schneider, Nikolaus Stiefl, and Gregory A Landrum. What’s what: The (nearly) definitive guide to reaction role assignment. Journal of chemical information and modeling , 56(12):2336– 2346,
-
[14]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathemat- ical reasoning in open language models. arXiv preprint arXiv:2402.03300,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Chemmllm: Chemical multimodal large language model
Qian Tan, Dongzhan Zhou, Peng Xia, Wanhao Liu, Wanli Ouyang, Lei Bai, Yuqiang Li, and Tianfan Fu. Chemmllm: Chemical multimodal large language model. arXiv preprint arXiv:2505.16326,
-
[16]
Galactica: A Large Language Model for Science
Ross Taylor, Marcin Kardas, Guillem Cucurull, Thomas Scialom, Anthony Hartshorn, Elvis Saravia, Andrew Poulton, Viktor Kerkez, and Robert Stojnic. Galactica: A large language model for science. arXiv preprint arXiv:2211.09085,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Gemini: A Family of Highly Capable Multimodal Models
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie Millican, et al. Gemini: a family of highly capable multimodal models. arXiv preprint arXiv:2312.11805,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Kimi Team, Angang Du, Bofei Gao, Bowei Xing, Changjiu Jiang, Cheng Chen, Cheng Li, Chenjun Xiao, Chenzhuang Du, Chonghua Liao, et al. Kimi k1. 5: Scaling reinforcement learning with llms. arXiv preprint arXiv:2501.12599,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
URL https://arxiv.org/abs/2405.09939. Yubo Wang, Xueguang Ma, Ge Zhang, Yuansheng Ni, Abhranil Chandra, Shiguang Guo, Weiming Ren, Aaran Arulraj, Xuan He, Ziyan Jiang, et al. Mmlu-pro: A more robust and challenging multi- task language understanding benchmark. Advances in Neural Information Processing Systems , 37: 95266–95290,
-
[20]
2023, arXiv e-prints, arXiv:2308.13565, 10.48550/arXiv.2308.13565
Tong Xie, Yuwei Wan, Wei Huang, Zhenyu Yin, Yixuan Liu, Shaozhou Wang, Qingyuan Linghu, Chunyu Kit, Clara Grazian, Wenjie Zhang, et al. Darwin series: Domain specific large language models for natural science. arXiv preprint arXiv:2308.13565,
-
[21]
An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, et al. Qwen2. 5 technical report. arXiv preprint arXiv:2412.15115, 2024a. An Yang, Beichen Zhang, Binyuan Hui, Bofei Gao, Bowen Yu, Chengpeng Li, Dayiheng Liu, Jian- hong Tu, Jingren Zhou, Junyang Lin, et al. Qwen2. 5-math technical re...
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
N.; Chen, Z.; Ning, X.; Sun, H
Botao Yu, Frazier N Baker, Ziqi Chen, Xia Ning, and Huan Sun. Llasmol: Advancing large language models for chemistry with a large-scale, comprehensive, high-quality instruction tuning dataset. arXiv preprint arXiv:2402.09391,
-
[23]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, et al. Dapo: An open-source llm reinforcement learning system at scale. arXiv preprint arXiv:2503.14476,
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
Chemllm: A chemical large language model
14 Di Zhang, Wei Liu, Qian Tan, Jingdan Chen, Hang Yan, Yuliang Yan, Jiatong Li, Weiran Huang, Xiangyu Yue, Wanli Ouyang, et al. Chemllm: A chemical large language model. arXiv preprint arXiv:2402.06852, 2024a. Situo Zhang, Hanqi Li, Lu Chen, Zihan Zhao, Xuanze Lin, Zichen Zhu, Bo Chen, Xin Chen, and Kai Yu. Reasoning-driven retrosynthesis prediction with...
-
[25]
DeepSeek-Coder-V2: Breaking the Barrier of Closed-Source Models in Code Intelligence
Qihao Zhu, Daya Guo, Zhihong Shao, Dejian Yang, Peiyi Wang, Runxin Xu, Y Wu, Yukun Li, Huazuo Gao, Shirong Ma, et al. Deepseek-coder-v2: Breaking the barrier of closed-source models in code intelligence. arXiv preprint arXiv:2406.11931,
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
The data is constructed from PubChem5
B.1.1 Molecule-Centric Tasks • Name Translation: The name translation between SMILES, IUPAC name, and molecular formula. The data is constructed from PubChem5. • Description Generation: The molecule description task is to describe the molecule given its SMILES. The data is constructed from PubChem. We only use the high-quality descriptions that contain mo...
work page 2018
-
[27]
In Figure 9, with only the question, o3-mini can hardly generate any useful rational. The rational merely repeats the IUPAC components mentioned in the question before rushing to a highly inaccurate conclusion without substantive analysis. When given the ground truth answer, o3-mini can construct a reasonably good rationale with minimal factual error. How...
work page 2025
-
[28]
As illustrated in Table 4, ChemDFM-R achieves competitive performance on SciKnowEval compared to cutting-edge LLMs. It is worth noting that ChemDFM-R’s performance advantage is less pro- nounced on SciKnowEval than on ChemEval. This is primarily because most tasks in SciKnowEval are formulated as multiple-choice questions, which substantially reduce the b...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.