GoViG: Goal-Conditioned Visual Navigation Instruction Generation via Multimodal Reasoning
Pith reviewed 2026-05-18 22:58 UTC · model grok-4.3
The pith
A multimodal language model generates navigation instructions by first predicting intermediate visual states between egocentric start and goal images.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By training an autoregressive multimodal LLM to jointly predict intermediate visual states that bridge initial and goal egocentric views and then synthesize instructions grounded in those states, the method produces spatially accurate and linguistically clear navigation directions without any structured inputs such as maps or annotations, yielding higher BLEU-4 and CIDEr scores and stronger cross-domain generalization than prior approaches.
What carries the argument
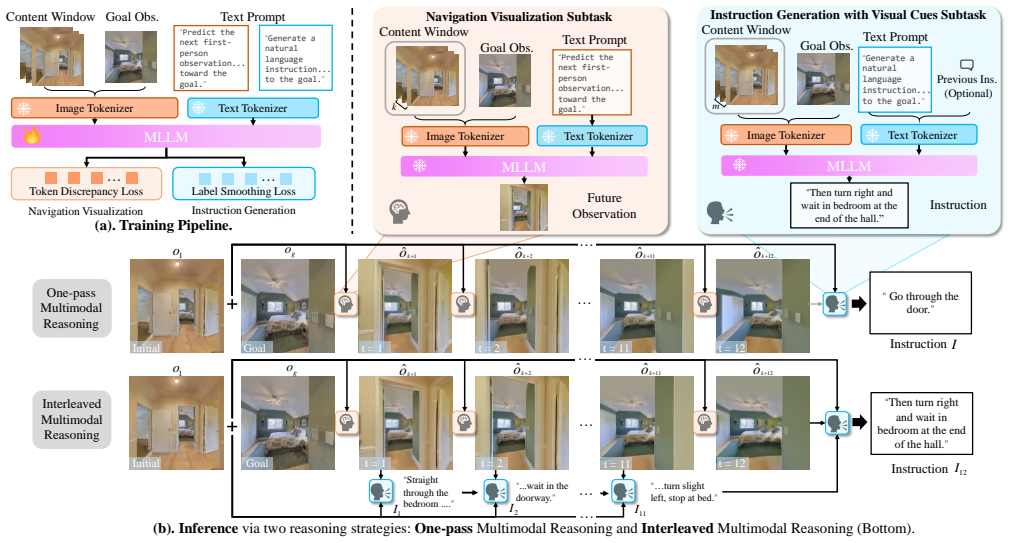
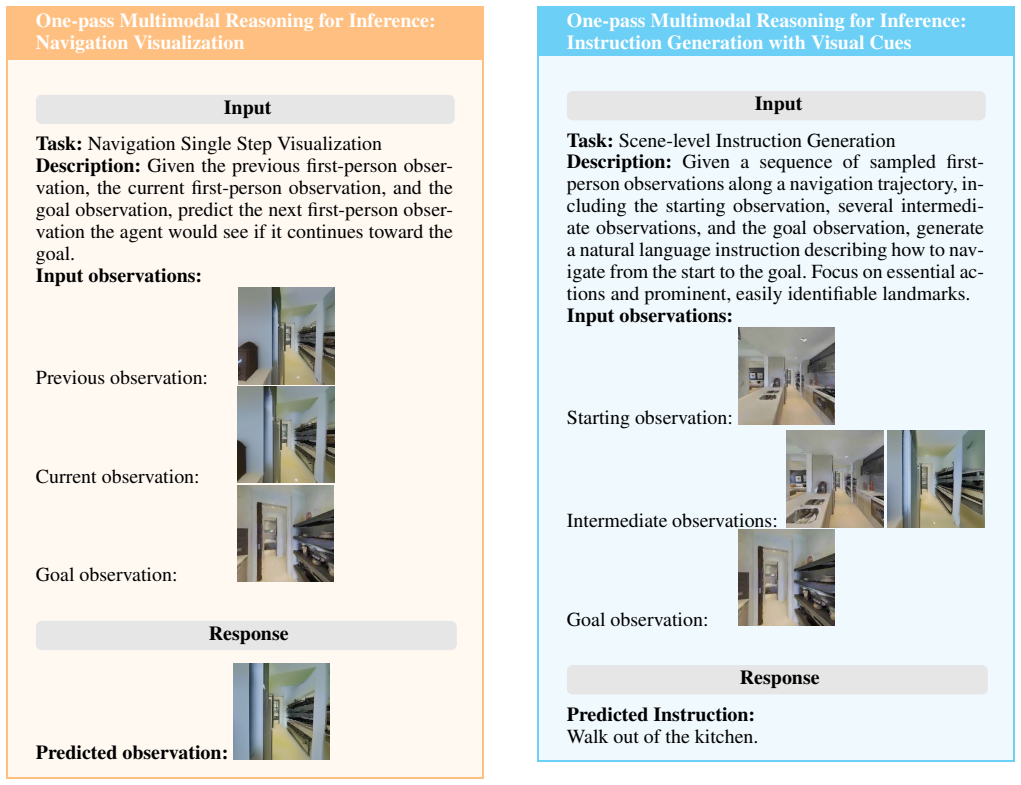
An autoregressive multimodal LLM that performs navigation visualization of intermediate states and instruction generation together, guided by one-pass and interleaved multimodal reasoning strategies.
If this is right
- Enables instruction generation in environments lacking maps or semantic annotations.
- Delivers measurable gains in BLEU-4 and CIDEr over existing methods on the R2R-Goal dataset.
- Maintains performance when moving between synthetic and real-world visual domains.
- Supports incremental, human-like reasoning by alternating visual prediction and language output.
Where Pith is reading between the lines
- The visual-state prediction step could be reused for online path correction when an agent encounters unexpected obstacles.
- Removing map requirements may lower the cost of deploying navigation agents in new buildings or outdoor areas.
- Accuracy of the intermediate visuals could be checked directly by comparing predicted frames against actual camera footage collected along the same route.
Load-bearing premise
Predicting intermediate visual states directly from raw egocentric images of the initial and goal views will produce spatially accurate and coherent navigation instructions.
What would settle it
Run the generated instructions in a navigation simulator or with a real agent and measure goal-reaching success rate; rates no higher than strong baselines that use maps would falsify the central claim.
Figures








read the original abstract
We introduce Goal-Conditioned Visual Navigation Instruction Generation (GoViG), a new task that aims to generate contextually coherent navigation instructions solely from egocentric visual observations of initial and goal states. Unlike prior work relying on structured inputs, such as semantic annotations or environmental maps, GoViG exclusively leverages raw egocentric visual data, improving adaptability to unseen and unstructured environments. Our method addresses this task by decomposing it into two interconnected subtasks: (1) navigation visualization, predicting intermediate visual states bridging the initial and goal views; and (2) instruction generation, synthesizing coherent instructions grounded in observed and anticipated visuals. Both subtasks are integrated within an autoregressive multimodal LLM trained with tailored objectives to ensure spatial accuracy and linguistic clarity. Furthermore, we introduce two multimodal reasoning strategies, one-pass and interleaved reasoning, to mimic incremental human navigation cognition. To comprehensively evaluate our method, we propose the R2R-Goal dataset, combining diverse synthetic and real-world trajectories. Empirical results demonstrate significant performance improvements over state-of-the-art methods in BLEU-4 and CIDEr scores along with robust cross-domain generalization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the GoViG task for generating contextually coherent navigation instructions solely from raw egocentric images of initial and goal states, without maps or semantic annotations. The proposed method decomposes the problem into navigation visualization (autoregressive prediction of intermediate egocentric frames) and instruction generation within a single multimodal LLM, using tailored objectives and two reasoning strategies (one-pass and interleaved). A new R2R-Goal dataset is presented combining synthetic and real-world trajectories, with empirical claims of improved BLEU-4 and CIDEr scores plus cross-domain generalization over prior methods.
Significance. If the results hold, this could meaningfully advance goal-conditioned visual navigation in unstructured environments by eliminating the need for structured inputs. The dataset contribution and the integration of visual state prediction with multimodal reasoning in one model are clear strengths. The approach offers a plausible path toward more adaptable systems, though its impact hinges on demonstrating that the generated instructions correspond to feasible trajectories.
major comments (2)
- [§3] §3 (Navigation Visualization): The autoregressive prediction of bridging egocentric frames from raw initial/goal images incorporates no explicit geometric, pose, or collision constraints. This directly bears on the central claim that the method produces spatially accurate instructions without maps or annotations, as visual plausibility alone does not guarantee metric consistency or feasible 3D paths.
- [§5] §5 (Empirical Evaluation): The reported gains on BLEU-4 and CIDEr are presented without error bars, statistical significance tests, ablation studies on the reasoning strategies or objectives, or details on dataset splits and post-hoc choices. These omissions undermine assessment of whether the improvements and cross-domain generalization are robust.
minor comments (2)
- [Abstract] Abstract: The phrase 'significant performance improvements' would be more informative if accompanied by the actual delta values on BLEU-4 and CIDEr.
- [§4] §4 (Reasoning Strategies): The distinction between one-pass and interleaved reasoning would benefit from a concrete example or diagram illustrating the token interleaving process.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We address each major comment below and describe the revisions we will incorporate to strengthen the manuscript.
read point-by-point responses
-
Referee: [§3] §3 (Navigation Visualization): The autoregressive prediction of bridging egocentric frames from raw initial/goal images incorporates no explicit geometric, pose, or collision constraints. This directly bears on the central claim that the method produces spatially accurate instructions without maps or annotations, as visual plausibility alone does not guarantee metric consistency or feasible 3D paths.
Authors: We acknowledge that the navigation visualization component does not incorporate explicit geometric, pose, or collision constraints and instead relies on the autoregressive multimodal LLM to implicitly learn spatial relationships from paired trajectory data. This design choice is intentional to maintain the method's reliance on raw visual inputs alone. To address the concern regarding metric consistency, we will revise §3 to include an expanded discussion of this limitation and add qualitative analysis showing alignment between predicted intermediate frames and feasible navigation paths in the R2R-Goal dataset. revision: partial
-
Referee: [§5] §5 (Empirical Evaluation): The reported gains on BLEU-4 and CIDEr are presented without error bars, statistical significance tests, ablation studies on the reasoning strategies or objectives, or details on dataset splits and post-hoc choices. These omissions undermine assessment of whether the improvements and cross-domain generalization are robust.
Authors: We agree that additional statistical analysis and transparency are needed to robustly support the reported improvements. In the revised manuscript, we will include error bars computed over multiple runs, perform statistical significance tests on the BLEU-4 and CIDEr gains, add ablation studies evaluating the one-pass versus interleaved reasoning strategies and the tailored objectives, and provide clearer details on dataset splits along with any post-hoc decisions made during evaluation. revision: yes
Circularity Check
No significant circularity; method and results are independent of inputs by construction.
full rationale
The paper proposes a new task (GoViG) and decomposes it into navigation visualization plus instruction generation inside a standard autoregressive multimodal LLM trained with tailored objectives and one-pass/interleaved reasoning. No equations or steps reduce a claimed prediction to a fitted parameter by definition, nor does any load-bearing premise rest on a self-citation chain whose prior result is itself unverified. The reported BLEU-4/CIDEr gains and cross-domain generalization are presented as empirical outcomes of the architecture on the new R2R-Goal dataset; they are not forced by renaming or self-definition. The absence of maps/annotations is an explicit design choice whose validity is tested externally rather than assumed via circular reasoning.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
GIST: Multimodal Knowledge Extraction and Spatial Grounding via Intelligent Semantic Topology
GIST extracts a semantically annotated 2D navigation topology from consumer mobile point clouds to improve spatial grounding for embodied AI in dense environments.
Reference graph
Works this paper leans on
-
[1]
Qwen2. 5-vl technical report. arXiv preprint arXiv:2502.13923. Banerjee, S.; and Lavie, A
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
See, think, confirm: Interactive prompting between vision and language models for knowledge-based visual rea- soning. arXiv preprint arXiv:2301.05226. Chern, E.; Su, J.; Ma, Y .; and Liu, P
-
[3]
arXiv preprint arXiv:2407.06135
Anole: An open, autoregressive, native large multimodal mod- els for interleaved image-text generation. arXiv preprint arXiv:2407.06135. Comanici, G.; Bieber, E.; Schaekermann, M.; Pasupat, I.; Sachdeva, N.; Dhillon, I.; Blistein, M.; Ram, O.; Zhang, D.; Rosen, E.; et al
-
[4]
Gemini 2.5: Pushing the fron- tier with advanced reasoning, multimodality, long context, and next generation agentic capabilities. arXiv preprint arXiv:2507.06261. Cui, Y .; Xie, L.; Zhao, Y .; Sun, J.; and Yin, E
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Gener- ating Vision-Language Navigation Instructions Incorporated Fine-Grained Alignment Annotations. arXiv:2506.08566. Dong, Y .; Wu, F.; He, Q.; Li, H.; Li, M.; Cheng, Z.; Zhou, Y .; Sun, J.; Dai, Q.; Cheng, Z.-Q.; et al
-
[6]
arXiv preprint arXiv:2503.14229
HA-VLN: A Benchmark for Human-Aware Navigation in Discrete- Continuous Environments with Dynamic Multi-Human In- teractions, Real-World Validation, and an Open Leader- board. arXiv preprint arXiv:2503.14229. Fan, S.; Liu, R.; Wang, W.; and Yang, Y
-
[7]
Speaker-Follower Models for Vision-and-Language Navigation
Speaker-Follower Models for Vision- and-Language Navigation. arXiv:1806.02724. Fu, S.; Tamir, N.; Sundaram, S.; Chai, L.; Zhang, R.; Dekel, T.; and Isola, P
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Dreamsim: Learning new dimen- sions of human visual similarity using synthetic data. arXiv preprint arXiv:2306.09344. Google
-
[9]
arXiv preprint arXiv:2409.05583
Spatially-aware speaker for vision-and- language navigation instruction generation. arXiv preprint arXiv:2409.05583. Henschel, R.; Khachatryan, L.; Hayrapetyan, D.; Poghosyan, H.; Tadevosyan, V .; Wang, Z.; Navasardyan, S.; and Shi, H
-
[10]
Streamingt2v: Consistent, dynamic, and extendable long video generation from text. arXiv preprint arXiv:2403.14773. Hirose, N.; Sadeghian, A.; V ´azquez, M.; Goebel, P.; and Savarese, S
-
[11]
In 2018 IEEE/RSJ international conference on intelligent robots and systems (IROS), 3044–3051
Gonet: A semi-supervised deep learning approach for traversability estimation. In 2018 IEEE/RSJ international conference on intelligent robots and systems (IROS), 3044–3051. IEEE. Hirose, N.; Shah, D.; Sridhar, A.; and Levine, S
work page 2018
-
[12]
CogVideo: Large-scale Pretraining for Text-to-Video Generation via Transformers
Cogvideo: Large-scale pretraining for text-to-video genera- tion via transformers. arXiv preprint arXiv:2205.15868. Hore, A.; and Ziou, D
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Image quality metrics: PSNR vs. SSIM. In 2010 20th international conference on pattern recognition, 2366–2369. IEEE. Hu, E. J.; Shen, Y .; Wallis, P.; Allen-Zhu, Z.; Li, Y .; Wang, S.; Wang, L.; Chen, W.; et al
work page 2010
-
[14]
Gpt-4o system card. arXiv preprint arXiv:2410.21276. Kong, X.; Chen, J.; Wang, W.; Su, H.; Hu, X.; Yang, Y .; and Liu, S
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Imagine while Reasoning in Space: Multimodal Visualization-of-Thought
Imagine while reasoning in space: Multimodal visualization-of-thought. arXiv preprint arXiv:2501.07542. Li, H.; Li, M.; Cheng, Z.-Q.; Dong, Y .; Zhou, Y .; He, J.-Y .; Dai, Q.; Mitamura, T.; and Hauptmann, A. G
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
VideoChat: Chat-Centric Video Understanding
Human- aware vision-and-language navigation: Bridging simulation to reality with dynamic human interactions. Advances in Neural Information Processing Systems , 37: 119411– 119442. Li, J.; Li, D.; Savarese, S.; and Hoi, S. 2023a. Blip-2: Bootstrapping language-image pre-training with frozen im- age encoders and large language models. In International conf...
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Rapid exploration for open-world navigation with latent goal models,
Rapid exploration for open-world navigation with latent goal models. arXiv preprint arXiv:2104.05859. Shao, H.; Qian, S.; Xiao, H.; Song, G.; Zong, Z.; Wang, L.; Liu, Y .; and Li, H
-
[18]
Learning to Navigate Unseen Environments: Back Translation with Environmen- tal Dropout. In Burstein, J.; Doran, C.; and Solorio, T., eds., Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, V olume 1 (Long and Short Papers), 2610–2621. Minneapolis, Minnesota: Ass...
work page 2019
-
[19]
Chameleon: Mixed-Modal Early-Fusion Foundation Models
Chameleon: Mixed-modal early-fusion foundation models. arXiv preprint arXiv:2405.09818. Vanetti, E. J.; and Allen, G. L
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
In Proceedings of the IEEE conference on computer vision and pattern recognition, 4566–4575
Cider: Consensus-based image description evaluation. In Proceedings of the IEEE conference on computer vision and pattern recognition, 4566–4575. Wang, H.; Liang, W.; Shen, J.; Van Gool, L.; and Wang, W. 2022a. Counterfactual Cycle-Consistent Learning for Instruction Following and Generation in Vision-Language Navigation. In 2022 IEEE/CVF Conference on Co...
work page 2022
-
[21]
Lana: A Language-Capable Navigator for Instruction Following and Generation. arXiv:2303.08409. Wang, X.; Wang, W.; Shao, J.; and Yang, Y
-
[22]
Image quality assessment: from error visibility to structural similarity. IEEE Transactions on Image Processing , 13(4): 600–612. Wang, Z.; Li, J.; Hong, Y .; Li, S.; Li, K.; Yu, S.; Wang, Y .; Qiao, Y .; Wang, Y .; Bansal, M.; and Wang, L. 2025a. Boot- strapping Language-Guided Navigation Learning with Self- Refining Data Flywheel. arXiv:2412.08467. Wang...
-
[23]
arXiv preprint arXiv:2410.04521
Mc-cot: A modular collabora- tive cot framework for zero-shot medical-vqa with llm and mllm integration. arXiv preprint arXiv:2410.04521. Wu, W.; Mao, S.; Zhang, Y .; Xia, Y .; Dong, L.; Cui, L.; and Wei, F
-
[24]
InstruGen: Automatic Instruction Generation for Vision- and-Language Navigation Via Large Multimodal Models. arXiv:2411.11394. Yang, Z.; Li, L.; Lin, K.; Wang, J.; Lin, C.-C.; Liu, Z.; and Wang, L. 2023a. The Dawn of LMMs: Preliminary Explo- rations with GPT-4V(ision). arXiv:2309.17421. Yang, Z.; Li, L.; Wang, J.; Lin, K.; Azarnasab, E.; Ahmed, F.; Liu, Z...
-
[25]
Kefa: A Knowledge Enhanced and Fine-grained Aligned Speaker for Navigation Instruction Generation. arXiv:2307.13368. Zhang, R.; Isola, P.; Efros, A. A.; Shechtman, E.; and Wang, O
-
[26]
Vision-and-language navigation today and tomorrow: A survey in the era of foundation models
Vision-and- language navigation today and tomorrow: A survey in the era of foundation models. arXiv preprint arXiv:2407.07035. Zhang, Z.; Zhang, A.; Li, M.; Zhao, H.; Karypis, G.; and Smola, A
-
[27]
Multimodal Chain-of-Thought Reasoning in Language Models
Multimodal chain-of-thought reasoning in language models. arXiv preprint arXiv:2302.00923. Zhao, Q.; Wang, S.; Zhang, C.; Fu, C.; Do, M. Q.; Agar- wal, N.; Lee, K.; and Sun, C
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
Antgpt: Can large language models help long-term action anticipation from videos?
Antgpt: Can large language models help long-term action anticipation from videos? arXiv preprint arXiv:2307.16368. Zhao, Y .; Wang, S.; and Li, J
-
[29]
LaF-GRPO: In-Situ Navigation Instruction Generation for the Visu- ally Impaired via GRPO with LLM-as-Follower Reward. arXiv:2506.04070. Zhou, Q.; Zhou, R.; Hu, Z.; Lu, P.; Gao, S.; and Zhang, Y
-
[30]
Image-of-thought prompting for visual reason- ing refinement in multimodal large language models. arXiv preprint arXiv:2405.13872. A More Related Work Table 7 categorizes prior work along five orthogonal axes: (i) viewpoint ( ego-centric vs. panoramic); (ii) reliance on privileged inputs (e.g., orientation, GPS, environment la- bels); (iii) pre-processing...
-
[31]
and LANA+ (Wang et al. 2024), retain the panoramic setting but incorporate orienta- tion priors and stronger sequence modeling. LANA+ further introduces CLIP-based landmark spotting as an explicit pre- processing signal, improving visual grounding while still as- suming privileged panoramic inputs. Recently, LLM-integrated “instructor” approaches have bro...
work page 2024
-
[32]
Retrieval- and map-centric vari- ants—NavRAG (Wang et al
moves toward an ego-centric perspective but still depends on multi-view im- agery, 3D bounding boxes, and BEV/action-map encodings orchestrated by an MLLM. Retrieval- and map-centric vari- ants—NavRAG (Wang et al. 2025b) and MapInstructor (Fan et al. 2025)—leverage navigable positions, panoramic im- agery, GPS, and scene maps to construct hierarchical str...
work page 2025
-
[33]
benchmarks. An A*-based heuristic search identifies the shortest feasible navigation path, with dy- namic re-planning triggered in real time upon encounter- ing unexpected obstacles. An egocentric camera mounted on the simulated agent continuously captures observations along each traversed path. Scene-level segmentation is per- formed in two stages using ...
work page 2025
-
[34]
plementary strengths across multimodal navigation tasks. C Experiments Details Evaluation Metrics We evaluate overall system performance using two comple- mentary categories of metrics: (1) Instruction Quality: Linguistic fidelity is compre- hensively assessed for both goal-conditioned and visu- ally grounded instruction generation using widely adopted te...
work page 2002
-
[35]
2004), PSNR (Hore and Ziou 2010), LPIPS (Zhang et al
SSIM (Wang et al. 2004), PSNR (Hore and Ziou 2010), LPIPS (Zhang et al. 2018), and DreamSim (Fu et al. 2023). The latter two are deep perceptual metrics specifically de- signed to more closely approximate human judgments. LPIPS: The Learned Perceptual Image Patch Similar- ity (Zhang et al
work page 2004
-
[36]
by extracting its instruction generation module. The original work takes nav- igation routes (panoramic observations and actions) as input and generates natural language instructions as output, using a unified architecture with shared route/language encoders and cross-attention based decoders for bidirectional transla- tion, jointly trained on both instru...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.