Towards Operational Validation of LLM-Agent Social Simulations: A Replicated Study of a Reddit-like Technology Forum
Pith reviewed 2026-05-18 20:10 UTC · model grok-4.3
The pith
LLM agents in faithful forum simulations match real activity and topics but diverge on toxicity and interactions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
LLM agents in platform-faithful environments can reproduce familiar online regularities, while systematic divergences, particularly those linked to stateless agent design and content-layer calibration, point to concrete directions for future improvement.
What carries the argument
Multi-run operational validation across activity patterns, network structure, toxicity, topical coverage, and stylistic convergence, measured by direct statistical comparison of thirty simulated runs against thirty matched real Voat data windows.
If this is right
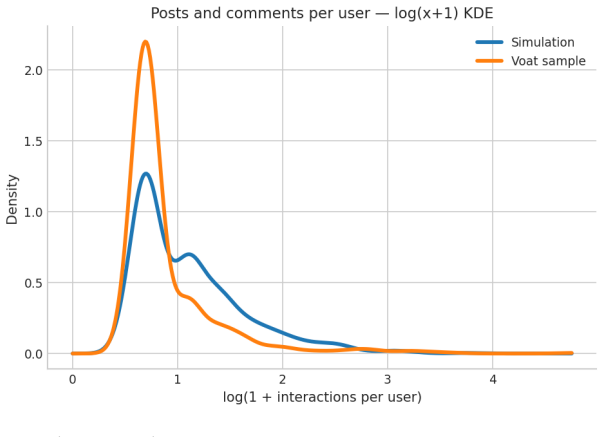
- Basic engagement metrics such as unique users, root posts, and daily active users fall inside overlapping 99 percent confidence intervals with real forum data.
- Topical coverage aligns near-completely between simulated and real content.
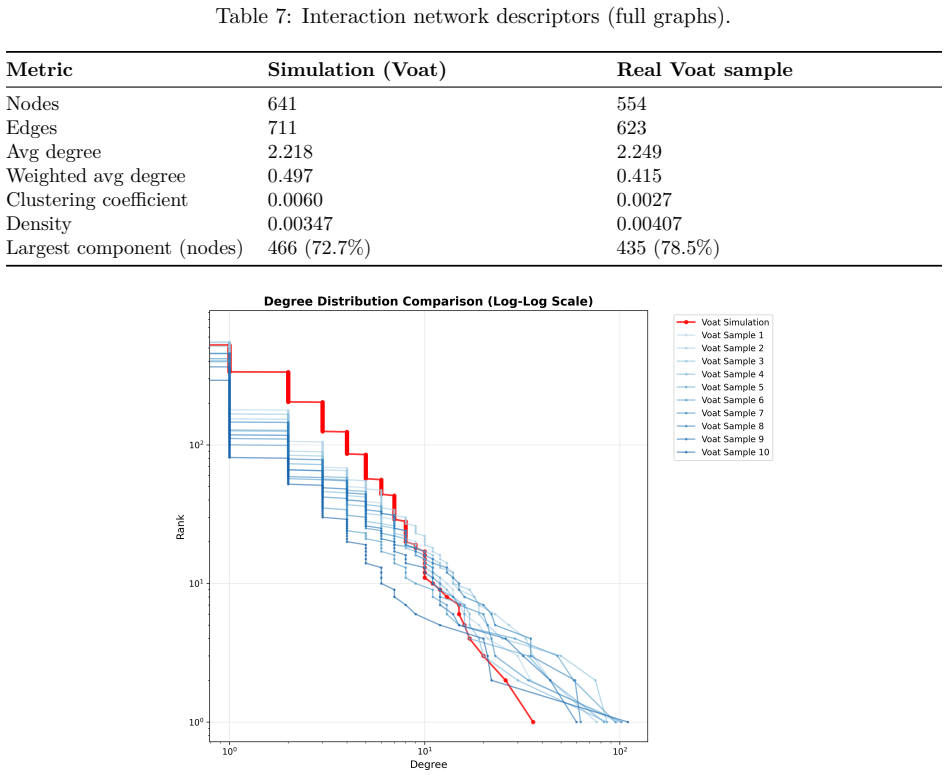
- Both simulated and real networks display core-periphery structure, yet simulated cores are larger, more diffuse, and show fewer repeated user interactions.
- Toxicity is misallocated across layers, with simulated root posts substantially more toxic and simulated comments less toxic than their real counterparts.
- The observed patterns identify stateless design and content-layer calibration as specific targets for improving future LLM-agent simulations.
Where Pith is reading between the lines
- Making agents stateful or giving them memory of past interactions could increase repeated user pairs to better match real forum behavior.
- Separate toxicity parameters for submissions and comments might correct the misallocation without affecting overall topic or activity matches.
- The same multi-run validation protocol could be applied to other platforms such as Reddit or Twitter to test whether the same divergence patterns appear.
- Varying simulation parameters like agent population size or run length offers a direct way to test whether comment volume and thread length can be aligned more closely.
Load-bearing premise
The Y Social platform and stateless Dolphin Mistral 24B configuration faithfully capture the interaction dynamics of the real Voat forum without introducing major artifacts from the simulation architecture itself.
What would settle it
A follow-up experiment that introduces agent state or memory and recalibrates toxicity separately for root posts versus comments, then shows the divergences in toxicity allocation and repeated interactions disappear while other matches remain.
Figures





read the original abstract
Validation of LLM-agent social simulations remains underdeveloped, with most studies relying on subjective assessments or single runs. We address this gap by running 30 independent 30-day simulations of a technology forum modeled on Voat's v/technology, using stateless Dolphin Mistral 24B agents on the Y Social platform, and evaluating operational validity across five dimensions: activity patterns, network structure, toxicity, topical coverage, and stylistic convergence. Against 30 matched, non-overlapping 30-day Voat comparison windows, results show overlapping 99% confidence intervals for unique users, root posts, and daily active users, while comments, average thread length, and mean toxicity remain higher in simulation. Both simulated and empirical networks exhibit core-periphery structure, though simulated cores are larger and more diffuse and repeated interactions are less frequent. Topic alignment is near-complete, but toxicity is misallocated across content layers: simulated root posts are substantially more toxic than real submissions, while simulated comments are less toxic than Voat comments. These findings demonstrate that LLM agents in platform-faithful environments can reproduce familiar online regularities, while systematic divergences, particularly those linked to stateless agent design and content-layer calibration, point to concrete directions for future improvement.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper reports a replicated validation study of LLM-agent social simulations for a technology forum modeled on Voat's v/technology. It runs 30 independent 30-day simulations using stateless Dolphin Mistral 24B agents on the Y Social platform and compares five operational dimensions—activity patterns, network structure, toxicity, topical coverage, and stylistic convergence—against 30 matched, non-overlapping real Voat 30-day windows. Results indicate overlapping 99% CIs for unique users, root posts, and daily active users; higher comment volume, average thread length, and mean toxicity in simulation; core-periphery structure in both but with larger, more diffuse cores and fewer repeated interactions in the simulated networks; near-complete topic alignment; and toxicity misallocated across layers (higher in simulated root posts, lower in comments). The authors conclude that LLM agents in platform-faithful environments reproduce familiar online regularities while systematic divergences, especially those tied to stateless design and content-layer calibration, indicate concrete directions for improvement.
Significance. If the empirical contrasts hold, the work strengthens the case for multi-run, statistically grounded validation of LLM social simulations over single-run or subjective approaches. The 30-run design with 99% CIs for key activity metrics and direct contrasts to external Voat data provide a reproducible benchmark that could guide future agent-based platform modeling; the identification of specific divergences in network repetition and toxicity allocation offers actionable hypotheses even if the causal attributions require further isolation.
major comments (2)
- [Results/Discussion] Results/Discussion (attribution of divergences): The paper links reduced repeated interactions, larger diffuse cores, and toxicity misallocation (higher in root posts, lower in comments) specifically to the stateless Dolphin Mistral 24B configuration and content-layer calibration. However, these attributions rest on observational comparisons across the 30 runs without controlled ablations that vary statefulness (e.g., adding conversation history) or recalibrate content prompts while holding model, platform mechanics, and other factors fixed. Alternative explanations—such as Y Social threading/visibility rules differing from Voat, prompt phrasing, or model scale—therefore cannot be ruled out, weakening the direct mapping from observed gaps to the named future directions.
- [Methods] Methods (agent and toxicity details): The abstract and methods description provide limited information on the exact system prompts, calibration procedures for content layers, and the precise toxicity scoring method applied across root posts versus comments. Because toxicity misallocation is a headline finding used to motivate calibration improvements, fuller specification of these procedures is needed to allow replication and to assess whether the layer-specific differences arise from agent behavior or from the scoring pipeline itself.
minor comments (2)
- [Statistical Analysis] Clarify why 99% confidence intervals were chosen over the conventional 95% for the activity metric overlaps; a brief justification in the statistical analysis subsection would aid interpretability.
- [Data] Add a short table or appendix entry listing the exact Voat data windows used for matching to ensure full reproducibility of the 30 non-overlapping comparison periods.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We have addressed each major point below with revisions where appropriate to improve precision, reproducibility, and caution in our interpretations. These changes strengthen the manuscript without altering the core findings or design.
read point-by-point responses
-
Referee: [Results/Discussion] Results/Discussion (attribution of divergences): The paper links reduced repeated interactions, larger diffuse cores, and toxicity misallocation (higher in root posts, lower in comments) specifically to the stateless Dolphin Mistral 24B configuration and content-layer calibration. However, these attributions rest on observational comparisons across the 30 runs without controlled ablations that vary statefulness (e.g., adding conversation history) or recalibrate content prompts while holding model, platform mechanics, and other factors fixed. Alternative explanations—such as Y Social threading/visibility rules differing from Voat, prompt phrasing, or model scale—therefore cannot be ruled out, weakening the direct mapping from observed gaps to the named future directions.
Authors: We agree that the attributions are observational and that controlled ablations would offer stronger causal isolation. The manuscript presents these links as hypotheses for future work rather than definitive conclusions. We have revised the Discussion to explicitly qualify the connections to stateless design and content-layer calibration as proposed directions, added discussion of alternative explanations including potential platform differences between Y Social and Voat, and outlined specific ablation designs for subsequent studies. While we cannot rule out all alternatives without new experiments, the platform was configured to match Voat mechanics as closely as possible, and the consistency of patterns across 30 independent runs supports the relevance of the agent configuration. We have not added new ablation runs in this revision due to computational cost but have tempered the language accordingly. revision: partial
-
Referee: [Methods] Methods (agent and toxicity details): The abstract and methods description provide limited information on the exact system prompts, calibration procedures for content layers, and the precise toxicity scoring method applied across root posts versus comments. Because toxicity misallocation is a headline finding used to motivate calibration improvements, fuller specification of these procedures is needed to allow replication and to assess whether the layer-specific differences arise from agent behavior or from the scoring pipeline itself.
Authors: We agree that fuller specification is required for replication and to clarify the source of layer-specific toxicity differences. In the revised manuscript we have expanded the Methods section to include the complete system prompts used for the stateless Dolphin Mistral 24B agents, detailed the calibration procedures that differentiate generation for root posts versus comments, and specified the exact toxicity scoring approach, including the classifier or model employed and its separate application to submissions and comments. We have also added validation notes on scoring consistency across layers. These additions enable readers to evaluate whether the observed misallocation originates in agent behavior or the scoring pipeline. revision: yes
Circularity Check
No circularity: direct empirical contrasts to external Voat data
full rationale
The paper runs 30 independent 30-day simulations of a Voat-modeled forum using stateless Dolphin Mistral 24B agents on the Y Social platform and evaluates operational validity by direct statistical comparison to 30 matched, non-overlapping real Voat 30-day windows. Reported results (overlapping CIs for unique users/root posts/DAU, higher simulated comments/thread length/toxicity, core-periphery structure with larger diffuse cores and fewer repeated interactions, near-complete topic alignment but misallocated toxicity across layers) are all observable empirical quantities measured against external data. No equations, fitted parameters, self-definitions, or self-citations are invoked that would reduce any prediction or central claim to the simulation inputs by construction; the derivation chain consists of platform-faithful execution followed by external benchmarking.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Stateless LLM agents can adequately model the behavior of users in an online forum over 30-day periods.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We run a 30-day simulation and evaluate operational validity by comparing distributions and structures—specifically, activity patterns, interaction networks, toxicity, and topic coverage—with matched Voat data.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
stateless agent design and content-layer calibration
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 2 Pith papers
-
The PIMMUR Principles: Ensuring Validity in Collective Behavior of LLM Societies
A systematic audit of LLM-based AI societies finds that 89.7% of 39 studies violate at least one of six PIMMUR validity principles, with reproductions showing that many claimed collective behaviors disappear when cont...
-
Agentic Microphysics: A Manifesto for Generative AI Safety
The authors introduce agentic microphysics and generative safety to link local agent interactions to population-level risks in agentic AI through a causally explicit framework.
Reference graph
Works this paper leans on
-
[1]
Carlo Adornetto, Adrian Mora, Kai Hu, Leticia Izquierdo Garcia, Parfait Atchade-Adelomou, Gianluigi Greco, Luis Alberto Alonso Pastor, and Kent Larson. Generative agents in agent- based modeling: Overview, validation, and emerging challenges.IEEE transactions on artificial intelligence, PP(99):1–20, 2025. 22
work page 2025
-
[2]
Aliya Amirova, Theodora Fteropoulli, Nafiso Ahmed, Martin R Cowie, and Joel Z Leibo. Framework-based qualitative analysis of free responses of Large Language Models: Algorithmic fidelity. PloS one, 19(3):e0300024, 2024
work page 2024
-
[3]
Jacy Reese Anthis, Ryan Liu, Sean M Richardson, Austin C Kozlowski, Bernard Koch, James A Evans, Erik Brynjolfsson, and Michael Bernstein. LLM social simulations are a promising research method. ArXiv, abs/2504.02234:arXiv: 2504.02234, 2025
-
[4]
Lisa P Argyle, Ethan C Busby, Nancy Fulda, Joshua R Gubler, Christopher Rytting, and David Wingate. Out of One, Many: Using Language Models to Simulate Human Samples.Political Analysis, 31(3):337–351, 2023
work page 2023
-
[5]
Persistent interaction patterns across social media platforms and over time
Michele Avalle, Niccolò Di Marco, Gabriele Etta, Emanuele Sangiorgio, Shayan Alipour, Anita Bonetti, Lorenzo Alvisi, Antonio Scala, Andrea Baronchelli, Matteo Cinelli, and Walter Quattrociocchi. Persistent interaction patterns across social media platforms and over time. Nature, 2024
work page 2024
-
[6]
Language Models Surface the Unwritten Code of Science and Society.arXiv [cs.CY], 2025
Honglin Bao, Siyang Wu, Jiwoong Choi, Yingrong Mao, and James A Evans. Language Models Surface the Unwritten Code of Science and Society.arXiv [cs.CY], 2025
work page 2025
-
[7]
Peter L Berger and Thomas Luckmann.The Social Construction of Reality. Penguin Books, 1991
work page 1991
-
[8]
Machine culture.Nature human behaviour, 7(11):1855–1868, 2023
Levin Brinkmann, Fabian Baumann, Jean-François Bonnefon, Maxime Derex, Thomas F Müller, Anne-Marie Nussberger, Agnieszka Czaplicka, Alberto Acerbi, Thomas L Griffiths, Joseph Henrich, Joel Z Leibo, Richard McElreath, Pierre-Yves Oudeyer, Jonathan Stray, and Iyad Rahwan. Machine culture.Nature human behaviour, 7(11):1855–1868, 2023
work page 2023
-
[9]
Large Language Model Discourse Dynamics
Ryan Chaiyakul, Zachary P Rosen, and Rick Dale. Large Language Model Discourse Dynamics. In Proceedings of the Annual Meeting of the Cognitive Science Society, volume 47, 2025
work page 2025
-
[10]
Matteo Cinelli, Gianmarco De Francisci Morales, Alessandro Galeazzi, Walter Quattrociocchi, and Michele Starnini. The echo chamber effect on social media.Proceedings of the National Academy of Sciences of the United States of America, 118(9):e2023301118, 2021
work page 2021
-
[11]
Kevin Durrheim and Michael Quayle. Human murmuration: Group polarisation as compression in interaction-language dynamics captured by large language models.European review of social psychology, pages 1–40, 2025
work page 2025
-
[12]
Large ai models are cultural and social technologies.Science (Policy Forum), 2025
Henry Farrell, Alison Gopnik, Cosma Shalizi, and James Evans. Large ai models are cultural and social technologies.Science (Policy Forum), 2025. Science galley
work page 2025
-
[13]
A clarified typology of core-periphery structure in networks.Science advances, 7(12):eabc9800, 2021
Ryan J Gallagher, Jean-Gabriel Young, and Brooke Foucault Welles. A clarified typology of core-periphery structure in networks.Science advances, 7(12):eabc9800, 2021
work page 2021
-
[14]
Exploring network structure, dynamics, and function using NetworkX
Aric A Hagberg, Daniel A Schult, and Pieter J Swart. Exploring network structure, dynamics, and function using NetworkX. InProceedings of the Python in Science Conference, pages 11–15. SciPy, 2008
work page 2008
-
[15]
ToxiGen: A large-scale machine-generated dataset for adversarial and implicit hate speech detection
Thomas Hartvigsen, Saadia Gabriel, Hamid Palangi, Maarten Sap, Dipankar Ray, and Ece Kamar. ToxiGen: A large-scale machine-generated dataset for adversarial and implicit hate speech detection. InProceedings of the 60th Annual Meeting of the Association of Computational Linguistics, 2022. 23
work page 2022
-
[16]
Austin C. Kozlowski and James Evans. Simulating subjects: The promise and peril of artificial intelligence stand-ins for social agents and interactions.Sociological Methods & Research, 0(0):1–57, 2025
work page 2025
-
[17]
Maik Larooij and Petter T"ornberg. Do large language models solve the problems of agent-based modeling? a critical review of generative social simulations.arXiv [cs.MA], 2025
work page 2025
-
[18]
James G. March and Johan P. Olsen. The Logic of Appropriateness. In Robert Goodin, editor, The Oxford Handbook of Political Science, pages 478–497. Oxford University Press, 1 edition, September 2013
work page 2013
-
[19]
Amin Mekacher and Antonis Papasavva. “I can’t keep it up.” A dataset from the defunct Voat.Co news aggregator. Proceedings of the International AAAI Conference on Web and Social Media, 16:1302–1311, 2022
work page 2022
-
[20]
Kayo Mimizuka, Megan A Brown, Kai-Cheng Yang, and Josephine Lukito. Post-post-api age: Studying digital platforms in scant data access times.Journal of the ACM, 37(4):Article 111,
- [21]
-
[22]
Marija Mitrović Dankulov, Aleksandar Tomašević, Slobodan Maletić, Miroslav Anđelković, Ana Vranić, Darja Cvetković, Boris Stupovski, Dušan Vudragović, Sara Major, and Aleksandar Bogojević. Multi-Platform Aggregated Dataset of Online Communities (MADOC).Proceedings of the International AAAI Conference on Web and Social Media, 19:2529–2538, 2025
work page 2025
-
[23]
The affective resonance of norm-violation rhetoric in social media
W Russell Neuman, George E Marcus, and Michael B MacKuen. The affective resonance of norm-violation rhetoric in social media. InResearch Handbook on Social Media and Society, pages 161–180. Edward Elgar Publishing, 2024
work page 2024
-
[24]
Swati Pandita, Ketika Garg, Jiajin Zhang, and Dean Mobbs. Three roots of online toxicity: disembodiment, accountability, and disinhibition.Trends in cognitive sciences, 2024
work page 2024
-
[25]
Joon Sung Park, Lindsay Popowski, Carrie Cai, Meredith Ringel Morris, Percy Liang, and Michael S. Bernstein. Social Simulacra: Creating Populated Prototypes for Social Computing Systems. In Proceedings of the 35th Annual ACM Symposium on User Interface Software and Technology, pages 1–18, Bend OR USA, October 2022. ACM
work page 2022
-
[26]
Pew Research Center. Beyond Red vs. Blue: The Political Typology. Technical report, Pew Research Center, 2021
work page 2021
-
[27]
Sentence-bert: Sentence embeddings using siamese bert- networks
Nils Reimers and Iryna Gurevych. Sentence-bert: Sentence embeddings using siamese bert- networks. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 11 2019
work page 2019
-
[28]
Zachary P Rosen and Rick Dale. BERTs of a feather: Studying inter- and intra-group communication via information theory and language models. Behavior research methods, 56(4):3140–3160, 2024
work page 2024
-
[29]
Y Social: an LLM-powered Social Media Digital Twin.arXiv [cs.AI], 2024
Giulio Rossetti, Massimo Stella, Rémy Cazabet, Katherine Abramski, Erica Cau, Salvatore Citraro, Andrea Failla, Riccardo Improta, Virginia Morini, and Valentina Pansanella. Y Social: an LLM-powered Social Media Digital Twin.arXiv [cs.AI], 2024
work page 2024
-
[30]
A new sociology of humans and machines.Nature human behaviour, 8(10):1864–1876, 2024
Milena Tsvetkova, Taha Yasseri, Niccolo Pescetelli, and Tobias Werner. A new sociology of humans and machines.Nature human behaviour, 8(10):1864–1876, 2024. 24
work page 2024
-
[31]
Alexander Sasha Vezhnevets, John P Agapiou, Avia Aharon, Ron Ziv, Jayd Matyas, Edgar A Duéñez Guzmán, William A Cunningham, Simon Osindero, Danny Karmon, and Joel Z Leibo. Generative agent-based modeling with actions grounded in physical, social, or digital space using Concordia. arXiv [cs.AI], 2023
work page 2023
-
[32]
Agapiou, Avia Aharon, Ron Ziv, Jayd Matyas, Edgar A
Alexander Sasha Vezhnevets, John P. Agapiou, Avia Aharon, Ron Ziv, Jayd Matyas, Edgar A. Duéñez-Guzmán, William A. Cunningham, Simon Osindero, Danny Karmon, and Joel Z. Leibo. Generative agent-based modeling with actions grounded in physical, social, or digital space using concordia. arXiv [cs.AI], 2023. 25
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.