MAS-Bench: A Unified Benchmark for Shortcut-Augmented Hybrid Mobile GUI Agents
Pith reviewed 2026-05-18 18:38 UTC · model grok-4.3
The pith
A benchmark for hybrid mobile agents shows they reach 68.3 percent success and 39 percent higher efficiency by combining GUI actions with shortcuts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
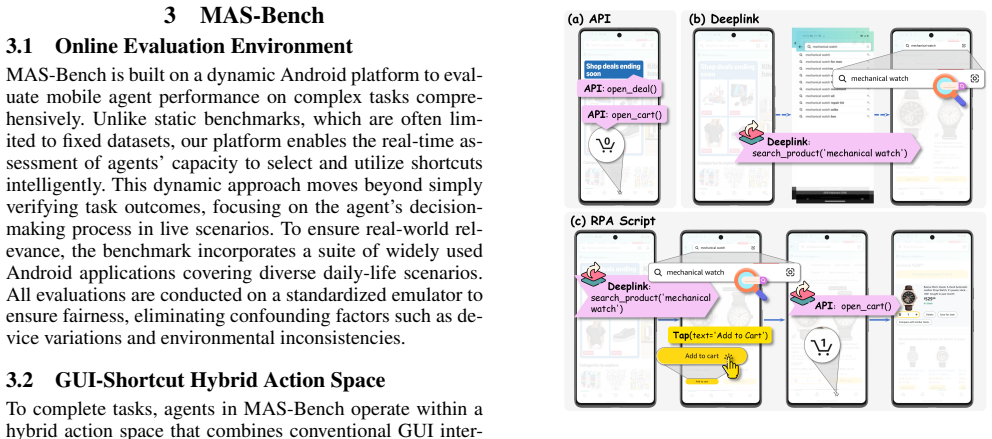
MAS-Bench supplies 139 complex tasks spanning 11 real-world applications, a knowledge base of 88 predefined shortcuts consisting of APIs, deep-links, and RPA scripts, and nine metrics to score hybrid agents. Hybrid agents that employ both GUI operations and shortcuts achieve success rates up to 68.3 percent while completing tasks 39 percent more efficiently than GUI-only agents. The evaluation framework further exposes measurable quality differences between the predefined shortcuts and those generated autonomously by the agents.
What carries the argument
MAS-Bench benchmark that supplies tasks, a shortcut knowledge base, and metrics to measure both execution of hybrid mobile agents and their ability to generate new shortcuts.
If this is right
- Hybrid agents that combine GUI steps with shortcuts can be deployed to complete more mobile tasks reliably and with less time.
- Agents should include mechanisms to detect reusable low-cost workflows and store them as new shortcuts.
- Developers can now compare different shortcut-generation methods using the same set of tasks and metrics.
- Training pipelines for mobile agents can incorporate both predefined and self-generated shortcuts to improve overall performance.
Where Pith is reading between the lines
- If the benchmark tasks generalize well, the same evaluation approach could be adapted to measure hybrid agents on desktop or web environments.
- Closing the quality gap between predefined and agent-generated shortcuts might require new algorithms that explicitly optimize for reusability across multiple tasks.
- Embedding shortcut generation directly into the agent's reasoning loop could reduce the need for large external knowledge bases over time.
Load-bearing premise
The 139 tasks across 11 applications capture enough of real-world mobile automation that results on this benchmark will predict how agents perform on unseen apps and tasks.
What would settle it
Test the same hybrid agents on a fresh collection of mobile applications and tasks outside the original 11 apps and check whether the reported success-rate and efficiency advantages remain intact.
Figures






read the original abstract
Shortcuts such as APIs and deep-links have emerged as efficient complements to flexible GUI operations, fostering a promising hybrid paradigm for MLLM-based mobile automation. However, systematic evaluation of GUI-shortcut hybrid agents remains largely underexplored. To bridge this gap, we introduce MAS-Bench, a benchmark that pioneers the evaluation of GUI-shortcut hybrid agents with a specific focus on the mobile domain. Beyond merely using predefined shortcuts, MAS-Bench assesses an agent's capability to autonomously generate shortcuts by discovering and creating reusable, low-cost workflows. It features 139 complex tasks across 11 real-world applications, a knowledge base of 88 predefined shortcuts (APIs, deep-links, RPA scripts), and 9 evaluation metrics. Experiments demonstrate that hybrid agents achieve up to 68.3% success rate and 39% greater execution efficiency than GUI-only counterparts. Furthermore, our evaluation framework effectively reveals the quality gap between predefined and agent-generated shortcuts, validating its capability to assess shortcut generation methods. MAS-Bench addresses the lack of systematic benchmarks for GUI-shortcut hybrid mobile agents, providing a foundational platform for future advancements in creating more efficient and robust intelligent agents. Project page: https://pengxiang-zhao.github.io/MAS-Bench.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces MAS-Bench, a benchmark for systematic evaluation of GUI-shortcut hybrid agents in the mobile domain. It comprises 139 complex tasks across 11 real-world applications, a knowledge base of 88 predefined shortcuts (APIs, deep-links, RPA scripts), and 9 evaluation metrics. Experiments report that hybrid agents reach up to 68.3% success rate and 39% greater execution efficiency than GUI-only baselines, while the framework detects quality gaps between predefined and agent-generated shortcuts. The work positions MAS-Bench as a foundational platform to advance research on efficient MLLM-based mobile automation.
Significance. If the task set is representative, the benchmark fills a clear gap by enabling controlled comparison of hybrid versus GUI-only agents and by providing a mechanism to assess autonomous shortcut generation. The concrete empirical deltas on success rate and efficiency supply a reproducible starting point for future work; the emphasis on both predefined and generated shortcuts is a useful distinction not commonly isolated in prior GUI-agent evaluations.
major comments (1)
- [§3 and §4] §3 (Benchmark Construction) and §4 (Experiments): No selection criteria, diversity metrics, category coverage statistics, or cross-app generalization analysis are provided for the 11 applications or 139 tasks. Because the headline claims (68.3% success, 39% efficiency gain, and the assertion that MAS-Bench is a 'foundational platform') rest on the assumption that performance on this set predicts behavior on unseen apps and tasks, the absence of such justification is load-bearing and must be addressed before the generalization statements can be accepted.
minor comments (2)
- [Abstract] Abstract: The nine evaluation metrics are referenced but neither named nor briefly characterized; a short enumeration would improve readability for readers who do not immediately consult the full text.
- [§4] Notation: The distinction between 'predefined' and 'agent-generated' shortcuts is central yet occasionally blurred in the experimental narrative; consistent terminology and a clear table mapping each metric to the two categories would reduce ambiguity.
Simulated Author's Rebuttal
We are grateful to the referee for highlighting an important aspect of our benchmark construction. The feedback points to a need for greater transparency in how the tasks and applications were selected, which is crucial for validating the broader applicability of our results. We respond to this comment below and will make corresponding revisions to the manuscript.
read point-by-point responses
-
Referee: [§3 and §4] §3 (Benchmark Construction) and §4 (Experiments): No selection criteria, diversity metrics, category coverage statistics, or cross-app generalization analysis are provided for the 11 applications or 139 tasks. Because the headline claims (68.3% success, 39% efficiency gain, and the assertion that MAS-Bench is a 'foundational platform') rest on the assumption that performance on this set predicts behavior on unseen apps and tasks, the absence of such justification is load-bearing and must be addressed before the generalization statements can be accepted.
Authors: We fully agree with the referee that explicit selection criteria and diversity analysis are necessary to substantiate the generalization claims. The original submission omitted a detailed description of how the 11 applications were chosen and the distribution of the 139 tasks. In the revised version, we will expand §3 to include: (1) Selection criteria: Applications were chosen based on popularity in app stores and to represent diverse functionalities and UI complexities in the mobile domain. Tasks were designed as complex, multi-step operations that could benefit from shortcut augmentation. (2) Diversity metrics: We will add statistics such as the number of tasks per application, distribution across different app types, and average task complexity. (3) A discussion on cross-app generalization, acknowledging that while we have not performed exhaustive experiments on completely unseen applications, the selected set aims to be representative, and we will include this as a limitation and direction for future work. We will also adjust the language in the abstract and introduction to present MAS-Bench as a foundational benchmark for this emerging area while being clear about the scope of the current evaluation. These changes will strengthen the manuscript and address the concerns raised. revision: yes
Circularity Check
No circularity: empirical benchmark results are direct measurements
full rationale
The paper introduces MAS-Bench as a new benchmark consisting of 139 tasks across 11 apps, 88 predefined shortcuts, and 9 metrics, then reports direct experimental outcomes such as hybrid agents reaching 68.3% success rate and 39% greater efficiency than GUI-only baselines. These figures are obtained by running agents on the benchmark tasks and measuring success and efficiency; no equations, fitted parameters, predictions, or first-principles derivations are presented that could reduce to the inputs by construction. The evaluation of quality gaps between predefined and agent-generated shortcuts is likewise an observational comparison on the held-out tasks rather than a self-referential loop. The central claims therefore remain independent and falsifiable through replication on the released benchmark.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The selected mobile applications and tasks are representative of real-world automation scenarios.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
hybrid agents achieve up to 68.3% success rate and 39% greater execution efficiency than GUI-only counterparts... low-cost workflows... Mean kTokens Cost (MToC)... Mean Shortcut Call Count (MSC)
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
139 complex tasks across 11 real-world applications... 88 predefined shortcuts (APIs, deep-links, RPA scripts)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 4 Pith papers
-
OS-SPEAR: A Toolkit for the Safety, Performance,Efficiency, and Robustness Analysis of OS Agents
OS-SPEAR is a new evaluation toolkit that tests 22 OS agents and identifies trade-offs between efficiency and safety or robustness.
-
FedGUI: Benchmarking Federated GUI Agents across Heterogeneous Platforms, Devices, and Operating Systems
FedGUI is the first comprehensive benchmark for federated GUI agents that studies cross-platform, cross-device, cross-OS, and cross-source heterogeneity, with experiments showing performance gains from cross-platform ...
-
UI-Copilot: Advancing Long-Horizon GUI Automation via Tool-Integrated Policy Optimization
UI-Copilot adds a selective copilot for memory and math to GUI agents and trains tool use with separate single-turn and multi-turn optimization, yielding SOTA results on MemGUI-Bench and a 17.1% gain on AndroidWorld.
-
Skill-SD: Skill-Conditioned Self-Distillation for Multi-turn LLM Agents
Skill-SD turns an agent's completed trajectories into dynamic natural-language skills that condition only the teacher in self-distillation, yielding 14-42% gains over RL and OPSD baselines on multi-turn agent benchmarks.
Reference graph
Works this paper leans on
-
[1]
, " * write output.state after.block = add.period write newline
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint howpublished institution isbn journal key month note number organization pages publisher school series title type volume year label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block FUNCTION init.state.consts #0 'before.a...
-
[2]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
-
[3]
Agostinelli, S.; Lupia, M.; Marrella, A.; and Mecella, M. 2022. Reactive synthesis of software robots in RPA from user interface logs. Computers in Industry, 142: 103721
work page 2022
-
[4]
Amalfitano, D.; Fasolino, A. R.; Tramontana, P.; Ta, B. D.; and Memon, A. M. 2014. MobiGUITAR: Automated model-based testing of mobile apps. IEEE software, 32(5): 53--59
work page 2014
- [5]
-
[6]
Bridle, R.; and McCreath, E. 2006. Inducing shortcuts on a mobile phone interface. In Proceedings of the 11th international conference on Intelligent user interfaces, 327--329
work page 2006
-
[7]
Chang, Y.; Wang, X.; Wang, J.; Wu, Y.; Yang, L.; Zhu, K.; Chen, H.; Yi, X.; Wang, C.; Wang, Y.; et al. 2024. A survey on evaluation of large language models. ACM Transactions on Intelligent Systems and Technology, 15(3): 1--45
work page 2024
-
[8]
Chen, J.; Yuen, D.; Xie, B.; Yang, Y.; Chen, G.; Wu, Z.; Yixing, L.; Zhou, X.; Liu, W.; Wang, S.; et al. 2024. Spa-bench: A comprehensive benchmark for smartphone agent evaluation. In NeurIPS 2024 Workshop on Open-World Agents
work page 2024
-
[9]
Cheng, K.; Sun, Q.; Chu, Y.; Xu, F.; Li, Y.; Zhang, J.; and Wu, Z. 2024. Seeclick: Harnessing gui grounding for advanced visual gui agents. arXiv preprint arXiv:2401.10935
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
et al., O. 2024. GPT-4 Technical Report. arXiv:2303.08774
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
Gou, B.; Wang, R.; Zheng, B.; Xie, Y.; Chang, C.; Shu, Y.; Sun, H.; and Su, Y. 2024. Navigating the Digital World as Humans Do: Universal Visual Grounding for GUI Agents. arXiv preprint arXiv:2410.05243
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
Guerreiro, T.; Gamboa, R.; and Jorge, J. 2008. Mnemonical body shortcuts: improving mobile interaction. In Proceedings of the 15th European conference on Cognitive ergonomics: the ergonomics of cool interaction, 1--8
work page 2008
-
[13]
Jiang, W.; Zhuang, Y.; Song, C.; Yang, X.; Zhou, J. T.; and Zhang, C. 2025. AppAgentX: Evolving GUI Agents as Proficient Smartphone Users. arXiv preprint arXiv:2503.02268
-
[14]
Kennedy, C.; and Everett, S. E. 2011. Use of cognitive shortcuts in landline and cell phone surveys. Public Opinion Quarterly, 75(2): 336--348
work page 2011
-
[15]
Kirubakaran, B.; and Karthikeyani, V. 2013. Mobile application testing—Challenges and solution approach through automation. In 2013 International Conference on Pattern Recognition, Informatics and Mobile Engineering, 79--84. IEEE
work page 2013
-
[16]
Kong, P.; Li, L.; Gao, J.; Liu, K.; Bissyand \'e , T. F.; and Klein, J. 2018. Automated testing of android apps: A systematic literature review. IEEE Transactions on Reliability, 68(1): 45--66
work page 2018
-
[17]
V.; Mayer, S.; Wei , M.; Vogelsang, J.; Weing \"a rtner, H.; and Henze, N
Le, H. V.; Mayer, S.; Wei , M.; Vogelsang, J.; Weing \"a rtner, H.; and Henze, N. 2020. Shortcut gestures for mobile text editing on fully touch sensitive smartphones. ACM Transactions on Computer-Human Interaction (TOCHI), 27(5): 1--38
work page 2020
- [18]
-
[19]
Ko, Sangeun Oh, and Insik Shin
Lee, S.; Choi, J.; Lee, J.; Wasi, M. H.; Choi, H.; Ko, S. Y.; Oh, S.; and Shin, I. 2023. Explore, select, derive, and recall: Augmenting llm with human-like memory for mobile task automation. arXiv preprint arXiv:2312.03003
-
[20]
Linares-V \'a squez, M.; Moran, K.; and Poshyvanyk, D. 2017. Continuous, evolutionary and large-scale: A new perspective for automated mobile app testing. In 2017 IEEE International Conference on Software Maintenance and Evolution (ICSME), 399--410. IEEE
work page 2017
-
[21]
Ling, X.; Gao, M.; and Wang, D. 2020. Intelligent document processing based on RPA and machine learning. In 2020 Chinese Automation Congress (CAC), 1349--1353. IEEE
work page 2020
- [22]
- [23]
-
[24]
Lu, Z.; Chai, Y.; Guo, Y.; Yin, X.; Liu, L.; Wang, H.; Xiong, G.; and Li, H. 2025. Ui-r1: Enhancing action prediction of gui agents by reinforcement learning. arXiv preprint arXiv:2503.21620
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
Minaee, S.; Mikolov, T.; Nikzad, N.; Chenaghlu, M.; Socher, R.; Amatriain, X.; and Gao, J. 2024. Large language models: A survey. arXiv preprint arXiv:2402.06196
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[26]
Rawles, C.; Clinckemaillie, S.; Chang, Y.; Waltz, J.; Lau, G.; Fair, M.; Li, A.; Bishop, W.; Li, W.; Campbell-Ajala, F.; et al. 2024. AndroidWorld: A dynamic benchmarking environment for autonomous agents. arXiv preprint arXiv:2405.14573
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
Roffarello, A. M.; Purohit, A. K.; and Purohit, S. V. 2024. Trigger-Action Programming for Wellbeing: Insights From 6590 iOS Shortcuts. IEEE Pervasive Computing
work page 2024
- [28]
-
[29]
Tripathi, A. M. 2018. Learning Robotic Process Automation: Create Software robots and automate business processes with the leading RPA tool--UiPath. Packt Publishing Ltd
work page 2018
-
[30]
Wang, F.; Zhang, Z.; Zhang, X.; Wu, Z.; Mo, T.; Lu, Q.; Wang, W.; Li, R.; Xu, J.; Tang, X.; et al. 2024 a . A comprehensive survey of small language models in the era of large language models: Techniques, enhancements, applications, collaboration with llms, and trustworthiness. arXiv preprint arXiv:2411.03350
- [31]
- [32]
- [33]
-
[34]
Inducing programmatic skills for agentic tasks.arXiv preprint arXiv:2504.06821, 2025
Wang, Z. Z.; Gandhi, A.; Neubig, G.; and Fried, D. 2025 b . Inducing programmatic skills for agentic tasks. arXiv preprint arXiv:2504.06821
- [35]
- [36]
- [37]
- [38]
- [39]
-
[40]
Zhang, J.; Yu, Y.; Liao, M.; Li, W.; Wu, J.; and Wei, Z. 2024. UI-Hawk: Unleashing the screen stream understanding for gui agents
work page 2024
-
[41]
A Survey of Large Language Models
Zhao, W. X.; Zhou, K.; Li, J.; Tang, T.; Wang, X.; Hou, Y.; Min, Y.; Zhang, B.; Zhang, J.; Dong, Z.; et al. 2023. A survey of large language models. arXiv preprint arXiv:2303.18223
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[42]
Zhao, Y.; Harrison, B.; and Yu, T. 2024. Dinodroid: Testing android apps using deep q-networks. ACM Transactions on Software Engineering and Methodology, 33(5): 1--24
work page 2024
-
[43]
SkillWeaver: Web Agents can Self-Improve by Discovering and Honing Skills
Zheng, B.; Fatemi, M. Y.; Jin, X.; Wang, Z. Z.; Gandhi, A.; Song, Y.; Gu, Y.; Srinivasa, J.; Liu, G.; Neubig, G.; and Su, Y. 2025. SkillWeaver: Web Agents can Self-Improve by Discovering and Honing Skills. arXiv:2504.07079
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.