Adapting Vision-Language Models for Neutrino Event Classification in High-Energy Physics
Pith reviewed 2026-05-18 17:17 UTC · model grok-4.3
The pith
Vision-language models adapted from LLaMA 3.2 classify neutrino interactions more accurately and with clearer reasoning than standard CNNs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
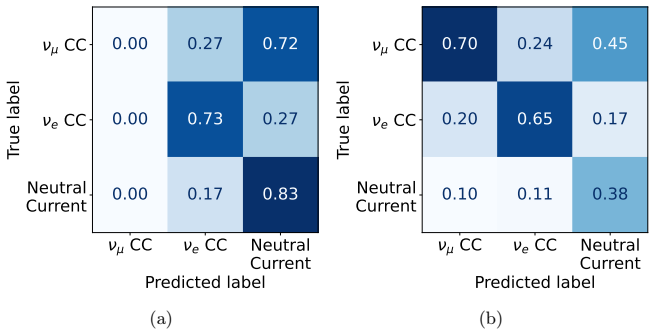
By fine-tuning LLaMA 3.2 as a vision-language model on pixelated detector data, the work establishes that this multimodal architecture classifies electron and muon neutrino events with better accuracy and robustness than a conventional CNN baseline or a vision-only ViT-h/14 encoder, while the language component supplies auxiliary semantic information and generates step-by-step reasoning for each prediction.
What carries the argument
The fine-tuned LLaMA 3.2 vision-language model that combines a vision transformer encoder with a language model to accept both detector images and textual prompts for joint classification and explanation.
If this is right
- Transformer architectures deliver higher classification accuracy and robustness than CNNs on neutrino detector images.
- The VLM gains flexibility by accepting auxiliary textual or semantic information alongside the images.
- Predictions become more interpretable because the model can output explicit reasoning steps.
- Large transformer models can serve as general-purpose backbones for event classification across physics experiments.
Where Pith is reading between the lines
- Similar fine-tuning could extend to other image-like data streams in particle physics such as calorimeter or tracking detector outputs.
- The built-in reasoning might help flag rare or unexpected event topologies that lack dedicated training labels.
- Integration with existing simulation and reconstruction software could create hybrid pipelines where language prompts guide analysis choices.
Load-bearing premise
The claim rests on the premise that any performance advantage comes from the VLM design itself rather than from larger training data volumes or more extensive hyperparameter tuning than what was given to the CNN and ViT baselines.
What would settle it
A controlled re-run of the three models on identical neutrino datasets, identical data splits, and matched training schedules that checks whether the reported accuracy and interpretability edges remain.
Figures










read the original abstract
Recent advances in Large Language Models (LLMs) have demonstrated their remarkable capacity to process and reason over structured and unstructured data modalities beyond natural language. In this work, we explore the applications of Vision Language Models (VLMs), specifically a fine-tuned variant of LLaMA 3.2 to the task of identifying neutrino interactions in pixelated detector data from high-energy physics (HEP) experiments. We benchmark this model against a state-of-the-art convolutional neural network (CNN) architecture, similar to those used in major neutrino experiments, which have achieved high efficiency and purity in classifying electron and muon neutrino events, and also a Vision Transformer (ViT-h/14), which is the same architecture inside the VLM's vision encoder. Our evaluation considers both classification performance and interpretability of the model predictions, comparing a VLM with a vision-only transformer (ViT) and a convolutional neural network (CNN) baseline. We find that transformer-based architectures outperform conventional CNNs in classification accuracy and robustness, with the VLM providing additional flexibility through the integration of auxiliary textual or semantic information and enabling more interpretable, reasoning-based predictions. These results highlight the potential of large transformer models, particularly vision-language models, as general-purpose backbones for physics event classification, combining strong performance, robustness, and interpretability, and opening new avenues for multimodal reasoning in experimental neutrino physics.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript explores adapting a fine-tuned LLaMA 3.2 Vision-Language Model for classifying neutrino interactions in pixelated high-energy physics detector data. It benchmarks the VLM against a state-of-the-art CNN (similar to those in major neutrino experiments) and the ViT-h/14 vision encoder, claiming that transformer-based models outperform CNNs in accuracy and robustness while the VLM adds flexibility via auxiliary textual/semantic information and enables more interpretable, reasoning-based predictions.
Significance. If the performance and interpretability claims hold under controlled conditions, the work could be significant as an early demonstration of VLMs as general-purpose backbones for HEP event classification. The multimodal aspect and reasoning capability represent a potential advance over vision-only models, with possible implications for robustness and new analysis workflows in neutrino physics.
major comments (2)
- [Abstract] Abstract: the central claim that 'transformer-based architectures outperform conventional CNNs in classification accuracy and robustness' and that the VLM provides 'additional flexibility' and 'more interpretable, reasoning-based predictions' is presented without any quantitative metrics (accuracy, AUC, efficiency/purity), dataset sizes, or error bars. This absence is load-bearing because the entire contribution rests on the empirical comparison.
- [Experimental Setup] Experimental Setup / Benchmarking description: no information is given on training data volume, epoch counts, learning-rate schedules, batch sizes, or hyperparameter tuning protocols applied to the CNN baseline versus the VLM (or the shared ViT-h/14 encoder). Without these details it is impossible to attribute any observed edge to the VLM architecture or multimodal fusion rather than differences in optimization or data exposure.
minor comments (2)
- [Results] The manuscript would benefit from a dedicated table or figure summarizing the classification metrics (accuracy, precision, recall, F1) across all three models on the same test set.
- [Methods] Clarify whether the textual prompts used with the VLM are fixed templates or learned; this detail affects the claimed advantage of 'auxiliary textual or semantic information'.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed comments, which help strengthen the clarity and rigor of our manuscript. We address each major comment point by point below, outlining specific revisions where appropriate while defending the core contributions on substance.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that 'transformer-based architectures outperform conventional CNNs in classification accuracy and robustness' and that the VLM provides 'additional flexibility' and 'more interpretable, reasoning-based predictions' is presented without any quantitative metrics (accuracy, AUC, efficiency/purity), dataset sizes, or error bars. This absence is load-bearing because the entire contribution rests on the empirical comparison.
Authors: We agree that the abstract would be strengthened by the inclusion of quantitative metrics to support the central claims. In the revised manuscript, we will update the abstract to report key performance figures such as classification accuracy, AUC, efficiency/purity, dataset sizes, and error bars from the experiments. This revision will make the empirical basis of the claims immediately accessible to readers without altering the overall narrative. revision: yes
-
Referee: [Experimental Setup] Experimental Setup / Benchmarking description: no information is given on training data volume, epoch counts, learning-rate schedules, batch sizes, or hyperparameter tuning protocols applied to the CNN baseline versus the VLM (or the shared ViT-h/14 encoder). Without these details it is impossible to attribute any observed edge to the VLM architecture or multimodal fusion rather than differences in optimization or data exposure.
Authors: The referee is correct that additional detail on training protocols is necessary for reproducibility and to support attribution of performance differences. The current manuscript provides a high-level description of the benchmarking but lacks the requested specifics. We will expand the Experimental Setup section to include training data volumes, epoch counts, learning-rate schedules, batch sizes, and hyperparameter tuning procedures applied to the CNN, ViT-h/14, and VLM. These additions will clarify that comparisons were performed under consistent conditions. revision: yes
Circularity Check
No circularity: empirical benchmarking study with external baselines
full rationale
The paper is an empirical comparison of a fine-tuned LLaMA 3.2 VLM against a CNN baseline and the identical ViT-h/14 vision encoder for neutrino event classification in HEP data. No mathematical derivation chain, equations, or first-principles results are claimed or present. Performance claims rest on reported accuracy, robustness, and interpretability metrics evaluated against stated external baselines. These metrics are externally falsifiable and do not reduce to self-definition, fitted inputs renamed as predictions, or self-citation chains. The study is self-contained against the provided benchmarks; any concerns about unequal training regimes fall under experimental fairness rather than circularity in a derivation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Pixelated detector outputs can be treated as images suitable for standard vision encoders.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We fine-tune the LLaMA 3.2 Vision Instruct 11B model... using QLoRA... on a labeled dataset of neutrino interaction pixel maps... accuracy of 0.87... textual justifications... grounded in event topology
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Siamese CNN Architecture... 3.4 million parameters... Adam optimizer... cross-entropy loss
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
Towards foundation-style models for energy-frontier heterogeneous neutrino detectors via self-supervised pre-training
Self-supervised pre-training on multimodal neutrino detector simulations produces reusable representations that improve downstream classification, regression, and data efficiency over training from scratch.
Reference graph
Works this paper leans on
-
[1]
A survey on evaluation of large language models,
Y. Chang et al., “A survey on evaluation of large language models,”ACM transactions on intelligent systems and technology, vol. 15, no. 3, pp. 1–45, 2024
work page 2024
-
[2]
Multimodal large language models: A survey,
J. Wu, W. Gan, Z. Chen, S. Wan, and P. S. Yu, “Multimodal large language models: A survey,” in2023 IEEE International Conference on Big Data (BigData), IEEE, 2023, pp. 2247–2256
work page 2023
-
[3]
A.Grattafiorietal.,“Thellama3herdofmodels,”arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
The nova technical design report,
D. Ayres et al., “The nova technical design report,” 2007. 15
work page 2007
-
[5]
Deep underground neutrino experi- ment: Dune,
A. Falcone, D. Collaboration, et al., “Deep underground neutrino experi- ment: Dune,”Nuclear Instruments and Methods in Physics Research Sec- tion A: Accelerators, Spectrometers, Detectors and Associated Equipment, vol. 1041, p. 167217, 2022
work page 2022
-
[6]
E. E. Robles, A. Yankelevich, W. Wu, J. Bian, and P. Baldi, “Particle hit clustering and identification using point set transformers in liquid argon time projection chambers,”Journal of Instrumentation, vol. 20, no. 07, P07030, 2025
work page 2025
-
[7]
Sparse convolution transformers for dune fd event and particle classification,
A. Yankelevich, A. Shmakov, J. Bian, and P. Baldi, “Sparse convolution transformers for dune fd event and particle classification,”Bulletin of the American Physical Society, 2024
work page 2024
-
[8]
Reconstruction of unstable heavy particles using deep symmetry-preserving attention networks,
M. J. Fenton et al., “Reconstruction of unstable heavy particles using deep symmetry-preserving attention networks,”Communications Physics, vol. 7, no. 1, p. 139, 2024
work page 2024
-
[9]
Searching for exotic particles in high-energy physics with deep learning,
P. Baldi, P. Sadowski, and D. Whiteson, “Searching for exotic particles in high-energy physics with deep learning,”Nature communications, vol. 5, no. 1, p. 4308, 2014
work page 2014
-
[10]
Jetsubstructure classification in high-energy physics with deep neural networks,
P.Baldi,K.Bauer,C.Eng,P.Sadowski,andD.Whiteson,“Jetsubstructure classification in high-energy physics with deep neural networks,”Physical Review D, vol. 93, no. 9, p. 094034, 2016
work page 2016
-
[11]
Param- eterized neural networks for high-energy physics,
P. Baldi, K. Cranmer, T. Faucett, P. Sadowski, and D. Whiteson, “Param- eterized neural networks for high-energy physics,”The European Physical Journal C, vol. 76, no. 5, pp. 1–7, 2016
work page 2016
-
[12]
Baldi,Deep learning in science
P. Baldi,Deep learning in science. Cambridge University Press, 2021
work page 2021
-
[13]
C.BackhouseandR.Patterson,“Libraryeventmatchingeventclassification algorithm for electron neutrino interactions in the noνa detectors,”Nuclear Instruments and Methods in Physics Research Section A: Accelerators, Spectrometers, Detectors and Associated Equipment, vol. 778, pp. 31–39, 2015
work page 2015
-
[14]
Neutrino interaction classification with a convolutional neural network in the dune far detector,
B. Abi et al., “Neutrino interaction classification with a convolutional neural network in the dune far detector,”Physical Review D, vol. 102, no. 9, p. 092003, 2020
work page 2020
-
[15]
Convolutional networks for images, speech, and time series,
Y. LeCun and Y. Bengio, “Convolutional networks for images, speech, and time series,”The handbook of brain theory and neural networks, 1998
work page 1998
-
[16]
Aconvolutionalneuralnetworkneutrinoeventclassifier,
A.Aurisanoetal.,“Aconvolutionalneuralnetworkneutrinoeventclassifier,” Journal of Instrumentation, vol. 11, no. 09, P09001, 2016
work page 2016
-
[17]
Vision-language models for vision tasks: A survey,
J. Zhang, J. Huang, S. Jin, and S. Lu, “Vision-language models for vision tasks: A survey,”IEEE transactions on pattern analysis and machine intelligence, vol. 46, no. 8, pp. 5625–5644, 2024
work page 2024
-
[18]
The GENIE Neutrino Monte Carlo Generator
C. Andreopoulos et al., “The GENIE Neutrino Monte Carlo Generator,” Nucl. Instrum. Meth. A, vol. 614, pp. 87–104, 2010.doi:10.1016/j.nima. 2009.12.009arXiv:0905.2517 [hep-ph]. 16
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1016/j.nima 2010
-
[19]
The GENIE Neutrino Monte Carlo Generator: Physics and User Manual
C. Andreopoulos et al.,The GENIE Neutrino Monte Carlo Generator: Physics and User Manual, Oct. 2015. arXiv:1510.05494 [hep-ph]
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[20]
Geant4 Collaboration, “Geant4 10.4 release notes,”geant4-data.web.cern.ch, 2017.[Online].Available: https://geant4-data.web.cern.ch/ReleaseNotes/ ReleaseNotes4.10.4.html
work page 2017
-
[21]
S. Agostinelli et al., “GEANT4–a simulation toolkit,”Nucl. Instrum. Meth. A, vol. 506, pp. 250–303, 2003.doi:10.1016/S0168-9002(03)01368-8
- [22]
-
[23]
Measurement of longitudinal electron diffusion in liquid argon,
Y. Li et al., “Measurement of longitudinal electron diffusion in liquid argon,”"Nucl. Instrum. Meth. A", vol. 816, pp. 160–170, 2016,issn: 0168- 9002.doi: https://doi.org/10.1016/j.nima.2016.01.094 [Online]. Available: https://www.sciencedirect.com/science/article/pii/ S0168900216001443
-
[24]
A. Vaswani et al., “Attention is all you need,”Advances in neural informa- tion processing systems, vol. 30, 2017
work page 2017
-
[25]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
A. Dosovitskiy et al., “An image is worth 16x16 words: Transformers for image recognition at scale,”arXiv preprint arXiv:2010.11929, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[26]
Qlora: Effi- cient finetuning of quantized llms,
T. Dettmers, A. Pagnoni, A. Holtzman, and L. Zettlemoyer, “Qlora: Effi- cient finetuning of quantized llms,”Advances in neural information pro- cessing systems, vol. 36, pp. 10088–10115, 2023
work page 2023
-
[27]
Lora: Low-rank adaptation of large language models.,
E. J. Hu et al., “Lora: Low-rank adaptation of large language models.,” ICLR, vol. 1, no. 2, p. 3, 2022
work page 2022
-
[28]
HuggingFace's Transformers: State-of-the-art Natural Language Processing
T. Wolf et al., “Huggingface’s transformers: State-of-the-art natural lan- guage processing,”arXiv preprint arXiv:1910.03771, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1910
-
[29]
Lexically Constrained Decoding for Sequence Generation Using Grid Beam Search
C. Hokamp and Q. Liu, “Lexically constrained decoding for sequence generation using grid beam search,”arXiv preprint arXiv:1704.07138, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[30]
Language Models as Knowledge Bases?
F. Petroni et al., “Language models as knowledge bases?”arXiv preprint arXiv:1909.01066, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[31]
On calibration of modern neural networks,
C. Guo, G. Pleiss, Y. Sun, and K. Q. Weinberger, “On calibration of modern neural networks,” inInternational conference on machine learning, PMLR, 2017, pp. 1321–1330
work page 2017
-
[32]
Grad-cam: Visual explanations from deep networks via gradient- based localization,
R. R. Selvaraju, M. Cogswell, A. Das, R. Vedantam, D. Parikh, and D. Batra, “Grad-cam: Visual explanations from deep networks via gradient- based localization,” inProceedings of the IEEE international conference on computer vision, 2017, pp. 618–626
work page 2017
-
[33]
Axiomatic attribution for deep networks,
M. Sundararajan, A. Taly, and Q. Yan, “Axiomatic attribution for deep networks,” inInternational conference on machine learning, PMLR, 2017, pp. 3319–3328. 17
work page 2017
-
[34]
Nlx-gpt: A model for natural language explanations in vision and vision-language tasks,
F. Sammani, T. Mukherjee, and N. Deligiannis, “Nlx-gpt: A model for natural language explanations in vision and vision-language tasks,” in proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 8322–8332
work page 2022
-
[35]
Madrazo, Celia Fernández, Heredia, Ignacio, Lloret, Lara, and Marco de Lucas, Jesús, “Application of a convolutional neural network for image classification for the analysis of collisions in high energy physics,”EPJ Web Conf., vol. 214, p. 06017, 2019.doi: 10.1051/epjconf/201921406017 [Online]. Available:https://doi.org/10.1051/epjconf/201921406017
-
[36]
Convolutional neural networks applied to neutrino events in a liquid argon time projection chamber,
R. Acciarri et al., “Convolutional neural networks applied to neutrino events in a liquid argon time projection chamber,”Journal of instrumentation, vol. 12, no. 03, P03011, 2017
work page 2017
-
[37]
Machine learning and the physical sciences,
G. Carleo et al., “Machine learning and the physical sciences,”Reviews of Modern Physics, vol. 91, no. 4, p. 045002, 2019
work page 2019
-
[38]
Signature verification using a
J. Bromley, I. Guyon, Y. LeCun, E. Säckinger, and R. Shah, “Signature verification using a" siamese" time delay neural network,”Advances in neural information processing systems, vol. 6, 1993
work page 1993
-
[39]
Siamese neural networks for one-shot image recognition,
G. Koch, R. Zemel, R. Salakhutdinov, et al., “Siamese neural networks for one-shot image recognition,” inICML deep learning workshop, Lille, vol. 2, 2015, pp. 1–30
work page 2015
-
[40]
Deep Learning using Rectified Linear Units (ReLU)
A. F. Agarap, “Deep learning using rectified linear units (relu),”arXiv preprint arXiv:1803.08375, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[41]
Mo- bilenetv2: Inverted residuals and linear bottlenecks,
M. Sandler, A. Howard, M. Zhu, A. Zhmoginov, and L.-C. Chen, “Mo- bilenetv2: Inverted residuals and linear bottlenecks,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 4510–4520
work page 2018
-
[42]
Squeeze-and-excitation networks,
J. Hu, L. Shen, and G. Sun, “Squeeze-and-excitation networks,” inProceed- ings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 7132–7141
work page 2018
-
[43]
Dropout: A simple way to prevent neural networks from overfitting,
N.Srivastava,G.Hinton,A.Krizhevsky,I.Sutskever,andR.Salakhutdinov, “Dropout: A simple way to prevent neural networks from overfitting,”The journal of machine learning research, vol. 15, no. 1, pp. 1929–1958, 2014
work page 1929
-
[44]
Adam: A Method for Stochastic Optimization
D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” arXiv preprint arXiv:1412.6980, 2014. 18
work page internal anchor Pith review Pith/arXiv arXiv 2014
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.