Guided Query Refinement: Multimodal Hybrid Retrieval with Test-Time Optimization
Pith reviewed 2026-05-18 09:38 UTC · model grok-4.3
The pith
Guided Query Refinement refines a vision-centric model's query embedding at test time using scores from a lightweight text retriever to match the accuracy of much larger models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
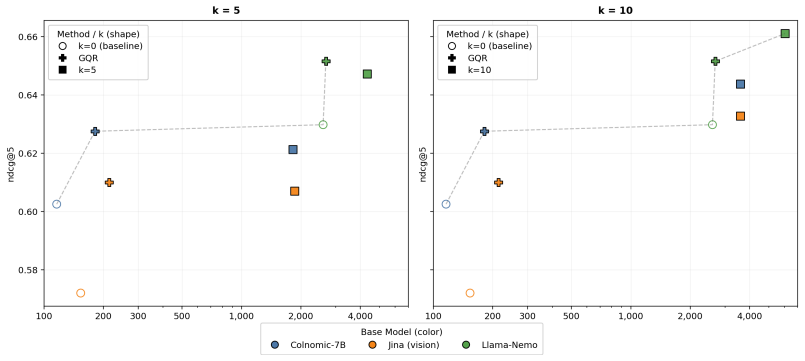
Guided Query Refinement is a test-time optimization procedure that refines the query embedding of a primary vision-centric retriever by leveraging guidance signals derived from the ranking scores of a complementary lightweight dense text retriever. This hybrid approach exploits rich interactions within each model's representation space rather than relying on coarse-grained fusion of ranks or scores. The result is that vision-centric models reach performance levels comparable to those relying on significantly larger representations.
What carries the argument
Guided Query Refinement (GQR), a test-time optimization that adjusts the primary query embedding using scores from a complementary retriever to improve hybrid retrieval without per-query hyperparameter search.
If this is right
- Vision-centric models achieve performance comparable to models with significantly larger representations on visual document retrieval benchmarks.
- Retrieval runs up to 14x faster and uses 54x less memory than the larger-representation alternatives.
- The Pareto frontier for performance versus efficiency advances in multimodal retrieval systems.
- Hybrid retrieval benefits from embedding-level refinement instead of post-hoc rank or score fusion.
Where Pith is reading between the lines
- The test-time guidance idea could extend to other retrieval settings where one modality or model type offers cheap signals to refine a stronger but heavier primary system.
- By improving smaller models dynamically, the method may reduce pressure to scale representations indefinitely for new tasks.
- GQR-style refinement might combine with existing efficiency techniques such as quantization or pruning to further ease real-world deployment.
Load-bearing premise
Scores from the lightweight dense text retriever supply reliable, non-conflicting guidance that refines the primary query embedding effectively without per-query hyperparameter search or degradation in edge cases.
What would settle it
A visual document retrieval benchmark where applying GQR either lowers accuracy relative to the base vision-centric model or requires query-specific hyperparameter adjustments to produce gains.
Figures







read the original abstract
Multimodal encoders have pushed the boundaries of visual document retrieval, matching textual query tokens directly to image patches and achieving state-of-the-art performance on public benchmarks. Recent models relying on this paradigm have massively scaled the sizes of their query and document representations, presenting obstacles to deployment and scalability in real-world pipelines. Furthermore, purely vision-centric approaches may be constrained by the inherent modality gap still exhibited by modern vision-language models. In this work, we connect these challenges to the paradigm of hybrid retrieval, investigating whether a lightweight dense text retriever can enhance a stronger vision-centric model. Existing hybrid methods, which rely on coarse-grained fusion of ranks or scores, fail to exploit the rich interactions within each model's representation space. To address this, we introduce Guided Query Refinement (GQR), a novel test-time optimization method that refines a primary retriever's query embedding using guidance from a complementary retriever's scores. Through extensive experiments on visual document retrieval benchmarks, we demonstrate that GQR allows vision-centric models to match the performance of models with significantly larger representations, while being up to 14x faster and requiring 54x less memory. Our findings show that GQR effectively pushes the Pareto frontier for performance and efficiency in multimodal retrieval. We release our code at https://github.com/IBM/test-time-hybrid-retrieval
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Guided Query Refinement (GQR), a test-time optimization method that refines the query embedding of a primary vision-centric multimodal retriever using score-based guidance from a lightweight dense text retriever. It claims that this hybrid approach enables smaller vision-centric models to match the performance of models with significantly larger representations on visual document retrieval benchmarks, while achieving up to 14x speedup and 54x memory reduction, thereby advancing the performance-efficiency Pareto frontier in multimodal retrieval.
Significance. If the efficiency and performance claims hold after accounting for test-time costs, the work would meaningfully advance hybrid retrieval by moving beyond coarse rank/score fusion to representation-space guidance, offering a practical deployment path for high-performing vision-centric models without requiring larger representations.
major comments (1)
- [Abstract] Abstract and the description of the GQR test-time optimization procedure: the reported 14x speedup and 54x memory savings versus larger-representation baselines do not include or bound the per-query cost of the iterative refinement (forward passes, score evaluations, or optimization steps). Without explicit measurement or amortization of this overhead relative to base inference, the net efficiency gains and the claim that GQR matches larger models while remaining faster cannot be verified from the stated results.
minor comments (1)
- [Abstract] The abstract refers to 'extensive experiments on visual document retrieval benchmarks' but does not name the specific datasets, baselines, or statistical tests used to support the performance-matching claim.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on the efficiency claims. We address the major comment regarding the inclusion of test-time optimization costs below.
read point-by-point responses
-
Referee: [Abstract] Abstract and the description of the GQR test-time optimization procedure: the reported 14x speedup and 54x memory savings versus larger-representation baselines do not include or bound the per-query cost of the iterative refinement (forward passes, score evaluations, or optimization steps). Without explicit measurement or amortization of this overhead relative to base inference, the net efficiency gains and the claim that GQR matches larger models while remaining faster cannot be verified from the stated results.
Authors: We acknowledge that the speedup and memory figures reported in the abstract compare the base inference costs of the smaller vision-centric model (augmented by GQR) to those of larger-representation baselines, without an explicit accounting of the per-query overhead from the iterative refinement procedure. The manuscript focuses on the final retrieval latency after refinement but does not provide per-step timing or bounds on the number of optimization iterations. We agree this omission limits verification of net gains. In the revised manuscript we will add (i) measured wall-clock time per refinement step on the evaluation hardware, (ii) the average and maximum number of steps observed across queries, and (iii) a combined latency figure that includes the full GQR procedure. We will also discuss amortization when GQR is applied to batches or when the number of steps remains small relative to the representation-size savings. These additions will allow readers to assess whether the claimed efficiency advantages hold after test-time costs. revision: yes
Circularity Check
No significant circularity; method defined procedurally and validated on external benchmarks
full rationale
The paper introduces Guided Query Refinement (GQR) as a test-time optimization procedure that refines a primary vision-centric model's query embedding using guidance from scores of a complementary lightweight dense text retriever. This is presented as a novel hybrid retrieval technique to address modality gaps and scalability issues. Performance claims (matching larger models while being faster and more memory-efficient) and efficiency assertions are supported exclusively by empirical results on visual document retrieval benchmarks, with no equations, derivations, or fitted parameters shown that reduce the reported gains to quantities defined solely by the method's own inputs or self-referential normalizations. No load-bearing self-citations or uniqueness theorems from overlapping authors are invoked in the provided text to justify the core approach. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- test-time optimization hyperparameters
axioms (1)
- domain assumption Scores from the complementary text retriever provide useful guidance for query refinement
Forward citations
Cited by 4 Pith papers
-
Test-Time Compute for Dense Retrieval: Agentic Program Generation with Frozen Embedding Models
Agentic program search over frozen embedding APIs yields a parameter-free inference algebra—a softmax-weighted centroid of top-K documents interpolated with the query—that lifts nDCG@10 across seven model families on ...
-
Test-Time Compute for Dense Retrieval: Agentic Program Generation with Frozen Embedding Models
A softmax-weighted centroid of the local top-K documents interpolated with the query improves nDCG@10 for frozen embedding models across seven families on held-out BEIR data.
-
Task-Adaptive Embedding Refinement via Test-time LLM Guidance
Test-time LLM feedback refines query embeddings to deliver up to 25% relative gains on zero-shot literature search, intent detection, and related benchmarks.
-
Beyond Chain-of-Thought: Rewrite as a Universal Interface for Generative Multimodal Embeddings
Rewrite-driven generation with alignment and RL produces shorter, more effective generative multimodal embeddings than CoT methods on retrieval benchmarks.
Reference graph
Works this paper leans on
-
[3]
PaliGemma: A versatile 3B VLM for transfer
URL https://arxiv.org/abs/2407.07726. Sebastian Bruch, Siyu Gai, and Amir Ingber. An analysis of fusion functions for hybrid retrieval. ACM Transactions on Information Systems, 42(1), August
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Antoine Chaffin and Aur´elien Lac
URLhttps://doi.org/ 10.1145/3596512. Antoine Chaffin and Aur´elien Lac. Monoqwen: Visual document reranking,
-
[5]
Tao Chen, Mingyang Zhang, Jing Lu, Michael Bendersky, and Marc Najork
URLhttps: //huggingface.co/lightonai/MonoQwen2-VL-v0.1. Tao Chen, Mingyang Zhang, Jing Lu, Michael Bendersky, and Marc Najork. Out-of-domain se- mantics to the rescue! Zero-shot hybrid retrieval models. InAdvances in Information Retrieval: 44th European Conference on IR Research, ECIR 2022, Stavanger, Norway, April 10–14, 2022, Proceedings, Part I, pp. 95...
work page 2022
-
[6]
Springer-Verlag. ISBN 978-3-030- 99735-9. URLhttps://doi.org/10.1007/978-3-030-99736-6_7. Chanyeol Choi, Junseong Kim, Seolhwa Lee, Jihoon Kwon, Sangmo Gu, Yejin Kim, Minkyung Cho, and Jy-yong Sohn. Linq-embed-mistral technical report.arXiv:2412.03223,
-
[7]
arXiv preprint arXiv:2412.03223
URL https://arxiv.org/abs/2412.03223. Benjamin Clavi´e and Florian Brand. Readbench: Measuring the dense text visual reading ability of vision-language models,
-
[8]
URLhttps://arxiv.org/abs/2505.19091. Gordon V . Cormack, Charles L A Clarke, and Stefan Buettcher. Reciprocal rank fusion outper- forms condorcet and individual rank learning methods. InSIGIR ’09: Proceedings of the 32nd international ACM SIGIR conference on Research and development in information retrieval, pp. 758–759, New York, NY , USA,
-
[9]
URLhttp://doi.acm.org/10.1145/1571941. 1572114. C´ıcero dos Santos, Luciano Barbosa, Dasha Bogdanova, and Bianca Zadrozny. Learning hybrid rep- resentations to retrieve semantically equivalent questions. In Chengqing Zong and Michael Strube (eds.),Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th Internati...
-
[10]
Association for Com- puting Machinery. ISBN 9798400715921. URLhttps://doi.org/10.1145/3726302. 3730160. Michael G ¨unther, Saba Sturua, Mohammad Kalim Akram, Isabelle Mohr, Andrei Ungureanu, Bo Wang, Sedigheh Eslami, Scott Martens, Maximilian Werk, Nan Wang, et al. jina-embeddings- v4: Universal embeddings for multimodal multilingual retrieval.arXiv:2506.18902,
-
[11]
11 Hsin-Ling Hsu and Jengnan Tzeng
URL https://arxiv.org/abs/2506.18902. 11 Hsin-Ling Hsu and Jengnan Tzeng. DAT: Dynamic alpha tuning for hybrid retrieval in retrieval- augmented generation.arXiv:2503.23013,
-
[13]
Unsupervised Dense Information Retrieval with Contrastive Learning
URLhttps://arxiv.org/abs/2112.09118. Chao Jia, Yinfei Yang, Ye Xia, Yi-Ting Chen, Zarana Parekh, Hieu Pham, Quoc V . Le, Yunhsuan Sung, Zhen Li, and Tom Duerig. Scaling up visual and vision-language representation learn- ing with noisy text supervision. InProceedings of the 38th International Conference on Machine Learning, volume 139 ofICML, pp. 4904–4916. PMLR,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
URLhttps:// proceedings.mlr.press/v139/jia21b.html. Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. Dense passage retrieval for open-domain question answering. In Bonnie Webber, Trevor Cohn, Yulan He, and Yang Liu (eds.),Proceedings of the 2020 Conference on Empirical Methods in Natural Lan...
work page 2020
-
[15]
URLhttps://aclanthology.org/ 2020.emnlp-main.550/
Association for Computational Linguistics. URLhttps://aclanthology.org/ 2020.emnlp-main.550/. Omar Khattab and Matei Zaharia. ColBERT: Efficient and effective passage search via contextual- ized late interaction over BERT. InProceedings of the 43rd International ACM SIGIR conference on research and development in Information Retrieval, pp. 39–48,
work page 2020
-
[17]
Binxu Li, Yuhui Zhang, Xiaohan Wang, Weixin Liang, Ludwig Schmidt, and Serena Yeung-Levy
URLhttps://arxiv.org/abs/2010.01195. Binxu Li, Yuhui Zhang, Xiaohan Wang, Weixin Liang, Ludwig Schmidt, and Serena Yeung-Levy. Closing the modality gap for mixed modality search,
-
[18]
URLhttps://arxiv.org/ abs/2507.19054. Junnan Li, Ramprasaath R. Selvaraju, Akhilesh Gotmare, Shafiq Joty, Caiming Xiong, and Steven Hoi. Align before fuse: Vision and language representation learning with momentum distillation. InAdvances in Neural Information Processing Systems, NeurIPS,
-
[19]
Junnan Li, Dongxu Li, Caiming Xiong, and Steven Hoi
URLhttps://proceedings.neurips.cc/paper/2021/hash/ 505259756244493872b7709a8a01b536-Abstract.html. Junnan Li, Dongxu Li, Caiming Xiong, and Steven Hoi. Blip: Bootstrapping language-image pre- training for unified vision-language understanding and generation. InInternational conference on machine learning, pp. 12888–12900. PMLR,
work page 2021
-
[20]
URL https://aclanthology.org/2024.acl-long.775
Association for Computational Linguistics. URL https://aclanthology.org/2024.acl-long.775. Yi Luan, Jacob Eisenstein, Kristina Toutanova, and Michael Collins. Sparse, dense, and attentional representations for text retrieval.Transactions of the Association for Computational Linguistics, 9:329–345,
work page 2024
-
[22]
Vidore benchmark v2: Raising the bar for visual retrieval.arXiv preprint arXiv:2505.17166, 2025
URLhttps://arxiv.org/abs/2505.17166. Minesh Mathew, Viraj Bagal, Rub `en P´erez Tito, Dimosthenis Karatzas, Ernest Valveny, and C. V Jawahar. InfographicVQA, 2021a. URLhttps://arxiv.org/abs/2104.12756. Minesh Mathew, Dimosthenis Karatzas, and C. V . Jawahar. DocVQA: A dataset for VQA on docu- ment images, 2021b. URLhttps://arxiv.org/abs/2007.00398. Rodrig...
-
[24]
Representation Learning with Contrastive Predictive Coding
URLhttps://arxiv.org/abs/ 1807.03748. Yingqi Qu, Yuchen Ding, Jing Liu, Kai Liu, Ruiyang Ren, Wayne Xin Zhao, Daxiang Dong, Hua Wu, and Haifeng Wang. Rocketqa: An optimized training approach to dense passage retrieval for open-domain question answering.arXiv preprint arXiv:2010.08191,
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[25]
URLhttps: //arxiv.org/abs/2010.08191. Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agar- wal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. InProceedings of the 38th International Conference on Machin...
-
[26]
Nils Reimers and Iryna Gurevych
URLhttps://proceedings.mlr.press/v139/radford21a.html. Nils Reimers and Iryna Gurevych. Sentence-BERT: Sentence embeddings using Siamese BERT- networks. In Kentaro Inui, Jing Jiang, Vincent Ng, and Xiaojun Wan (eds.),Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th In- ternational Joint Conference on Natur...
work page 2019
-
[27]
Gerard Salton and Christopher Buckley
URLhttps://arxiv.org/abs/ 2505.03703. Gerard Salton and Christopher Buckley. Term-weighting approaches in automatic text retrieval. Information processing & management, 24(5):513–523,
-
[29]
Colbertv2: Effective and efficient retrieval via lightweight late interaction
URLhttps://arxiv.org/abs/2112.01488. Keshav Santhanam, Omar Khattab, Christopher Potts, and Matei Zaharia. PLAID: an efficient engine for late interaction retrieval. InProceedings of the 31st ACM International Conference on Information & Knowledge Management, pp. 1747–1756,
-
[30]
Optimizing test-time query representations for dense retrieval
Mujeen Sung, Jungsoo Park, Jaewoo Kang, Danqi Chen, and Jinhyuk Lee. Optimizing test-time query representations for dense retrieval. In Anna Rogers, Jordan Boyd-Graber, and Naoaki Okazaki (eds.),Findings of the Association for Computational Linguistics: ACL 2023, pp. 5731– 5746, Toronto, Canada, July
work page 2023
-
[31]
URLhttps: //aclanthology.org/2023.findings-acl.354/
Association for Computational Linguistics. URLhttps: //aclanthology.org/2023.findings-acl.354/. Ryota Tanaka, Kyosuke Nishida, and Sen Yoshida. Visualmrc: Machine reading comprehension on document images. InAAAI,
work page 2023
-
[32]
arXiv preprint arXiv:2408.09869 , year=
URLhttps: //arxiv.org/abs/2408.09869. 13 IBM Research Team. Granite-vision-3.3-2b-embedding, 2025a. URLhttps://huggingface. co/ibm-granite/granite-vision-3.3-2b-embedding. Nomic Team. Nomic embed multimodal: Interleaved text, image, and screenshots for visual document retrieval, 2025b. URLhttps://nomic.ai/blog/posts/ nomic-embed-multimodal. Peng Wang, Shu...
-
[33]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
URLhttps://arxiv. org/abs/2409.12191. Navve Wasserman, Oliver Heinimann, Yuval Golbari, Tal Zimbalist, Eli Schwartz, and Michal Irani. Docrerank: Single-page hard negative query generation for training multi-modal rag rerankers. arXiv preprint arXiv:2505.22584,
work page internal anchor Pith review Pith/arXiv arXiv
-
[34]
URLhttps://arxiv.org/abs/2505.22584. Lee Xiong, Chenyan Xiong, Ye Li, Kwok-Fung Tang, Jialin Liu, Paul Bennett, Junaid Ahmed, and Arnold Overwijk. Approximate nearest neighbor negative contrastive learning for dense text retrieval.arXiv preprint arXiv:2007.00808,
- [35]
-
[37]
Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models
URLhttps://arxiv.org/abs/2506.05176. Fengbin Zhu, Wenqiang Lei, Fuli Feng, Chao Wang, Haozhou Zhang, and Tat-Seng Chua. To- wards complex document understanding by discrete reasoning. InProceedings of the 30th ACM International Conference on Multimedia, pp. 4857–4866,
work page internal anchor Pith review Pith/arXiv arXiv
-
[38]
A BACKGROUND Neural Information Retrieval represents a fundamental shift from traditional lexical matching meth- ods like BM25 (Robertson et al., 1995), TF-IDF (Salton & Buckley, 1988), and other term-based approaches (Zhai & Lafferty, 2017). Unlike these sparse retrieval methods that rely on exact term matches and statistical properties, neural approache...
work page 1995
-
[39]
The MaxSim equation, as defined in ColBERT (see eq
pioneered this approach with its MaxSim operation, which computes the maximum similar- ity between each query token and all passage tokens, then aggregates these scores. The MaxSim equation, as defined in ColBERT (see eq. 4)), finds for query token embeddingq i the maximum similarity (dot product) with any passage token embeddingp j. These maximum scores ...
work page 2021
-
[40]
(2025) for visual document retrieval
for text retrieval and Chaffin & Lac (2024); Wasserman et al. (2025) for visual document retrieval. A.1 VISUALDOCUMENTRETRIEVAL VERBALIZATION-BASED METHODSwere the dominant approach before the advent of end-to-end vision models. These pipelines convert visual documents into text through various techniques: tra- ditional Optical Character Recognition (OCR)...
work page 2024
-
[41]
After verbalization, these methods apply standard text retrieval techniques to the extracted content
extract printed text, while Vision-Language Models (VLMs) can generate textual descriptions of visual elements such as charts, diagrams, and infographics. After verbalization, these methods apply standard text retrieval techniques to the extracted content. While verbalization-based approaches can leverage powerful text-only retrieval models, they inherent...
work page 2024
-
[42]
ColPali provides native text-query support due to its VLM-based design
and adapting the late-interaction framework to vision-language models by treating image patches as visual tokens that interact with textual query tokens through MaxSim operations. ColPali provides native text-query support due to its VLM-based design. Queries remain text, are encoded by the model’s language tower, and are matched directly against visual p...
work page 2025
-
[43]
to ingest the images. Docling is an open library providing OCR capabilities combined with document layout analysis, allowing us to recover page content via simple function calls. The resulting text is stored alongside the page images without any chunking, ensuring consistent alignment between visual and textual page representations across the datasets. We...
work page 2025
-
[44]
It is noticeable that this benchmark suffers from saturation, with many subset scores reaching90or higher (and indeed this was the direct motivation for the release of ViDoRe 2, Mac ´e et al., 2025). Nevertheless, our method does not harm performance, in contrast to other hybrid retrieval methods, as seen in Tables 8 and
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.