EEPO: Exploration-Enhanced Policy Optimization via Sample-Then-Forget
Pith reviewed 2026-05-18 08:50 UTC · model grok-4.3
The pith
A two-stage rollout with temporary unlearning after the first samples forces language models to explore new responses and raises reasoning scores.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
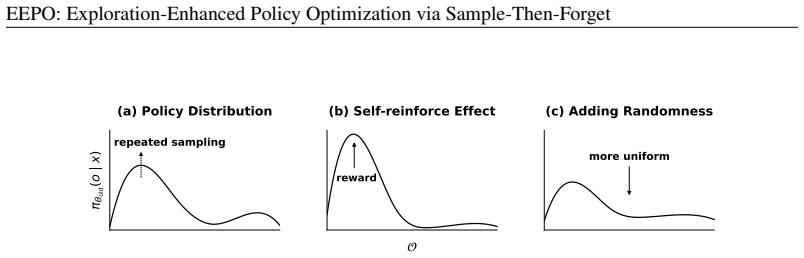
EEPO uses two-stage rollouts with adaptive unlearning: after the policy produces the first half of trajectories, a lightweight unlearning step temporarily suppresses those sampled responses, so the second stage must generate different outputs. This sample-then-forget process disrupts the self-reinforcing loop of dominant modes and improves exploration during training.
What carries the argument
The sample-then-forget mechanism, which inserts a lightweight unlearning step after the first-stage rollouts to suppress sampled trajectories and compel the policy to explore new output regions in the second stage.
If this is right
- The method raises average performance on reasoning benchmarks by 10 to 33 percent relative to GRPO across the tested model sizes.
- Exploration is restored during rollouts without needing larger batch sizes or external entropy bonuses.
- The two-stage structure keeps the overall training pipeline simple while targeting the entropy-collapse problem directly.
- The same sample-then-forget pattern can be inserted into other RLVR algorithms that currently suffer from repeated sampling of dominant responses.
Where Pith is reading between the lines
- The approach may extend to non-reasoning tasks such as code generation or dialogue where repeated safe answers also limit diversity.
- Because the unlearning is temporary and lightweight, it could be combined with existing exploration bonuses without major hyper-parameter retuning.
- If the suppression effect scales with model size, larger models might show even bigger relative gains on harder reasoning problems.
- A natural next test is whether the same two-stage pattern improves sample efficiency when the total number of rollouts per prompt is held fixed.
Load-bearing premise
The lightweight unlearning step can be applied after the first-stage rollouts without causing lasting damage to the policy or interfering with the subsequent optimization updates.
What would settle it
Run the same training setup on one of the reported models and benchmarks but measure output diversity or final accuracy after removing the unlearning step; if the gains disappear and performance matches the GRPO baseline, the claim fails.
Figures






read the original abstract
Balancing exploration and exploitation remains a central challenge in reinforcement learning with verifiable rewards (RLVR) for large language models (LLMs). Current RLVR methods often overemphasize exploitation, leading to entropy collapse, diminished exploratory capacity, and ultimately limited performance gains. Although techniques that increase policy stochasticity can promote exploration, they frequently fail to escape dominant behavioral modes. This creates a self-reinforcing loop -- repeatedly sampling and rewarding dominant modes -- that further erodes exploration. We introduce Exploration-Enhanced Policy Optimization (EEPO), a framework that promotes exploration via two-stage rollouts with adaptive unlearning. In the first stage, the model generates half of the trajectories; it then undergoes a lightweight unlearning step to temporarily suppress these sampled responses, forcing the second stage to explore different regions of the output space. This sample-then-forget mechanism disrupts the self-reinforcing loop and promotes wider exploration during rollouts. Across five reasoning benchmarks, EEPO outperforms GRPO, achieving average relative gains of 24.3% on Qwen2.5-3B, 33.0% on Llama3.2-3B-Instruct, and 10.4% on Qwen3-8B-Base.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Exploration-Enhanced Policy Optimization (EEPO), a two-stage rollout framework for reinforcement learning with verifiable rewards (RLVR) in large language models. After first-stage trajectory sampling, a lightweight unlearning step temporarily suppresses the sampled responses to force the second-stage rollouts into different regions of the output space, thereby disrupting the self-reinforcing exploitation loop. The authors report that EEPO outperforms GRPO across five reasoning benchmarks, with average relative gains of 24.3% on Qwen2.5-3B, 33.0% on Llama3.2-3B-Instruct, and 10.4% on Qwen3-8B-Base.
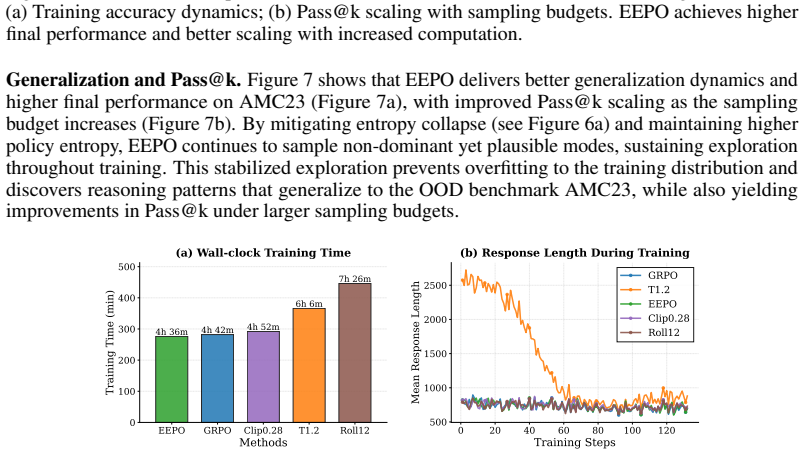
Significance. If the sample-then-forget mechanism can be shown to increase exploration without permanent policy degradation or distortion of subsequent gradients, the approach would address a recognized limitation of current RLVR methods (entropy collapse) and could yield more reliable gains on reasoning tasks. The reported empirical improvements, if robust, indicate practical value for LLM post-training.
major comments (2)
- [§3] §3 (Method): The unlearning step is described only at the conceptual level. No loss function, step count, learning-rate schedule, or safeguard (KL regularization, replay buffer, or early stopping) is specified. Because the central claim rests on the unlearning (1) sufficiently reducing probability mass on first-stage trajectories, (2) remaining reversible, and (3) not interfering with later policy-gradient updates, the absence of these implementation details prevents verification of the three required properties.
- [§4] §4 (Experiments): The performance tables report relative gains over GRPO but contain no information on the number of random seeds, standard deviations, statistical significance tests, or ablation studies that isolate the contribution of the unlearning step versus other design choices. Without these controls, the observed improvements cannot be confidently attributed to the intended exploration mechanism.
minor comments (1)
- [Abstract] The abstract refers to 'adaptive unlearning' without indicating what quantity is adapted or how adaptation is performed; a single clarifying sentence would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate planned revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [§3] §3 (Method): The unlearning step is described only at the conceptual level. No loss function, step count, learning-rate schedule, or safeguard (KL regularization, replay buffer, or early stopping) is specified. Because the central claim rests on the unlearning (1) sufficiently reducing probability mass on first-stage trajectories, (2) remaining reversible, and (3) not interfering with later policy-gradient updates, the absence of these implementation details prevents verification of the three required properties.
Authors: We agree that the current description in §3 is primarily conceptual and lacks the requested implementation specifics. In the revised manuscript we will expand the method section to specify the unlearning loss (negative log-likelihood on first-stage samples), the number of steps (typically 2–4), the learning-rate schedule, and a lightweight KL regularization term to the pre-unlearning policy. These additions will directly support verification of probability-mass reduction, reversibility, and non-interference with subsequent policy-gradient updates. revision: yes
-
Referee: [§4] §4 (Experiments): The performance tables report relative gains over GRPO but contain no information on the number of random seeds, standard deviations, statistical significance tests, or ablation studies that isolate the contribution of the unlearning step versus other design choices. Without these controls, the observed improvements cannot be confidently attributed to the intended exploration mechanism.
Authors: We acknowledge that the reported results are from single runs and that statistical controls and targeted ablations are needed to attribute gains specifically to the unlearning mechanism. In the revision we will rerun all experiments with at least three random seeds, report means and standard deviations, add significance testing, and include an ablation that disables only the unlearning step while holding other hyperparameters fixed. revision: yes
Circularity Check
No significant circularity; empirical gains reported from independent benchmark evaluations.
full rationale
The paper introduces EEPO as a two-stage rollout procedure with a lightweight unlearning step to disrupt self-reinforcing sampling loops in RLVR. Performance claims consist of direct empirical comparisons to GRPO on five reasoning benchmarks, with no equations, fitted parameters, or first-principles derivations presented that would reduce the reported relative gains to a definitional identity or self-referential construction. No load-bearing self-citations, uniqueness theorems, or ansatzes imported from prior author work are invoked to justify the central mechanism. The method is self-contained as an algorithmic intervention whose effects are measured externally via benchmark results, satisfying the criteria for an honest non-finding of circularity.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 3 Pith papers
-
Breaking $\textit{Winner-Takes-All}$: Cooperative Policy Optimization Improves Diverse LLM Reasoning
GCPO shifts RLVR from rollout competition to team cooperation by assigning advantages via marginal contributions to a determinant-based coverage volume over semantic embeddings, yielding higher accuracy and solution d...
-
Breaking $\textit{Winner-Takes-All}$: Cooperative Policy Optimization Improves Diverse LLM Reasoning
GCPO uses team-level credit assignment via determinant volume over reward-weighted semantic embeddings to promote non-redundant correct reasoning paths, improving both accuracy and diversity in LLM training.
-
The Past Is Not Past: Memory-Enhanced Dynamic Reward Shaping
MEDS improves LLM RL performance by up to 4.13 pass@1 and 4.37 pass@128 points by dynamically penalizing rollouts matching prevalent historical error clusters identified via memory-stored representations and density c...
Reference graph
Works this paper leans on
-
[1]
Evaluating Large Language Models Trained on Code
Liang Chen, Xueting Han, Li Shen, Jing Bai, and Kam-Fai Wong. Beyond two-stage training: Cooperative sft and rl for llm reasoning, 2025a. URL https://arxiv.org/abs/2509. 06948. Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde De Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating large...
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Zhipeng Chen, Yingqian Min, Beichen Zhang, Jie Chen, Jinhao Jiang, Daixuan Cheng, Wayne Xin Zhao, Zheng Liu, Xu Miao, Yang Lu, Lei Fang, Zhongyuan Wang, and Ji-Rong Wen. An empirical study on eliciting and improving r1-like reasoning models, 2025b. URL https: //arxiv.org/abs/2503.04548. Zhipeng Chen, Xiaobo Qin, Youbin Wu, Yue Ling, Qinghao Ye, Wayne Xin ...
-
[3]
URL https:// codeforces.com/. Accessed: 2025-03-18. Ganqu Cui, Yuchen Zhang, Jiacheng Chen, Lifan Yuan, Zhi Wang, Yuxin Zuo, Haozhan Li, Yuchen Fan, Huayu Chen, Weize Chen, Zhiyuan Liu, Hao Peng, Lei Bai, Wanli Ouyang, Yu Cheng, Bowen Zhou, and Ning Ding. The entropy mechanism of reinforcement learning for reasoning language models,
work page 2025
-
[4]
The Entropy Mechanism of Reinforcement Learning for Reasoning Language Models
URLhttps://arxiv.org/abs/2505.22617. DeepSeek-AI, Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, Xiaokang Zhang, Xingkai Yu, Yu Wu, Z. F. Wu, Zhibin Gou, Zhihong Shao, Zhuoshu Li, Ziyi Gao, Aixin Liu, Bing Xue, Bingxuan Wang, Bochao Wu, Bei Feng, Chengda Lu, Chenggang Zhao, Chengqi De...
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
URLhttps://arxiv.org/abs/2501.12948. Kanishk Gandhi, Ayush Chakravarthy, Anikait Singh, Nathan Lile, and Noah D. Goodman. Cognitive behaviors that enable self-improving reasoners, or, four habits of highly effective stars,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Cognitive Behaviors that Enable Self-Improving Reasoners, or, Four Habits of Highly Effective STaRs
URL https://arxiv.org/abs/2503.01307. Chaoqun He, Renjie Luo, Yuzhuo Bai, Shengding Hu, Zhen Leng Thai, Junhao Shen, Jinyi Hu, Xu Han, Yujie Huang, Yuxiang Zhang, et al. Olympiadbench: A challenging benchmark for promoting agi with olympiad-level bilingual multimodal scientific problems.arXiv preprint arXiv:2402.14008,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Measuring Mathematical Problem Solving With the MATH Dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset.arXiv preprint arXiv:2103.03874, 2021a. Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical...
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
URLhttps://arxiv.org/abs/2501.11651. Joel Jang, Dongkeun Yoon, Sohee Yang, Sungmin Cha, Moontae Lee, Lajanugen Logeswaran, and Minjoon Seo. Knowledge unlearning for mitigating privacy risks in language models. In Anna Rogers, Jordan Boyd-Graber, and Naoaki Okazaki (eds.),Proceedings of the 61st Annual Meeting of the Association for Computational Linguisti...
-
[9]
Yifan Li, Yifan Du, Kun Zhou, Jinpeng Wang, Xin Zhao, and Ji-Rong Wen
Association for Computational Linguistics. doi: 10.18653/v1/2023. acl-long.805. URLhttps://aclanthology.org/2023.acl-long.805/. Aitor Lewkowycz, Anders Andreassen, David Dohan, Ethan Dyer, Henryk Michalewski, Vinay Ra- masesh, Ambrose Slone, Cem Anil, Imanol Schlag, Theo Gutman-Solo, et al. Solving quantitative reasoning problems with language models.Adva...
-
[10]
Varshney, Mohit Bansal, Sanmi Koyejo, and Yang Liu
URL https: //arxiv.org/abs/2402.08787. Eric Mitchell, Charles Lin, Antoine Bosselut, Christopher D. Manning, and Chelsea Finn. Memory- based model editing at scale,
- [11]
-
[12]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Y Wu, et al. DeepSeekMath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
HybridFlow: A Flexible and Efficient RLHF Framework
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. Hybridflow: A flexible and efficient rlhf framework.arXiv preprint arXiv:2409.19256,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Kimi k1.5: Scaling Reinforcement Learning with LLMs
Kimi Team, Angang Du, Bofei Gao, Bowei Xing, Changjiu Jiang, Cheng Chen, Cheng Li, Chenjun Xiao, Chenzhuang Du, Chonghua Liao, et al. Kimi K1.5: Scaling reinforcement learning with LLMs.arXiv preprint arXiv:2501.12599,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
URL https://arxiv.org/abs/2407. 21783. An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, et al. Qwen2. 5 technical report.arXiv preprint arXiv:2412.15115,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
URLhttps://arxiv.org/abs/2505.09388. Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, Xin Liu, Haibin Lin, Zhiqi Lin, Bole Ma, Guangming Sheng, Yuxuan Tong, Chi Zhang, Mofan Zhang, Wang Zhang, Hang Zhu, Jinhua Zhu, Jiaze Chen, Jiangjie Chen, Chengyi Wang, Hongli Yu, Yuxuan Song, Xia...
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
URL https://arxiv.org/ abs/2503.14476. Weihao Zeng, Yuzhen Huang, Qian Liu, Wei Liu, Keqing He, Zejun Ma, and Junxian He. Simplerl- zoo: Investigating and taming zero reinforcement learning for open base models in the wild,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
URLhttps://arxiv.org/abs/2503.18892. 13 EEPO: Exploration-Enhanced Policy Optimization via Sample-Then-Forget Daniel M Ziegler, Nisan Stiennon, Jeffrey Wu, Tom B Brown, Alec Radford, Dario Amodei, Paul Christiano, and Geoffrey Irving. Fine-tuning language models from human preferences.arXiv preprint arXiv:1909.08593,
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[20]
14 EEPO: Exploration-Enhanced Policy Optimization via Sample-Then-Forget A DETAILEDEXPERIMENTALSETUP Datasets.We use the MATH dataset (Hendrycks et al., 2021a) for RL training. Following the setup of SimpleRL (Zeng et al., 2025), we train on the hard data, which contains 8.5K problems with difficulty levels ranging from 3 to
work page 2025
-
[21]
For evaluation, we adopt five challenging mathematical reasoning benchmarks: Minerva Math (Lewkowycz et al., 2022), OlympiadBench (He et al., 2024), and three recent competition-level datasets—AMC 2023, AIME 2024, and AIME
work page 2022
-
[22]
Models.To demonstrate the generality of our approach, we experiment with three LLMs from different model families and scales. • Qwen2.5-3B (Yang et al., 2024): a base model from the Qwen2.5 series, with stronger pretraining and support for long-context inputs. • Llama-3.2-3B-Instruct (Team, 2024): an instruction-following model based on Meta’s Llama archi...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.