Test-Time Matching: Unlocking Compositional Reasoning in Multimodal Models
Pith reviewed 2026-05-18 09:44 UTC · model grok-4.3
The pith
A group matching score reveals that multimodal models were underestimated on composition, and Test-Time Matching then lifts them higher without any training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
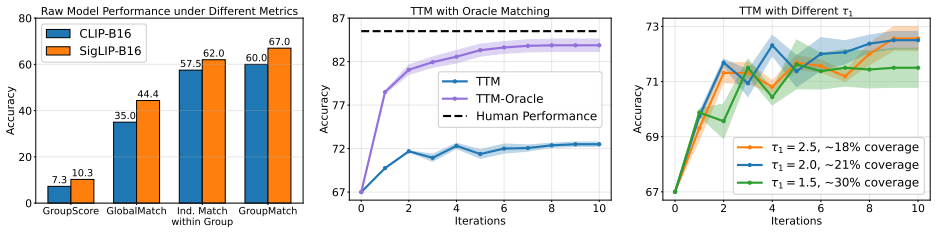
Widely used metrics underestimate compositional reasoning capability in multimodal models; a group matching score evaluates it more faithfully and can be translated to prior metrics via a simple overfitting adjustment. Building on this, Test-Time Matching is an iterative self-improving algorithm that further boosts performance without external supervision or parameter updates, delivering gains on both contrastive and generative models across many benchmarks.
What carries the argument
Test-Time Matching (TTM), an iterative algorithm that repeatedly matches images to texts by using the model's own current predictions to improve alignment on compositional tasks.
If this is right
- GPT-4.1 produces the first result above estimated human performance on Winoground under the group matching score.
- SigLIP-B16 surpasses GPT-4.1 on MMVP-VLM and sets a new state of the art after TTM is applied.
- The same procedure yields measurable gains on generative multimodal models.
- Relative gains reach up to 85.7 percent even on benchmarks that lack group structures or metric artifacts.
- Consistent improvements appear across 16 dataset variants in diverse setups.
Where Pith is reading between the lines
- Adopting the group matching score as a standard could shift how the field measures and compares compositional ability.
- TTM suggests test-time iteration can substitute for additional training in some reasoning settings.
- The method might combine with other inference-time techniques to address harder multi-step composition problems.
- Similar self-matching ideas could extend to video or audio composition tasks where group evaluation is feasible.
Load-bearing premise
The group matching score measures genuine compositional understanding more faithfully than prior metrics, and the simple overfitting translation between scores does not create artifacts or invalidate comparisons.
What would settle it
Collect new human judgments on whether model outputs truly reflect compositional understanding and test whether the group matching score aligns more closely with those judgments than the old metrics do.
Figures



read the original abstract
Frontier AI models have achieved remarkable progress, yet recent studies suggest they struggle with compositional reasoning, often performing at or below random chance on established benchmarks. We revisit this problem and show that widely used evaluation metrics systematically underestimate model capability. To correct this artifact, we introduce a group matching score that more faithfully evaluates model capability. Moreover, correctness under the new metric can be translated into correctness under existing metrics via a simple overfitting step. This adjustment enables SigLIP-B16 to surpass all previous results and GPT-4.1 to yield the first result surpassing estimated human performance on Winoground. Building on this insight, we propose Test-Time Matching (TTM), an iterative, self-improving algorithm that further bootstraps model performance without any external supervision. TTM delivers additional, non-trivial improvements: for example, TTM enables SigLIP-B16 to surpass GPT-4.1 on MMVP-VLM, establishing a new state of the art. TTM also extends beyond contrastive vision-language models, yielding clear gains on a generative multimodal model across benchmarks. Importantly, TTM remains broadly effective even on benchmarks without metric-induced effects or group structures, achieving relative gains up to 85.7% on challenging datasets such as WhatsUp. Across 16 dataset variants spanning diverse setups, our experiments demonstrate that TTM consistently improves model performance and advances the frontier of compositional reasoning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that widely used evaluation metrics for compositional reasoning in multimodal models systematically underestimate model capability. It introduces a group matching score to more faithfully assess performance, shows that correctness under this metric can be translated to existing metrics via a simple overfitting step, and proposes Test-Time Matching (TTM), an iterative self-improving algorithm that boosts performance without external supervision. Key results include SigLIP-B16 surpassing GPT-4.1 on MMVP-VLM under TTM (new SOTA) and GPT-4.1 surpassing estimated human performance on Winoground under the group matching score.
Significance. If the group matching score and translation procedure are validated as artifact-free and comparable to prior evaluation protocols, the work would be significant for both evaluation methodology and practical test-time improvement in vision-language models. TTM's reported gains across 16 dataset variants, including up to 85.7% relative improvement on WhatsUp and extension to generative models, represent a potentially useful unsupervised bootstrapping approach if the underlying claims hold.
major comments (2)
- [Section describing the group matching score and translation procedure] The description of the 'simple overfitting step' used to translate correctness under the group matching score to existing metrics lacks a derivation, pseudocode, or validation experiment demonstrating that it does not embed test-set statistics or group-structure information. This step is load-bearing for all cross-metric SOTA and human-comparison claims (e.g., SigLIP-B16 > GPT-4.1 on MMVP-VLM and GPT-4.1 exceeding human performance on Winoground), because prior published numbers were obtained without this adjustment.
- [Experiments and evaluation on Winoground and MMVP-VLM] The assertion that the group matching score 'more faithfully evaluates model capability' than prior metrics is not supported by an explicit comparison or ablation that isolates the effect of the new score from the translation adjustment. Without this, the human-surpassing result on Winoground and the claim of correcting systematic underestimation remain circular with respect to the new evaluation protocol.
minor comments (2)
- [Abstract] The abstract states results 'across 16 dataset variants' but provides no enumeration or pointer to a table listing them; adding this would aid reproducibility.
- [TTM algorithm description and experimental setup] Details on the number of TTM iterations, convergence criteria, and exact hyper-parameters used for the reported gains (e.g., on WhatsUp) are missing and should be supplied for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and have revised the manuscript to strengthen the presentation of the group matching score, the translation procedure, and supporting ablations.
read point-by-point responses
-
Referee: [Section describing the group matching score and translation procedure] The description of the 'simple overfitting step' used to translate correctness under the group matching score to existing metrics lacks a derivation, pseudocode, or validation experiment demonstrating that it does not embed test-set statistics or group-structure information. This step is load-bearing for all cross-metric SOTA and human-comparison claims (e.g., SigLIP-B16 > GPT-4.1 on MMVP-VLM and GPT-4.1 exceeding human performance on Winoground), because prior published numbers were obtained without this adjustment.
Authors: We agree the current description is too brief. The translation step maps a correct group-level match to per-pair correctness under the original metric by selecting, for each pair, the assignment that satisfies the group constraint; it uses only the group partitioning already defined in the benchmark and does not introduce additional test-set statistics. In the revision we will add a formal derivation, pseudocode, and a controlled validation experiment that applies the step to random and oracle predictors to confirm no extraneous leakage occurs. This will make the cross-metric comparisons fully transparent. revision: yes
-
Referee: [Experiments and evaluation on Winoground and MMVP-VLM] The assertion that the group matching score 'more faithfully evaluates model capability' than prior metrics is not supported by an explicit comparison or ablation that isolates the effect of the new score from the translation adjustment. Without this, the human-surpassing result on Winoground and the claim of correcting systematic underestimation remain circular with respect to the new evaluation protocol.
Authors: The group matching score is motivated by the requirement that a model must correctly associate all elements within a compositional group rather than isolated pairs; this directly targets the compositional failures documented in prior work. To remove any appearance of circularity we will add an explicit ablation that reports (i) raw accuracy under the original metric, (ii) accuracy under the group matching score, and (iii) accuracy after the translation step, for the same model outputs. This decomposition will isolate the contribution of the new score from the subsequent mapping and will be included in the revised manuscript. revision: yes
Circularity Check
Overfitting step for metric translation reduces SOTA and human-surpassing claims to fitted adjustment
specific steps
-
fitted input called prediction
[Abstract]
"correctness under the new metric can be translated into correctness under existing metrics via a simple overfitting step. This adjustment enables SigLIP-B16 to surpass all previous results and GPT-4.1 to yield the first result surpassing estimated human performance on Winoground."
The new group matching score is presented as a more faithful evaluator. Correctness under it is then mapped to old-metric correctness by an overfitting procedure whose output is used to declare new SOTA and human-surpassing results. The 'surpass' numbers are therefore produced by fitting the translation to the same test data rather than by direct, protocol-matched comparison.
full rationale
The paper's central evaluation claims rest on introducing a group matching score to 'correct' underestimation, then using a simple overfitting step to translate correctness back to prior metrics. This translation is explicitly described as enabling the reported surpass of GPT-4.1 and first human-surpassing result. Because the adjustment is fitted to achieve comparability, the numerical superiority is statistically forced rather than arising from an independent evaluation protocol matching prior work. TTM itself may contain independent algorithmic content, but the load-bearing performance claims (new SOTA, human exceedance) reduce to this fitted mapping. No other self-definitional or self-citation circularity is evident from the provided text.
Axiom & Free-Parameter Ledger
free parameters (1)
- overfitting step parameters
axioms (1)
- domain assumption Group matching score faithfully captures compositional capability beyond prior metrics
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We introduce a group matching score (GroupMatch) that evaluates the best overall matching rather than isolated pairwise comparisons... TTM selects matching-induced pseudo-labels for self-training and progressively relaxes the selection threshold
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
TTM enables SigLIP-B16 to surpass GPT-4.1 on MMVP-VLM, establishing a new state of the art
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 2 Pith papers
-
Active Testing of Large Language Models via Approximate Neyman Allocation
Proposes surrogate semantic entropy stratification followed by approximate Neyman allocation for active testing of LLMs on generative benchmarks, reporting up to 28% MSE reduction and 22.9% average budget savings vers...
-
Active Testing of Large Language Models via Approximate Neyman Allocation
Active testing via surrogate semantic entropy stratification and approximate Neyman allocation reduces MSE by up to 28% versus uniform sampling and saves about 23% of the labeling budget on language and multimodal benchmarks.
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Colorswap: A color and word order dataset for multimodal evaluation.arXiv preprint arXiv:2402.04492,
Jirayu Burapacheep, Ishan Gaur, Agam Bhatia, and Tristan Thrush. Colorswap: A color and word order dataset for multimodal evaluation.arXiv preprint arXiv:2402.04492,
-
[3]
Semi-supervised learning (chapelle, o
Olivier Chapelle, Bernhard Scholkopf, and Alexander Zien. Semi-supervised learning (chapelle, o. et al., eds.; 2006)[book reviews].IEEE Transactions on Neural Networks, 20(3):542–542,
work page 2006
-
[4]
On the Measure of Intelligence
Fran¸ cois Chollet. On the measure of intelligence.arXiv preprint arXiv:1911.01547,
work page internal anchor Pith review Pith/arXiv arXiv 1911
-
[5]
Arc prize 2024: Technical report, 2025
Francois Chollet, Mike Knoop, Gregory Kamradt, and Bryan Landers. Arc prize 2024: Technical report. arXiv preprint arXiv:2412.04604,
-
[6]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Anuj Diwan, Layne Berry, Eunsol Choi, David Harwath, and Kyle Mahowald. Why is winoground hard? investigating failures in visuolinguistic compositionality.arXiv preprint arXiv:2211.00768,
-
[8]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card.arXiv preprint arXiv:2410.21276,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Amita Kamath, Jack Hessel, and Kai-Wei Chang. What’s” up” with vision-language models? investigating their struggle with spatial reasoning.arXiv preprint arXiv:2310.19785,
-
[10]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Gemini: A Family of Highly Capable Multimodal Models
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie Millican, et al. Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Mohit Vaishnav and Tanel Tammet. A cognitive paradigm approach to probe the perception-reasoning interface in vlms.arXiv preprint arXiv:2501.13620,
-
[13]
Yifan Wu, Pengchuan Zhang, Wenhan Xiong, Barlas Oguz, James C Gee, and Yixin Nie. The role of chain-of-thought in complex vision-language reasoning task.arXiv preprint arXiv:2311.09193,
-
[14]
Daoan Zhang, Junming Yang, Hanjia Lyu, Zijian Jin, Yuan Yao, Mingkai Chen, and Jiebo Luo. Cocot: Contrastive chain-of-thought prompting for large multimodal models with multiple image inputs.arXiv preprint arXiv:2401.02582, 2024a. Jifan Zhang, Yifang Chen, Gregory Canal, Arnav Mohanty Das, Gantavya Bhatt, Stephen Mussmann, Yinglun Zhu, Jeff Bilmes, Simon ...
-
[15]
Following Li et al. (2025), we further convert the WhatsUp datasets into four directional variants with 2 × 2 group structures and present results in Table 8: Algorithm 1 again yields significant improvements—up to 135.1% relative gains and 95.5% relative error reduction—on top of SimpleMatch. Together, these results demonstrate that TTM is broadly effect...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.