LiveResearchBench: A Live Benchmark for User-Centric Deep Research in the Wild
Pith reviewed 2026-05-18 06:58 UTC · model grok-4.3
The pith
A benchmark of 100 expert-curated tasks enables systematic evaluation of AI systems that synthesize citation-grounded reports from live web sources.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
LiveResearchBench consists of 100 tasks spanning daily life, enterprise, and academic domains, each constructed to require extensive real-time web search and synthesis into citation-grounded long-form reports. DeepEval supplies four complementary evaluation protocols that jointly measure content quality, report-level attributes such as citation accuracy and association, and overall analytical depth, with the explicit goal of producing stable scores that align with human judgment. Together these resources support fair comparison across single-agent search systems, deep research agents, and multi-agent setups, revealing both recurring limitations and the system components that correlate with a
What carries the argument
LiveResearchBench is the set of 100 expert-curated, dynamic tasks that enforce user-centric, unambiguous, and search-intensive requirements; DeepEval is the accompanying evaluation suite that applies content-level and report-level metrics through four protocols to produce stable, human-aligned scores on citation-grounded outputs.
If this is right
- Current systems exhibit recurring weaknesses in citation accuracy, source association, and depth of analysis that limit report reliability.
- Design choices such as multi-step planning and explicit verification steps correlate with better performance on multi-faceted tasks.
- The benchmark enables repeated evaluation as web content evolves, supporting longitudinal tracking of agent progress.
- Single-agent versus multi-agent architectures show measurable differences in handling the search-intensive and synthesis demands of the tasks.
Where Pith is reading between the lines
- Widespread adoption could shift research focus from narrow question-answering metrics toward end-to-end report quality in agent development.
- The task design principles could extend to evaluating agents on private or domain-specific data sources beyond public web search.
- Periodic refresh of the task set would keep the benchmark aligned with changing real-world information needs.
Load-bearing premise
Expert curation over 1,500 hours produces tasks that stay unambiguous and genuinely demand multi-source live search for every user without introducing interpretation differences or hidden biases that would make comparisons across systems unfair.
What would settle it
Observe whether independent users or different research systems produce reports that satisfy the task requirements yet differ substantially in scope, sources, or conclusions, or whether many tasks can be answered adequately from model parameters alone without live search.
Figures

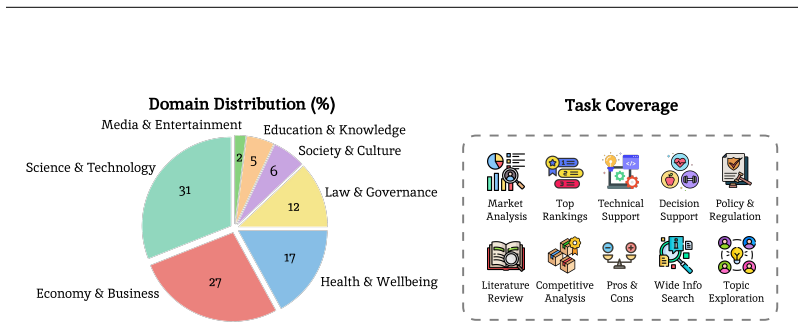



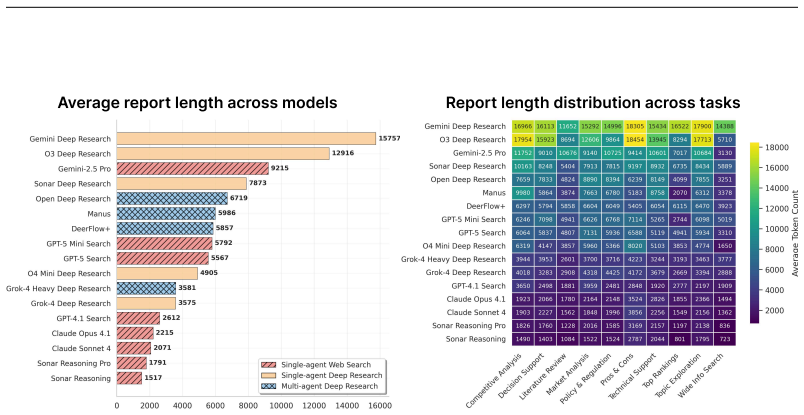

















read the original abstract
Deep research -- producing comprehensive, citation-grounded reports by searching and synthesizing information from hundreds of live web sources -- marks an important frontier for agentic systems. To rigorously evaluate this ability, four principles are essential: tasks should be (1) user-centric, reflecting realistic information needs, (2) dynamic, requiring up-to-date information beyond parametric knowledge, (3) unambiguous, ensuring consistent interpretation across users, and (4) multi-faceted and search-intensive, requiring search over numerous web sources and in-depth analysis. Existing benchmarks fall short of these principles, often focusing on narrow domains or posing ambiguous questions that hinder fair comparison. Guided by these principles, we introduce LiveResearchBench, a benchmark of 100 expert-curated tasks spanning daily life, enterprise, and academia, each requiring extensive, dynamic, real-time web search and synthesis. Built with over 1,500 hours of human labor, LiveResearchBench provides a rigorous basis for systematic evaluation. To evaluate citation-grounded long-form reports, we introduce DeepEval, a comprehensive suite covering both content- and report-level quality, including coverage, presentation, citation accuracy and association, consistency and depth of analysis. DeepEval integrates four complementary evaluation protocols, each designed to ensure stable assessment and high agreement with human judgments. Using LiveResearchBench and DeepEval, we conduct a comprehensive evaluation of 17 frontier deep research systems, including single-agent web search, single-agent deep research, and multi-agent systems. Our analysis reveals current strengths, recurring failure modes, and key system components needed to advance reliable, insightful deep research. Our code is available at: https://github.com/SalesforceAIResearch/LiveResearchBench.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces LiveResearchBench, a benchmark of 100 expert-curated tasks spanning daily life, enterprise, and academia, designed to evaluate deep research systems that produce comprehensive, citation-grounded reports from live web sources. Guided by four principles (user-centric, dynamic, unambiguous, and multi-faceted/search-intensive), the tasks were built with over 1,500 hours of human labor. The authors also present DeepEval, a suite with four complementary protocols for assessing content- and report-level quality (coverage, presentation, citation accuracy, consistency, depth), and use it to evaluate 17 frontier systems (single-agent search, deep research, and multi-agent), revealing strengths, failure modes, and needed components. Code is released at the provided GitHub link.
Significance. If the curation successfully yields tasks that are verifiably unambiguous and genuinely require extensive multi-source search without shortcuts or interpretation variance, LiveResearchBench would fill an important gap by providing a live, user-centric benchmark for an emerging frontier in agentic AI. The introduction of DeepEval with multiple protocols designed for high human agreement is a constructive contribution, as is the broad evaluation across 17 systems and the public code release. These elements could support more systematic progress tracking if the core task properties are empirically demonstrated.
major comments (2)
- [Abstract / Task Curation] Abstract and task creation description: the central claim that LiveResearchBench supplies a 'rigorous basis' for evaluation rests on the assertion that 1,500 hours of expert curation produces tasks that are unambiguously interpretable and require genuine multi-source search. No inter-annotator agreement metrics, pilot studies with multiple user cohorts, or empirical source-count distributions are reported to validate these properties, leaving the four principles as unverified assertions rather than demonstrated features. This directly affects the reliability of the 17-system comparison.
- [DeepEval and System Evaluation] Evaluation section (implied by the 17-system study): while DeepEval is described as integrating four protocols for stable assessment, the manuscript provides no quantitative results on agreement with human judgments or ablation of the individual protocols, making it difficult to assess whether the reported strengths and failure modes are robust.
minor comments (2)
- [Abstract] The abstract states tasks span 'daily life, enterprise, and academia' but does not break down the 100 tasks by category or provide example task statements; adding a table or appendix with representative examples would improve clarity.
- [Conclusion / Code Availability] The GitHub link is provided, but the manuscript does not specify which artifacts (task definitions, DeepEval implementation, or evaluation scripts) are included; explicit enumeration would aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for acknowledging the potential contributions of LiveResearchBench and DeepEval. We address each major comment below and indicate where we will revise the manuscript to incorporate additional evidence.
read point-by-point responses
-
Referee: [Abstract / Task Curation] Abstract and task creation description: the central claim that LiveResearchBench supplies a 'rigorous basis' for evaluation rests on the assertion that 1,500 hours of expert curation produces tasks that are unambiguously interpretable and require genuine multi-source search. No inter-annotator agreement metrics, pilot studies with multiple user cohorts, or empirical source-count distributions are reported to validate these properties, leaving the four principles as unverified assertions rather than demonstrated features. This directly affects the reliability of the 17-system comparison.
Authors: We agree that quantitative validation would strengthen the central claims. The 1,500 hours of curation involved iterative expert review to enforce the four principles, but the manuscript does not report inter-annotator agreement, pilot-study results, or source-count distributions. In the revised version we will add these metrics, including curator agreement scores, descriptions of pilot cohorts, and empirical distributions of sources per task, to empirically support the task properties and the reliability of the system comparisons. revision: yes
-
Referee: [DeepEval and System Evaluation] Evaluation section (implied by the 17-system study): while DeepEval is described as integrating four protocols for stable assessment, the manuscript provides no quantitative results on agreement with human judgments or ablation of the individual protocols, making it difficult to assess whether the reported strengths and failure modes are robust.
Authors: We appreciate the observation. The four protocols were designed for stability and high human agreement, yet the current manuscript does not include the corresponding quantitative agreement statistics or protocol ablations. We will revise the evaluation section to report correlation with human judgments and ablation results for each protocol, thereby providing direct evidence for the robustness of the strengths and failure modes observed across the 17 systems. revision: yes
Circularity Check
No circularity: benchmark and evaluation suite introduced as independent contributions
full rationale
The paper's core contribution is the expert-curated LiveResearchBench dataset of 100 tasks and the accompanying DeepEval evaluation suite, both presented as novel artifacts built from 1,500 hours of human labor. No mathematical derivations, equations, fitted parameters, or predictions appear in the provided text. The four guiding principles are stated as design criteria rather than derived results, and no self-citations or prior author work are invoked to justify uniqueness or force the benchmark's properties. The claims rest on the described curation process and evaluation protocols, which are self-contained and do not reduce to equivalent inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Expert human curation can produce tasks that are simultaneously user-centric, dynamic, unambiguous, and multi-faceted.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
four principles are essential: tasks should be (1) user-centric, reflecting realistic information needs, (2) dynamic, requiring up-to-date information beyond parametric knowledge, (3) unambiguous, ensuring consistent interpretation across users, and (4) multi-faceted and search-intensive
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
DeepEval integrates four complementary evaluation protocols... checklist-based, pointwise, pairwise, or rubric-tree
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 4 Pith papers
-
Rethinking Reasoning-Intensive Retrieval: Evaluating and Advancing Retrievers in Agentic Search Systems
BRIGHT-Pro and RTriever-Synth advance reasoning-intensive retrieval by adding multi-aspect evidence evaluation and aspect-decomposed synthetic training, with the fine-tuned RTriever-4B showing gains over its base model.
-
OpenJarvis: Personal AI, On Personal Devices
OpenJarvis decomposes personal AI into Intelligence, Engine, Agents, Tools & Memory, and Learning primitives and applies LLM-guided spec search to produce on-device configurations that reach within 3.2 pp of cloud bas...
-
MARCA: A Checklist-Based Benchmark for Multilingual Web Search
MARCA is a bilingual benchmark using 52 questions and validated checklists to evaluate LLM web-search completeness and correctness in English and Portuguese.
-
AutoResearch AI: Towards AI-Powered Research Automation for Scientific Discovery
A survey organizing AI-powered research automation into five workflow stages, defining AutoResearch and Vibe Research, and proposing five evaluation dimensions while noting domain-conditioned limits on autonomy.
Reference graph
Works this paper leans on
-
[1]
URLhttps://arxiv.org/abs/2409.16191. Haochen Tan, Zhijiang Guo, Zhan Shi, Lu Xu, Zhili Liu, Yunlong Feng, Xiaoguang Li, Yasheng Wang, Lifeng Shang, Qun Liu, and Linqi Song. Proxyqa: An alternative framework for evaluating long-form text generation with large language models, 2024. URL https://arxiv.org/ abs/2401.15042. Peiyi Wang, Lei Li, Liang Chen, Zefa...
-
[2]
Factual accuracy (e.g., whether the report is free of factual errors) is a separate criterion and should NOT be considered here
-
[3]
The same source can be used to cite multiple claims. This does NOT constitute a contradiction. OUTPUT FORMAT: Respond in JSON with the following fields: -specific_issues: A list of specific problems, with exact quotes or locations in the text (e.g., “In section X...”, “The claim that ‘...’ is unsupported”). -total_issues: Total number of issues (must matc...
-
[4]
Compare both reportsonly on depth, using the rubric above
-
[5]
Give each report a0–25 depth score
-
[6]
Decide the outcome: - If one report’s score is more than 1 point higher→it wins. - If the difference is≤1point→call it a tie. Exclude Entirely - Coverage (breadth of topics). - Factual correctness or consistency. - Presentation, formatting, style, grammar. - Citation traceability. - Length alone (verbosity̸=depth). Output Format (JSON only) { "winner": "A...
work page 2024
-
[7]
A URL may not always be attached immediately after a claim; in some cases, it appears at the end of a paragraph and is intended to support the preceding claims within that paragraph
-
[8]
Factual accuracy (e.g., whether the report is free of factual errors) is a separate criterion and should NOT be considered here. OUTPUT FORMAT: Respond in JSON with the following fields: -specific_issues: A list of specific problems, with exact quotes or locations in the text (e.g.,“In section X...”, “The claim that ‘...’ is unsupported”). -total_issues: ...
-
[9]
emerged within state and literati-dominated systems of production and taste [17][18]. Literati painting emphasized brushwork, monochrome ink, and poetic inscription, while academies cultivated refined mineral colors and precise draftsmanship; these aesthetics were shaped further under foreign dynasties, including the Mongol Yuan [18]. - Representative wor...
-
[10]
| | EGYPT_MAMLUK_OTTOMAN | Spice-route shifts; Ottoman integration and patronage reorientation [20] | | WCSUDAN_ISLAM | Islam's role; monumental adobe architecture; scholarship; coinage/trade
-
[11]
| | OTTOMAN_SILKS | Bursa workshops; nakkashane codification; palace demand and export; sericulture shifts [25] | | JAPAN_UKIYOE_POLY | Collaborative production; kento registration; urban subjects [26][27] | | EUROPE_19C_PRINT | Industrial proliferation; etching revival; Japonisme [28] | --- ### 6. Debates, Institutions, and Markets - Figuration and image...
work page 2016
-
[12]
Studies in Iconology: Humanistic Themes in the Art of the Renaissance: https://www. routledge.com/Studies-In-Iconology-Humanistic-Themes-In-The-Art-Of-The-Renaissance/ Panofsky-Panofsky/p/book/9780064300254
-
[13]
Painting and Experience in Fifteenth-Century Italy (Internet Archive item): https:// archive.org/details/paintingexperien00baxa
- [14]
-
[15]
Why Have There Been No Great Women Artists? (Thames & Hudson product page): https://www .thamesandhudson.com/products/why-have-there-been-no-great-women-artists
- [16]
-
[17]
The Predicament of Culture (Oxfam Books listing): https://www.oxfambookshop.au/products /581532_clifford_predicamentofculture
-
[18]
Global Art History (De Gruyter/Brill): https://www.degruyter.com/document/cover/isbn /9783839440612/product_pages
-
[19]
African Indigenous Knowledges in a Postcolonial World (Routledge): https://www. routledge.com/African-Indigenous-Knowledges-in-a-Postcolonial-World-A-Tribute-to-Toyin /Afolayan-Babalola-Ibrahim/p/book/9780367516833
-
[20]
Artforum (letters image associated with McEvilley's critique): https://www.artforum.com /wp-content/uploads/2016/09/article00_large-359.jpg
work page 2016
-
[21]
Artforum (additional page image referencing the critique): https://www.artforum.com/wp -content/uploads/2017/01/article_large-261.jpg
work page 2017
-
[22]
The Met Heilbrunn Timeline of Art History: https://www.metmuseum.org/toah
-
[23]
Oxford Art Online (Grove Art Online): https://digital.library.wisc.edu/1711.web/ oxfordart
-
[24]
Smarthistory (About/Essays): https://smarthistory.org/
-
[25]
JSTOR Archive Journals (about access): https://eifl.net/e-resources/jstor-archive- journals
-
[26]
Project MUSE (About): https://about.muse.jhu.edu/
-
[27]
Unit 7: Trade and Artistic Exchange (Met educator curriculum, Islamic world): https:// www.metmuseum.org/learn/educators/curriculum-resources/~/media/Files/Learn/For%20 Educators/Publications%20for%20Educators/Islamic%20Teacher%20Resource/Unit7.pdf
-
[28]
| Heilbrunn Timeline of Art History: https://www.metmuseum.org/ toah/ht/06/eac.html
China, 500-1000 A.D. | Heilbrunn Timeline of Art History: https://www.metmuseum.org/ toah/ht/06/eac.html
-
[29]
China, 1000-1400 A.D.: https://www.metmuseum.org/toah/ht/07/eac.html 32
-
[30]
Eastern and Southern Africa, 1400-1600 A.D.: https://www.metmuseum.org/toah/ht/08/afa. html
-
[31]
Egypt, 1400-1600 A.D.: https://www.metmuseum.org/toah/ht/08/afe.html
-
[32]
Guinea Coast, 1400-1600 A.D.: https://www.metmuseum.org/toah/ht/08/afg.html
-
[33]
Western and Central Sudan, 1000-1400 A.D.: https://www.metmuseum.org/toah/ht/07/afu. html
-
[34]
Age of Transition: Byzantine Culture in the Islamic World (Met symposia volume): https ://resources.metmuseum.org/resources/metpublications/pdf/ Age_of_Transition_Byzantine_Culture_in_the_Islamic_World.pdf
-
[35]
Tile from a Squinch (muqarnas element; Met 20.120.189): https://www.metmuseum.org/art/ collection/search/447256
-
[36]
Silks from Ottoman Turkey (Bursa sericulture; nakkashane; saz/chintamani): https://www .metmuseum.org/essays/silks-from-ottoman-turkey
-
[37]
metmuseum.org/essays/woodblock-prints-in-the-ukiyo-e-style
Woodblock Prints in the Ukiyo-e Style (technique; kento; collaboration): https://www. metmuseum.org/essays/woodblock-prints-in-the-ukiyo-e-style
-
[38]
Art of the Pleasure Quarters and the Ukiyo-e Style (urban culture; subjects; markets): https://www.metmuseum.org/essays/art-of-the-pleasure-quarters-and-the-ukiyo-e-style
-
[39]
The Print in the Nineteenth Century (industrial prints; etching revival; Japonisme): https://www.metmuseum.org/essays/the-print-in-the-nineteenth-century Notes on sources and images: All images embedded above are drawn exclusively from the provided resources. Assertions are restricted to the content of the cited materials. Gaps are acknowledged explicitly...
work page 2023
-
[40]
mental health and well-being (e.g., anxiety, depression, self-esteem, and loneliness),
-
[41]
In the report, I would like to have 6 pro arguments and 6 con arguments
educational and developmental impacts (e.g., learning, attention span, and digital literacy), 3) social and civil outcomes (e.g., friendships, community engagement, political awareness, and misinformation exposure), and 4) safety and risk factors (e.g., cyberbullying, privacy, exploitation, and screen-time effects). In the report, I would like to have 6 p...
work page 2020
-
[42]
h ttps:/ / www . car g or x. c om/blog/ elec tric -trucks-hit -the-tipping-poin t -is-2025-the- y ear
work page 2025
-
[43]
c om/indu str y -an aly sis / nor th-america-elec tric -truck -m ark e t
h ttps:/ / www .gminsigh ts. c om/indu str y -an aly sis / nor th-america-elec tric -truck -m ark e t
-
[44]
or g/ r epor ts / global-e v -outlook -2025/ tr ends-in-hea vy -duty -elec tric - v ehicles
h ttps:/ / www .iea. or g/ r epor ts / global-e v -outlook -2025/ tr ends-in-hea vy -duty -elec tric - v ehicles
work page 2025
-
[45]
c om/ ne ws / elec tric -trucks-m ark e t -t o-r each-124-billion-b y -2030/
h ttps:/ / www .ac t -ne ws. c om/ ne ws / elec tric -trucks-m ark e t -t o-r each-124-billion-b y -2030/ ... C u st omer Segmen ts and A dop tion Driv ers
work page 2030
-
[46]
h ttps:/ / www . tr anspor ta tion.g o v / rur al/ e v / t oolkit / e v -bene fits-and-ch alleng es / ch alleng es-and-e v olving- solutions
-
[47]
c om/ scienc e / ar ticle /pii/ S1361920924004723
h ttps:/ / www .scienc edir ec t. c om/ scienc e / ar ticle /pii/ S1361920924004723
-
[48]
c om/blog/ elec tric -truck -ch ar ging-the-in fr astruc tur e-ch alleng es
h ttps:/ / www .helio x -ener g y . c om/blog/ elec tric -truck -ch ar ging-the-in fr astruc tur e-ch alleng es
-
[49]
h ttps:/ / www .nr el.g o v / ne ws / fea tur e /2025/ the-dawn-o f-elec tric -trucking-calls-for -high-po w er -ch ar ging
work page 2025
-
[50]
h ttps:/ / www . cb tne ws. c om/ elec tric - v ehicle-ch ar ging-in fr astruc tur e-ch alleng es-and-solutions / ... Mismat ched in- t e xt citations and r ef er ences An aly sis: The r epor t r eu ses cita tion n umbers acr oss m ultiple r e fer enc e lists, ca u sing ambiguity in m apping in- t e x t cita tions t o sour c es. Figure 14: Error pattern: ...
-
[51]
Ex t ensor carpi uln aris injuries in t ennis pla y ers: a study o f 28 cases
Mon talv an B, P arier J, Br asseur JL, L e V ie t D , Dr ape JL. Ex t ensor carpi uln aris injuries in t ennis pla y ers: a study o f 28 cases. *Br J Spor ts Med * . 2006;40(5):424–429. (I den tifies ECU t endinopa th y , instability , rup tur e; outlines immobiliza tion and sur gical pr o t oc ols.)
work page 2006
-
[52]
Ph y sio sour c es on ECU t endinopa th y —o v eru se mech anism, s ymp t oms, c ommon in r ack e t spor ts [2015+ g ener al kno wledg e]
work page 2015
-
[53]
L ogli AL e t al. Uln ar wrist pain in a t ennis pla y er: case r e vie w and disc u ssion. * JB JS R e vie ws * . 2022. (Disc u sses TF C C, UT ligamen t injur y and ar thr osc opic r epair .) ... Mis sing Link s (URLs) An aly sis: In-t e x t cita tions (e .g ., [2], [9]) either lack a pr oper r e fer enc e en tr y or appear in the r e fer enc e list wit...
work page 2022
-
[54]
F or d Br oadens Elec trifica tion Str a t eg y t o R each Mor e ... (2024, A ugu st 21). F r om ther oad. for d. c om. h ttps:/ / www . fr om ther oad. for d. c om/ u s / en/ ar ticles /2024/ for d-br oadens-elec trifica tion-str a t eg y -t o-r each- mor e-c u st omers-
work page 2024
-
[55]
F or d ' s R ole in Sh aping the 2024 Elec tric V ehicle Mark e t. (n. d.). Willisfor d. c om. h ttps:/ / www . willisfor d. c om/ for d-elec tric - v ehicle-m ark e t -2024-outlook.h tm
work page 2024
-
[56]
In t egr a t ed Su stain ability and F in ancial R epor t 2024. (2024, April 22). C orpor a t e . for d. c om. h ttps:/ / c orpor a t e . for d. c om/ c on t en t / dam/ c orpor a t e / u s / en-u s / doc umen ts / r epor ts /2024-in t egr a t ed-su stain ability - and-fin ancial-r epor t.pdf
work page 2024
-
[57]
Mu stang Suv 2024. (2025, Sep t ember 6). C er t -t est -ne w .itlab .stan for d. edu. h ttps:/ / c er t -t est - ne w .itlab .stan for d. edu/ m u stang-suv -2024 R eport fr om Manu s: Figure 17: Error pattern: references not mentioned in the report. 39 R eport fr om Gemini-2.5 Flash: C ompr ehensiv e R esear ch R eport: Global ESG R eporting Str a t egi...
work page 2024
-
[58]
Multi-C olumn C omparison T able | Dimension | SEC Clim a t e Disclosur e R ule (as o f 2025, c urr en tly sta y ed)| EU C orpor a t e Su stain ability R epor ting Dir ec tiv e (C SRD) (as o f 2025)| California SB-253 & SB-261 (as o f 2025) I t' s impor tan t t o no t e th a t the r egula t or y landscape for ESG r epor ting is dyn amic, and some o f the ...
work page 2025
-
[59]
Sleep and A cademic Ex c ellenc e: A Deeper L ook. (2024). * Stan for d L ong e vity * . [h ttps:/ / long e vity .stan for d. edu/lifestyle /2024/01/10/ sleep-and-academic -e x c ellenc e-a-deeper -look /](h ttps:/ / long e vity .stan for d. edu/lifestyle /2024/01/10/ sleep-and-academic -e x c ellenc e-a-deeper -look /)
work page 2024
-
[60]
P olyph asic Sleep: P r os and C ons o f Shor t Sleep Schedule . (2018). *V er y w ell Health * . [h ttps:/ / www . v er y w ellhealth. c om/pr os-and-c ons-o f-a-polyph asic -sleep-schedule-4165843](h ttps:/ / www . v er y w ellhealth. c om/pr os-and-c ons-o f-a-polyph asic -sleep-schedule-4165843)
work page 2018
-
[61]
Sleep h y giene: Simple pr ac tic es for be tt er r est. (2025). *Har v ar d Health P ublishing * . [h ttps:/ / www .health.h ar v ar d. edu/ sta ying-health y / sleep-h y giene-simple-pr ac tic es-for -be tt er -r est](h ttps:/ / www .health.h ar v ar d. edu/ sta ying-health y / sleep-h y giene-simple-pr ac tic es-for -be tt er -r est) ... R e fer enc es
work page 2025
-
[62]
The impac t o f e x t ended sleep on da y time aler tness, vigilanc e and mood. (2025). *R esear chGa t e * . [h ttps:/ / www .r esear chga t e .ne t / publica tion/8370477_ The _impac t_ o f _ e x t ended_ sleep _ on_ da y time _ aler tness _ vigilanc e _ and_mood] (h ttps:/ / www .r esear chga t e .ne t / publica tion/8370477_ The _impac t_ o f _ e x t ...
-
[63]
Cir cadian Rh y thms | Na tion al Institut e o f Gener al Medical Scienc es. (2025). *NI GMS * . [h ttps:/ / www .nigms.nih.g o v / educa tion/ fac t -shee ts /P ag es / cir cadian-rh y thms](h ttps:/ / www .nigms.nih.g o v / educa tion/ fac t -shee ts /P ag es / cir cadian-rh y thms) ... Out -of -or der R ef er ences An aly sis: The r e fer enc e list is...
work page 2025
-
[64]
** Sa uc on y E ndorphin Elit e 2** * R unner ' s W orld R a ting Ca t eg or y: Best Ligh tw eigh t R ac er
-
[65]
**Br ooks Calder a 8** * R unner ' s W orld R a ting Ca t eg or y: Best Ov er all T r ail * C omposit e Sc or e: 0.53
-
[66]
**L ululemon Wildfeel ** * R unner ' s W orld R a ting Ca t eg or y: Best Hybrid * C omposit e Sc or e: 0.33 ... * W eigh t: 0.0 o z * Dr op: 0.0 mm * W eigh t: 4.5 o z * Dr op: 0.0 mm * W eigh t: 1.0 o z * Dr op: 7.0 mm * C omposit e Sc or e: 1.11 Hallucinat ed inf or mation An aly sis: The r epor t fabrica t es da ta and pr oduc es a logically inc onsis...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.