Instructions are all you need: Self-supervised Reinforcement Learning for Instruction Following
Pith reviewed 2026-05-18 06:51 UTC · model grok-4.3
The pith
Language models can improve at following complex instructions by learning rewards directly from the instructions using self-supervised reinforcement learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
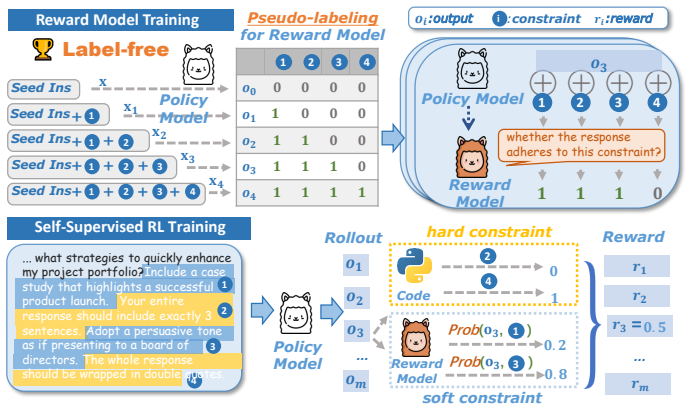
By decomposing instructions into constraints and using constraint-wise binary classification to generate pseudo-labels, the method produces reward signals sufficient to train an effective reward model without any external supervision or human labels, which then supports reinforcement learning that improves instruction following across multiple datasets.
What carries the argument
Constraint decomposition paired with constraint-wise binary classification to generate pseudo-labels directly from instructions for reward model training.
If this is right
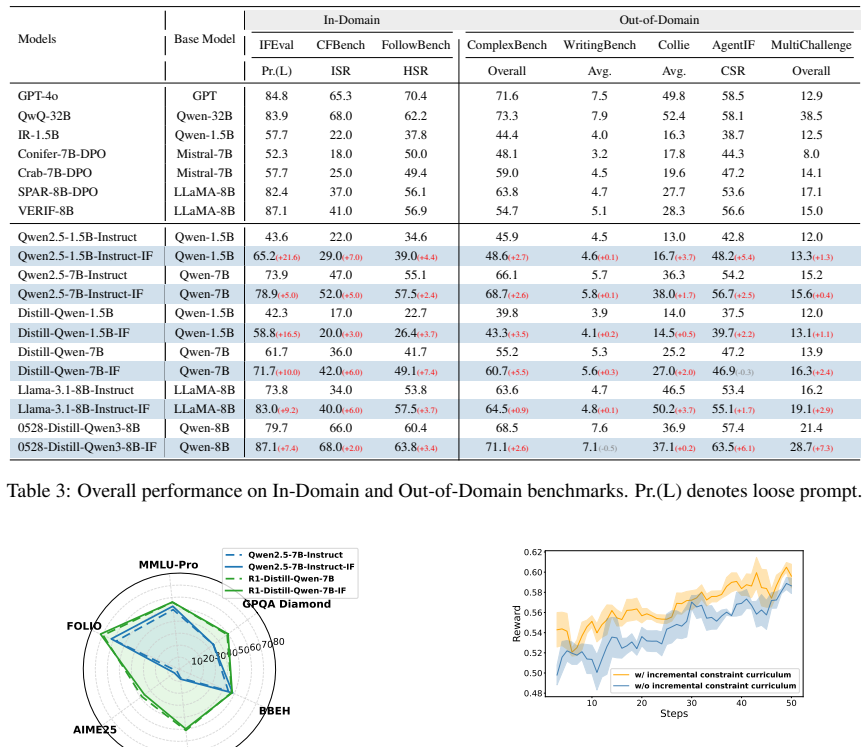
- Better results on the three in-domain instruction-following datasets used in the experiments.
- Stronger generalization to the five out-of-domain datasets, including agentic and multi-turn settings.
- No need for external reward signals or human annotations during training.
- Computational efficiency is preserved while handling the sparse-reward problem of multi-constraint tasks.
Where Pith is reading between the lines
- The same decomposition-plus-binary-check pattern could be tested on other tasks where behavior is defined by explicit constraints, such as tool-use sequences or planning problems.
- Scaling the approach to larger base models might reveal whether pseudo-label quality improves or plateaus as model capacity grows.
- Combining the instruction-derived rewards with a small amount of human preference data could be explored as a hybrid training signal.
Load-bearing premise
Rewards created by splitting instructions into constraints and running binary checks on each one are accurate enough to train a useful reward model without outside labels.
What would settle it
Human raters scoring model outputs on a fresh set of multi-constraint instructions would show no alignment with the pseudo-rewards produced by the binary classification step.
Figures





read the original abstract
Language models often struggle to follow multi-constraint instructions that are crucial for real-world applications. Existing reinforcement learning (RL) approaches suffer from dependency on external supervision and sparse reward signals from multi-constraint tasks. We propose a label-free self-supervised RL framework that eliminates dependency on external supervision by deriving reward signals directly from instructions and generating pseudo-labels for reward model training. Our approach introduces constraint decomposition strategies and efficient constraint-wise binary classification to address sparse reward challenges while maintaining computational efficiency. Experiments show that our approach generalizes well, achieving strong improvements across 3 in-domain and 5 out-of-domain datasets, including challenging agentic and multi-turn instruction following. The data and code are publicly available at https://github.com/Rainier-rq/verl-if
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a label-free self-supervised RL framework for language model instruction following. Reward signals are derived directly from input instructions via constraint decomposition strategies followed by constraint-wise binary classification to generate pseudo-labels for reward model training. This eliminates external supervision and addresses sparse rewards in multi-constraint settings. Experiments report strong improvements on 3 in-domain and 5 out-of-domain datasets, including agentic and multi-turn tasks, with code and data released publicly.
Significance. If the pseudo-labels prove accurate, the approach would be significant for scaling RL-based instruction tuning without human labels or external rewards, directly tackling sparse reward issues in complex instructions. Public release of data and code supports reproducibility and is a clear strength.
major comments (2)
- [Abstract] Abstract: the central claim that constraint decomposition plus binary classification produces sufficiently accurate pseudo-labels for effective RL training is load-bearing but unsupported. No direct measurement of pseudo-label quality (e.g., error rates against human references or failure modes on multi-constraint/agentic instructions) is provided, leaving open whether the reported gains arise from the method or from distorted reward landscapes.
- [Experiments] Experiments section (implied by abstract claims): performance gains are asserted across 3 in-domain and 5 out-of-domain datasets without reported baselines, statistical tests, data exclusion criteria, or ablation on the decomposition step. This prevents verification that the self-supervised signal generalizes rather than fitting to artifacts of the pseudo-labeling process.
minor comments (2)
- Clarify the precise constraint decomposition rules for different instruction types (e.g., agentic vs. multi-turn) and how binary classifiers are trained and thresholded.
- Add a dedicated subsection or table quantifying pseudo-label agreement or downstream sensitivity to label noise.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address each major comment below and have revised the manuscript accordingly to strengthen the evidence for our claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that constraint decomposition plus binary classification produces sufficiently accurate pseudo-labels for effective RL training is load-bearing but unsupported. No direct measurement of pseudo-label quality (e.g., error rates against human references or failure modes on multi-constraint/agentic instructions) is provided, leaving open whether the reported gains arise from the method or from distorted reward landscapes.
Authors: We agree that direct measurement of pseudo-label quality would provide stronger support for the central claim. Although generalization to out-of-domain tasks offers indirect validation, we have added a new analysis subsection reporting pseudo-label accuracy against human references on a held-out set, including error rates and discussion of failure modes for multi-constraint and agentic instructions. This revision clarifies that performance gains stem from the method rather than reward distortion. revision: yes
-
Referee: [Experiments] Experiments section (implied by abstract claims): performance gains are asserted across 3 in-domain and 5 out-of-domain datasets without reported baselines, statistical tests, data exclusion criteria, or ablation on the decomposition step. This prevents verification that the self-supervised signal generalizes rather than fitting to artifacts of the pseudo-labeling process.
Authors: The original manuscript reports baseline comparisons and results across the specified datasets. To address the concerns, we have added statistical significance tests across multiple runs, explicit data exclusion criteria, and an ablation isolating the constraint decomposition step. These revisions demonstrate that the self-supervised signal generalizes and is not an artifact of the pseudo-labeling process. revision: yes
Circularity Check
No significant circularity; reward construction is explicit and externally validated
full rationale
The paper constructs reward signals directly from input instructions using constraint decomposition followed by constraint-wise binary classification to produce pseudo-labels for the reward model. This is a definitional procedure applied to the instructions themselves rather than a fitted parameter or prediction that reduces back to the same fitted values. The subsequent RL stage optimizes the policy against the resulting reward model, with performance measured on separate in-domain and out-of-domain datasets. No equations or self-citations are shown to create a closed loop where a claimed result equals its own input by construction. The approach is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Instructions contain decomposable constraints that can be evaluated independently via binary classification to generate usable reward signals
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
constraint decomposition strategies and efficient constraint-wise binary classification to address sparse reward challenges
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_injective unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
pseudo-labels: (ok, ck, label=1) ... (ok-1, ck, label=0)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 2 Pith papers
-
SEIF: Self-Evolving Reinforcement Learning for Instruction Following
SEIF creates a self-reinforcing loop in which an LLM alternately generates increasingly difficult instructions and learns to follow them better using reinforcement learning signals from its own judgments.
-
From Coarse to Fine: Benchmarking and Reward Modeling for Writing-Centric Generation Tasks
WEval and WRL introduce fine-grained benchmarking and requirement-selective sample construction for training writing reward models, yielding substantial gains on writing benchmarks with strong generalization.
Reference graph
Works this paper leans on
-
[1]
InFindings of the Association for Computational Linguistics: ACL 2025, pages 18632–18702
Multichallenge: A realistic multi-turn con- versation evaluation benchmark challenging to frontier llms. InFindings of the Association for Computational Linguistics: ACL 2025, pages 18632–18702. Guanting Dong, Keming Lu, Chengpeng Li, Tingyu Xia, Bowen Yu, Chang Zhou, and Jingren Zhou
work page 2025
-
[2]
Self-play with execution feedback: Improv- ing instruction-following capabilities of large lan- guage models.arXiv preprint arXiv:2406.13542. Kehua Feng, Keyan Ding, Weijie Wang, Xiang Zhuang, Zeyuan Wang, Ming Qin, Yu Zhao, Jianhua Yao, Qiang Zhang, and Huajun Chen
-
[3]
Sciknoweval: Evaluating multi-level scien- tific knowledge of large language models.arXiv preprint arXiv:2406.09098. Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ah- mad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, and 1 others. 2024. The llama 3 herd of models.arXiv preprint arXiv:2407.21783....
-
[4]
Big-bench extra hard.arXiv preprint arXiv:2502.19187, 2025
Big-bench extra hard.arXiv preprint arXiv:2502.19187. Andreas Köpf, Yannic Kilcher, Dimitri von Rütte, Sotiris Anagnostidis, Zhi Rui Tam, Keith Stevens, Abdullah Barhoum, Duc Nguyen, Oliver Stanley, Richárd Nagyfi, and 1 others. 2024. Openassis- tant conversations-democratizing large language model alignment.Advances in Neural Informa- tion Processing Sys...
-
[5]
Agentif: Benchmarking instruction following of large language models in agentic scenarios
Agentif: Benchmarking instruction follow- ing of large language models in agentic scenarios. arXiv preprint arXiv:2505.16944. Yunjia Qi, Hao Peng, Xiaozhi Wang, Bin Xu, Lei Hou, and Juanzi Li. 2024. Constraint back- translation improves complex instruction follow- ing of large language models.arXiv preprint arXiv:2410.24175. Yulei Qin, Gang Li, Zongyi Li,...
-
[6]
InFirst Conference on Language Modeling
Gpqa: A graduate-level google-proof q&a benchmark. InFirst Conference on Language Modeling. Qingyu Ren, Jie Zeng, Qianyu He, Jiaqing Liang, Yanghua Xiao, Weikang Zhou, Zeye Sun, and Fei Yu. 2025. Step-by-step mastery: Enhancing soft constraint following ability of large language models.Preprint, arXiv:2501.04945. ByteDance Seed, Jiaze Chen, Tiantian Fan, ...
-
[7]
Seed1.5-thinking: Advancing superb reasoning models with reinforce- ment learning
Seed1. 5-thinking: Advancing superb rea- soning models with reinforcement learning.arXiv preprint arXiv:2504.13914. Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, and 1 oth- ers. 2024. Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint ar...
-
[8]
Conifer: Improving complex constrained instruction-following ability of large language models.arXiv preprint arXiv:2404.02823. Qwen Team. 2024. Qwen2 technical report.arXiv preprint arXiv:2412.15115. Yizhong Wang, Yeganeh Kordi, Swaroop Mishra, Al- isa Liu, Noah A Smith, Daniel Khashabi, and Han- naneh Hajishirzi. 2022a. Self-instruct: Aligning language m...
-
[9]
Qwen3 technical report.arXiv preprint arXiv:2505.09388. Shunyu Yao, Howard Chen, Austin W Hanjie, Run- zhe Yang, and Karthik Narasimhan. 2023. Collie: Systematic construction of constrained text gener- ation tasks.arXiv preprint arXiv:2307.08689. Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, ...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[10]
Cfbench: A comprehensive constraints- following benchmark for llms.arXiv preprint arXiv:2408.01122. Jeffrey Zhou, Tianjian Lu, Swaroop Mishra, Sid- dhartha Brahma, Sujoy Basu, Yi Luan, Denny Zhou, and Le Hou. 2023. Instruction-following evaluation for large language models.arXiv preprint arXiv:2311.07911. A Appendix A.1 Dataset Analysis A.1.1 Constraint D...
-
[11]
I currently have a seed question, but the seed questions are relatively simple. To make the instructions more complex, I want you to identify and return five atomic constraints that can be added to the seed question
-
[12]
I will provide [Seed Question] and [Constraint References], and you can use these references to propose five constraints that would increase the difficulty of the seed question
-
[13]
You may choose one or more constraints from the list or propose new ones if needed
[Constraint References] are just suggestions. You may choose one or more constraints from the list or propose new ones if needed
-
[14]
Your task is only to generate new constraints that can be added to it
Do not modify or rewrite the seed question. Your task is only to generate new constraints that can be added to it
-
[15]
Return the added constraints in the following JSON format: json { "c1": "<first constraint>", "c2": "<second constraint>", "c3": "<third constraint>", "c4": "<fourth constraint>", "c5": "<fifth constraint>" }
-
[16]
No explanation, no reformulated question, no analysis—only the JSON structure
Do not return anything else. No explanation, no reformulated question, no analysis—only the JSON structure. [Constraint References]
-
[17]
Lexical content constraint : {Definition} {Example}
-
[18]
Word Count : {Definition} {Example}
-
[19]
Rule Constraint : {Definition} {Example} [Seed Question] {raw_question} Table 11: Prompt for generating constraints. dataset accordingly. WritingBench (Wu et al., 2025): It is a comprehensive benchmark designed to evaluate LLMs across 6 core writing domains and 100 subdomains, encompassing creative, persuasive, informative, and technical writing. Collie (...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.