MemoryBench: A Benchmark for Memory and Continual Learning in LLM Systems
Pith reviewed 2026-05-18 06:16 UTC · model grok-4.3
The pith
Existing benchmarks fall short for testing LLM memory and continual learning from user feedback.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We propose a user feedback simulation framework and a comprehensive benchmark covering multiple domains, languages, and types of tasks to evaluate the continual learning abilities of LLM systems. Experiments show that the effectiveness and efficiency of state-of-the-art baselines are far from satisfying.
What carries the argument
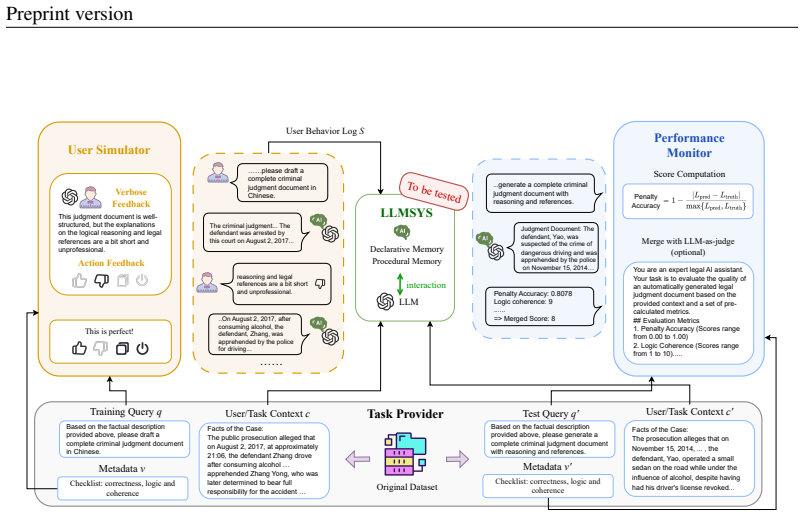
User feedback simulation framework that generates realistic interactions to build the MemoryBench for assessing continual learning in LLM systems.
If this is right
- LLM systems should incorporate better mechanisms to learn from accumulated user feedback over time.
- Evaluation of memory capabilities needs to shift from long reading comprehension to diverse, interactive tasks.
- Future optimization algorithms for LLMs may focus on continual learning to overcome scaling limits.
- New methods are needed to improve both the effectiveness and efficiency of memory in LLM services.
Where Pith is reading between the lines
- If the benchmark results hold, real-world LLM deployments could benefit from feedback-driven updates to reduce errors over time.
- This approach connects to broader efforts in lifelong learning for AI systems beyond LLMs.
- Extending the benchmark to include more complex user behaviors could reveal additional weaknesses in current systems.
Load-bearing premise
The user feedback simulation framework accurately represents real user behavior in deployed LLM services.
What would settle it
Running a controlled experiment where an LLM system is deployed with real users and comparing its learning performance over time to the benchmark predictions.
Figures










read the original abstract
Scaling up data, parameters, and test-time computation has been the mainstream methods to improve LLM systems (LLMsys), but their upper bounds are almost reached due to the gradual depletion of high-quality data and marginal gains obtained from larger computational resource consumption. Inspired by the abilities of human and traditional AI systems in learning from practice, constructing memory and continual learning frameworks for LLMsys has become an important and popular research direction in recent literature. Yet, existing benchmarks for LLM memory often focus on evaluating the system on homogeneous reading comprehension tasks with long-form inputs rather than testing their abilities to learn from accumulated user feedback in service time. Therefore, we propose a user feedback simulation framework and a comprehensive benchmark covering multiple domains, languages, and types of tasks to evaluate the continual learning abilities of LLMsys. Experiments show that the effectiveness and efficiency of state-of-the-art baselines are far from satisfying, and we hope this benchmark could pave the way for future studies on LLM memory and optimization algorithms.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MemoryBench, a benchmark for memory and continual learning in LLM systems. It argues that prior benchmarks emphasize homogeneous reading-comprehension tasks with long inputs, whereas MemoryBench employs a user-feedback simulation framework to evaluate learning from accumulated service-time interactions across multiple domains, languages, and task types. Experiments on state-of-the-art baselines are reported to show unsatisfactory effectiveness and efficiency.
Significance. If the simulation framework produces interactions representative of real deployed LLM usage, the benchmark could usefully expose gaps in current memory mechanisms and motivate more practical continual-learning algorithms. The work supplies a new evaluation resource in an area where existing tests are acknowledged to be limited.
major comments (2)
- [§4] §4 (User Feedback Simulation Framework): No quantitative validation is provided for the simulation (e.g., statistical comparison to production logs, human-rater studies of simulated vs. real sessions, or ablation on simulation parameters). This is load-bearing for the central claim that baselines perform poorly on service-time learning, because the observed results could be artifacts of how queries, feedback signals, and task distributions are generated.
- [Experiments section] Experiments section and associated tables: Results are presented without error bars, details on data-selection criteria, or explicit description of how the benchmark instances were constructed and filtered. These omissions make it difficult to judge the reliability and generalizability of the headline finding that SOTA methods are “far from satisfying.”
minor comments (2)
- [Abstract] The abstract and introduction could more explicitly state the number of domains, languages, and task types covered by the benchmark to help readers assess its breadth.
- [§3] Notation for feedback signals and memory-update rules should be defined once in a dedicated subsection rather than introduced piecemeal.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments on our manuscript. We address each major comment below in detail and indicate where revisions will be made to strengthen the paper.
read point-by-point responses
-
Referee: [§4] §4 (User Feedback Simulation Framework): No quantitative validation is provided for the simulation (e.g., statistical comparison to production logs, human-rater studies of simulated vs. real sessions, or ablation on simulation parameters). This is load-bearing for the central claim that baselines perform poorly on service-time learning, because the observed results could be artifacts of how queries, feedback signals, and task distributions are generated.
Authors: We agree that quantitative validation of the simulation is important for supporting claims about real-world applicability. We do not have access to proprietary production logs and thus cannot perform statistical comparisons against them. However, we will add human-rater evaluation studies comparing simulated sessions to real user interactions and include ablations on simulation parameters (such as query generation and feedback signal distributions) in the revised manuscript to demonstrate representativeness. revision: partial
-
Referee: [Experiments section] Experiments section and associated tables: Results are presented without error bars, details on data-selection criteria, or explicit description of how the benchmark instances were constructed and filtered. These omissions make it difficult to judge the reliability and generalizability of the headline finding that SOTA methods are “far from satisfying.”
Authors: We acknowledge that the current presentation lacks these details, which limits assessment of reliability. In the revised version, we will add error bars computed over multiple random seeds or runs, provide explicit data-selection criteria, and include a detailed description of benchmark instance construction, filtering steps, and task distribution generation. revision: yes
- Statistical comparison to production logs, as we lack access to proprietary real-world deployment data.
Circularity Check
No significant circularity in benchmark proposal or experimental claims
full rationale
The paper proposes a user feedback simulation framework and a new benchmark covering multiple domains and tasks to evaluate continual learning in LLM systems. It reports direct experimental results showing that state-of-the-art baselines perform poorly in effectiveness and efficiency. This does not involve any self-definitional reduction, fitted inputs renamed as predictions, or load-bearing self-citations that collapse the central claim to prior unverified work by the same authors. The benchmark construction and evaluation results are independent of the reported outcomes; the simulation defines the test environment rather than deriving the performance numbers by construction. The paper is self-contained against its own defined tasks with no evident circular derivation chain.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Simulated user feedback accurately reflects real-world continual learning scenarios for LLM systems.
Forward citations
Cited by 13 Pith papers
-
GroupMemBench: Benchmarking LLM Agent Memory in Multi-Party Conversations
GroupMemBench shows leading LLM memory systems reach only 46% average accuracy on multi-party tasks, with a simple BM25 baseline matching or beating most of them.
-
MemGym: a Long-Horizon Memory Environment for LLM Agents
MemGym unifies agent gyms into a memory benchmark with isolated scoring across tool-use, research, coding, and computer-use regimes plus a lightweight reward model for tractable coding evaluation.
-
EXG: Self-Evolving Agents with Experience Graphs
EXG is an experience graph framework for self-evolving LLM agents that supports online real-time growth and offline reuse to enhance solution quality and efficiency on code generation and reasoning benchmarks.
-
GroupMemBench: Benchmarking LLM Agent Memory in Multi-Party Conversations
GroupMemBench is a new benchmark exposing that LLM agent memory systems fail on group conversation properties like speaker-grounded tracking and audience-adapted responses, with top systems at 46% accuracy.
-
Skill Retrieval Augmentation for Agentic AI
Introduces the SRA paradigm and SRA-Bench benchmark showing retrieval-based skill augmentation improves agent performance but skill incorporation remains a bottleneck regardless of retrieval quality.
-
Skill Retrieval Augmentation for Agentic AI
Agents improve when they retrieve skills on demand from large corpora, yet current models cannot selectively decide when to load or ignore a retrieved skill.
-
PERMA: Benchmarking Personalized Memory Agents via Event-Driven Preference and Realistic Task Environments
PERMA is a new benchmark using temporally ordered events, text variability, and linguistic alignment to evaluate LLM memory agents on persona consistency beyond simple retrieval.
-
EvoMemBench: Benchmarking Agent Memory from a Self-Evolving Perspective
EvoMemBench evaluates 15 memory methods for LLM agents and finds long-context baselines competitive with no single memory approach working consistently across settings.
-
State Contamination in Memory-Augmented LLM Agents
Toxic context can be laundered into memory summaries that stay below toxicity thresholds while still driving higher downstream toxicity in LLM agents compared to neutral baselines.
-
Trust Your Memory: Verifiable Control of Smart Homes through Reinforcement Learning with Multi-dimensional Rewards
Introduces MemHome benchmark and RL with multi-dimensional rewards for memory-driven smart home device control.
-
ATANT: An Evaluation Framework for AI Continuity
ATANT defines AI continuity via seven properties and offers a 10-checkpoint, LLM-free test using 250 stories to check if systems retrieve correct facts without cross-contamination.
-
Improve Large Language Model Systems with User Logs
UNO distills user logs into semi-structured rules and preferences, applies query-and-feedback clustering to handle heterogeneity, quantifies cognitive gaps to filter noise, and builds primary and reflective modules th...
-
ATANT v1.1: Positioning Continuity Evaluation Against Memory, Long-Context, and Agentic-Memory Benchmarks
Existing memory benchmarks cover at most two of the seven continuity properties from ATANT v1.0, with a median of one and none covering more than two.
Reference graph
Works this paper leans on
-
[1]
Association for Computational Linguistics. URLhttps://aclanthology.org/ W05-0909/. Valeriia Bolotova, Vladislav Blinov, Falk Scholer, W. Bruce Croft, and Mark Sanderson. A non- factoid question-answering taxonomy. InProceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR ’22, pp. 1196–1207, Ne...
-
[2]
Lianlei Shan, Shixian Luo, Zezhou Zhu, Yu Yuan, and Yong Wu
URLhttps://arxiv.org/abs/2409.16191. Lianlei Shan, Shixian Luo, Zezhou Zhu, Yu Yuan, and Yong Wu. Cognitive memory in large lan- guage models, 2025. URLhttps://arxiv.org/abs/2504.02441. Xuehua Shen and ChengXiang Zhai. Active feedback in ad hoc information retrieval. InPro- ceedings of the 28th Annual International ACM SIGIR Conference on Research and Dev...
-
[3]
Answer Prediction (F1) – Overall
ISSN 0306-4573. doi: https://doi.org/10.1016/j.ipm.2004.08.010. URLhttps:// www.sciencedirect.com/science/article/pii/S0306457304001001. For- mal Methods for Information Retrieval. Di Wu, Hongwei Wang, Wenhao Yu, Yuwei Zhang, Kai-Wei Chang, and Dong Yu. Longmemeval: Benchmarking chat assistants on long-term interactive memory. InThe Thirteenth Interna- ti...
-
[4]
Your responses should solely rely on the retrieved dialog history. If the informa- tion in the dialog history is insufficient to answer the question, you must admit that you don’t know the answer
-
[5]
This question is being asked in the context of{Date}. [Question]{Question} [Answer] Due to the large dataset size, we randomly select 1,000 queries from each subset for Mem- oryBench. The evaluation of DialSim is an LLM-assisted accuracy assessment: first, we use exact match to check whether the predicted answer is identical to the golden answer; if exact...
work page 2023
-
[6]
Penalty Accuracy (Scores range from 0.00 to 1.00) time score:{time score}(Measures the accuracy of the prison sentence duration.) amount score:{amount score}(Measures the accuracy of the monetary fine amount.)
-
[7]
Convicting Accuracy (Scores range from 0.00 to 1.00) crime recall:{crime recall}(The proportion of actual charges that the system correctly identifies.) crime precision:{crime precision}(The proportion of predicted charges that are accurate.)
-
[8]
Referencing Accuracy (Scores range from 0.00 to 1.00) penalcode index recall:{penalcode index recall}(The proportion of correctly cited ground-truth statutes among all relevant statutes.) penalcode index precision:{penalcode index precision}(The proportion of correctly cited statutes among all citations in the generated judgment.) reasoning meteor:{reason...
-
[9]
Scores range from 0.00 (no similarity) to 1.00 (perfect semantic match)
Semantic Similarity (bert score): Measures the semantic similarity between the ’Gen- erated Research Idea’ and the ’Ground Truth Research Idea’. Scores range from 0.00 (no similarity) to 1.00 (perfect semantic match). bert score:{bert score}
-
[10]
Scores range from 1 (minimal overlap) to 10 (perfect overlap)
Idea Overlap (llm rating score): An LLM-based rating of the idea overlap between the ’Generated Research Idea’ and the ’Ground Truth’. Scores range from 1 (minimal overlap) to 10 (perfect overlap). llm rating score:{llm rating score}
-
[11]
This score is derived by ranking the generated idea(s) against the ground truth idea
Novelty Insight Score (llm novelty ranking score): Quantifies the novelty of the ’Gen- erated Research Idea’ relative to the ’Ground Truth’. This score is derived by ranking the generated idea(s) against the ground truth idea. Scores range from 0.00 to 1.00. * A score near **0.00** means the generated idea is significantly less novel than the ground truth...
-
[12]
Scores range from 0.00 to 1.00
Feasibility Insight Score (llm feasibility ranking score): Quantifies the feasibility of the ’Generated Research Idea’ relative to the ’Ground Truth’, using the same ranking method- ology as the Novelty Insight Score. Scores range from 0.00 to 1.00. * A score near **0.00** means the generated idea is significantly less feasible than the ground truth. * A ...
work page 2022
-
[15]
Response: What the user would say (only if continuing the conversation) Consider factors like:{evaluation criteria} {additional context} Overall Test Prompt Analyze this conversation and predict the user’s response: The user is{task description}. CRITICAL: Focus on the initial request as the core topic that should be the primary focus throughout this enti...
-
[16]
Reasoning: Detailed analysis of the assistant’s response quality and accuracy (always consider how well it addresses the initial prompt)
-
[17]
Behavior decision: Whether to continue or end the conversation
-
[18]
Total” denotes the full size of each dataset, while “Samples
Response: What the user would say (only if continuing the conversation) Consider factors like: - Accessible and readable for general audiences without technical background - Accurate to the original scientific work without oversimplification - Engaging and newsworthy in its presentation style - Well-structured with appropriate journalistic elements (headl...
-
[19]
If a dataset contains static knowledge, we first load this knowledge into the memory of LLMsys
-
[20]
At each on-policy step, we perform the following: (a) Randomly sample 100 training instances from the combined training set, and let LLM- sys interact with the user feedback simulator to generate up to 3 rounds of dialogues. (b) Incorporate these 100 training dialogues into the memory of LLMsys, so that it accu- mulates more experience. (c) Evaluate the L...
-
[21]
The training dialogues generated previously are grouped into batches of 100 instances
-
[22]
At each step, we load one batch of dialogues into the memory of the LLMsys
-
[23]
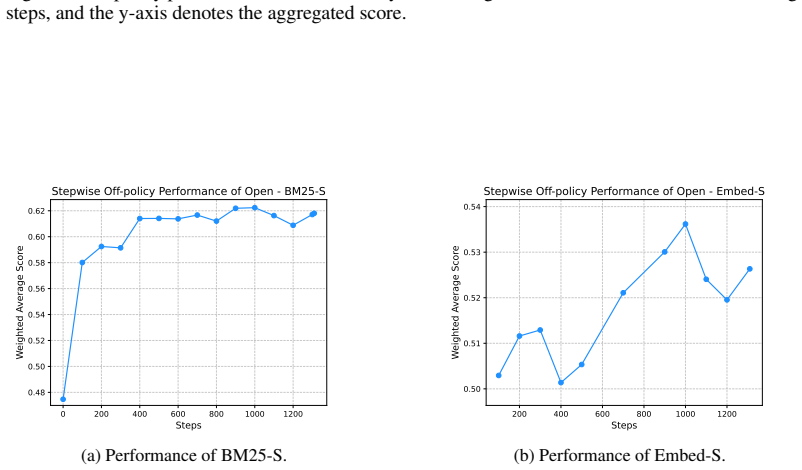
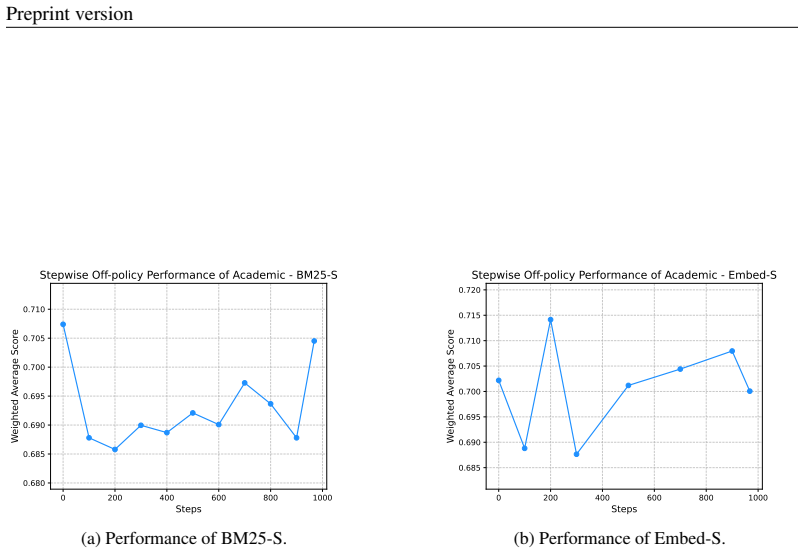
Evaluate the current LLMsys on the entire test set and record its performance. The results of the off-policy experiments of some LLMsys on domains Open, Academic, Legal, corresponding to Figs. 8, 9 and 10, respectively. 39 Preprint version Table 16: Comparison of performance with and without feedback across different datasets. Results are reported with th...
work page 2000
-
[24]
Discussed the proce- dure when a new crime (intentional injury) is discovered after a death penalty order is signed but before execution, requiring suspension and Supreme Court review... Analyzed a case involving a judge (Wang) accused of bribery and malfea- sance to determine if there were ju- risdictional errors. The response con- cluded that there were...
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.