The Fast and Spurious: Developer Productivity with GenAI
Pith reviewed 2026-05-18 03:23 UTC · model grok-4.3
The pith
GenAI speeds up coding tasks but shifts effort to code review and output verification, leaving perceived productivity gains potentially spurious.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Frequent GenAI users complete tasks more quickly and produce more code, but these gains are counterbalanced by higher demands on code review, sustained cognitive effort to check AI outputs for correctness, and unchanged collaboration patterns. Applying the SPACE framework to the survey data reveals systematic shifts of effort across satisfaction, performance, activity, communication, and efficiency dimensions. At the present stage of adoption, this pattern indicates that perceived productivity improvements may be spurious.
What carries the argument
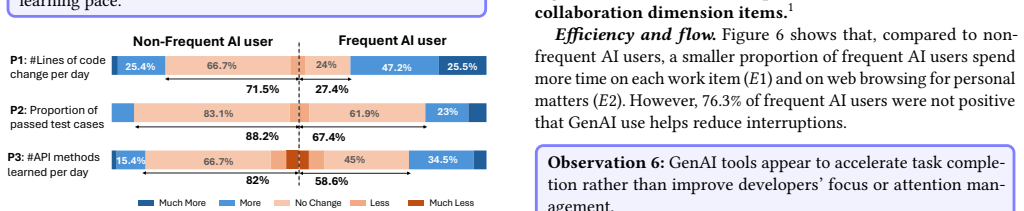
Survey mapping of GenAI usage levels to perceived changes across the five SPACE productivity dimensions, which tracks where effort increases and decreases.
If this is right
- Faster individual task completion does not reduce total workload because of added review time.
- Cognitive load from verifying AI outputs stays constant even as speed improves.
- Collaboration and communication patterns show no change with GenAI use.
- Developers face specific challenges that can be addressed with targeted mitigation strategies.
Where Pith is reading between the lines
- Teams may need to adjust schedules to account for extra review time when rolling out GenAI tools.
- Pairing self-reported data with logged metrics could test whether the observed shifts hold in practice.
- GenAI tools could be refined to lower the verification overhead that currently offsets speed gains.
Load-bearing premise
Developers' self-reported perceptions of productivity changes accurately reflect actual shifts without systematic bias or the need for objective measures like time logs.
What would settle it
A follow-up study that collects objective time-tracking or version-control data on coding, review, and verification effort before and after GenAI adoption to check whether net productivity increases.
Figures





read the original abstract
Generative AI (GenAI) tools are increasingly being adopted in software development as productivity aids, since there is evidence that GenAI tools can improve individual aspects of productivity. However, productivity is multidimensional; accelerating one aspect of work may simply shift effort to another. In this paper, we investigate how GenAI adoption affects different dimensions of developer productivity. We surveyed 415 software practitioners to understand how they perceive productivity changes associated with AI adoption, using the SPACE framework (Satisfaction and well-being, Performance, Activity, Communication and collaboration, and Efficiency and flow). Our results reveal systematic redistribution of effort across SPACE dimensions. While frequent GenAI users reported faster task completion and higher output volume, these gains were offset by increased code review burden, persistent cognitive load from output verification, and unchanged collaboration patterns. We further provide an empirical mapping between the challenges perceived by developers and potential strategies to mitigate them. Overall, our findings suggest that, at the current stage of GenAI adoption, perceived productivity gains may be spurious -- surface-level acceleration, often accompanied by redistributed effort and hidden costs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper reports results from a survey of 415 software practitioners on how GenAI tool adoption affects developer productivity across the SPACE dimensions (Satisfaction, Performance, Activity, Communication/collaboration, Efficiency/flow). Frequent users report faster task completion and higher output volume, but these are offset by greater code-review burden, persistent cognitive load from verifying AI-generated code, and unchanged collaboration patterns; the authors conclude that perceived productivity gains may therefore be spurious and supply an empirical mapping from reported challenges to mitigation strategies.
Significance. If the central redistribution claim holds, the work would be a useful addition to the empirical literature on GenAI in software engineering by moving beyond single-dimension speed claims and applying the established SPACE lens. The challenge-to-strategy mapping supplies concrete practitioner guidance. The study is timely and the sample size is respectable for a perception survey, but the absence of objective corroboration limits how strongly the “spurious” interpretation can be advanced.
major comments (2)
- [§3] §3 (Survey Design and Data Collection): The central claim that gains are spurious depends on self-reported perceptions accurately reflecting actual effort redistribution. The manuscript provides no objective metrics (commit rates, PR review durations, time logs), reports no response rate, and does not describe controls for self-selection bias. This is load-bearing for the abstract’s conclusion because the observed offsets in review burden and verification load could be artifacts of recall or social-desirability bias rather than genuine shifts.
- [§4] §4 (Results): The quantitative presentation of SPACE-dimension changes relies on Likert-scale or frequency responses without reported effect sizes, confidence intervals, or statistical tests comparing frequent versus infrequent users. Without these, it is difficult to judge whether the reported offsets are large enough to render the performance/activity gains spurious.
minor comments (2)
- [Abstract] The abstract states that the survey used the SPACE framework but does not list the exact items or adaptations; a short appendix or table with the instrument would improve reproducibility.
- [Figure 2] Figure 2 (SPACE dimension shifts) would benefit from error bars or significance markers to allow readers to assess the reliability of the reported differences.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We address each major comment below, indicating planned revisions where feasible.
read point-by-point responses
-
Referee: [§3] §3 (Survey Design and Data Collection): The central claim that gains are spurious depends on self-reported perceptions accurately reflecting actual effort redistribution. The manuscript provides no objective metrics (commit rates, PR review durations, time logs), reports no response rate, and does not describe controls for self-selection bias. This is load-bearing for the abstract’s conclusion because the observed offsets in review burden and verification load could be artifacts of recall or social-desirability bias rather than genuine shifts.
Authors: We agree that the study is based on self-reported perceptions, which is the standard approach when applying the SPACE framework to capture how developers experience productivity across multiple dimensions. Objective metrics such as commit rates or time logs would require a longitudinal design with direct access to development data, which was outside the scope of this perception survey. We will add an expanded limitations section that explicitly discusses potential biases including recall bias and social-desirability bias. The survey was distributed through open professional channels (e.g., LinkedIn groups, developer forums, and social media), so a response rate cannot be calculated; we will state this clearly in the methods. We will also elaborate on our sampling approach and efforts to reach a broad practitioner population to address self-selection concerns. revision: partial
-
Referee: [§4] §4 (Results): The quantitative presentation of SPACE-dimension changes relies on Likert-scale or frequency responses without reported effect sizes, confidence intervals, or statistical tests comparing frequent versus infrequent users. Without these, it is difficult to judge whether the reported offsets are large enough to render the performance/activity gains spurious.
Authors: We thank the referee for highlighting the need for stronger statistical presentation. The original analysis emphasized descriptive patterns and the observed redistribution of effort. We will revise the results section to include effect sizes (using appropriate measures for ordinal data), confidence intervals for key findings, and statistical comparisons (e.g., Mann-Whitney U or chi-square tests) between frequent and infrequent GenAI users. These additions will allow readers to better assess the magnitude and reliability of the reported offsets. revision: yes
- We cannot provide objective metrics such as commit rates, PR review durations, or time logs, as the study was designed as a cross-sectional perception survey and collected no such data.
Circularity Check
Empirical survey with no derivation or self-referential reduction
full rationale
The paper is a survey-based empirical study of 415 practitioners using the established SPACE framework. Central claims about redistributed effort and spurious perceived gains are presented as direct interpretations of self-reported responses rather than any mathematical derivation, fitted parameter, or equation that reduces to prior inputs by construction. No self-citation chains, uniqueness theorems, or ansatzes are invoked to justify the results. The study is self-contained against its own data collection and does not exhibit any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Self-reported perceptions from software practitioners accurately reflect changes in productivity dimensions.
Forward citations
Cited by 1 Pith paper
-
To Copilot and Beyond: 22 AI Systems Developers Want Built
Survey of 860 developers reveals 22 desired AI systems for non-coding tasks with explicit constraints on authority, provenance, and quality signals, framed as bounded delegation where AI handles assembly work but not ...
Reference graph
Works this paper leans on
-
[1]
Anonym. 2025. Developer Productivity with GenAI — Appendix. https://doi. org/10.5281/zenodo.17459831
- [2]
-
[3]
Ana Casic and Eri Panselina. 2025. Quiet cracking: The hidden crisis silently re- shaping work. https://www.talentlms.com/research/quiet-cracking-workplace- survey
work page 2025
- [4]
-
[5]
Zixuan Feng, Amreeta Chatterjee, Anita Sarma, and Iftekhar Ahmed. 2022. A case study of implicit mentoring, its prevalence, and impact in Apache. InESEC/FSE. 797–809
work page 2022
-
[6]
Zixuan Feng, Igor Steinmacher, Marco Gerosa, Tyler Menezes, Alexander Sere- brenik, Reed Milewicz, and Anita Sarma. 2025. The multifaceted nature of mentoring in oss: strategies, qualities, and ideal outcomes. InCHASE. IEEE, 203–214
work page 2025
- [7]
-
[8]
Nicole Forsgren, Margaret-Anne Storey, Chandra Maddila, Thomas Zimmermann, Brian Houck, and Jenna Butler. 2021. The SPACE of Developer Productivity: There’s more to it than you think.Queue19, 1 (2021), 20–48
work page 2021
-
[9]
Ranim Khojah, Mazen Mohamad, Philipp Leitner, and Francisco de Oliveira Neto
-
[10]
Beyond code generation: An observational study of chatgpt usage in software engineering practice.FSE1 (2024), 1819–1840
work page 2024
-
[11]
Mohammad Amin Kuhail, Sujith Samuel Mathew, Ashraf Khalil, Jose Berengueres, and Syed Jawad Hussain Shah. 2024. “Will I be replaced?” Assessing ChatGPT’s effect on software development and programmer perceptions of AI tools.Science of Computer Programming235 (2024), 103111
work page 2024
-
[12]
André N Meyer, Thomas Fritz, Gail C Murphy, and Thomas Zimmermann. 2014. Software developers’ perceptions of productivity. InFSE. 19–29
work page 2014
-
[13]
Maybe We Need Some More Examples:
Courtney Miller, Rudrajit Choudhuri, Mara Ulloa, Sankeerti Haniyur, Robert DeLine, Margaret-Anne Storey, Emerson Murphy-Hill, Christian Bird, and Jenna L Butler. 2025. " Maybe We Need Some More Examples:" Individual and Team Drivers of Developer GenAI Tool Use.arXiv preprint arXiv:2507.21280(2025)
-
[14]
Audris Mockus, Roy Fielding, and James Herbsleb. 2002. Two case studies of open source software development: Apache and Mozilla.TOSEM11, 3 (2002)
work page 2002
-
[15]
Anh Nguyen-Duc, Beatriz Cabrero-Daniel, Adam Przybylek, Chetan Arora, Dron Khanna, Tomas Herda, Usman Rafiq, Jorge Melegati, Eduardo Guerra, Kai-Kristian Kemell, et al. 2025. Generative artificial intelligence for software engineering—A research agenda.Software: Practice and Experience(2025)
work page 2025
-
[16]
Abi Noda, Margaret-Anne Storey, Nicole Forsgren, and Michaela Greiler. 2023. DevEx: What Actually Drives Productivity: The developer-centric approach to measuring and improving productivity.Queue21, 2 (2023), 35–53
work page 2023
-
[17]
Edson Oliveira, Eduardo Fernandes, Igor Steinmacher, Marco Cristo, Tayana Conte, and Alessandro Garcia. 2020. Code and commit metrics of developer productivity: a study on team leaders perceptions.EMSE25, 4 (2020), 2519–2549
work page 2020
-
[18]
Elise Paradis, Kate Grey, Quinn Madison, et al. 2025. How much does AI impact development speed? An enterprise RCT. InProc. ICSE-SEIP. 618–629
work page 2025
-
[19]
Sida Peng, Eirini Kalliamvakou, Peter Cihon, and Mert Demirer. 2023. The Impact of AI on Developer Productivity: Evidence from GitHub Copilot. arXiv preprint arXiv:2302.06590
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[20]
Ketai Qiu, Niccolò Puccinelli, Matteo Ciniselli, and Luca Di Grazia. 2025. From today’s code to tomorrow’s symphony: The AI transformation of developer’s routine by 2030.TOSEM34, 5 (2025), 1–17
work page 2025
-
[21]
Ya Gao & GitHub Customer Research. [n. d.]. Research: Quanti- fying GitHub Copilot’s impact in the enterprise with Accenture. https://github.blog/news-insights/research/research-quantifying-github- copilots-impact-in-the-enterprise-with-accenture/. Accessed: 2025-08-08
work page 2025
-
[22]
Daniel Rodríguez, MA Sicilia, E García, and Rachel Harrison. 2012. Empirical findings on team size and productivity in software development.Journal of Systems and Software85, 3 (2012), 562–570
work page 2012
-
[23]
Mario Rodriguez. 2023. Research: Quantifying GitHub Copilot’s impact on code quality. https://github.blog/news-insights/research/research-quantifying-github- copilots-impact-on-code-quality/. Accessed: 2025-10-21
work page 2023
-
[24]
Alan Shimel. 2025. Stack Overflow Survey Shows AI Adoption for Devs.De- vOps.com(August 12 2025). https://devops.com/stack-overflow-survey-shows- Conference acronym ’XX, June 03–05, 2018, Woodstock, NY Sadia Afroz, Zixuan Feng, Katie Kimura, Bianca Trinkenreich, Igor Steinmacher, and Anita Sarma ai-adoption-for-devs/ Accessed: 2025-10-05
work page 2025
-
[25]
Margaret-Anne Storey, Brian Houck, and Thomas Zimmermann. 2022. How developers and managers define and trade productivity for quality. InCHASE
work page 2022
-
[26]
Margaret-Anne Storey, Thomas Zimmermann, Christian Bird, Jacek Czerwonka, Brendan Murphy, and Eirini Kalliamvakou. 2019. Towards a theory of software developer job satisfaction and perceived productivity.TSE47, 10 (2019)
work page 2019
-
[27]
Franziska Tobisch and Florian Matthes. 2025. Knowledge Sharing and Coor- dination in Large-Scale Agile Software Development–A Systematic Literature Review and an Interview Study. InInternational Conference on Agile Software Development. Springer, 81–99
work page 2025
-
[28]
Anna Tong. 2025. AI slows down some experienced software developers, study finds. https://www.reuters.com/business/ai-slows-down-some-experienced- software-developers-study-finds-2025-07-10/. Accessed: 2025-10-21
work page 2025
-
[29]
Bianca Trinkenreich, Fabio Santos, and Klaas-jan Stol. 2024. Predicting attrition among software professionals: Antecedents and consequences of burnout and engagement.TOSEM33, 8 (2024), 1–45
work page 2024
-
[30]
Priyan Vaithilingam, Tianyi Zhang, and Elena L Glassman. 2022. Expectation vs. experience: Evaluating the usability of code generation tools powered by large language models. InCHI EA. 1–7
work page 2022
-
[31]
Bogdan Vasilescu, Yue Yu, Huaimin Wang, Premkumar Devanbu, and Vladimir Filkov. 2015. Quality and productivity outcomes relating to continuous integra- tion in GitHub. InESEC/FSE. 805–816
work page 2015
-
[32]
Brennan Wilkes, Alessandra Maciel Paz Milani, and Margaret-Anne Storey. 2023. A framework for automating the measurement of devops research and assessment (dora) metrics. InICSME. IEEE, 62–72
work page 2023
- [33]
-
[34]
Ilya Zakharov, Ekaterina Koshchenko, and Agnia Sergeyuk. 2025. AI in Software Engineering: Perceived Roles and Their Impact on Adoption. InFSE Companion. 1305–1309
work page 2025
-
[35]
Minghui Zhou and Audris Mockus. 2010. Developer fluency: Achieving true mastery in software projects. InFSE. 137–146
work page 2010
-
[36]
Albert Ziegler, Eirini Kalliamvakou, X Alice Li, Andrew Rice, Devon Rifkin, Shawn Simister, Ganesh Sittampalam, and Edward Aftandilian. 2022. Productivity assessment of neural code completion. InMAPS. 21–29
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.