XR-1: Towards Versatile Vision-Language-Action Models via Learning Unified Vision-Motion Representations
Pith reviewed 2026-05-18 01:00 UTC · model grok-4.3
The pith
A shared discrete code for vision and motion lets one model control many different robots and tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
XR-1 shows that Unified Vision-Motion Codes learned by a dual-branch VQ-VAE that jointly encodes visual dynamics and robotic motion can serve as an effective bridge between high-dimensional observations and low-level actions. The codes align multimodal information from heterogeneous sources such as varied robot embodiments and human demonstrations, allowing the model to produce precise actions while transferring knowledge without embodiment-specific fine-tuning of the codebook itself.
What carries the argument
Unified Vision-Motion Codes (UVMC) from a dual-branch VQ-VAE that encodes visual dynamics in one branch and robotic motion in the other before mapping both into a shared discrete latent space.
If this is right
- Large-scale pretraining can combine data from many robots and human sources into one model without per-embodiment codebooks.
- The resulting policies show improved success on manipulation tasks when objects, backgrounds, distractors, or lighting change from training conditions.
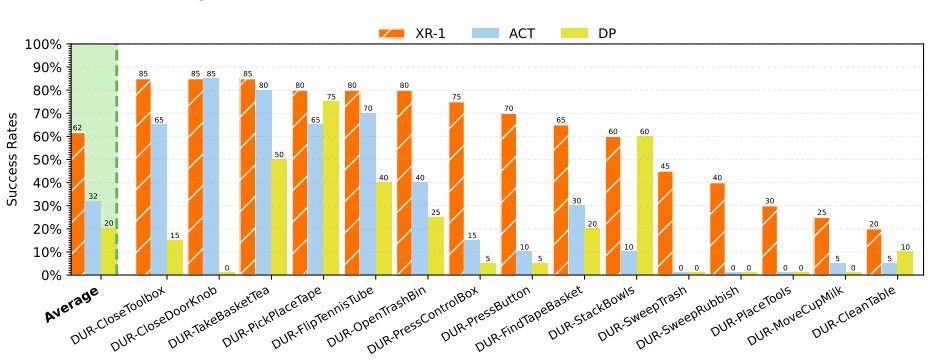
- One model achieves higher performance than prior VLA systems across six robot embodiments and more than 120 tasks in over 14,000 real-world rollouts.
- Task-specific adaptation requires only the final post-training stage once the shared codes are learned.
Where Pith is reading between the lines
- The joint-encoding step could lower data collection needs in other embodied settings where hardware differences create similar observation-action gaps.
- Freezing the learned codes during policy training and measuring any drop in transfer performance would test how much embodiment information remains outside the codes.
- Applying the same dual-branch structure to additional signals such as language instructions or force feedback might expand the range of tasks that transfer without extra fine-tuning.
Load-bearing premise
The discrete codes from the dual-branch VQ-VAE capture complementary multimodal knowledge that transfers across different robot embodiments and human demonstrations without needing to retrain the codebook for each new body.
What would settle it
Train and evaluate the full XR-1 pipeline but replace the joint dual-branch VQ-VAE with two separate independent VQ-VAEs for vision and motion only; if real-world task success rates stay the same or improve, the claimed benefit of joint encoding does not hold.
Figures










read the original abstract
Recent progress in large-scale robotic datasets and vision-language models (VLMs) has advanced research on vision-language-action (VLA) models. However, existing VLA models still face two fundamental challenges: (i) producing precise low-level actions from high-dimensional observations, (ii) bridging domain gaps across heterogeneous data sources, including diverse robot embodiments and human demonstrations. Existing methods often encode latent variables from either visual dynamics or robotic actions to guide policy learning, but they fail to fully exploit the complementary multi-modal knowledge present in large-scale, heterogeneous datasets. In this work, we present X Robotic Model 1 (XR-1), a novel framework for versatile and scalable VLA learning across diverse robots, tasks, and environments. XR-1 introduces the \emph{Unified Vision-Motion Codes (UVMC)}, a discrete latent representation learned via a dual-branch VQ-VAE that jointly encodes visual dynamics and robotic motion. UVMC addresses these challenges by (i) serving as an intermediate representation between the observations and actions, and (ii) aligning multimodal dynamic information from heterogeneous data sources to capture complementary knowledge. To effectively exploit UVMC, we propose a three-stage training paradigm: (i) self-supervised UVMC learning, (ii) UVMC-guided pretraining on large-scale cross-embodiment robotic datasets, and (iii) task-specific post-training. We validate XR-1 through extensive real-world experiments with more than 14,000 rollouts on six different robot embodiments, spanning over 120 diverse manipulation tasks. XR-1 consistently outperforms state-of-the-art baselines such as $\pi_{0.5}$, $\pi_0$, RDT, UniVLA, and GR00T-N1.5 while demonstrating strong generalization to novel objects, background variations, distractors, and illumination changes. Our project is at https://xr-1-vla.github.io/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces XR-1, a vision-language-action model that learns Unified Vision-Motion Codes (UVMC) via a dual-branch VQ-VAE to jointly encode visual dynamics and robotic motion. These discrete codes act as an intermediate representation bridging high-dimensional observations to low-level actions while aligning complementary multimodal knowledge across heterogeneous sources including diverse robot embodiments and human demonstrations. A three-stage training paradigm is proposed: (i) self-supervised UVMC learning, (ii) UVMC-guided pretraining on large-scale cross-embodiment datasets, and (iii) task-specific post-training. The approach is validated through more than 14,000 real-world rollouts on six robot embodiments spanning over 120 manipulation tasks, claiming consistent outperformance over baselines such as π_{0.5}, π_0, RDT, UniVLA, and GR00T-N1.5 together with strong generalization to novel objects, backgrounds, distractors, and illumination changes.
Significance. If the central claims hold, XR-1 would mark a meaningful step toward scalable cross-embodiment VLA models by supplying a unified discrete latent space that exploits complementary vision-motion knowledge without embodiment-specific codebook fine-tuning. The scale of the real-world evaluation (more than 14,000 rollouts across six embodiments) constitutes a clear empirical strength that exceeds typical VLA reporting and lends weight to the generalization results. However, the absence of quantitative controls on the VQ-VAE design choices limits the ability to isolate the precise contribution of UVMC to the reported gains.
major comments (2)
- [Three-stage training paradigm] Three-stage training paradigm: The manuscript does not state whether the codebook produced by the dual-branch VQ-VAE in stage (i) remains frozen or continues to be updated during the UVMC-guided pretraining on mixed robot and human data in stage (ii). This detail is load-bearing for the unification claim; if the codebook receives embodiment-specific updates, the explanation for why XR-1 transfers without per-embodiment fine-tuning and outperforms baselines such as π_{0.5} and GR00T-N1.5 on novel objects and lighting is weakened.
- [Experimental evaluation] Experimental results: The reported outperformance and generalization rest on more than 14,000 rollouts, yet no quantitative ablations, error bars, or sensitivity analysis are supplied for the codebook size, commitment loss weight, or cross-embodiment alignment losses. Without these controls it is difficult to attribute performance gains specifically to the dual-branch VQ-VAE rather than to data scale or other unablated factors.
minor comments (2)
- [Abstract] Abstract: The phrasing 'X Robotic Model 1 (XR-1)' is slightly inconsistent with the title and could be standardized for clarity.
- [Methods] Methods: Explicit values or ranges for the data mixture ratios and the number of training stages would improve reproducibility of the three-stage paradigm.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the scale of our real-world evaluation across more than 14,000 rollouts. We address each major comment below with clarifications on our methodology and plans for revision.
read point-by-point responses
-
Referee: [Three-stage training paradigm] Three-stage training paradigm: The manuscript does not state whether the codebook produced by the dual-branch VQ-VAE in stage (i) remains frozen or continues to be updated during the UVMC-guided pretraining on mixed robot and human data in stage (ii). This detail is load-bearing for the unification claim; if the codebook receives embodiment-specific updates, the explanation for why XR-1 transfers without per-embodiment fine-tuning and outperforms baselines such as π_{0.5} and GR00T-N1.5 on novel objects and lighting is weakened.
Authors: We appreciate this observation. In our framework, the codebook learned via the dual-branch VQ-VAE in stage (i) is kept frozen throughout stage (ii). This design choice ensures that UVMC serves as a fixed, unified discrete representation that aligns complementary vision-motion knowledge across heterogeneous sources (diverse robot embodiments and human demonstrations) without any embodiment-specific updates to the codebook. Freezing the codebook is central to enabling cross-embodiment transfer and the observed generalization to novel objects, backgrounds, and lighting conditions. We will revise the manuscript to explicitly describe this freezing step in the three-stage training section and in the method overview figure caption. revision: yes
-
Referee: [Experimental evaluation] Experimental results: The reported outperformance and generalization rest on more than 14,000 rollouts, yet no quantitative ablations, error bars, or sensitivity analysis are supplied for the codebook size, commitment loss weight, or cross-embodiment alignment losses. Without these controls it is difficult to attribute performance gains specifically to the dual-branch VQ-VAE rather than to data scale or other unablated factors.
Authors: We agree that additional quantitative controls would better isolate the contribution of the dual-branch VQ-VAE and UVMC. Our current results emphasize large-scale real-world validation and direct comparisons to strong baselines, but we did not report sensitivity analyses for codebook size, commitment loss weight, or alignment loss coefficients in the main text. In the revised manuscript we will add a dedicated ablation subsection (including tables) that varies codebook sizes (e.g., 512/1024/2048), commitment loss weights, and cross-embodiment alignment loss coefficients, reporting success rates with error bars computed over multiple random seeds where feasible. This will strengthen attribution of gains to the proposed UVMC design. revision: yes
Circularity Check
No significant circularity: empirical results on held-out rollouts are independent of training definitions
full rationale
The paper presents a three-stage training procedure (self-supervised UVMC learning via dual-branch VQ-VAE, followed by UVMC-guided pretraining on heterogeneous data, then task-specific post-training) whose value is measured by external real-world metrics: success rates over 14,000 rollouts on six embodiments and 120 tasks, plus generalization to novel objects/lighting. These metrics are not defined in terms of the VQ-VAE reconstruction loss, codebook entropy, or any fitted parameter from stage (i). No equation or claim equates a reported performance number to a quantity that was optimized during training. The codebook-freezing question raised by the skeptic is an implementation detail that would affect interpretation but does not make the reported outperformance numbers tautological by construction. The derivation chain therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- codebook size and commitment loss weight
- number of training stages and data mixture ratios
axioms (1)
- domain assumption A discrete latent code learned jointly from vision and motion can serve as an effective intermediate representation that bridges heterogeneous robot embodiments.
invented entities (1)
-
Unified Vision-Motion Codes (UVMC)
no independent evidence
Forward citations
Cited by 3 Pith papers
-
Demo-JEPA: Joint-Embedding Predictive Architecture for One-shot Cross-Embodiment Imitation
Demo-JEPA enables one-shot cross-embodiment imitation by mapping visual demonstrations to shared latent future trajectories that serve as subgoals for the target agent's own forward dynamics planning.
-
From Imagined Futures to Executable Actions: Mixture of Latent Actions for Robot Manipulation
MoLA infers a mixture of latent actions from generated future videos via modality-aware inverse dynamics models to improve robot manipulation policies.
-
UniT: Toward a Unified Physical Language for Human-to-Humanoid Policy Learning and World Modeling
UniT creates a unified physical language via visual anchoring and tri-branch reconstruction to enable scalable human-to-humanoid transfer for policy learning and world modeling.
Reference graph
Works this paper leans on
-
[1]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
-
[2]
Affordances from human videos as a versatile representation for robotics
Shikhar Bahl, Russell Mendonca, Lili Chen, Unnat Jain, and Deepak Pathak. Affordances from human videos as a versatile representation for robotics. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp.\ 13778--13790, 2023
work page 2023
-
[3]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou. Qwen-vl: A frontier large vision-language model with versatile abilities. arXiv preprint arXiv:2308.12966, 1 0 (2): 0 3, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Erik Bauer, Elvis Nava, and Robert K. Katzschmann. Latent action diffusion for cross-embodiment manipulation. In Proceedings of the Conference on Robot Learning (CoRL), 2025
work page 2025
-
[5]
Hydra: Hybrid robot actions for imitation learning
Suneel Belkhale, Yuchen Cui, and Dorsa Sadigh. Hydra: Hybrid robot actions for imitation learning. In Conference on Robot Learning, pp.\ 2113--2133. PMLR, 2023
work page 2023
-
[6]
PaliGemma: A versatile 3B VLM for transfer
Lucas Beyer, Andreas Steiner, Andr \'e Susano Pinto, Alexander Kolesnikov, Xiao Wang, Daniel Salz, Maxim Neumann, Ibrahim Alabdulmohsin, Michael Tschannen, Emanuele Bugliarello, et al. Paligemma: A versatile 3b vlm for transfer. arXiv preprint arXiv:2407.07726, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
Homanga Bharadhwaj, Jay Vakil, Mohit Sharma, Abhinav Gupta, Shubham Tulsiani, and Vikash Kumar. Roboagent: Generalization and efficiency in robot manipulation via semantic augmentations and action chunking. In 2024 IEEE International Conference on Robotics and Automation (ICRA), pp.\ 4788--4795. IEEE, 2024
work page 2024
-
[8]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
Johan Bjorck, Fernando Casta \ n eda, Nikita Cherniadev, Xingye Da, Runyu Ding, Linxi Fan, Yu Fang, Dieter Fox, Fengyuan Hu, Spencer Huang, et al. Gr00t n1: An open foundation model for generalist humanoid robots. arXiv preprint arXiv:2503.14734, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, et al. _0 : A vision-language-action flow model for general robot control. arXiv preprint arXiv:2410.24164, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
RT-1: Robotics Transformer for Real-World Control at Scale
Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Joseph Dabis, Chelsea Finn, Keerthana Gopalakrishnan, Karol Hausman, Alex Herzog, Jasmine Hsu, et al. Rt-1: Robotics transformer for real-world control at scale. arXiv preprint arXiv:2212.06817, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[11]
Qingwen Bu, Jisong Cai, Li Chen, Xiuqi Cui, Yan Ding, Siyuan Feng, Shenyuan Gao, Xindong He, Xuan Hu, Xu Huang, et al. Agibot world colosseo: A large-scale manipulation platform for scalable and intelligent embodied systems. arXiv preprint arXiv:2503.06669, 2025 a
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Univla: Learning to act anywhere with task-centric latent actions
Qingwen Bu, Yanting Yang, Jisong Cai, Shenyuan Gao, Guanghui Ren, Maoqing Yao, Ping Luo, and Hongyang Li. Univla: Learning to act anywhere with task-centric latent actions. In Proceedings of Robotics: Science and Systems (RSS), 2025 b
work page 2025
-
[13]
Mamba policy: Towards efficient 3d diffusion policy with hybrid selective state models
Jiahang Cao, Qiang Zhang, Jingkai Sun, Jiaxu Wang, Hao Cheng, Yulin Li, Jun Ma, Kun Wu, Zhiyuan Xu, Yecheng Shao, et al. Mamba policy: Towards efficient 3d diffusion policy with hybrid selective state models. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2025
work page 2025
-
[14]
GR-2: A Generative Video-Language-Action Model with Web-Scale Knowledge for Robot Manipulation
Chi-Lam Cheang, Guangzeng Chen, Ya Jing, Tao Kong, Hang Li, Yifeng Li, Yuxiao Liu, Hongtao Wu, Jiafeng Xu, Yichu Yang, et al. Gr-2: A generative video-language-action model with web-scale knowledge for robot manipulation. arXiv preprint arXiv:2410.06158, 2025 a
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
Chilam Cheang, Sijin Chen, Zhongren Cui, Yingdong Hu, Liqun Huang, Tao Kong, Hang Li, Yifeng Li, Yuxiao Liu, Xiao Ma, et al. Gr-3 technical report. arXiv preprint arXiv:2507.15493, 2025 b
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
Berkeley UR5 demonstration dataset
Lawrence Yunliang Chen, Simeon Adebola, and Ken Goldberg. Berkeley UR5 demonstration dataset. https://sites.google.com/view/berkeley-ur5/home
-
[17]
Playfusion: Skill acquisition via diffusion from language-annotated play
Lili Chen, Shikhar Bahl, and Deepak Pathak. Playfusion: Skill acquisition via diffusion from language-annotated play. In Conference on Robot Learning, pp.\ 2012--2029. PMLR, 2023
work page 2012
-
[18]
Moto: Latent motion token as the bridging language for robot manipulation
Yi Chen, Yuying Ge, Yizhuo Li, Yixiao Ge, Mingyu Ding, Ying Shan, and Xihui Liu. Moto: Latent motion token as the bridging language for robot manipulation. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). IEEE, 2025
work page 2025
-
[19]
Diffusion policy: Visuomotor policy learning via action diffusion
Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Yilun Du, Benjamin Burchfiel, Russ Tedrake, and Shuran Song. Diffusion policy: Visuomotor policy learning via action diffusion. The International Journal of Robotics Research, pp.\ 02783649241273668, 2023
work page 2023
-
[20]
From play to policy: Conditional behavior generation from uncurated robot data
Zichen Jeff Cui, Yibin Wang, Nur Muhammad Mahi Shafiullah, and Lerrel Pinto. From play to policy: Conditional behavior generation from uncurated robot data. In Proceedings of the International Conference on Learning Representations (ICLR), 2023
work page 2023
-
[21]
Shivin Dass, Jullian Yapeter, Jesse Zhang, Jiahui Zhang, Karl Pertsch, Stefanos Nikolaidis, and Joseph J. Lim. Clvr jaco play dataset, 2023. URL https://github.com/clvrai/clvr_jaco_play_dataset
work page 2023
-
[22]
Danny Driess, Fei Xia, Mehdi S. M. Sajjadi, Corey Lynch, Aakanksha Chowdhery, Brian Ichter, Ayzaan Wahid, Jonathan Tompson, Quan Vuong, Tianhe Yu, Wenlong Huang, Yevgen Chebotar, Pierre Sermanet, Daniel Duckworth, Sergey Levine, Vincent Vanhoucke, Karol Hausman, Marc Toussaint, Klaus Greff, Andy Zeng, Igor Mordatch, and Pete Florence. P a LM -e: An embodi...
work page 2023
-
[23]
Learning universal policies via text-guided video generation
Yilun Du, Sherry Yang, Bo Dai, Hanjun Dai, Ofir Nachum, Josh Tenenbaum, Dale Schuurmans, and Pieter Abbeel. Learning universal policies via text-guided video generation. Advances in neural information processing systems, 36: 0 9156--9172, 2023
work page 2023
-
[24]
Bridge data: Boosting generalization of robotic skills with cross-domain datasets
Frederik Ebert, Yanlai Yang, Karl Schmeckpeper, Bernadette Bucher, Georgios Georgakis, Kostas Daniilidis, Chelsea Finn, and Sergey Levine. Bridge data: Boosting generalization of robotic skills with cross-domain datasets. In Proceedings of Robotics: Science and Systems (RSS), 2022
work page 2022
-
[25]
Diffusion trajectory-guided policy for long-horizon robot manipulation
Shichao Fan, Quantao Yang, Yajie Liu, Kun Wu, Zhengping Che, Qingjie Liu, and Min Wan. Diffusion trajectory-guided policy for long-horizon robot manipulation. IEEE Robotics and Automation Letters, 10 0 (12): 0 12788--12795, 2025. doi:10.1109/LRA.2025.3619794
-
[26]
Finetuning offline world models in the real world
Yunhai Feng, Nicklas Hansen, Ziyan Xiong, Chandramouli Rajagopalan, and Xiaolong Wang. Finetuning offline world models in the real world. In Conference on Robot Learning (CoRL), 2023
work page 2023
-
[27]
Mobile aloha: Learning bimanual mobile manipulation with low-cost whole-body teleoperation
Zipeng Fu, Tony Z Zhao, and Chelsea Finn. Mobile aloha: Learning bimanual mobile manipulation with low-cost whole-body teleoperation. In Conference on Robot Learning (CoRL), 2024
work page 2024
-
[28]
Llama-adapter v2: Parameter-efficient visual instruction model
Peng Gao, Jiaming Han, Renrui Zhang, Ziyi Lin, Shijie Geng, Aojun Zhou, Wei Zhang, Pan Lu, Conghui He, Xiangyu Yue, et al. Llama-adapter v2: Parameter-efficient visual instruction model. In Proceedings of the International Conference on Learning Representations (ICLR), 2024
work page 2024
-
[29]
Ego4d: Around the world in 3,000 hours of egocentric video
Kristen Grauman, Andrew Westbury, Eugene Byrne, Zachary Chavis, Antonino Furnari, Rohit Girdhar, Jackson Hamburger, Hao Jiang, Miao Liu, Xingyu Liu, et al. Ego4d: Around the world in 3,000 hours of egocentric video. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp.\ 18995--19012, 2022
work page 2022
-
[30]
Watch and match: Supercharging imitation with regularized optimal transport
Siddhant Haldar, Vaibhav Mathur, Denis Yarats, and Lerrel Pinto. Watch and match: Supercharging imitation with regularized optimal transport. In Conference on Robot Learning, pp.\ 32--43. PMLR, 2023
work page 2023
-
[31]
Learning an actionable discrete diffusion policy via large-scale actionless video pre-training
Haoran He, Chenjia Bai, Ling Pan, Weinan Zhang, Bin Zhao, and Xuelong Li. Learning an actionable discrete diffusion policy via large-scale actionless video pre-training. Advances in Neural Information Processing Systems, 37: 0 31124--31153, 2024
work page 2024
-
[32]
Masked autoencoders are scalable vision learners
Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Doll \'a r, and Ross Girshick. Masked autoencoders are scalable vision learners. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp.\ 16000--16009, 2022
work page 2022
-
[33]
Furniturebench: Reproducible real-world benchmark for long-horizon complex manipulation
Minho Heo, Youngwoon Lee, Doohyun Lee, and Joseph J Lim. Furniturebench: Reproducible real-world benchmark for long-horizon complex manipulation. The International Journal of Robotics Research, pp.\ 02783649241304789, 2023
work page 2023
-
[34]
Sacson: Scalable autonomous control for social navigation
Noriaki Hirose, Dhruv Shah, Ajay Sridhar, and Sergey Levine. Sacson: Scalable autonomous control for social navigation. IEEE Robotics and Automation Letters, 9 0 (1): 0 49--56, 2023
work page 2023
-
[35]
Video Prediction Policy: A Generalist Robot Policy with Predictive Visual Representations
Yucheng Hu, Yanjiang Guo, Pengchao Wang, Xiaoyu Chen, Yen-Jen Wang, Jianke Zhang, Koushil Sreenath, Chaochao Lu, and Jianyu Chen. Video prediction policy: A generalist robot policy with predictive visual representations. arXiv preprint arXiv:2412.14803, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[36]
$\pi_{0.5}$: a Vision-Language-Action Model with Open-World Generalization
Physical Intelligence, Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, et al. _ 0.5 : a vision-language-action model with open-world generalization. arXiv preprint arXiv:2504.16054, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
Bc-z: Zero-shot task generalization with robotic imitation learning
Eric Jang, Alex Irpan, Mohi Khansari, Daniel Kappler, Frederik Ebert, Corey Lynch, Sergey Levine, and Chelsea Finn. Bc-z: Zero-shot task generalization with robotic imitation learning. In Conference on Robot Learning, pp.\ 991--1002. PMLR, 2022
work page 2022
-
[38]
Self-supervised deep reinforcement learning with generalized computation graphs for robot navigation
Gregory Kahn, Adam Villaflor, Bosen Ding, Pieter Abbeel, and Sergey Levine. Self-supervised deep reinforcement learning with generalized computation graphs for robot navigation. In 2018 IEEE international conference on robotics and automation (ICRA), pp.\ 5129--5136. IEEE, 2018
work page 2018
-
[39]
Scalable deep reinforcement learning for vision-based robotic manipulation
Dmitry Kalashnikov, Alex Irpan, Peter Pastor, Julian Ibarz, Alexander Herzog, Eric Jang, Deirdre Quillen, Ethan Holly, Mrinal Kalakrishnan, Vincent Vanhoucke, et al. Scalable deep reinforcement learning for vision-based robotic manipulation. In Conference on robot learning, pp.\ 651--673. PMLR, 2018
work page 2018
-
[40]
DROID: A Large-Scale In-The-Wild Robot Manipulation Dataset
Alexander Khazatsky, Karl Pertsch, Suraj Nair, Ashwin Balakrishna, Sudeep Dasari, Siddharth Karamcheti, Soroush Nasiriany, Mohan Kumar Srirama, Lawrence Yunliang Chen, Kirsty Ellis, et al. Droid: A large-scale in-the-wild robot manipulation dataset. arXiv preprint arXiv:2403.12945, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[41]
Minchan Kim, Junhyek Han, Jaehyung Kim, and Beomjoon Kim. Pre-and post-contact policy decomposition for non-prehensile manipulation with zero-shot sim-to-real transfer. In 2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pp.\ 10644--10651. IEEE, 2023
work page 2023
-
[42]
Openvla: An open-source vision-language-action model
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, et al. Openvla: An open-source vision-language-action model. In Conference on Robot Learning (CoRL), 2024
work page 2024
-
[43]
Molmoact: Action reasoning models that can reason in space
Jason Lee, Jiafei Duan, Haoquan Fang, Yuquan Deng, Shuo Liu, Boyang Li, Bohan Fang, Jieyu Zhang, Yi Ru Wang, Sangho Lee, et al. Molmoact: Action reasoning models that can reason in space. In CoRL 2025 Robot Data Workshop, 2025
work page 2025
-
[44]
Behavior generation with latent actions
Seungjae Lee, Yibin Wang, Haritheja Etukuru, H Jin Kim, Nur Muhammad Mahi Shafiullah, and Lerrel Pinto. Behavior generation with latent actions. In Proceedings of the International Conference on Machine Learning (ICML), 2024
work page 2024
-
[45]
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. In International conference on machine learning, pp.\ 19730--19742. PMLR, 2023
work page 2023
-
[46]
Meng Li, Zhen Zhao, Zhengping Che, Fei Liao, Kun Wu, Zhiyuan Xu, Pei Ren, Zhao Jin, Ning Liu, and Jian Tang. Switchvla: Execution-aware task switching for vision-language-action models. arXiv preprint arXiv:2506.03574, 2025 a
-
[47]
Shuang Li, Yihuai Gao, Dorsa Sadigh, and Shuran Song. Unified video action model. In Proceedings of Robotics: Science and Systems (RSS), 2025 b
work page 2025
-
[48]
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning. Advances in neural information processing systems, 36: 0 34892--34916, 2023
work page 2023
-
[49]
Robot learning on the job: Human-in-the-loop autonomy and learning during deployment
Huihan Liu, Soroush Nasiriany, Lance Zhang, Zhiyao Bao, and Yuke Zhu. Robot learning on the job: Human-in-the-loop autonomy and learning during deployment. The International Journal of Robotics Research, pp.\ 02783649241273901, 2022
work page 2022
-
[50]
HybridVLA: Collaborative Diffusion and Autoregression in a Unified Vision-Language-Action Model
Jiaming Liu, Hao Chen, Pengju An, Zhuoyang Liu, Renrui Zhang, Chenyang Gu, Xiaoqi Li, Ziyu Guo, Sixiang Chen, Mengzhen Liu, et al. Hybridvla: Collaborative diffusion and autoregression in a unified vision-language-action model. arXiv preprint arXiv:2503.10631, 2025 a
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[51]
Rdt-1b: a diffusion foundation model for bimanual manipulation
Songming Liu, Lingxuan Wu, Bangguo Li, Hengkai Tan, Huayu Chen, Zhengyi Wang, Ke Xu, Hang Su, and Jun Zhu. Rdt-1b: a diffusion foundation model for bimanual manipulation. In Proceedings of the International Conference on Learning Representations (ICLR), 2025 b
work page 2025
-
[52]
Zhuoyang Liu, Jiaming Liu, Jiadong Xu, Nuowei Han, Chenyang Gu, Hao Chen, Kaichen Zhou, Renrui Zhang, Kai Chin Hsieh, Kun Wu, et al. Mla: A multisensory language-action model for multimodal understanding and forecasting in robotic manipulation. arXiv preprint arXiv:2509.26642, 2025 c
-
[53]
Multistage cable routing through hierarchical imitation learning
Jianlan Luo, Charles Xu, Xinyang Geng, Gilbert Feng, Kuan Fang, Liam Tan, Stefan Schaal, and Sergey Levine. Multistage cable routing through hierarchical imitation learning. IEEE Transactions on Robotics, 40: 0 1476--1491, 2024
work page 2024
-
[54]
Fmb: a functional manipulation benchmark for generalizable robotic learning
Jianlan Luo, Charles Xu, Fangchen Liu, Liam Tan, Zipeng Lin, Jeffrey Wu, Pieter Abbeel, and Sergey Levine. Fmb: a functional manipulation benchmark for generalizable robotic learning. The International Journal of Robotics Research, 44 0 (4): 0 592--606, 2025
work page 2025
-
[55]
Interactive language: Talking to robots in real time
Corey Lynch, Ayzaan Wahid, Jonathan Tompson, Tianli Ding, James Betker, Robert Baruch, Travis Armstrong, and Pete Florence. Interactive language: Talking to robots in real time. IEEE Robotics and Automation Letters, 2023
work page 2023
-
[56]
Ajay Mandlekar, Jonathan Booher, Max Spero, Albert Tung, Anchit Gupta, Yuke Zhu, Animesh Garg, Silvio Savarese, and Li Fei-Fei. Scaling robot supervision to hundreds of hours with roboturk: Robotic manipulation dataset through human reasoning and dexterity. In 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pp.\ 1048--1055...
work page 2019
-
[57]
Tatsuya Matsushima, Hiroki Furuta, Yusuke Iwasawa, and Yutaka Matsuo. Weblab xarm dataset, 2023
work page 2023
-
[58]
Grounding language with visual affordances over unstructured data
Oier Mees, Jessica Borja-Diaz, and Wolfram Burgard. Grounding language with visual affordances over unstructured data. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), 2023
work page 2023
-
[59]
Structured world models from human videos
Russell Mendonca, Shikhar Bahl, and Deepak Pathak. Structured world models from human videos. In Proceedings of Robotics: Science and Systems (RSS), 2023
work page 2023
-
[60]
Quest: Self-supervised skill abstractions for learning continuous control
Atharva Mete, Haotian Xue, Albert Wilcox, Yongxin Chen, and Animesh Garg. Quest: Self-supervised skill abstractions for learning continuous control. Advances in Neural Information Processing Systems, 37: 0 4062--4089, 2024
work page 2024
-
[61]
Learning and retrieval from prior data for skill-based imitation learning
Soroush Nasiriany, Tian Gao, Ajay Mandlekar, and Yuke Zhu. Learning and retrieval from prior data for skill-based imitation learning. In Proceedings of the Conference on Robot Learning (CoRL), 2022
work page 2022
-
[62]
X-embodiment u-tokyo pr2 datasets
Jihoon Oh, Naoaki Kanazawa, and Kento Kawaharazuka. X-embodiment u-tokyo pr2 datasets. URL https://github. com/ojh6404/rlds\_dataset\_builder, 22, 2023
work page 2023
-
[63]
Motion planning by learning the solution manifold in trajectory optimization
Takayuki Osa. Motion planning by learning the solution manifold in trajectory optimization. The International Journal of Robotics Research, 41 0 (3): 0 281--311, 2022
work page 2022
-
[64]
Open x-embodiment: Robotic learning datasets and rt-x models: Open x-embodiment collaboration 0
Abby O’Neill, Abdul Rehman, Abhiram Maddukuri, Abhishek Gupta, Abhishek Padalkar, Abraham Lee, Acorn Pooley, Agrim Gupta, Ajay Mandlekar, Ajinkya Jain, et al. Open x-embodiment: Robotic learning datasets and rt-x models: Open x-embodiment collaboration 0. In 2024 IEEE International Conference on Robotics and Automation (ICRA), pp.\ 6892--6903. IEEE, 2024
work page 2024
-
[65]
Abhishek Padalkar, Gabriel Quere, Antonin Raffin, Jo \ a o Silv \'e rio, and Freek Stulp. A guided reinforcement learning approach using shared control templates for learning manipulation skills in the real world. 2023 a
work page 2023
-
[66]
Guiding reinforcement learning with shared control templates
Abhishek Padalkar, Gabriel Quere, Franz Steinmetz, Antonin Raffin, Matthias Nieuwenhuisen, Jo \ a o Silv \'e rio, and Freek Stulp. Guiding reinforcement learning with shared control templates. In ICRA, pp.\ 11531--11537, 2023 b
work page 2023
-
[67]
The surprising effectiveness of representation learning for visual imitation
Jyothish Pari, Nur Muhammad Shafiullah, Sridhar Pandian Arunachalam, and Lerrel Pinto. The surprising effectiveness of representation learning for visual imitation. In Proceedings of Robotics: Science and Systems (RSS), 2022
work page 2022
-
[68]
Supramodal and cross-modal representations of working memory in higher-order cortex
Doyoung Park, Seong-Hwan Hwang, Keonwoo Lee, Yeeun Ryoo, Hyoung F Kim, and Sue-Hyun Lee. Supramodal and cross-modal representations of working memory in higher-order cortex. Nature Communications, 16 0 (1): 0 4497, 2025
work page 2025
-
[69]
Embodied artificial intelligence: Trends and challenges
Rolf Pfeifer and Fumiya Iida. Embodied artificial intelligence: Trends and challenges. Lecture notes in computer science, pp.\ 1--26, 2004
work page 2004
-
[70]
Spatialvla: Exploring spatial representations for visual-language-action model
Delin Qu, Haoming Song, Qizhi Chen, Yuanqi Yao, Xinyi Ye, Yan Ding, Zhigang Wang, JiaYuan Gu, Bin Zhao, Dong Wang, et al. Spatialvla: Exploring spatial representations for visual-language-action model. In Proceedings of Robotics: Science and Systems (RSS), 2025
work page 2025
-
[71]
Shared control templates for assistive robotics
Gabriel Quere, Annette Hagengruber, Maged Iskandar, Samuel Bustamante, Daniel Leidner, Freek Stulp, and J \"o rn Vogel. Shared control templates for assistive robotics. In 2020 IEEE international conference on robotics and automation (ICRA), pp.\ 1956--1962. IEEE, 2020
work page 2020
-
[72]
Robot learning with sensorimotor pre-training
Ilija Radosavovic, Baifeng Shi, Letian Fu, Ken Goldberg, Trevor Darrell, and Jitendra Malik. Robot learning with sensorimotor pre-training. In Conference on Robot Learning, pp.\ 683--693. PMLR, 2023 a
work page 2023
-
[73]
Real-world robot learning with masked visual pre-training
Ilija Radosavovic, Tete Xiao, Stephen James, Pieter Abbeel, Jitendra Malik, and Trevor Darrell. Real-world robot learning with masked visual pre-training. In Conference on Robot Learning, pp.\ 416--426. PMLR, 2023 b
work page 2023
-
[74]
Latent plans for task-agnostic offline reinforcement learning
Erick Rosete-Beas, Oier Mees, Gabriel Kalweit, Joschka Boedecker, and Wolfram Burgard. Latent plans for task-agnostic offline reinforcement learning. In Conference on Robot Learning, pp.\ 1838--1849. PMLR, 2023
work page 2023
-
[75]
Multi-resolution sensing for real-time control with vision-language models
Saumya Saxena, Mohit Sharma, and Oliver Kroemer. Multi-resolution sensing for real-time control with vision-language models. In 2nd Workshop on Language and Robot Learning: Language as Grounding, 2023
work page 2023
-
[76]
Behavior transformers: Cloning k modes with one stone
Nur Muhammad Shafiullah, Zichen Cui, Ariuntuya Arty Altanzaya, and Lerrel Pinto. Behavior transformers: Cloning k modes with one stone. Advances in neural information processing systems, 35: 0 22955--22968, 2022
work page 2022
-
[77]
Nur Muhammad Mahi Shafiullah, Anant Rai, Haritheja Etukuru, Yiqian Liu, Ishan Misra, Soumith Chintala, and Lerrel Pinto. On bringing robots home. arXiv preprint arXiv:2311.16098, 2023
-
[78]
Rapid exploration for open-world navigation with latent goal models
Dhruv Shah, Benjamin Eysenbach, Gregory Kahn, Nicholas Rhinehart, and Sergey Levine. Rapid exploration for open-world navigation with latent goal models. In Proceedings of the Conference on Robot Learning (CoRL), 2021
work page 2021
-
[79]
Mutex: Learning unified policies from multimodal task specifications
Rutav Shah, Roberto Mart \' n-Mart \' n, and Yuke Zhu. Mutex: Learning unified policies from multimodal task specifications. In Proceedings of the Conference on Robot Learning (CoRL), 2023
work page 2023
-
[80]
Dense policy: Bidirectional autoregressive learning of actions
Yue Su, Xinyu Zhan, Hongjie Fang, Han Xue, Hao-Shu Fang, Yong-Lu Li, Cewu Lu, and Lixin Yang. Dense policy: Bidirectional autoregressive learning of actions. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2025
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.