OpenTrack3D: Towards Accurate and Generalizable Open-Vocabulary 3D Instance Segmentation
Pith reviewed 2026-05-17 02:56 UTC · model grok-4.3
The pith
OpenTrack3D uses an online visual-spatial tracker on lifted 2D masks to generate consistent 3D instance proposals without meshes or dataset-specific training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
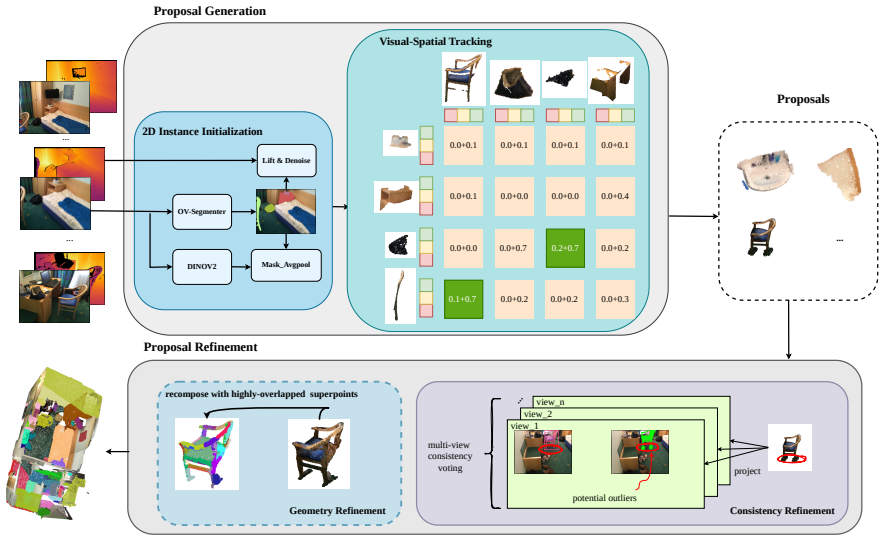
OpenTrack3D constructs cross-view consistent object proposals online using a visual-spatial tracker that fuses visual and spatial cues from depth-lifted 2D open-vocabulary masks and DINO feature maps. The core pipeline operates entirely without meshes, though an optional superpoints refinement is available when meshes exist. Substituting a multi-modal large language model for CLIP enhances compositional reasoning on user queries, leading to state-of-the-art results on benchmarks including ScanNet200, Replica, ScanNet++, and SceneFun3D.
What carries the argument
The visual-spatial tracker, which maintains instance consistency by fusing visual features from DINO and spatial cues from the 3D point clouds lifted from 2D masks.
If this is right
- The framework applies to diverse unstructured scenes without requiring scene meshes or retraining proposal networks.
- It supports complex natural language queries through improved reasoning with the multi-modal LLM.
- Performance reaches state-of-the-art levels while maintaining strong generalization to novel scenes.
- Optional mesh-based refinement further boosts accuracy when a scene mesh is provided.
Where Pith is reading between the lines
- If the tracker reliably handles occlusions and motion, it could extend to dynamic real-time 3D tracking in robotics.
- Connecting the lifted proposals to other 3D tasks like navigation or manipulation becomes feasible without additional training.
- Testing on outdoor or highly cluttered environments would reveal the limits of the current 2D segmenter and depth lifting assumptions.
Load-bearing premise
That lifting 2D masks with depth and fusing DINO visual features with spatial cues in the tracker will produce reliable instance consistency across multiple views in varied unstructured scenes.
What would settle it
A set of RGB-D sequences from a new unstructured scene where the tracker frequently merges or splits the same physical objects across frames, leading to incorrect 3D instances.
Figures




read the original abstract
Generalizing open-vocabulary 3D instance segmentation (OV-3DIS) to diverse, unstructured, and mesh-free environments is crucial for robotics and AR/VR, yet remains a significant challenge. We attribute this to two key limitations of existing methods: (1) proposal generation relies on dataset-specific proposal networks or mesh-based superpoints, rendering them inapplicable in mesh-free scenarios and limiting generalization to novel scenes; and (2) the weak textual reasoning of CLIP-based classifiers, which struggle to recognize compositional and functional user queries. To address these issues, we introduce OpenTrack3D, a generalizable and accurate framework. Unlike methods that rely on pre-generated proposals, OpenTrack3D employs a novel visual-spatial tracker to construct cross-view consistent object proposals online. Given an RGB-D stream, our pipeline first leverages a 2D open-vocabulary segmenter to generate masks, which are lifted to 3D point clouds using depth. Mask-guided instance features are then extracted using DINO feature maps, and our tracker fuses visual and spatial cues to maintain instance consistency. The core pipeline is entirely mesh-free, yet we also provide an optional superpoints refinement module to further enhance performance when scene mesh is available. Finally, we replace CLIP with a multi-modal large language model (MLLM), significantly enhancing compositional reasoning for complex user queries. Extensive experiments on diverse benchmarks, including ScanNet200, Replica, ScanNet++, and SceneFun3D, demonstrate state-of-the-art performance and strong generalization capabilities.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces OpenTrack3D for open-vocabulary 3D instance segmentation in mesh-free, unstructured environments. It generates 2D masks via an open-vocabulary segmenter, lifts them to 3D point clouds with depth, extracts mask-guided DINO features, and fuses visual and spatial cues in a novel visual-spatial tracker to produce cross-view consistent proposals online. An optional superpoint refinement module is included when meshes are available, and CLIP is replaced by an MLLM to improve handling of compositional queries. The work claims SOTA results and strong generalization on ScanNet200, Replica, ScanNet++, and SceneFun3D.
Significance. If the results hold, the mesh-free design and online tracker would meaningfully advance OV-3DIS for robotics and AR/VR by removing reliance on dataset-specific proposals or precomputed meshes. Replacing CLIP with an MLLM for better compositional reasoning is a clear strength, and the optional refinement path allows fair comparison with mesh-based methods.
major comments (2)
- [§3.2] §3.2 (Visual-Spatial Tracker): The fusion of DINO visual features with spatial cues is described at a high level but does not specify the weighting scheme, update rules, or handling of depth noise/occlusions; this mechanism is load-bearing for the central claim of reliable cross-view consistency without mesh or per-dataset training.
- [§4.3] §4.3 (Experiments on SceneFun3D): The generalization claims to unstructured scenes rest on quantitative tables, yet no ablation isolating the tracker's contribution (e.g., tracker vs. naive depth-lifted masks) or error bars across runs is reported; this weakens the evidence that the novel component drives the reported gains.
minor comments (2)
- [§2] §2 (Related Work): A brief discussion of recent MLLM-based 3D methods (post-2023) would better contextualize the CLIP replacement choice.
- [Figure 4] Figure 4: The qualitative visualizations would benefit from explicit callouts showing where the tracker resolves identity switches that naive lifting fails on.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments. We are pleased that the referee recognizes the potential impact of our mesh-free design and the use of MLLM for compositional reasoning. We address the major comments below and plan to revise the manuscript accordingly.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Visual-Spatial Tracker): The fusion of DINO visual features with spatial cues is described at a high level but does not specify the weighting scheme, update rules, or handling of depth noise/occlusions; this mechanism is load-bearing for the central claim of reliable cross-view consistency without mesh or per-dataset training.
Authors: We agree that the description in §3.2 is somewhat high-level and will provide more technical details in the revision. Specifically, we will elaborate on the weighting scheme used to fuse DINO visual features with spatial cues (e.g., a learned or fixed combination based on similarity scores), the update rules for the tracker (including how proposals are matched and updated across frames), and our strategies for handling depth noise and occlusions, such as using temporal consistency checks and outlier rejection. These additions will strengthen the explanation of how cross-view consistency is achieved in mesh-free settings. revision: yes
-
Referee: [§4.3] §4.3 (Experiments on SceneFun3D): The generalization claims to unstructured scenes rest on quantitative tables, yet no ablation isolating the tracker's contribution (e.g., tracker vs. naive depth-lifted masks) or error bars across runs is reported; this weakens the evidence that the novel component drives the reported gains.
Authors: We appreciate this suggestion for strengthening the experimental validation. In the revised manuscript, we will include an ablation study on SceneFun3D that isolates the contribution of the visual-spatial tracker by comparing it against a naive baseline that uses depth-lifted masks without tracking. Additionally, we will report error bars or standard deviations from multiple runs to provide a more robust assessment of the results and confirm that the gains are attributable to the proposed tracker. revision: yes
Circularity Check
No circularity: pipeline assembles independent off-the-shelf components
full rationale
The paper presents OpenTrack3D as an assembly of existing modules (2D open-vocabulary segmenter, depth lifting, DINO features, MLLM replacement for CLIP, and a described visual-spatial tracker) without any equations, fitted parameters, or self-referential definitions that reduce the claimed performance or consistency to quantities defined by the authors' own choices. No load-bearing step is shown to collapse by construction to prior self-citations or ansatzes; the tracker is introduced as a new fusion mechanism rather than derived from the paper's own inputs. The derivation chain therefore remains self-contained against external benchmarks and does not exhibit any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Our tracker fuses visual (DINO features) and spatial cues to maintain instance consistency across views... s = α cos(f_T, f_I) + (1-α) IoU_voxel
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The core pipeline is entirely mesh-free... optional superpoints refinement
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
SpaCeFormer: Fast Proposal-Free Open-Vocabulary 3D Instance Segmentation
SpaCeFormer delivers 11.1 zero-shot mAP on ScanNet200 (2.8x prior proposal-free best) and runs 2-3 orders of magnitude faster than multi-stage 2D+3D pipelines by using spatial window attention and Morton-curve seriali...
Reference graph
Works this paper leans on
-
[1]
Mohamed El Amine Boudjoghra, Angela Dai, Jean Lahoud, Hisham Cholakkal, Rao Muhammad Anwer, Salman Khan, and Fahad Shahbaz Khan. Open-yolo 3d: Towards fast and accurate open-vocabulary 3d instance segmentation.arXiv preprint arXiv:2406.02548, 2024. 2, 5
-
[2]
Clip2scene: Towards label-efficient 3d scene understanding by clip
Runnan Chen, Youquan Liu, Lingdong Kong, Xinge Zhu, Yuexin Ma, Yikang Li, Yuenan Hou, Yu Qiao, and Wen- ping Wang. Clip2scene: Towards label-efficient 3d scene understanding by clip. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 7020–7030, 2023. 1, 2
work page 2023
-
[3]
Yolo-world: Real-time open-vocabulary object detection
Tianheng Cheng, Lin Song, Yixiao Ge, Wenyu Liu, Xing- gang Wang, and Ying Shan. Yolo-world: Real-time open-vocabulary object detection. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16901–16911, 2024. 2, 6, 1
work page 2024
-
[4]
Gsnerf: Generalizable semantic neural radiance fields with enhanced 3d scene understanding
Zi-Ting Chou, Sheng-Yu Huang, I Liu, Yu-Chiang Frank Wang, et al. Gsnerf: Generalizable semantic neural radiance fields with enhanced 3d scene understanding. InProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 20806–20815, 2024. 1
work page 2024
-
[5]
Functionality understanding and segmentation in 3d scenes
Jaime Corsetti, Francesco Giuliari, Alice Fasoli, Davide Boscaini, and Fabio Poiesi. Functionality understanding and segmentation in 3d scenes. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 24550– 24559, 2025. 2, 7
work page 2025
-
[6]
Chang, Manolis Savva, Maciej Hal- ber, Thomas Funkhouser, and Matthias Nießner
Angela Dai, Angel X. Chang, Manolis Savva, Maciej Hal- ber, Thomas Funkhouser, and Matthias Nießner. Scannet: Richly-annotated 3d reconstructions of indoor scenes. In Proc. Computer Vision and Pattern Recognition (CVPR), IEEE, 2017. 2, 6, 1
work page 2017
-
[7]
Scenefun3d: Fine-grained functionality and affordance un- derstanding in 3d scenes
Alexandros Delitzas, Ayca Takmaz, Federico Tombari, Robert Sumner, Marc Pollefeys, and Francis Engelmann. Scenefun3d: Fine-grained functionality and affordance un- derstanding in 3d scenes. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14531–14542, 2024. 2, 6, 7, 1
work page 2024
-
[8]
Runyu Ding, Jihan Yang, Chuhui Xue, Wenqing Zhang, Song Bai, and Xiaojuan Qi. Lowis3d: Language-driven open-world instance-level 3d scene understanding.IEEE Transactions on Pattern Analysis and Machine Intelligence,
-
[9]
Pla: Language-driven open- vocabulary 3d scene understanding
Runyu Ding, Jihan Yang, Chuhui Xue, Wenqing Zhang, Song Bai, and Xiaojuan Qi. Pla: Language-driven open- vocabulary 3d scene understanding. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 7010–7019, 2023. 1, 2
work page 2023
-
[10]
A density-based algorithm for discovering clusters in large spatial databases with noise
Martin Ester, Hans-Peter Kriegel, J ¨org Sander, Xiaowei Xu, et al. A density-based algorithm for discovering clusters in large spatial databases with noise. Inkdd, pages 226–231,
-
[11]
Efficient graph-based image segmentation.International journal of computer vision, 59:167–181, 2004
Pedro F Felzenszwalb and Daniel P Huttenlocher. Efficient graph-based image segmentation.International journal of computer vision, 59:167–181, 2004. 4
work page 2004
-
[12]
Sam-guided graph cut for 3d instance segmentation
Haoyu Guo, He Zhu, Sida Peng, Yuang Wang, Yujun Shen, Ruizhen Hu, and Xiaowei Zhou. Sam-guided graph cut for 3d instance segmentation. InEuropean Conference on Com- puter Vision, pages 234–251. Springer, 2024. 1, 2, 5
work page 2024
-
[13]
Segment3d: Learning fine-grained class-agnostic 3d segmentation without manual labels
Rui Huang, Songyou Peng, Ayca Takmaz, Federico Tombari, Marc Pollefeys, Shiji Song, Gao Huang, and Francis Engel- mann. Segment3d: Learning fine-grained class-agnostic 3d segmentation without manual labels. InEuropean Confer- ence on Computer Vision, pages 278–295. Springer, 2024. 1, 2, 7
work page 2024
-
[14]
Openins3d: Snap and lookup for 3d open-vocabulary instance segmentation
Zhening Huang, Xiaoyang Wu, Xi Chen, Hengshuang Zhao, Lei Zhu, and Joan Lasenby. Openins3d: Snap and lookup for 3d open-vocabulary instance segmentation. InEuropean Conference on Computer Vision, pages 169–185. Springer,
-
[15]
Details matter for indoor open- vocabulary 3d instance segmentation
Sanghun Jung, Jingjing Zheng, Ke Zhang, Nan Qiao, Al- bert YC Chen, Lu Xia, Chi Liu, Yuyin Sun, Xiao Zeng, Hsiang-Wei Huang, et al. Details matter for indoor open- vocabulary 3d instance segmentation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 9627–9637, 2025. 2, 5, 8, 1
work page 2025
-
[16]
Lerf: Language embedded radiance fields
Justin Kerr, Chung Min Kim, Ken Goldberg, Angjoo Kanazawa, and Matthew Tancik. Lerf: Language embedded radiance fields. InProceedings of the IEEE/CVF interna- tional conference on computer vision, pages 19729–19739,
-
[17]
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer White- head, Alexander C Berg, Wan-Yen Lo, et al. Segment any- thing. InProceedings of the IEEE/CVF International Con- ference on Computer Vision, pages 4015–4026, 2023. 1
work page 2023
-
[18]
Oneformer3d: One transformer for unified point cloud segmentation
Maxim Kolodiazhnyi, Anna V orontsova, Anton Konushin, and Danila Rukhovich. Oneformer3d: One transformer for unified point cloud segmentation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 20943–20953, 2024. 1
work page 2024
-
[19]
Gonzalez, Hao Zhang, and Ion Stoica
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with pagedattention. InPro- ceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles, 2023. 1
work page 2023
-
[20]
Grounding dino: Marry- ing dino with grounded pre-training for open-set object de- tection, 2024
Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Qing Jiang, Chunyuan Li, Jianwei Yang, Hang Su, Jun Zhu, and Lei Zhang. Grounding dino: Marry- ing dino with grounded pre-training for open-set object de- tection, 2024. 1, 2
work page 2024
-
[21]
Ovir-3d: Open-vocabulary 3d in- stance retrieval without training on 3d data
Shiyang Lu, Haonan Chang, Eric Pu Jing, Abdeslam Boular- ias, and Kostas Bekris. Ovir-3d: Open-vocabulary 3d in- stance retrieval without training on 3d data. InConference on Robot Learning, pages 1610–1620. PMLR, 2023. 2, 5
work page 2023
-
[22]
Tuan Duc Ngo, Binh-Son Hua, and Khoi Nguyen. Isbnet: a 3d point cloud instance segmentation network with instance- aware sampling and box-aware dynamic convolution. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13550–13559, 2023. 1
work page 2023
-
[23]
Open3dis: Open-vocabulary 3d instance segmentation with 9 2d mask guidance
Phuc Nguyen, Tuan Duc Ngo, Evangelos Kalogerakis, Chuang Gan, Anh Tran, Cuong Pham, and Khoi Nguyen. Open3dis: Open-vocabulary 3d instance segmentation with 9 2d mask guidance. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 4018–4028, 2024. 2, 5, 7, 1
work page 2024
-
[24]
Any3dis: Class-agnostic 3d instance segmentation by 2d mask tracking
Phuc Nguyen, Minh Luu, Anh Tran, Cuong Pham, and Khoi Nguyen. Any3dis: Class-agnostic 3d instance segmentation by 2d mask tracking. InProceedings of the Computer Vi- sion and Pattern Recognition Conference, pages 3636–3645,
-
[25]
DINOv2: Learning Robust Visual Features without Supervision
Maxime Oquab, Timoth ´ee Darcet, Th ´eo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193, 2023. 2, 4, 1
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[26]
Oa-cnns: Omni- adaptive sparse cnns for 3d semantic segmentation
Bohao Peng, Xiaoyang Wu, Li Jiang, Yukang Chen, Heng- shuang Zhao, Zhuotao Tian, and Jiaya Jia. Oa-cnns: Omni- adaptive sparse cnns for 3d semantic segmentation. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21305–21315, 2024. 1
work page 2024
-
[27]
Openscene: 3d scene understanding with open vocabularies
Songyou Peng, Kyle Genova, Chiyu Jiang, Andrea Tagliasacchi, Marc Pollefeys, Thomas Funkhouser, et al. Openscene: 3d scene understanding with open vocabularies. InProceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, pages 815–824, 2023. 1, 2, 5
work page 2023
-
[28]
Learning transferable visual models from natural language supervi- sion
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervi- sion. InInternational conference on machine learning, pages 8748–8763. PMLR, 2021. 1, 2
work page 2021
-
[29]
SAM 2: Segment Anything in Images and Videos
Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman R¨adle, Chloe Rolland, Laura Gustafson, et al. Sam 2: Segment anything in images and videos.arXiv preprint arXiv:2408.00714, 2024. 1, 2, 6
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[30]
Language- grounded indoor 3d semantic segmentation in the wild
David Rozenberszki, Or Litany, and Angela Dai. Language- grounded indoor 3d semantic segmentation in the wild. In European conference on computer vision, pages 125–141. Springer, 2022. 1
work page 2022
-
[31]
Jonas Schult, Francis Engelmann, Alexander Hermans, Or Litany, Siyu Tang, and Bastian Leibe. Mask3d: Mask trans- former for 3d semantic instance segmentation.arXiv preprint arXiv:2210.03105, 2022. 1, 5
-
[32]
Spherical mask: Coarse-to- fine 3d point cloud instance segmentation with spherical rep- resentation
Sangyun Shin, Kaichen Zhou, Madhu Vankadari, Andrew Markham, and Niki Trigoni. Spherical mask: Coarse-to- fine 3d point cloud instance segmentation with spherical rep- resentation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4060– 4069, 2024. 1
work page 2024
-
[33]
Julian Straub, Thomas Whelan, Lingni Ma, Yufan Chen, Erik Wijmans, Simon Green, Jakob J. Engel, Raul Mur-Artal, Carl Ren, Shobhit Verma, Anton Clarkson, Mingfei Yan, Brian Budge, Yajie Yan, Xiaqing Pan, June Yon, Yuyang Zou, Kimberly Leon, Nigel Carter, Jesus Briales, Tyler Gillingham, Elias Mueggler, Luis Pesqueira, Manolis Savva, Dhruv Batra, Hauke M. S...
work page internal anchor Pith review Pith/arXiv arXiv 1906
-
[34]
Alpha- clip: A clip model focusing on wherever you want
Zeyi Sun, Ye Fang, Tong Wu, Pan Zhang, Yuhang Zang, Shu Kong, Yuanjun Xiong, Dahua Lin, and Jiaqi Wang. Alpha- clip: A clip model focusing on wherever you want. InPro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 13019–13029, 2024. 2
work page 2024
-
[35]
Openmask3d: Open-vocabulary 3d instance segmenta- tion,
Ayc ¸a Takmaz, Elisabetta Fedele, Robert W Sumner, Marc Pollefeys, Federico Tombari, and Francis Engelmann. Open- mask3d: Open-vocabulary 3d instance segmentation.arXiv preprint arXiv:2306.13631, 2023. 2, 5, 7
-
[36]
Nesf: Neural semantic fields for generalizable semantic segmentation of 3d scenes
Suhani V ora, Noha Radwan, Klaus Greff, Henning Meyer, Kyle Genova, Mehdi SM Sajjadi, Etienne Pot, Andrea Tagliasacchi, and Daniel Duckworth. Nesf: Neural semantic fields for generalizable semantic segmentation of 3d scenes. arXiv preprint arXiv:2111.13260, 2021. 1
-
[37]
Softgroup for 3d instance segmentation on point clouds
Thang Vu, Kookhoi Kim, Tung M Luu, Thanh Nguyen, and Chang D Yoo. Softgroup for 3d instance segmentation on point clouds. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2708– 2717, 2022. 1
work page 2022
-
[38]
Mi Yan, Jiazhao Zhang, Yan Zhu, and He Wang. Maskclus- tering: View consensus based mask graph clustering for open-vocabulary 3d instance segmentation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pat- tern Recognition, pages 28274–28284, 2024. 2, 5
work page 2024
-
[39]
Regionplc: Regional point-language contrastive learning for open-world 3d scene understanding
Jihan Yang, Runyu Ding, Weipeng Deng, Zhe Wang, and Xi- aojuan Qi. Regionplc: Regional point-language contrastive learning for open-world 3d scene understanding. InProceed- ings of the IEEE/CVF conference on computer vision and pattern recognition, pages 19823–19832, 2024. 1, 2
work page 2024
-
[40]
Scannet++: A high-fidelity dataset of 3d indoor scenes, 2023
Chandan Yeshwanth, Yueh-Cheng Liu, Matthias Nießner, and Angela Dai. Scannet++: A high-fidelity dataset of 3d indoor scenes, 2023. 2, 6, 1
work page 2023
-
[41]
Sai3d: Segment any instance in 3d scenes
Yingda Yin, Yuzheng Liu, Yang Xiao, Daniel Cohen-Or, Jingwei Huang, and Baoquan Chen. Sai3d: Segment any instance in 3d scenes. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 3292–3302, 2024. 2, 5
work page 2024
-
[42]
Sam2object: Consolidating view consistency via sam2 for zero-shot 3d instance segmentation
Jihuai Zhao, Junbao Zhuo, Jiansheng Chen, and Huimin Ma. Sam2object: Consolidating view consistency via sam2 for zero-shot 3d instance segmentation. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 19325–19334, 2025. 2, 5
work page 2025
-
[43]
In-place scene labelling and understanding with implicit scene representation
Shuaifeng Zhi, Tristan Laidlow, Stefan Leutenegger, and An- drew J Davison. In-place scene labelling and understanding with implicit scene representation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 15838–15847, 2021. 1 10 OpenTrack3D: Towards Accurate and Generalizable Open-Vocabulary 3D Instance Segmentation Suppleme...
work page 2021
-
[44]
More Implementation Details In this section, we provide additional implementation de- tails of our MLLM components to improve understand- ing and reproducibility. We deploy Qwen3-4B using vLLM [19] on a single A100 GPU and use the default gen- eration settings unless otherwise noted. For the SceneFun3D [7] dataset, the user-provided task descriptions cann...
-
[45]
Sensitivity analysis of theτ match parameter on subsets of the ScanNet200 validation set
Hyperparameter Sensitivity Analysis τmatch AP AP 50 AP25 0.6 26.4 38.3 46.4 0.5 28.2 39.6 47.9 0.4 28.6 40.5 48.8 0.3 27.3 38.2 45.9 Table 7. Sensitivity analysis of theτ match parameter on subsets of the ScanNet200 validation set. τexp AP τvis AP γAP τmerge AP 0.00 28.0 0.1 28.6 0.5 27.6 0.8 27.6 0.03 28.2 0.229.1 0.4 28.6 0.7 28.4 0.0528.6 0.3 27.2 0.32...
-
[46]
Most of our runtime is spent on model inference
Runtime Analysis We analyze the runtime of our framework and compare it with the previous state-of-the-art, DetailMatters [15]. Most of our runtime is spent on model inference. The cost of the 2D open-vocabulary segmenter and DINO scales with the number of video frames, while the proposal-classification cost (via either MLLM or CLIP [28]) mainly depends o...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.