Recognition: unknown
SpaCeFormer: Fast Proposal-Free Open-Vocabulary 3D Instance Segmentation
Pith reviewed 2026-05-10 00:03 UTC · model grok-4.3
The pith
A space-curve transformer performs open-vocabulary 3D instance segmentation directly from point clouds without external proposals or multi-stage pipelines.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
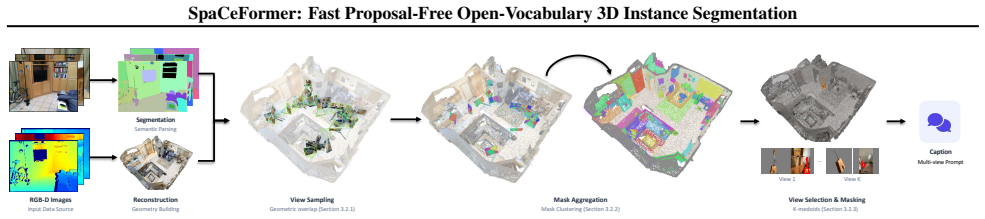
SpaCeFormer is a proposal-free space-curve transformer that combines spatial window attention with Morton-curve serialization to extract spatially coherent features from point clouds and uses a RoPE-enhanced decoder to predict instance masks directly from learned queries. When trained on the SpaCeFormer-3M dataset of 3.0M multi-view-consistent captions obtained through mask clustering and VLM captioning, the model reaches 11.1 zero-shot mAP on ScanNet200 (2.8 times the prior best proposal-free result), 22.9 mAP on ScanNet++, and 24.1 mAP on Replica, all while processing each scene in 0.14 seconds.
What carries the argument
The space-curve transformer, which serializes 3D points along Morton curves to enable efficient spatial window attention and employs a rotary position embedding decoder to output instance masks from learned queries without any external proposals.
If this is right
- Real-time deployment becomes feasible for robotics and AR/VR applications that require open-vocabulary 3D instance segmentation.
- The approach eliminates dependence on slow aggregation of 2D foundation model outputs or post-processing of fragmented masks.
- Direct mask prediction from queries removes the need for external region proposals or additional clustering stages.
- The multi-view captioning pipeline produces training data with substantially higher mask recall than single-view methods.
Where Pith is reading between the lines
- Curve-based serialization of 3D points may offer a general way to make transformers efficient on unordered spatial data without quadratic attention costs.
- Strong results from VLM-generated pseudo-labels suggest the method could scale to much larger collections of unlabeled 3D scans.
- The reported inference speed opens the possibility of integrating the model into online 3D mapping pipelines that update instance labels frame by frame.
Load-bearing premise
The pseudo-labels created by clustering masks across multiple views and captioning them with a vision-language model must be sufficiently accurate and free of systematic biases for the model to learn useful patterns rather than artifacts.
What would settle it
Retraining the identical model architecture on the same scenes but using single-view captions instead of the multi-view clustered captions, then measuring whether zero-shot mAP on ScanNet200 falls below the prior best proposal-free baseline, would directly test the necessity of the dataset construction step.
Figures





















read the original abstract
Open-vocabulary 3D instance segmentation is a core capability for robotics and AR/VR, but prior methods trade one bottleneck for another: multi-stage 2D+3D pipelines aggregate foundation-model outputs at hundreds of seconds per scene, while pseudo-labeled end-to-end approaches rely on fragmented masks and external region proposals. We present SpaCeFormer, a proposal-free space-curve transformer that runs at 0.14 seconds per scene, 2-3 orders of magnitude faster than multi-stage 2D+3D pipelines. We pair it with SpaCeFormer-3M, the largest open-vocabulary 3D instance segmentation dataset (3.0M multi-view-consistent captions over 604K instances from 7.4K scenes) built through multi-view mask clustering and multi-view VLM captioning; it reaches 21x higher mask recall than prior single-view pipelines (54.3% vs 2.5% at IoU > 0.5). SpaCeFormer combines spatial window attention with Morton-curve serialization for spatially coherent features, and uses a RoPE-enhanced decoder to predict instance masks directly from learned queries without external proposals. On ScanNet200 we achieve 11.1 zero-shot mAP, a 2.8x improvement over the prior best proposal-free method; on ScanNet++ and Replica, we reach 22.9 and 24.1 mAP, surpassing all prior methods including those using multi-view 2D inputs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents SpaCeFormer, a proposal-free space-curve transformer for open-vocabulary 3D instance segmentation. It runs at 0.14 seconds per scene using spatial window attention, Morton-curve serialization, and a RoPE-enhanced decoder to predict instance masks directly from learned queries. The authors introduce the SpaCeFormer-3M dataset (3.0M multi-view-consistent captions over 604K instances from 7.4K scenes) generated via multi-view mask clustering and VLM captioning, claiming 21x higher mask recall (54.3% vs. 2.5% at IoU > 0.5) than prior single-view pipelines. They report 11.1 zero-shot mAP on ScanNet200 (2.8x over prior best proposal-free method), 22.9 mAP on ScanNet++, and 24.1 mAP on Replica, surpassing prior methods including multi-view 2D approaches.
Significance. If the results hold after validation of the pseudo-label pipeline, the work would be significant for enabling real-time open-vocabulary 3D perception in robotics and AR/VR, offering 2-3 orders of magnitude faster inference than multi-stage 2D+3D pipelines while improving accuracy. The large-scale SpaCeFormer-3M dataset could become a valuable resource for training and benchmarking future open-vocabulary methods. The architectural choices (Morton-curve serialization combined with window attention) represent a practical adaptation of transformer techniques to 3D point clouds.
major comments (2)
- [Abstract / Dataset Construction] Abstract and dataset construction section: The headline zero-shot mAP gains (11.1 on ScanNet200, 22.9/24.1 on ScanNet++/Replica) and the 2.8x improvement claim rest on training with SpaCeFormer-3M pseudo-labels. While 54.3% recall at IoU > 0.5 is stated, no precision, caption fidelity (e.g., agreement with ground-truth labels), or cross-view semantic consistency metrics are reported. Without these, it remains possible that performance exploits systematic label noise or view-specific artifacts rather than demonstrating genuine open-vocabulary generalization; this is load-bearing for all empirical claims.
- [Experimental Evaluation] Experimental evaluation section: The abstract and results claim superiority over proposal-free and multi-view 2D baselines, but no ablations isolate the contribution of the space-curve transformer components (spatial window attention, Morton serialization, RoPE decoder) from the quality of the multi-view VLM pseudo-labels. This makes it difficult to attribute gains to the proposed architecture versus the new training data.
minor comments (1)
- [Abstract] The abstract refers to SpaCeFormer-3M as 'the largest' dataset but provides no direct size or diversity comparison table against prior open-vocabulary 3D datasets beyond the single recall number.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and describe the revisions we will incorporate to strengthen the presentation.
read point-by-point responses
-
Referee: [Abstract / Dataset Construction] Abstract and dataset construction section: The headline zero-shot mAP gains (11.1 on ScanNet200, 22.9/24.1 on ScanNet++/Replica) and the 2.8x improvement claim rest on training with SpaCeFormer-3M pseudo-labels. While 54.3% recall at IoU > 0.5 is stated, no precision, caption fidelity (e.g., agreement with ground-truth labels), or cross-view semantic consistency metrics are reported. Without these, it remains possible that performance exploits systematic label noise or view-specific artifacts rather than demonstrating genuine open-vocabulary generalization; this is load-bearing for all empirical claims.
Authors: We agree that additional quantitative validation of the pseudo-label pipeline would strengthen the claims. The original submission emphasized mask recall (54.3% vs. 2.5%) as the key indicator of multi-view improvement over single-view methods. To directly address concerns about label noise or view-specific artifacts, we will add precision metrics, caption fidelity scores (measured against ground-truth labels on overlapping scenes), and cross-view semantic consistency statistics to the revised dataset construction section. We note that the reported zero-shot results on ScanNet200 (and the other held-out benchmarks) were obtained on scenes and annotations not used during pseudo-label generation, which provides evidence that the gains reflect genuine open-vocabulary generalization rather than exploitation of training artifacts. revision: yes
-
Referee: [Experimental Evaluation] Experimental evaluation section: The abstract and results claim superiority over proposal-free and multi-view 2D baselines, but no ablations isolate the contribution of the space-curve transformer components (spatial window attention, Morton serialization, RoPE decoder) from the quality of the multi-view VLM pseudo-labels. This makes it difficult to attribute gains to the proposed architecture versus the new training data.
Authors: We acknowledge that explicit ablations separating architectural choices from data quality would improve attribution. The manuscript already compares SpaCeFormer against prior proposal-free methods trained on their respective (smaller) datasets, and the large margins (2.8x on ScanNet200) are consistent with the combined benefit of the space-curve design and the higher-quality multi-view labels. In the revision we will add targeted ablations, including (i) training the proposed architecture on prior pseudo-label sets and (ii) retraining a strong baseline architecture on SpaCeFormer-3M, to the extent the prior label sets are publicly available. These experiments will clarify the individual contributions while preserving the core efficiency claims. revision: yes
Circularity Check
No circularity; empirical claims rest on independent benchmarks
full rationale
The paper's core claims consist of an empirical architecture (space-curve transformer with Morton serialization and RoPE decoder) trained on a newly constructed pseudo-labeled dataset (SpaCeFormer-3M) and evaluated via standard zero-shot mAP metrics on held-out benchmarks (ScanNet200, ScanNet++, Replica). No equations, predictions, or uniqueness theorems are presented that reduce outputs to inputs by construction. Dataset construction via multi-view clustering and VLM captioning is an input-generation step whose quality is externally verifiable against ground truth, not a self-referential fit. No self-citations are invoked as load-bearing mathematical facts forbidding alternatives. The reported speed and accuracy numbers are direct measurements, not derived quantities forced by the training procedure itself.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Matterport3d: Learning from rgb-d data in indoor environments
Chang, A., Dai, A., Funkhouser, T., Halber, M., Niebner, M., Savva, M., Song, S., Zeng, A., and Zhang, Y . Matterport3d: Learning from rgb-d data in indoor environments. In7th IEEE International Conference on 3D Vision, 3DV 2017, pp. 667–676. Institute of Electrical and Electronics Engineers Inc.,
2017
-
[2]
arXiv preprint arXiv:2507.23134 (2025) 9, 12, 13
Chen, Y ., Guo, X., Chen, W., and Wang, Y . Details matter: Accu- rate 3d open-vocabulary instance segmentation.arXiv preprint arXiv:2507.23134,
-
[3]
NimbleReg: A light-weight deep-learning framework for diffeomorphic image registration
Koch, S., Navarro, M., Avetisyan, A., and Dai, A. Opensplat3d: Open-vocabulary 3d instance segmentation with gaussian splat- ting.arXiv preprint arXiv:2503.07768,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Nguyen, K., de Silva Edirimuni, D., Hassan, G. M., and Mian, A. Retrieving objects from 3d scenes with box- guided open-vocabulary instance segmentation.arXiv preprint arXiv:2512.19088,
-
[5]
Oord, A. v. d., Li, Y ., and Vinyals, O. Representation learning with contrastive predictive coding.arXiv preprint arXiv:1807.03748,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
High quality entity segmentation
Qi, L., Kuen, J., Shen, T., Gu, J., Li, W., Guo, W., Jia, J., Lin, Z., and Yang, M.-H. High quality entity segmentation. In 2023 IEEE/CVF International Conference on Computer Vision (ICCV), pp. 4024–4033. IEEE,
2023
-
[7]
Grounded SAM: Assembling Open-World Models for Diverse Visual Tasks
Ren, T., Liu, S., Zeng, A., Lin, J., Li, K., Cao, H., Chen, J., Huang, X., Chen, Y ., Yan, F., et al. Grounded sam: Assembling open-world models for diverse visual tasks.arXiv preprint arXiv:2401.14159,
-
[8]
Straub, J., Whelan, T., Ma, L., Chen, Y ., Wijmans, E., Green, S., Engel, J. J., Mur-Artal, R., Ren, C., Verber, S., Clarkson, J., Yan, Q., Wang, S., Alcantarilla, P., Cabezas, I., Chapin, L., De Nardi, R., Frank, B., Golber, O., Goldman, D., Haenel, P., Kendall, A., Leon, S., Lovegrove, S., Lv, C., Mudrazija, N., Peris, R., Rennie, S., Restrepo, L., Rodr...
work page internal anchor Pith review arXiv 1906
-
[9]
OpenTrack3D: Towards Accurate and Generalizable Open-Vocabulary 3D Instance Segmentation
Zhou, Z., Wei, S., Wang, Z., Wang, C., Yan, X., and Liu, X. Open- track3d: Towards accurate and generalizable open-vocabulary 3d instance segmentation.arXiv preprint arXiv:2512.03532,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
(Right) Non-overlapping windows shifted by half the window size, illustrating SWIN’s shifted windowing
Figure 12.SWIN Windowing on a 2D Grid.(Left) Non-overlapping windows aligned to the grid. (Right) Non-overlapping windows shifted by half the window size, illustrating SWIN’s shifted windowing. where pi = (x i, yi, zi) and pj = (x j, yj, zj) are the 3D coordinates of voxels vi and vj in window W. Lower values indicate better spatial coherence. A.5.2. WIND...
2024
-
[11]
to generate intrinsic and spatially consistent captions: 21 SpaCeFormer: Fast Proposal-Free Open-Vocabulary 3D Instance Segmentation Full System Prompt You are an expert image-captioning assistant. You will be given multiple “views” of the same subject. Your job is to synthesize these views into one cohesive description that focuses on the subject’s intri...
-
[12]
Method mAP mAP 50 mAP25 mAPhead mAPcom. mAPtail SpaCeFormer (Default) 7.78 14.24 18.93 10.58 7.14 5.28 SpaCeFormer (PreNorm) 7.60 13.73 18.57 10.62 6.47 5.42 SpaCeFormer (PostNorm) 6.23 12.34 17.43 9.45 5.21 3.70 A.11.1. SAMPLINGSTRATEGY Table 11 analyzes different key sampling strategies for the decoder. We find thatRandomsampling outperforms Full sampli...
-
[13]
The diagonal dominance indicates strong performance across most categories, though some confusion persists between semantically similar classes such as table/desk and cabinet/shelves. 27 SpaCeFormer: Fast Proposal-Free Open-Vocabulary 3D Instance Segmentation Table 14.Validation mIoU (%) on ScanNet20, ScanNet++, ScanNet200, and Matterport3D. We use the sa...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.