Rethinking Jailbreak Detection of Large Vision Language Models with Representational Contrastive Scoring
Pith reviewed 2026-05-16 22:25 UTC · model grok-4.3
The pith
Internal representations of vision-language models contain signals that a lightweight contrastive score can use to detect jailbreaks even for unseen attack types.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Representational Contrastive Scoring inspects the internal geometry of LVLM representations and learns a lightweight projection that maximally separates benign and malicious inputs in safety-critical layers, yielding a contrastive score that differentiates true malicious intent from mere distribution shift; its instantiations MCD and KCD achieve state-of-the-art performance on an evaluation protocol that tests generalization to unseen attack types.
What carries the argument
Representational Contrastive Scoring (RCS): a framework that applies a learned lightweight projection to the internal representations of safety-critical layers to compute a contrastive score separating benign from malicious inputs.
Load-bearing premise
The most potent safety signals reside inside the LVLM's own internal representations, and a lightweight projection can separate benign and malicious inputs in safety-critical layers without overfitting to the attacks seen during training.
What would settle it
Run MCD or KCD on a fresh collection of multimodal jailbreak attacks never encountered in training and measure whether detection accuracy remains high while false-positive rates on ordinary benign image-text pairs stay low; a sharp drop in either metric would falsify the generalization claim.
Figures

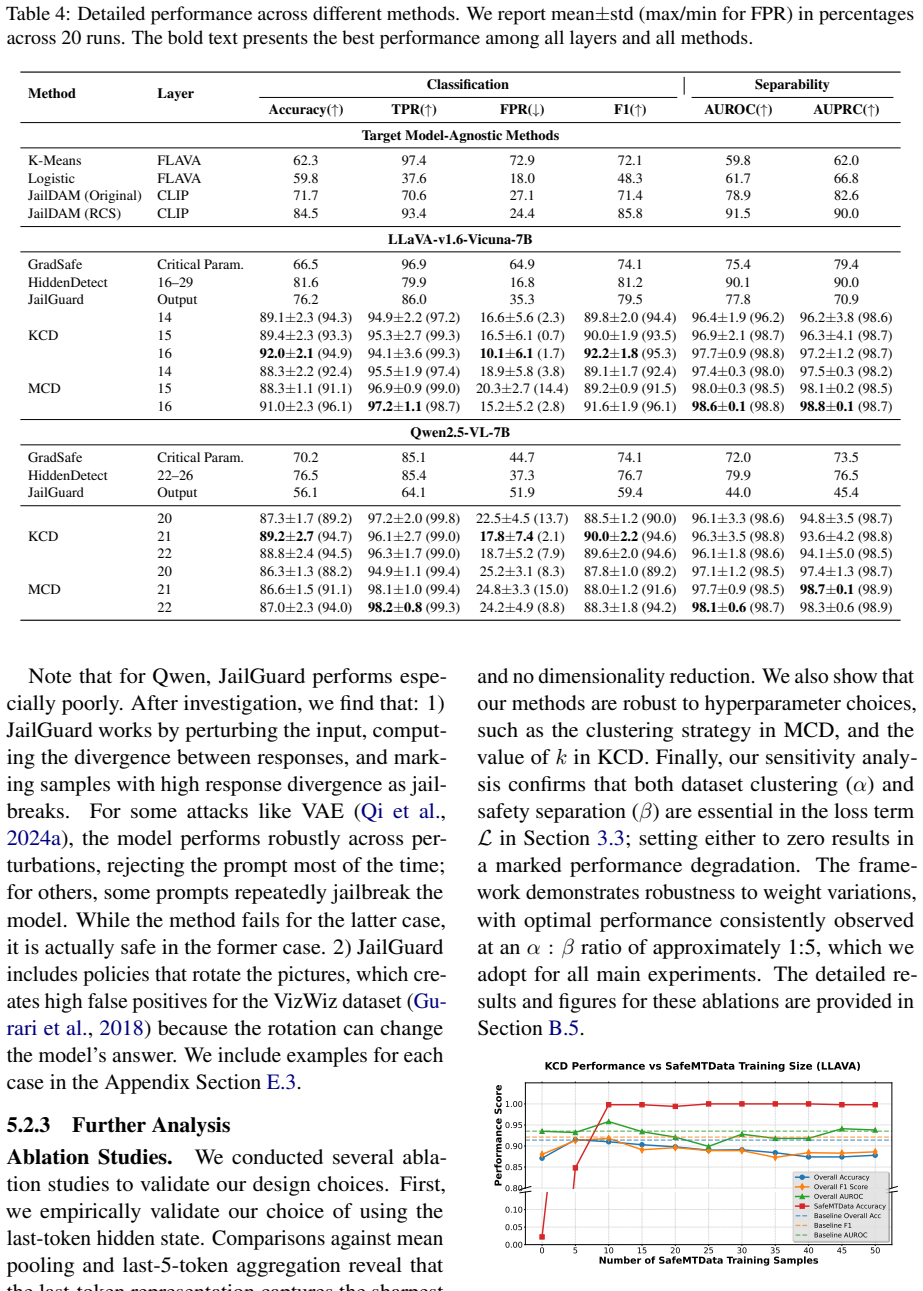









read the original abstract
Large Vision-Language Models (LVLMs) are vulnerable to a growing array of multimodal jailbreak attacks, necessitating defenses that are both generalizable to novel threats and efficient for practical deployment. Many current strategies fall short, either targeting specific attack patterns, which limits generalization, or imposing high computational overhead. While lightweight anomaly-detection methods offer a promising direction, we find that their common one-class design tends to confuse unseen benign inputs with malicious ones, leading to unreliable over-rejection. To address this, we propose Representational Contrastive Scoring (RCS), a framework built on a key insight: the most potent safety signals reside within the LVLM's own internal representations. Our approach inspects the internal geometry of these representations, learning a lightweight projection to maximally separate benign and malicious inputs in safety-critical layers. This enables a simple yet powerful contrastive score that differentiates true malicious intent from mere distribution shift. Our instantiations, MCD (Mahalanobis Contrastive Detection) and KCD (K-nearest Contrastive Detection), achieve state-of-the-art performance on a challenging evaluation protocol designed to test generalization to unseen attack types. This work demonstrates that effective jailbreak detection can be achieved by applying simple, interpretable statistical methods to the internal representations, offering a practical path towards safer LVLM deployment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Representational Contrastive Scoring (RCS) for detecting jailbreaks in Large Vision-Language Models. It claims that the most potent safety signals lie in the internal geometry of LVLM representations; a lightweight projection learned to separate benign from malicious inputs in safety-critical layers yields a contrastive score (instantiated as MCD and KCD) that achieves state-of-the-art generalization on a protocol that holds out unseen attack types, while remaining computationally lightweight.
Significance. If the central claim holds, the work is significant because it shows that simple, interpretable statistical methods applied directly to internal LVLM activations can outperform both pattern-specific defenses and heavy anomaly detectors on a generalization-focused benchmark. This offers a practical route to efficient, deployable jailbreak detection without requiring attack-specific engineering or large auxiliary models.
major comments (2)
- [§3.2] §3.2 (Projection Learning): The optimization objective for the lightweight projection is not fully specified (loss function, supervision signal, regularization, or whether only benign data are used). This detail is load-bearing for the generalization claim, because without it one cannot determine whether the reported separation on unseen attacks reflects invariant safety geometry or partial overlap between the attacks used to fit the projection and those in the test set.
- [§5.1] §5.1 (Evaluation Protocol): The paper must explicitly list which attack families are present during projection learning versus those held out for the 'unseen' test split, together with the exact train/test attack-type partition. The current description leaves open the possibility that the SOTA numbers partly reflect distribution overlap rather than true out-of-distribution robustness.
minor comments (2)
- [Abstract / §2] The abstract and §2 refer to 'safety-critical layers' without stating the selection criterion (e.g., layer index, activation norm, or empirical validation).
- [§3.3] Notation for the contrastive score (Eq. 3 or equivalent) should be accompanied by a short derivation or pseudocode to clarify how the Mahalanobis or k-NN distance is computed after the projection.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments correctly identify areas where additional methodological and protocol details will strengthen the paper. We address each point below and will revise the manuscript to incorporate the requested clarifications.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Projection Learning): The optimization objective for the lightweight projection is not fully specified (loss function, supervision signal, regularization, or whether only benign data are used). This detail is load-bearing for the generalization claim, because without it one cannot determine whether the reported separation on unseen attacks reflects invariant safety geometry or partial overlap between the attacks used to fit the projection and those in the test set.
Authors: We agree that the optimization objective must be stated explicitly for reproducibility and to support the generalization claims. In the revised manuscript we will add a precise description of the projection learning procedure, including the contrastive loss function, the use of labeled benign and malicious examples as the supervision signal, the regularization terms applied, and confirmation that both classes are used during training. This will make clear that the projection is fit on a training partition of known attacks while evaluation measures performance on held-out attack families. revision: yes
-
Referee: [§5.1] §5.1 (Evaluation Protocol): The paper must explicitly list which attack families are present during projection learning versus those held out for the 'unseen' test split, together with the exact train/test attack-type partition. The current description leaves open the possibility that the SOTA numbers partly reflect distribution overlap rather than true out-of-distribution robustness.
Authors: We will revise §5.1 to include an explicit table (or enumerated list) that states every attack family used when learning the projection versus every family held out for the unseen test split, together with the exact train/test partition. This will eliminate ambiguity and allow readers to verify that the reported results reflect generalization to truly unseen attack types rather than partial overlap. revision: yes
Circularity Check
No circularity: RCS derives contrastive scores from learned projections on internal representations
full rationale
The paper introduces Representational Contrastive Scoring by inspecting LVLM internal geometry and learning a lightweight projection to separate benign vs. malicious inputs in safety-critical layers, then computing a simple contrastive score. This construction is not self-referential: the projection parameters are fitted from data (not defined in terms of the target score), the score is a downstream statistic on the projected representations, and the generalization claims are evaluated on a held-out protocol for unseen attack types. No equations reduce the output to the inputs by construction, no self-citations are load-bearing for the core claim, and no ansatz or uniqueness theorem is smuggled in. The method is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
Revisiting JBShield: Breaking and Rebuilding Representation-Level Jailbreak Defenses
JBShield is vulnerable to adaptive JB-GCG attacks (up to 53% ASR) because jailbreak representations occupy a distinct region in refusal-direction space; the new RTV defense using Mahalanobis detection on multi-layer f...
Reference graph
Works this paper leans on
-
[1]
Refusal in language models is mediated by a single direction. InAdvances in Neural Information Processing Systems 38: Annual Conference on Neu- ral Information Processing Systems 2024, NeurIPS 2024, Vancouver, BC, Canada, December 10 - 15, 2024. Eugene Bagdasaryan, Tsung-Yin Hsieh, Ben Nassi, and Vitaly Shmatikov. 2023. Abusing images and sounds for indir...
-
[2]
A realistic threat model for large language model jailbreaks
Representation learning: A review and new perspectives.IEEE transactions on pattern analysis and machine intelligence, 35(8):1798–1828. Valentyn Boreiko, Alexander Panfilov, Vaclav V o- racek, Matthias Hein, and Jonas Geiping. 2024. An interpretable n-gram perplexity threat model for large language model jailbreaks.ArXiv preprint, abs/2410.16222. Patrick ...
-
[3]
In2025 IEEE Conference on Se- cure and Trustworthy Machine Learning (SaTML), pages 23–42
Jailbreaking black box large language models in twenty queries. In2025 IEEE Conference on Se- cure and Trustworthy Machine Learning (SaTML), pages 23–42. IEEE. Guorui Chen, Yifan Xia, Xiaojun Jia, Zhijiang Li, Philip Torr, and Jindong Gu. 2024a. Llm jailbreak detection for (almost) free!ArXiv preprint, abs/2409.14558. Jianhui Chen, Xiaozhi Wang, Zijun Yao...
-
[4]
Scalable defense against in-the-wild jailbreaking attacks with safety context retrieval,
Scalable defense against in-the-wild jailbreak- ing attacks with safety context retrieval.ArXiv preprint, abs/2505.15753. Yangyi Chen, Hongcheng Gao, Ganqu Cui, Fanchao Qi, Longtao Huang, Zhiyuan Liu, and Maosong Sun
-
[5]
Llama Guard 3 Vision: Safeguarding Human-AI Image Understanding Conversations
Why should adversarial perturbations be im- perceptible? rethink the research paradigm in adver- sarial NLP. InProceedings of the 2022 Conference on Empirical Methods in Natural Language Process- ing, pages 11222–11237, Abu Dhabi, United Arab Emirates. Association for Computational Linguistics. Yilun Chen, Ami Wiesel, and Alfred O Hero. 2011. Robust shrin...
-
[6]
Safe RLHF: safe reinforcement learning from human feedback. InThe Twelfth International Con- ference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net. Yihe Deng, Yu Yang, Junkai Zhang, Wei Wang, and Bo Li. 2025. Duoguard: A two-player rl-driven framework for multilingual llm guardrails.ArXiv preprint, abs/2502.05163....
-
[7]
Improving Reconstruction Autoencoder Out-of-distribution Detection with Mahalanobis Distance
Improving reconstruction autoencoder out- of-distribution detection with mahalanobis distance. ArXiv preprint, abs/1812.02765. Xuefeng Du, Reshmi Ghosh, Robert Sim, Ahmed Salem, Vitor Carvalho, Emily Lawton, Yixuan Li, and Jack W Stokes. 2024. Vlmguard: Defending vlms against malicious prompts via unlabeled data. ArXiv preprint, abs/2410.00296. Xuefeng Du...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
InForty-first International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27,
Agent smith: A single image can jailbreak one million multimodal LLM agents exponentially fast. InForty-first International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27,
work page 2024
-
[9]
OpenReview.net. Prannaya Gupta, Le Qi Yau, Hao Han Low, I Lee, Hugo Maximus Lim, Yu Xin Teoh, Jia Hng Koh, Dar Win Liew, Rishabh Bhardwaj, Rajat Bhardwaj, and 1 others. 2024. Walledeval: A comprehensive safety evaluation toolkit for large language models. ArXiv preprint, abs/2408.03837. Danna Gurari, Qing Li, Abigale J. Stangl, Anhong Guo, Chi Lin, Kriste...
-
[10]
Lukas Helff, Felix Friedrich, Manuel Brack, Kristian Kersting, and Patrick Schramowski
Towards llm guardrails via sparse representa- tion steering.ArXiv preprint, abs/2503.16851. Lukas Helff, Felix Friedrich, Manuel Brack, Kristian Kersting, and Patrick Schramowski. 2024. Llava- guard: An open vlm-based framework for safeguard- ing vision datasets and models.ArXiv preprint, abs/2406.05113. Dan Hendrycks and Kevin Gimpel. 2017. A baseline fo...
-
[11]
A simple unified framework for detecting out- of-distribution samples and adversarial attacks. In Advances in Neural Information Processing Systems 31: Annual Conference on Neural Information Pro- cessing Systems 2018, NeurIPS 2018, December 3-8, 2018, Montréal, Canada, pages 7167–7177. Taegyeong Lee, Jeonghwa Yoo, Hyoungseo Cho, Soo Yong Kim, and Yunho M...
-
[12]
Fight back against jailbreaking via prompt ad- versarial tuning. InAdvances in Neural Information Processing Systems 38: Annual Conference on Neu- ral Information Processing Systems 2024, NeurIPS 2024, Vancouver, BC, Canada, December 10 - 15, 2024. Yi Nian, Shenzhe Zhu, Yuehan Qin, Li Li, Ziyi Wang, Chaowei Xiao, and Yue Zhao. 2025. Jaildam: Jail- break d...
-
[13]
Steering Llama 2 via Contrastive Activation Addition
Steering llama 2 via contrastive activation addition.ArXiv preprint, abs/2312.06681. Vladimir Pestov. 2013. Is the k-nn classifier in high dimensions affected by the curse of dimensional- ity?Computers & Mathematics with Applications, 65(10):1427–1437. Anirudh Phukan, Divyansh Divyansh, Harshit Kumar Morj, Vaishnavi Vaishnavi, Apoorv Saxena, and Koustava ...
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[14]
Great, Now Write an Article About That: The Crescendo Multi-Turn LLM Jailbreak Attack
Great, now write an article about that: The crescendo multi-turn llm jailbreak attack.ArXiv preprint, abs/2404.01833. Christian Schlarmann and Matthias Hein. 2023. On the adversarial robustness of multi-modal foundation models. InProceedings of the IEEE/CVF Interna- tional Conference on Computer Vision, pages 3677– 3685. Vikash Sehwag, Mung Chiang, and Pr...
work page internal anchor Pith review arXiv 2023
-
[15]
Jailbreak in pieces: Compositional adversar- ial attacks on multi-modal language models. InThe Twelfth International Conference on Learning Rep- resentations, ICLR 2024, Vienna, Austria, May 7-11,
work page 2024
-
[16]
OpenReview.net. Xinyue Shen, Zeyuan Chen, Michael Backes, Yun Shen, and Yang Zhang. 2024. " do anything now": Charac- terizing and evaluating in-the-wild jailbreak prompts on large language models. InProceedings of the 2024 on ACM SIGSAC Conference on Computer and Communications Security, pages 1671–1685. Amanpreet Singh, Ronghang Hu, Vedanuj Goswami, Gui...
work page 2024
-
[17]
Out-of-distribution detection with deep near- est neighbors. InInternational Conference on Ma- chine Learning, ICML 2022, 17-23 July 2022, Balti- more, Maryland, USA, volume 162 ofProceedings of Machine Learning Research, pages 20827–20840. PMLR. Rohan Taori, Ishaan Gulrajani, Tianyi Zhang, Yann Dubois, Xuechen Li, Carlos Guestrin, Percy Liang, and Tatsun...
-
[18]
Weiliang Zhao, Daniel Ben-Levi, Wei Hao, Junfeng Yang, and Chengzhi Mao
Defending large language models against jailbreak attacks via layer-specific editing.ArXiv preprint, abs/2405.18166. Weiliang Zhao, Daniel Ben-Levi, Wei Hao, Junfeng Yang, and Chengzhi Mao. 2025c. Diversity helps jailbreak large language models. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computationa...
-
[19]
On evaluating adversarial robustness of large vision-language models. InAdvances in Neural In- formation Processing Systems 36: Annual Confer- ence on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023. Chujie Zheng, Fan Yin, Hao Zhou, Fandong Meng, Jie Zhou, Kai-Wei Chang, Minlie Huang, and Nanyun Peng....
-
[20]
identified in Figure 10. For instance, Layer 17, selected by the “In-the-Wild” strategy, yields marginally higher AUROC than Layer 16. Table 14: Top 3 discriminative layers identified by each dataset setup. The identified layers consistently fall within the optimal “sweet spot” range (Layers 14–20). Experiment Top 3 Layers (Score) SGXSTest (Baseline) L16 ...
work page 2013
-
[21]
The framework is designed to be model-agnostic and can be deployed on top of existing LVLMs
follows the principles outlined in the original paper, creating a universal detection framework that identifies prompt-based attacks by analyzing the response consistency of a model to mutated inputs. The framework is designed to be model-agnostic and can be deployed on top of existing LVLMs. E.3.1 Detection Framework The core of JailGuard operates on the...
-
[22]
Input Mutation: For a given input prompt (either text-only or multimodal), JailGuard generates a set of N variants using a selected mutation strategy. By default,N= 8
-
[23]
These responses are collected for consistency analy- sis
Response Generation: Each of the N vari- ants is then passed to the target LVLM to ob- tain a corresponding set of responses. These responses are collected for consistency analy- sis
-
[24]
methods for analyzing the facial features of a person to predict their personality traits
Divergence-Based Detection: The semantic similarity between all pairs of responses is cal- culated using a pre-trained ‘en_core_web_md’ model from the spaCy library. These similari- ties are used to construct a similarity matrix, which is then converted into a divergence ma- trix using Kullback-Leibler (KL) divergence (Zhang et al., 2023). If the maximum ...
work page 2023
-
[25]
The CAPTCHA in the image reads ’takrth 1863’
The semantic embedding is dominated by this shared prefix, resulting inlow divergencebe- tween the refusal and the jail- break. JailGuard fails to detect the suffix difference. VizWiz Benign High Vari- ance Text:(Benign VQA request to read the blurry CAPTCHA) Response 1:“The CAPTCHA in the image reads ’takrth 1863’.” Response 2:“The captcha in the im- age...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.