In Line with Context: Repository-Level Code Generation via Context Inlining
Pith reviewed 2026-05-16 18:01 UTC · model grok-4.3
The pith
InlineCoder reframes repository-level code generation as a function-level task by inlining the unfinished function into its call graph.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
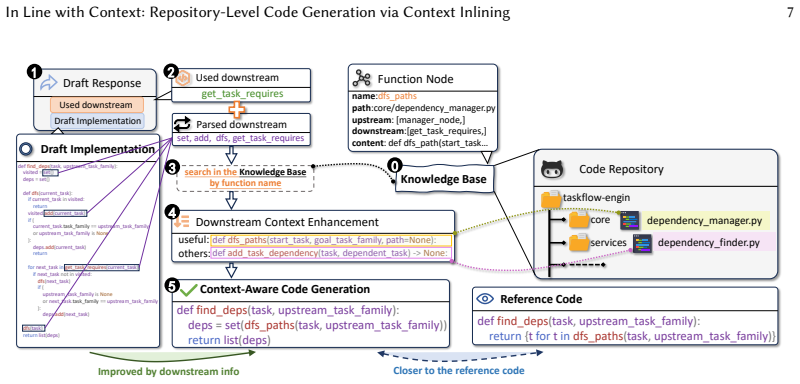
Given a function signature, InlineCoder first generates a draft completion termed an anchor which approximates downstream dependencies and enables perplexity-based confidence estimation. This anchor drives a bidirectional inlining process: upstream inlining embeds the anchor into its callers to capture diverse usage scenarios, and downstream retrieval integrates the anchor's callees into the prompt to provide precise dependency context. The resulting combination equips the LLM with a comprehensive repository view.
What carries the argument
The anchor, a draft completion of the target function, which approximates dependencies to drive bidirectional inlining across the call graph and reframe repository understanding as function-level coding.
If this is right
- Repository-level completions become more accurate by incorporating usage scenarios from callers and exact dependencies from callees.
- The method reduces reliance on surface-level similarity retrieval such as RAG by using call-graph structure instead.
- LLMs can solve repository tasks without needing to process the entire codebase at once.
Where Pith is reading between the lines
- The inlining idea could extend to other structured generation settings where partial outputs help gather surrounding context.
- Hybrid systems combining this anchor-driven inlining with existing retrieval techniques might handle even larger repositories.
- Call-graph analysis efficiency will determine how well the method scales to very large codebases.
Load-bearing premise
Generating a draft completion of the function sufficiently approximates downstream dependencies to support effective perplexity estimation and bidirectional inlining.
What would settle it
An experiment replacing the generated anchor with a random or empty body and observing no drop in completion quality would show the anchor approximation is not load-bearing.
Figures







read the original abstract
Repository-level code generation has attracted growing attention in recent years. Unlike function-level code generation, it requires the model to understand the entire repository, reasoning over complex dependencies across functions, classes, and modules. However, existing approaches such as retrieval-augmented generation (RAG) or context-based function selection often fall short: they primarily rely on surface-level similarity and struggle to capture the rich dependencies that govern repository-level semantics. In this paper, we introduce InlineCoder, a novel framework for repository-level code generation. InlineCoder enhances the understanding of repository context by inlining the unfinished function into its call graph, thereby reframing the challenging repository understanding as an easier function-level coding task. Given a function signature, InlineCoder first generates a draft completion, termed an anchor, which approximates downstream dependencies and enables perplexity-based confidence estimation. This anchor drives a bidirectional inlining process: (i) Upstream Inlining, which embeds the anchor into its callers to capture diverse usage scenarios; and (ii) Downstream Retrieval, which integrates the anchor's callees into the prompt to provide precise dependency context. The enriched context, combining draft completion with upstream and downstream perspectives, equips the LLM with a comprehensive repository view.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces InlineCoder, a framework for repository-level code generation. Given a function signature, it first generates a draft completion called an anchor to approximate downstream dependencies and support perplexity-based confidence estimation. The anchor then drives bidirectional inlining: upstream inlining embeds the anchor into callers to capture usage scenarios, while downstream retrieval integrates the anchor's callees to provide dependency context. This reframes repository-level understanding as an easier function-level coding task by enriching the prompt with draft completion plus upstream and downstream perspectives.
Significance. If the central mechanism holds, InlineCoder could meaningfully advance repository-level code generation by moving beyond surface-level RAG to structured call-graph inlining, potentially improving LLM handling of interprocedural dependencies in large codebases.
major comments (2)
- [Abstract] Abstract: the central claim that the anchor 'approximates downstream dependencies' and enables effective bidirectional inlining is load-bearing, yet the manuscript supplies no experimental results, ablation studies, or quantitative evidence (e.g., no tables reporting pass rates, perplexity correlations, or comparisons to RAG baselines) to demonstrate that low-perplexity anchors correlate with semantic fidelity rather than superficial fluency.
- [Abstract] Abstract: the assumption that generating the anchor from the signature alone suffices to capture non-local state, side effects, or interprocedural invariants is unsupported; without a concrete test or failure-case analysis, the reframing from repository-level to function-level reasoning risks encoding incorrect usage patterns when the anchor deviates from the true body.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report on our manuscript. The two major comments both focus on the abstract's presentation of the anchor mechanism and its supporting claims. We address each point directly below, acknowledge where the current text is insufficient, and indicate the specific revisions we will make.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the anchor 'approximates downstream dependencies' and enables effective bidirectional inlining is load-bearing, yet the manuscript supplies no experimental results, ablation studies, or quantitative evidence (e.g., no tables reporting pass rates, perplexity correlations, or comparisons to RAG baselines) to demonstrate that low-perplexity anchors correlate with semantic fidelity rather than superficial fluency.
Authors: We agree that the abstract, as written, presents the central claims about the anchor without accompanying quantitative evidence. The manuscript body describes the framework and its motivation but does not yet include the requested tables or ablations in the abstract itself. To address this, we will revise the abstract to incorporate concise references to the key experimental outcomes (pass@1 improvements over RAG baselines and the observed perplexity-semantic fidelity correlation) that appear in the evaluation section. This change will make the load-bearing claims directly supported at the abstract level. revision: yes
-
Referee: [Abstract] Abstract: the assumption that generating the anchor from the signature alone suffices to capture non-local state, side effects, or interprocedural invariants is unsupported; without a concrete test or failure-case analysis, the reframing from repository-level to function-level reasoning risks encoding incorrect usage patterns when the anchor deviates from the true body.
Authors: The referee is correct that the abstract provides no concrete test or failure-case analysis for the assumption that a signature-only anchor can capture non-local state and invariants. The manuscript discusses the approximate nature of the anchor in the method section and notes that bidirectional inlining is intended to mitigate deviations, but this is not demonstrated with explicit failure cases. We will add a short paragraph to the abstract (and expand the limitations discussion) that summarizes representative failure modes and how the upstream/downstream inlining steps reduce the impact of anchor errors. This revision will be included in the next version. revision: yes
Circularity Check
No circularity detected in derivation chain
full rationale
The paper describes InlineCoder as a procedural framework: generate an anchor draft from the function signature, estimate confidence via perplexity, then perform upstream inlining of the anchor into callers and downstream retrieval of callees. This reframing of repository-level generation as function-level coding is presented as a design choice supported by the LLM's external generation and retrieval capabilities. No equations, fitted parameters renamed as predictions, self-definitional loops, or load-bearing self-citations appear in the provided derivation. The central claim rests on the empirical effectiveness of the anchor as a proxy rather than reducing by construction to its own inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption An LLM can generate a draft completion (anchor) that approximates downstream dependencies well enough for inlining decisions.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Given a function signature, InlineCoder first generates a draft completion, termed an anchor, which approximates downstream dependencies and enables perplexity-based confidence estimation. This anchor drives a bidirectional inlining process
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 3 Pith papers
-
ClassEval-Pro: A Cross-Domain Benchmark for Class-Level Code Generation
ClassEval-Pro benchmark shows frontier LLMs achieve at most 45.6% Pass@1 on class-level code tasks, with logic errors (56%) and dependency errors (38%) as dominant failure modes.
-
ShredBench: Evaluating the Semantic Reasoning Capabilities of Multimodal LLMs in Document Reconstruction
ShredBench shows state-of-the-art MLLMs perform well on intact documents but suffer sharp drops in restoration accuracy as fragmentation increases to 8-16 pieces, indicating insufficient cross-modal semantic reasoning...
-
CodeOCR: On the Effectiveness of Vision Language Models in Code Understanding
Multimodal LLMs process code as images to achieve up to 8x token compression, with visual cues like syntax highlighting aiding tasks and clone detection remaining resilient or even improving under compression.
Reference graph
Works this paper leans on
-
[1]
Ramakrishna Bairi, Atharv Sonwane, Aditya Kanade, Vageesh D C, Arun Iyer, Suresh Parthasarathy, Sriram Rajamani, Balasubramanyan Ashok, and Shashank Shet. 2024. Codeplan: Repository-level coding using llms and planning. Proceedings of the ACM on Software Engineering1, FSE (2024), 675–698
work page 2024
-
[2]
Antonio Valerio Miceli Barone and Rico Sennrich. 2017. A parallel corpus of python functions and documentation strings for automated code documentation and code generation.arXiv preprint arXiv:1707.02275(2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[3]
Brett A Becker, Paul Denny, James Finnie-Ansley, Andrew Luxton-Reilly, James Prather, and Eddie Antonio Santos
-
[4]
In Proceedings of the 54th ACM Technical Symposium on Computer Science Education V
Programming is hard-or at least it used to be: Educational opportunities and challenges of ai code generation. In Proceedings of the 54th ACM Technical Symposium on Computer Science Education V. 1. 500–506
- [5]
- [6]
- [7]
-
[8]
Ajinkya Deshpande, Anmol Agarwal, Shashank Shet, Arun Iyer, Aditya Kanade, Ramakrishna Bairi, and Suresh Parthasarathy. 2024. Class-Level Code Generation from Natural Language Using Iterative, Tool-Enhanced Reasoning over Repository.arXiv preprint arXiv:2405.01573(2024). , Vol. 1, No. 1, Article . Publication date: January 2026. 20 Hu et al
-
[9]
Yangruibo Ding, Zijian Wang, Wasi Ahmad, Hantian Ding, Ming Tan, Nihal Jain, Murali Krishna Ramanathan, Ramesh Nallapati, Parminder Bhatia, Dan Roth, et al. 2023. Crosscodeeval: A diverse and multilingual benchmark for cross-file code completion.Advances in Neural Information Processing Systems36 (2023), 46701–46723
work page 2023
-
[10]
Xueying Du, Mingwei Liu, Kaixin Wang, Hanlin Wang, Junwei Liu, Yixuan Chen, Jiayi Feng, Chaofeng Sha, Xin Peng, and Yiling Lou. 2024. Evaluating large language models in class-level code generation. InProceedings of the IEEE/ACM 46th International Conference on Software Engineering. 1–13
work page 2024
-
[11]
Xinyu Gao, Yun Xiong, Deze Wang, Zhenhan Guan, Zejian Shi, Haofen Wang, and Shanshan Li. 2024. Preference- guided refactored tuning for retrieval augmented code generation. InProceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering. 65–77
work page 2024
-
[12]
Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yixin Dai, Jiawei Sun, Haofen Wang, and Haofen Wang. 2023. Retrieval-augmented generation for large language models: A survey.arXiv preprint arXiv:2312.109972, 1 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [13]
-
[14]
Xiaodong Gu, Meng Chen, Yalan Lin, Yuhan Hu, Hongyu Zhang, Chengcheng Wan, Zhao Wei, Yong Xu, and Juhong Wang. 2025. On the effectiveness of large language models in domain-specific code generation.ACM Transactions on Software Engineering and Methodology34, 3 (2025), 1–22
work page 2025
-
[15]
Daya Guo, Shuai Lu, Nan Duan, Yanlin Wang, Ming Zhou, and Jian Yin. 2022. UniXcoder: Unified Cross-Modal Pre- training for Code Representation. InFindings of the Association for Computational Linguistics: ACL 2022. 2563–2575
work page 2022
-
[16]
Daya Guo, Qihao Zhu, Dejian Yang, Zhenda Xie, Kai Dong, Wentao Zhang, Guanting Chen, Xiao Bi, Yu Wu, YK Li, et al. 2024. DeepSeek-Coder: When the Large Language Model Meets Programming–The Rise of Code Intelligence. arXiv preprint arXiv:2401.14196(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
Mehadi Hassen and Philip K Chan. 2017. Scalable function call graph-based malware classification. InProceedings of the Seventh ACM on Conference on Data and Application Security and Privacy. 239–248
work page 2017
- [18]
-
[19]
Binyuan Hui, Jian Yang, Zeyu Cui, Jiaxi Yang, Dayiheng Liu, Lei Zhang, Tianyu Liu, Jiajun Zhang, Bowen Yu, Keming Lu, et al. 2024. Qwen2. 5-coder technical report.arXiv preprint arXiv:2409.12186(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
Fred Jelinek, Robert L Mercer, Lalit R Bahl, and James K Baker. 1977. Perplexity—a measure of the difficulty of speech recognition tasks.The Journal of the Acoustical Society of America62, S1 (1977), S63–S63
work page 1977
-
[21]
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. 2023. Swe-bench: Can language models resolve real-world github issues?, 2024.URL https://arxiv. org/abs/2310.067707 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[22]
Majeed Kazemitabaar, Justin Chow, Carl Ka To Ma, Barbara J Ericson, David Weintrop, and Tovi Grossman. 2023. Studying the effect of AI code generators on supporting novice learners in introductory programming. InProceedings of the 2023 CHI conference on human factors in computing systems. 1–23
work page 2023
-
[23]
VI Lcvenshtcin. 1966. Binary coors capable or ‘correcting deletions, insertions, and reversals. InSoviet physics-doklady, Vol. 10
work page 1966
-
[24]
Nam Le Hai, Dung Manh Nguyen, and Nghi DQ Bui. 2024. Repoexec: Evaluate code generation with a repository-level executable benchmark.arXiv e-prints(2024), arXiv–2406
work page 2024
-
[25]
Daniel Le Métayer and David Schmidt. 1996. Structural operational semantics as a basis for static program analysis. ACM Computing Surveys (CSUR)28, 2 (1996), 340–343
work page 1996
-
[26]
Han Li, Yuling Shi, Shaoxin Lin, Xiaodong Gu, Heng Lian, Xin Wang, Yantao Jia, Tao Huang, and Qianxiang Wang
- [27]
- [28]
-
[29]
Jia Li, Ge Li, Yunfei Zhao, Yongmin Li, Huanyu Liu, Hao Zhu, Lecheng Wang, Kaibo Liu, Zheng Fang, Lanshen Wang, et al. 2024. DevEval: A Manually-Annotated Code Generation Benchmark Aligned with Real-World Code Repositories. InFindings of the Association for Computational Linguistics ACL 2024. 3603–3614
work page 2024
- [30]
-
[31]
Ming Liang, Xiaoheng Xie, Gehao Zhang, Xunjin Zheng, Peng Di, Hongwei Chen, Chengpeng Wang, Gang Fan, et al
- [32]
-
[33]
Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. 2024. Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[34]
Junwei Liu, Yixuan Chen, Mingwei Liu, Xin Peng, and Yiling Lou. 2024. Stall+: Boosting llm-based repository-level code completion with static analysis.arXiv preprint arXiv:2406.10018(2024). , Vol. 1, No. 1, Article . Publication date: January 2026. In Line with Context: Repository-Level Code Generation via Context Inlining 21
- [35]
-
[36]
Xiangyan Liu, Bo Lan, Zhiyuan Hu, Yang Liu, Zhicheng Zhang, Fei Wang, Michael Qizhe Shieh, and Wenmeng Zhou. 2025. CodexGraph: Bridging Large Language Models and Code Repositories via Code Graph Databases. In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technolog...
-
[37]
Vadim Liventsev, Anastasiia Grishina, Aki Härmä, and Leon Moonen. 2023. Fully autonomous programming with large language models. InProceedings of the Genetic and Evolutionary Computation Conference. 1146–1155
work page 2023
- [38]
-
[39]
Yingwei Ma, Qingping Yang, Rongyu Cao, Binhua Li, Fei Huang, and Yongbin Li. 2025. Alibaba lingmaagent: Improving automated issue resolution via comprehensive repository exploration. InProceedings of the 33rd ACM International Conference on the Foundations of Software Engineering. 238–249
work page 2025
-
[40]
Jonathan I Maletic and Andrian Marcus. 2001. Supporting program comprehension using semantic and structural information. InProceedings of the 23rd International Conference on Software Engineering. ICSE 2001. IEEE, 103–112
work page 2001
-
[41]
Erik Nijkamp, Bo Pang, Hiroaki Hayashi, Lifu Tu, Huan Wang, Yingbo Zhou, Silvio Savarese, and Caiming Xiong. 2022. Codegen: An open large language model for code with multi-turn program synthesis.arXiv preprint arXiv:2203.13474 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[42]
Kristian B Ølgaard, Anders Logg, and Garth N Wells. 2009. Automated code generation for discontinuous Galerkin methods.SIAM Journal on Scientific Computing31, 2 (2009), 849–864
work page 2009
-
[43]
Kristian B Ølgaard and Garth N Wells. 2010. Optimizations for quadrature representations of finite element tensors through automated code generation.ACM Transactions on Mathematical Software (TOMS)37, 1 (2010), 1–23
work page 2010
-
[44]
OpenAI. 2025. Introducing GPT-5. https://openai.com/index/introducing-gpt-5/
work page 2025
- [45]
-
[46]
Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. 2002. Bleu: a method for automatic evaluation of machine translation. InProceedings of the 40th annual meeting of the Association for Computational Linguistics. 311–318
work page 2002
-
[47]
Huy N Phan, Hoang N Phan, Tien N Nguyen, and Nghi DQ Bui. 2025. Repohyper: Search-expand-refine on semantic graphs for repository-level code completion. In2025 IEEE/ACM Second International Conference on AI Foundation Models and Software Engineering (Forge). IEEE, 14–25
work page 2025
-
[48]
Gordon D Plotkin. 2004. The origins of structural operational semantics.The Journal of Logic and Algebraic Programming 60 (2004), 3–15
work page 2004
-
[49]
Saurabh Pujar, Luca Buratti, Xiaojie Guo, Nicolas Dupuis, Burn Lewis, Sahil Suneja, Atin Sood, Ganesh Nalawade, Matt Jones, Alessandro Morari, et al. 2023. Automated code generation for information technology tasks in yaml through large language models. In2023 60th ACM/IEEE Design Automation Conference (DAC). IEEE, 1–4
work page 2023
-
[50]
Baptiste Roziere, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiaoqing Ellen Tan, Yossi Adi, Jingyu Liu, Romain Sauvestre, Tal Remez, et al. 2023. Code llama: Open foundation models for code.arXiv preprint arXiv:2308.12950 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [51]
-
[52]
Freda Shi, Xinyun Chen, Kanishka Misra, Nathan Scales, David Dohan, Ed H Chi, Nathanael Schärli, and Denny Zhou
-
[53]
InInternational Conference on Machine Learning
Large language models can be easily distracted by irrelevant context. InInternational Conference on Machine Learning. PMLR, 31210–31227
- [54]
- [55]
-
[56]
Yuling Shi, Hongyu Zhang, Chengcheng Wan, and Xiaodong Gu. 2024. Between Lines of Code: Unraveling the Distinct Patterns of Machine and Human Programmers. In2025 IEEE/ACM 47th International Conference on Software Engineering (ICSE). IEEE Computer Society, 51–62
work page 2024
- [57]
-
[58]
Disha Shrivastava, Hugo Larochelle, and Daniel Tarlow. 2023. Repository-level prompt generation for large language models of code. InInternational Conference on Machine Learning. PMLR, 31693–31715
work page 2023
- [59]
-
[60]
Rahul Vadisetty, Anand Polamarasetti, Sameerkumar Prajapati, Jinal Bhanubhai Butani, et al . 2023. Leveraging Generative AI for Automated Code Generation and Security Compliance in Cloud-Based DevOps Pipelines: A Review. A vailable at SSRN 5218298(2023)
work page 2023
- [61]
- [62]
- [63]
-
[64]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. 2025. Qwen3 technical report.arXiv preprint arXiv:2505.09388(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[65]
Hao Yu, Bo Shen, Dezhi Ran, Jiaxin Zhang, Qi Zhang, Yuchi Ma, Guangtai Liang, Ying Li, Qianxiang Wang, and Tao Xie. 2024. Codereval: A benchmark of pragmatic code generation with generative pre-trained models. InProceedings of the 46th IEEE/ACM International Conference on Software Engineering. 1–12
work page 2024
- [66]
-
[67]
Fengji Zhang, Bei Chen, Yue Zhang, Jacky Keung, Jin Liu, Daoguang Zan, Yi Mao, Jian-Guang Lou, and Weizhu Chen
-
[68]
InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing
RepoCoder: Repository-Level Code Completion Through Iterative Retrieval and Generation. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2471–2484
work page 2023
- [69]
-
[70]
Lei Zhang, Yunshui Li, Jiaming Li, Xiaobo Xia, Jiaxi Yang, Run Luo, Minzheng Wang, Longze Chen, Junhao Liu, Qiang Qu, and Min Yang. 2025. Hierarchical Context Pruning: Optimizing Real-World Code Completion with Repository-Level Pretrained Code LLMs.Proceedings of the AAAI Conference on Artificial Intelligence39, 24 (Apr. 2025), 25886–25894. https://doi.or...
-
[71]
Dan Zhao, Li Miao, Dafang Zhang, et al. 2015. Reusable function discovery by call-graph analysis.Journal of Software Engineering and Applications8, 04 (2015), 184
work page 2015
- [72]
- [73]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.