Recognition: unknown
ShredBench: Evaluating the Semantic Reasoning Capabilities of Multimodal LLMs in Document Reconstruction
Pith reviewed 2026-05-08 06:31 UTC · model grok-4.3
The pith
Current multimodal LLMs struggle to reconstruct documents from shredded fragments, with accuracy dropping sharply as fragmentation increases.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
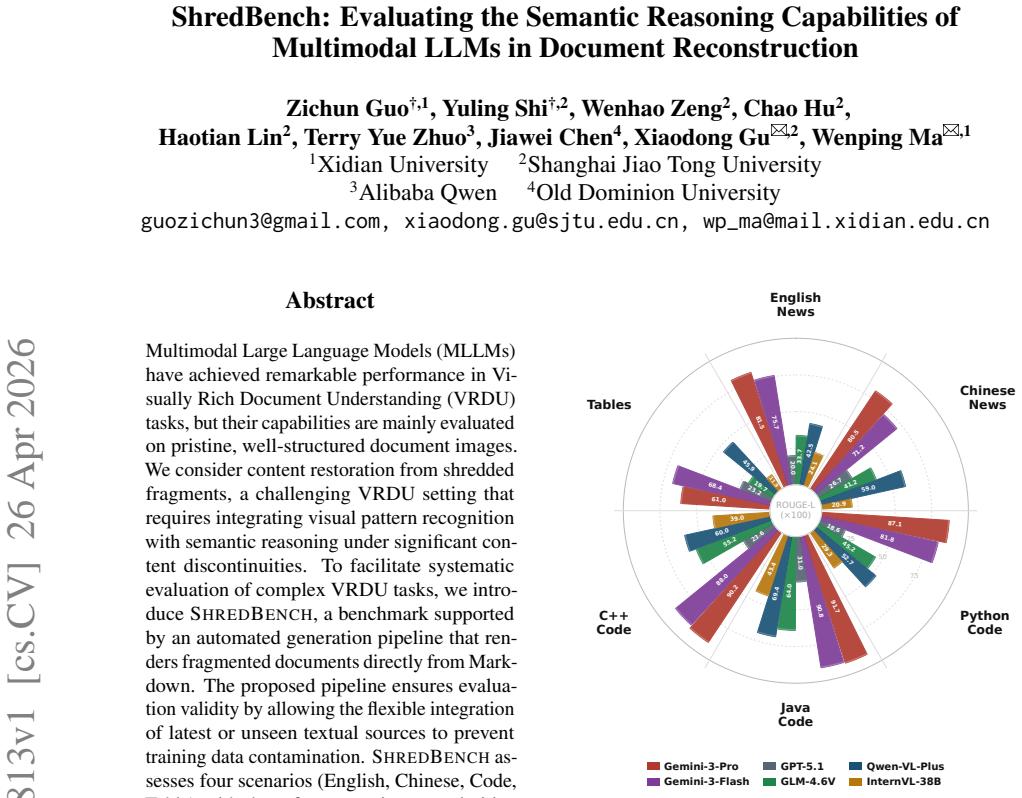
We introduce ShredBench, a benchmark supported by an automated generation pipeline that renders fragmented documents directly from Markdown. ShredBench assesses four scenarios (English, Chinese, Code, Table) with three fragmentation granularities (8, 12, 16 pieces). Empirical evaluations on state-of-the-art MLLMs reveal a significant performance gap: the method is effective on intact documents; however, once the document is shredded, restoration becomes a significant challenge, with NED dropping sharply as fragmentation increases. Our findings highlight that current MLLMs lack the fine-grained cross-modal reasoning required to bridge visual discontinuities.
What carries the argument
ShredBench benchmark with its automated pipeline that renders fragmented documents from Markdown sources, enabling contamination-free evaluation across scenarios and fragmentation levels.
If this is right
- MLLMs achieve adequate results on intact documents but encounter major restoration challenges with shredded versions.
- Normalized edit distance falls sharply as the number of fragments rises from 8 to 16 pieces.
- The Markdown-based pipeline supports evaluation with fresh textual sources to avoid training data contamination.
- Current MLLMs lack the fine-grained cross-modal reasoning needed to handle visual discontinuities in documents.
Where Pith is reading between the lines
- Model training regimes could add simulated shredding tasks to build better handling of partial inputs.
- Direct comparisons between synthetic shreds and physical shreds would clarify how well the benchmark matches real conditions.
- Document processing tools in archives or forensics might need extra steps to handle fragmentation until reasoning improves.
- Similar evaluation pipelines could apply to other types of document damage or multimodal discontinuities.
Load-bearing premise
The synthetic fragments generated automatically from Markdown accurately represent the visual and semantic challenges of real-world shredded documents.
What would settle it
Measuring normalized edit distance for the same MLLMs on a collection of physically shredded real paper documents prepared to match the benchmark's scenarios and fragment counts.
Figures




read the original abstract
Multimodal Large Language Models (MLLMs) have achieved remarkable performance in Visually Rich Document Understanding (VRDU) tasks, but their capabilities are mainly evaluated on pristine, well-structured document images. We consider content restoration from shredded fragments, a challenging VRDU setting that requires integrating visual pattern recognition with semantic reasoning under significant content discontinuities. To facilitate systematic evaluation of complex VRDU tasks, we introduce ShredBench, a benchmark supported by an automated generation pipeline that renders fragmented documents directly from Markdown. The proposed pipeline ensures evaluation validity by allowing the flexible integration of latest or unseen textual sources to prevent training data contamination. ShredBench assesses four scenarios (English, Chinese, Code, Table) with three fragmentation granularities (8, 12, 16 pieces). Empirical evaluations on state-of-the-art MLLMs reveal a significant performance gap: The method is effective on intact documents; however, once the document is shredded, restoration becomes a significant challenge, with NED dropping sharply as fragmentation increases. Our findings highlight that current MLLMs lack the fine-grained cross-modal reasoning required to bridge visual discontinuities, identifying a critical gap in robust VRDU research.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ShredBench, a benchmark for evaluating multimodal LLMs on semantic reasoning for document reconstruction from shredded fragments. It features an automated pipeline that renders fragmented documents directly from Markdown sources across four scenarios (English, Chinese, Code, Table) and three fragmentation levels (8, 12, 16 pieces). The central empirical claim is that state-of-the-art MLLMs perform adequately on intact documents but exhibit sharp drops in Normalized Edit Distance (NED) as fragmentation increases, indicating a lack of fine-grained cross-modal reasoning to bridge visual discontinuities.
Significance. If the observed performance degradation can be rigorously attributed to reasoning deficits rather than pipeline artifacts, ShredBench would offer a valuable, contamination-resistant tool for probing limitations in current MLLMs for visually rich document understanding tasks involving discontinuities. The automated Markdown-based generation pipeline is a clear strength, enabling flexible, up-to-date textual sources without training data leakage.
major comments (2)
- [§4] §4 (Empirical Evaluations): The abstract and evaluation description report clear NED drops with increasing fragmentation but provide no specifics on the exact MLLMs tested, the NED computation formula or implementation, statistical controls, variance across runs, or any baseline comparisons (e.g., OCR-only or non-MLLM methods), which are load-bearing for substantiating the 'significant performance gap' and attribution to cross-modal reasoning failures.
- [§3] §3 (Benchmark Generation Pipeline): The synthetic rectangular fragments generated from Markdown may confound the central claim, as performance degradation could stem from rendering artifacts, multi-fragment prompting/tokenization effects, or layout/OCR degradation on smaller pieces rather than purely semantic integration failures; no ablation or validation (e.g., comparison to real shredded documents or controlled irregularity tests) is described to isolate the intended capability.
minor comments (2)
- [Abstract] Abstract: The qualitative description of 'NED dropping sharply' would be strengthened by including at least one key quantitative example or range of observed values to convey effect size.
- [§4] The manuscript would benefit from explicit discussion of prompt engineering details for multi-fragment inputs and any failure mode analysis (e.g., cases where visual continuity is preserved but semantics fail).
Simulated Author's Rebuttal
We thank the referee for their constructive comments on our paper introducing ShredBench. We address each major comment point-by-point below, agreeing where revisions are needed to enhance clarity and rigor.
read point-by-point responses
-
Referee: [§4] §4 (Empirical Evaluations): The abstract and evaluation description report clear NED drops with increasing fragmentation but provide no specifics on the exact MLLMs tested, the NED computation formula or implementation, statistical controls, variance across runs, or any baseline comparisons (e.g., OCR-only or non-MLLM methods), which are load-bearing for substantiating the 'significant performance gap' and attribution to cross-modal reasoning failures.
Authors: We agree that the manuscript would benefit from more detailed reporting on the experimental setup. In the revised version, we will expand §4 to explicitly list the state-of-the-art MLLMs evaluated (including model names, versions, and access methods), provide the exact formula and code reference for Normalized Edit Distance (NED), report mean NED with standard deviations across multiple prompt runs or seeds, and include baseline comparisons such as OCR followed by text reconstruction and traditional non-MLLM document reconstruction methods. These additions will strengthen the substantiation of our claims regarding the performance gap and its link to cross-modal reasoning deficits. revision: yes
-
Referee: [§3] §3 (Benchmark Generation Pipeline): The synthetic rectangular fragments generated from Markdown may confound the central claim, as performance degradation could stem from rendering artifacts, multi-fragment prompting/tokenization effects, or layout/OCR degradation on smaller pieces rather than purely semantic integration failures; no ablation or validation (e.g., comparison to real shredded documents or controlled irregularity tests) is described to isolate the intended capability.
Authors: We appreciate this valid concern regarding potential confounds in our synthetic pipeline. While the rectangular fragments and Markdown rendering are chosen to enable scalable, contamination-free evaluation, we acknowledge that additional validation is warranted. In the revision, we will add a dedicated subsection in §3 discussing possible artifacts (e.g., tokenization effects) and include an ablation study on fragment shape irregularity. We will also report preliminary comparisons with a limited set of real-world shredded document images to support the generalizability of our findings. This will help isolate the semantic reasoning aspect more rigorously. revision: partial
Circularity Check
No circularity: new benchmark with direct empirical evaluation on external models
full rationale
The paper introduces ShredBench as a novel benchmark with an automated Markdown-to-fragment pipeline and reports direct performance measurements (NED) of existing state-of-the-art MLLMs on intact vs. shredded documents across fixed scenarios. No equations, parameter fitting, self-citations, or ansatzes are invoked to derive the central claim; the performance gap is presented as an observed empirical outcome on external models and the newly generated test cases. The derivation chain is therefore self-contained and falsifiable against the released benchmark data.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Document reconstruction from shredded fragments requires integration of visual pattern recognition with semantic reasoning under content discontinuities
invented entities (1)
-
ShredBench
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
Qwen-vl: A fron- tier of large multimodal models.arXiv preprint arXiv:2308.12966. Lukas Blecher, Guillem Cucurull, Thomas Scialom, and Robert Stojnic
work page internal anchor Pith review arXiv
-
[2]
arXiv preprint arXiv:2308.13418 , year=
Nougat: Neural optical un- derstanding for academic documents.arXiv preprint arXiv:2308.13418. Wei Chen, Liangmin Wu, Yunhai Hu, Zhiyuan Li, Zhiyuan Cheng, Yicheng Qian, Lingyue Zhu, Zhipeng Hu, Luoyi Liang, Qiang Tang, Zhen Liu, and Han Yang. 2025a. Autoneural: Co-designing vision-language models for npu inference.Preprint, arXiv:2512.02924. Xiaoyue Chen...
-
[3]
Enhancing financial report question- answering: A retrieval-augmented generation system with reranking analysis.Preprint, arXiv:2603.16877. Yew Ken Chia, Liying Cheng, Hou Pong Chan, Chao- qun Liu, Maojia Song, Sharifah Mahani Aljunied, Soujanya Poria, and Lidong Bing
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
M-longdoc: A benchmark for multimodal super-long document understanding and a retrieval-aware tuning frame- work.arXiv preprint arXiv:2411.06176. Jacob Cohen
-
[5]
arXiv preprint arXiv:2601.13024
Tears or cheers? benchmarking llms via culturally elicited distinct affective responses. arXiv preprint arXiv:2601.13024. Yongkun Du, Pinxuan Chen, Xuye Ying, and Zhineng Chen
-
[6]
arXiv preprint arXiv:2511.18434 , year=
Docptbench: Benchmarking end-to- end photographed document parsing and translation. arXiv preprint arXiv:2511.18434. Team GLM, Aohan Zeng, Bin Xu, Bowen Wang, Chen- hui Zhang, Da Yin, and 1 others
-
[7]
ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools
Glm- 4: Towards intelligent chat agents.arXiv preprint arXiv:2406.12793. Google DeepMind
work page internal anchor Pith review arXiv
-
[8]
https://deepmind.google/models/ gemini/pro/
Gemini: Most capable AI models. https://deepmind.google/models/ gemini/pro/. Accessed: 2026-01-04. Tianrui Guan, Fuxiao Liu, Xiyang Wu, Ruiqi Xian, Zongxia Li, Xiaoyu Liu, Xijun Wang, Lijie Chen, Furong Furrer, Yabo Dou, and 1 others
2026
-
[9]
In Line with Context: Repository-Level Code Generation via Context Inlining
In line with context: Repository- level code generation via context inlining.arXiv preprint arXiv:2601.00376. Jinpeng Hu, Hongchang Shi, Chongyuan Dai, Zhuo Li, Peipei Song, and Meng Wang
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
InFindings of the Associa- tion for Computational Linguistics: ACL 2025, pages 6033–6056
Mcbe: A multi-task chinese bias evaluation benchmark for large language models. InFindings of the Associa- tion for Computational Linguistics: ACL 2025, pages 6033–6056. Kenton Lee, Mandar Joshi, Iulia Turc, Hexiang Hu, Fangyu Liu, Julian Eisenschlos, Urvashi Khandel- wal, Ming-Wei Shaw, Peter andchang, and Kristina Toutanova
2025
-
[11]
SEED-Bench: Benchmarking Multimodal LLMs with Generative Comprehension
Binary codes capable of correcting deletions, insertions, and reversals.Soviet physics doklady, 10(8):707–710. Bohao Li, Rui Wang, Guangzhi Wang, Yuying Ge, Yix- iao Ge, and Ying Shan. 2023a. Seed-bench: Bench- marking multimodal llms with generative compre- hension.arXiv preprint arXiv:2307.16125. Jiang Li, Tian Lan, Shanshan Wang, Dongxing Zhang, Dianqi...
work page internal anchor Pith review arXiv
-
[12]
Who Wrote This Line? Evaluating the Detection of LLM-Generated Classical Chinese Poetry
Who wrote this line? evaluat- ing the detection of llm-generated classical chinese poetry.arXiv preprint arXiv:2604.10101. Yifan Li, Yifan Du, Kun Zhou, Jinpeng Wang, Wayne Xin Zhao, and Ji-Rong Wen. 2023b. Eval- uating object hallucination in large vision-language models. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Proce...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[13]
MMBench: Is Your Multi-modal Model an All-around Player?
Rouge: A package for automatic evaluation of summaries. InText summarization branches out, pages 74–81. Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. 2023a. Visual instruction tuning. InNeurIPS. Yuan Liu, Haodong Duan, Yuanhan Zhang, Bo Li, Chi Zhang, Wattanit Zhao, and 1 others. 2023b. Mm- bench: Is your multi-modal model an all-around player?...
work page internal anchor Pith review arXiv
-
[14]
Kosmos-2.5: A multimodal liter- ate model
Kosmos-2.5: A multimodal literate model.arXiv preprint arXiv:2309.11419. Zesen Lyu, Dandan Zhang, Wei Ye, Fangdi Li, Zhi- hang Jiang, and Yao Yang
-
[15]
Ahmed Masry, Xuan Do, Joty Tan, Shafiq Joty, and Enamul Hoque
Jigsaw-puzzles: From seeing to understanding to reasoning in vision- language models.arXiv preprint arXiv:2505.20728. Ahmed Masry, Xuan Do, Joty Tan, Shafiq Joty, and Enamul Hoque
-
[16]
https://openai
Introducing GPT-5. https://openai. com/zh-Hans-CN/index/introducing-gpt-5/ . Accessed: 2026-01-04. Linke Ouyang, Yuan Qu, Hongbin Zhou, Jiawei Zhu, Rui Zhang, Qunshu Lin, Bin Wang, Zhiyuan Zhao, Man Jiang, Xiaomeng Zhao, Jin Shi, Fan Wu, Pei Chu, Minghao Liu, Zhenxiang Li, Chao Xu, Bo Zhang, Botian Shi, Zhongying Tu, and Conghui He
2026
-
[17]
SWE-QA: Can Language Models Answer Repository-level Code Questions?
Swe-qa: Can language models answer repository-level code ques- tions?arXiv preprint arXiv:2509.14635. Xinkuan Qiu, Meina Kan, Yongbin Zhou, and Shiguang Shan
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Yuling Shi, Songsong Wang, Chengcheng Wan, Min Wang, and Xiaodong Gu
Longcodezip: Compress long context for code language models.arXiv preprint arXiv:2510.00446. Yuling Shi, Songsong Wang, Chengcheng Wan, Min Wang, and Xiaodong Gu. 2024a. From code to correctness: Closing the last mile of code gener- ation with hierarchical debugging.arXiv preprint arXiv:2410.01215. Yuling Shi, Chaoxiang Xie, Zhensu Sun, Yeheng Chen, Chenx...
-
[19]
CodeOCR: On the Effectiveness of Vision Language Models in Code Understanding
Codeocr: On the effectiveness of vision lan- guage models in code understanding.arXiv preprint arXiv:2602.01785. Yuling Shi, Hongyu Zhang, Chengcheng Wan, and Xi- aodong Gu. 2024b. Between lines of code: Unravel- ing the distinct patterns of machine and human pro- grammers. In2025 IEEE/ACM 47th International Conference on Software Engineering (ICSE), page...
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Jiang, Andy Lo, Gabrielle Berrada, Guillaume Lample, et al
Unifying vision, text, and layout for universal document processing. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 19254– 19264. Mistral AI Team. 2025a. Magistral: A multimodal reasoning framework for transparent logic.arXiv preprint arXiv:2506.10910. Tencent Hunyuan Vision Team. 2025b. Hunyuanocr tech...
-
[21]
Con- ceptual and Theoretical Foundations.Psychological Bulletin, 138(6):1218–1252
A Century of Gestalt Psychology in Visual Perception II. Con- ceptual and Theoretical Foundations.Psychological Bulletin, 138(6):1218–1252. An-Lan Wang, Jingqun Tang, Liao Lei, Hao Feng, Qi Liu, Xiang Fei, Jinghui Lu, Han Wang, Wei- wei Liu, Hao Liu, Yuliang Liu, Xiang Bai, and Can Huang. 2025a. Wilddoc: How far are we from achiev- ing comprehensive and r...
-
[22]
Effiskill: Agent skill based automated code efficiency optimization.arXiv preprint arXiv:2603.27850. Haoran Wei and 1 others
-
[23]
Vary: Scaling up the vision vocab- ulary for large vision-language models
Vary: Scaling up the vision vocabulary for large vision-language models. arXiv preprint arXiv:2312.06109. Zhiyu Wu and 1 others
-
[24]
DeepSeek-VL2: Mixture-of-Experts Vision-Language Models for Advanced Multimodal Understanding
Deepseek-vl2: Mixture-of-experts vision-language models for ad- vanced multimodal understanding.arXiv preprint arXiv:2412.10302. Shukang Yin, Chaoyou Fu, Sirui Zhao, Ke Li, Xing Sun, Tong Xu, and Enhong Chen
work page internal anchor Pith review arXiv
-
[25]
arXiv preprint arXiv:2306.13549 , year=
A survey on multimodal large language models.arXiv preprint arXiv:2306.13549. Updated version in
-
[26]
Wenhao Zeng, Yaoning Wang, Chao Hu, Yuling Shi, Chengcheng Wan, Hongyu Zhang, and Xiaodong Gu
Readability- robust code summarization via meta curriculum learn- ing.arXiv preprint arXiv:2601.05485. Wenhao Zeng, Yaoning Wang, Chao Hu, Yuling Shi, Chengcheng Wan, Hongyu Zhang, and Xiaodong Gu
-
[27]
Pruning the unsurprising: Efficient code reasoning via first-token surprisal.arXiv preprint arXiv:2508.05988. Jinxu Zhang
-
[28]
Read and Think: An Efficient Step-wise Multimodal Language Model for Docu- ment Understanding and Reasoning.arXiv preprint arXiv:2403.00816. Tianshu Zhang, Xiang Yue, Yifei Li, Hunar Batra, Shangmin Guo, Shiyu Chen, Linbin Wang, Semih Yavuz, Richard Yan, Xinyu Zhang, and Tao Yu
-
[29]
InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics (NAACL)
Tablellama: Towards open large generalist models for tables. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics (NAACL). Xu Zhong, Elaheh Shafieibavani, and Antonio Ji- meno Yepes
2024
-
[30]
InComputer Vision– ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XII 16, pages 564–580
Image-based table recognition: data, model, and evaluation. InComputer Vision– ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XII 16, pages 564–580. Springer. Rixin Zhou, Ding Xia, Yi Zhang, Honglin Pang, Xi Yang, and Chuntao Li
2020
-
[31]
Pairingnet: A learning-based pair-searching and -matching network for image fragments.arXiv preprint arXiv:2312.08704. A Additional Evaluation: Metric Suitability for Code Restoration While standard string-matching metrics (such as NED, BLEU, and ROUGE) offer a robust general measure of text similarity, they may over-penalize benign formatting variations ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.