Sonar-TS: Search-Then-Verify Natural Language Querying for Time Series Databases
Pith reviewed 2026-05-21 12:07 UTC · model grok-4.3
The pith
Sonar-TS retrieves time series events by first searching candidates with SQL then verifying them with generated Python programs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
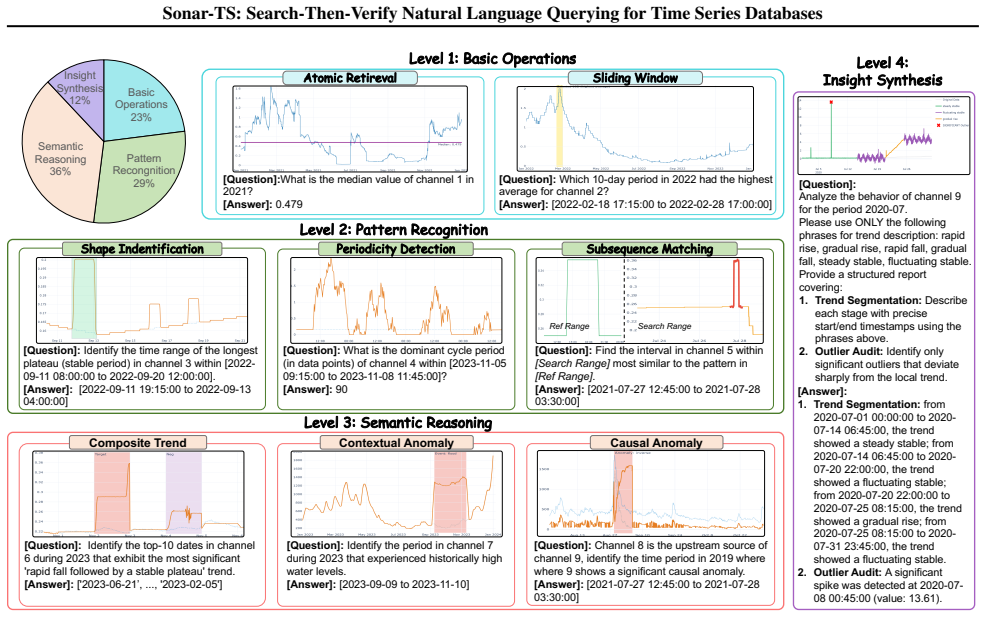
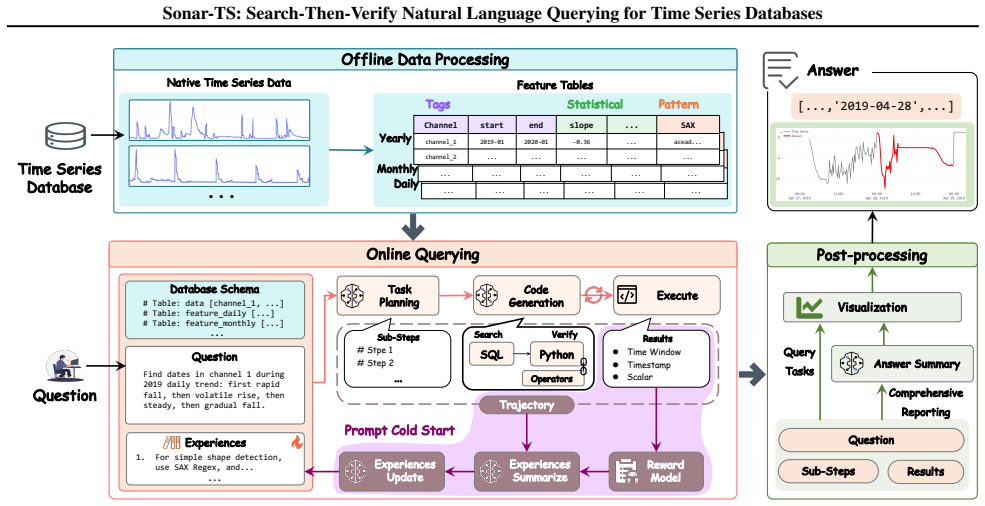
Sonar-TS is a neuro-symbolic framework for natural language querying over time series databases that follows a Search-Then-Verify pipeline: a feature index first pings candidate windows via SQL, after which generated Python programs lock onto and verify those candidates against the raw signals, evaluated on the new NLQTSBench benchmark.
What carries the argument
Search-Then-Verify pipeline that combines SQL-based candidate retrieval from a feature index with generated Python program verification for morphological intents such as shapes or anomalies.
If this is right
- Non-experts can extract specific temporal events from massive records without writing queries or code.
- Queries about shapes, anomalies, and other morphological features become practical on histories too long for direct processing.
- NLQTSBench supplies a common testbed for measuring progress on natural language time series retrieval.
- The hybrid SQL-plus-code design scales verification cost with the number of candidates rather than the full data length.
Where Pith is reading between the lines
- The same two-stage pattern could be adapted to natural language queries over other ordered data such as video frames or sensor streams.
- Stronger code-generation models would directly raise verification accuracy on edge-case patterns.
- Better feature indexes could shrink the set of candidates passed to the Python stage and lower overall latency.
Load-bearing premise
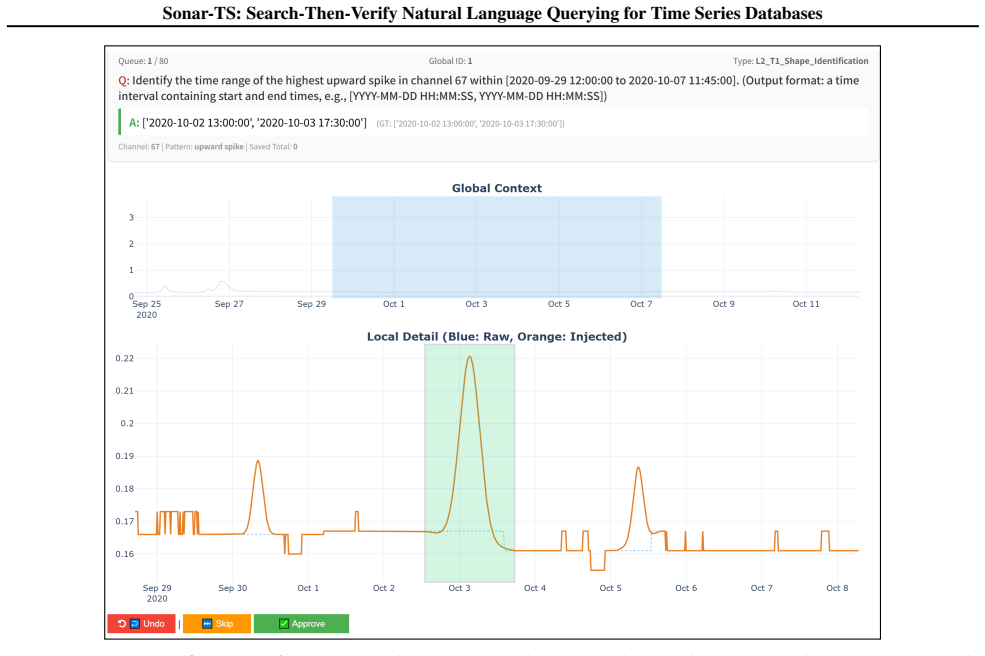
The Python programs generated on the fly will correctly decide whether each candidate window matches the user's intended continuous pattern even when the full history is extremely long.
What would settle it
A test set from NLQTSBench in which the generated verification programs systematically accept windows that lack the queried shape or anomaly, or reject windows that contain it.
Figures



read the original abstract
Natural Language Querying for Time Series Databases (NLQ4TSDB) aims to assist non-expert users retrieve meaningful events, intervals, and summaries from massive temporal records. However, existing Text-to-SQL methods are not designed for continuous morphological intents such as shapes or anomalies, while time series models struggle to handle ultra-long histories. To address these challenges, we propose Sonar-TS, a neuro-symbolic framework that tackles NLQ4TSDB via a Search-Then-Verify pipeline. Analogous to active sonar, it utilizes a feature index to ping candidate windows via SQL, followed by generated Python programs to lock on and verify candidates against raw signals. To enable effective evaluation, we introduce NLQTSBench, the first large-scale benchmark designed for NLQ over TSDB-scale histories. Our experiments highlight the unique challenges within this domain and demonstrate that Sonar-TS effectively navigates complex temporal queries where traditional methods fail. This work presents the first systematic study of NLQ4TSDB, offering a general framework and evaluation standard to facilitate future research.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Sonar-TS, a neuro-symbolic Search-Then-Verify framework for natural language querying over time series databases (NLQ4TSDB). It first applies SQL queries against a feature index to retrieve candidate windows, then uses LLM-generated Python programs to verify those candidates against raw signals for complex morphological intents such as shapes and anomalies. The paper presents NLQTSBench as a new large-scale benchmark and states that experiments demonstrate Sonar-TS successfully handles queries where traditional Text-to-SQL and time-series methods fail, positioning the work as the first systematic study of NLQ4TSDB.
Significance. If the verify stage is shown to scale reliably, Sonar-TS could meaningfully advance accessible querying of massive temporal datasets by non-experts. The introduction of NLQTSBench supplies a concrete evaluation standard that future work can build upon.
major comments (2)
- [Abstract] Abstract: the statement that 'experiments demonstrate effectiveness' and that Sonar-TS 'effectively navigates complex temporal queries where traditional methods fail' is unsupported by any quantitative metrics, error rates, runtime figures, or analysis of the verification programs, leaving the central claim without visible evidence.
- [Verification stage description] Verification component: the claim that LLM-generated Python programs reliably 'lock on' to shapes, anomalies, and other continuous patterns on ultra-long histories is load-bearing for the neuro-symbolic pipeline, yet no success rates, false-negative analysis, or scalability results on raw signals are reported.
minor comments (1)
- [Abstract] Abstract: consider adding one concrete example query and its expected output to illustrate the morphological intents that defeat pure Text-to-SQL approaches.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback on our manuscript. We address the major comments point by point below, agreeing where additional quantitative support is warranted and outlining the revisions we will make.
read point-by-point responses
-
Referee: [Abstract] Abstract: the statement that 'experiments demonstrate effectiveness' and that Sonar-TS 'effectively navigates complex temporal queries where traditional methods fail' is unsupported by any quantitative metrics, error rates, runtime figures, or analysis of the verification programs, leaving the central claim without visible evidence.
Authors: We agree that the abstract would benefit from explicit quantitative support to ground the claims. The full manuscript (Section 5) reports precision/recall metrics, runtime comparisons against Text-to-SQL and time-series baselines, and overall success rates on NLQTSBench, showing Sonar-TS outperforming alternatives on morphological queries. We will revise the abstract to include key figures (e.g., accuracy improvements and failure modes of baselines) while preserving brevity. revision: yes
-
Referee: [Verification stage description] Verification component: the claim that LLM-generated Python programs reliably 'lock on' to shapes, anomalies, and other continuous patterns on ultra-long histories is load-bearing for the neuro-symbolic pipeline, yet no success rates, false-negative analysis, or scalability results on raw signals are reported.
Authors: We acknowledge that dedicated metrics for the verification stage would strengthen the neuro-symbolic claims. While overall pipeline results are presented, we will add a new subsection in the experiments (or appendix) reporting success rates of the LLM-generated verification programs, false-negative analysis on shape/anomaly detection, and scalability tests across varying history lengths on raw signals. revision: yes
Circularity Check
Sonar-TS introduces a new neuro-symbolic Search-Then-Verify framework with no circular derivation
full rationale
The paper proposes Sonar-TS as an original construction: a feature-index SQL search stage followed by LLM-generated Python verification programs on raw signals. No equations, fitted parameters, or predictions appear. The central claims rest on the empirical performance of this pipeline on the newly introduced NLQTSBench benchmark rather than on any self-referential definitions, self-citation chains, or renamings of prior results. The derivation is therefore self-contained and non-circular.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Existing Text-to-SQL methods cannot handle continuous morphological intents such as shapes or anomalies.
- domain assumption Time series models cannot scale to ultra-long histories.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.