PaveBench: A Versatile Benchmark for Pavement Distress Perception and Interactive Vision-Language Analysis
Pith reviewed 2026-05-13 19:39 UTC · model grok-4.3
The pith
PaveBench introduces a unified benchmark for pavement distress analysis that combines visual recognition tasks with interactive vision-language question answering on real highway images.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
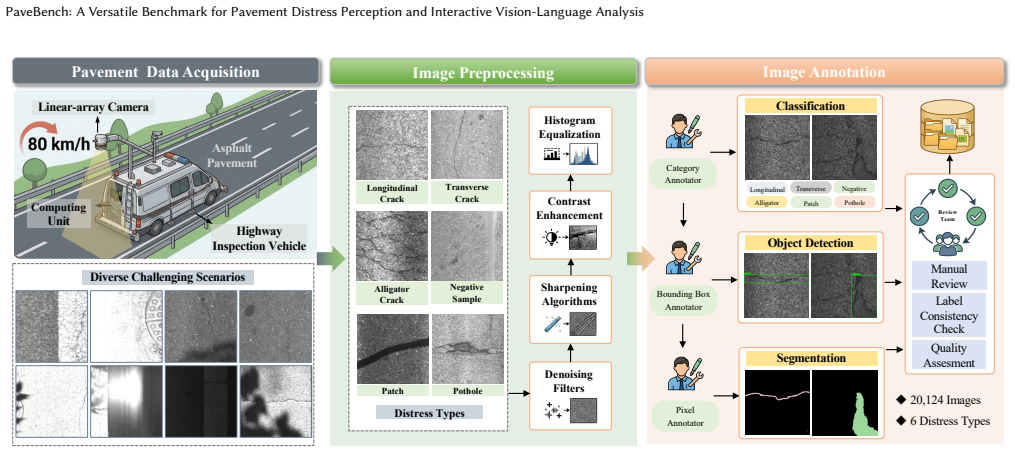
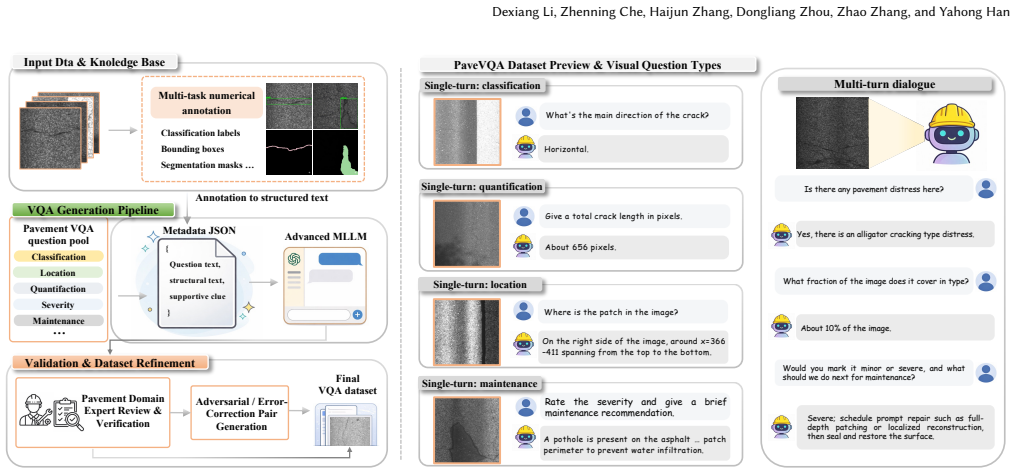
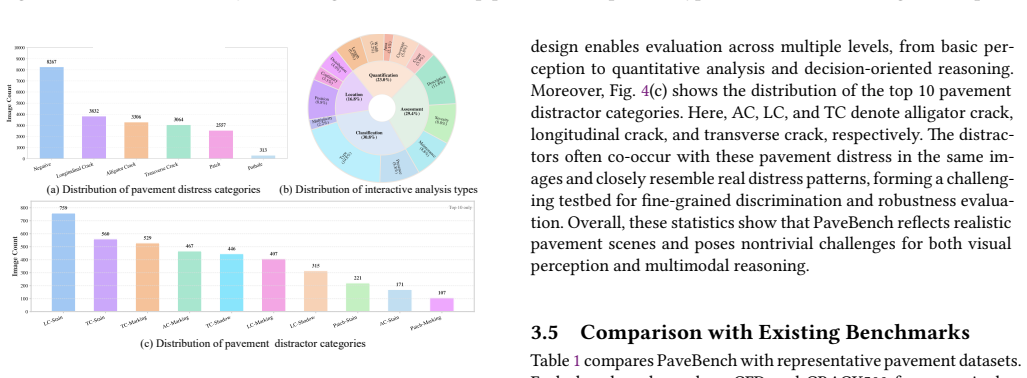
PaveBench is a large-scale benchmark for pavement distress perception and interactive vision-language analysis on real-world highway inspection images that supports classification, object detection, semantic segmentation, and vision-language question answering through unified task definitions, large-scale annotations, a hard-distractor subset, and the PaveVQA dataset for single-turn, multi-turn, and expert-corrected interactions covering recognition, localization, quantitative estimation, and maintenance reasoning.
What carries the argument
PaveBench benchmark together with its PaveVQA component, which supplies unified annotations and evaluation protocols across four tasks on real pavement images plus a hard-distractor subset for robustness testing.
If this is right
- Unified task definitions and protocols enable direct comparison of models across perception and multimodal reasoning on the same data.
- The hard-distractor subset provides a concrete way to measure robustness when models encounter difficult pavement cases.
- PaveVQA's support for multi-turn and expert-corrected interactions allows evaluation of systems that handle realistic inspection dialogues.
- The agent-augmented framework demonstrates one way to improve quantitative estimation and maintenance reasoning by routing queries to domain tools.
- Public release of the dataset on a common platform makes it possible for other researchers to test new methods against the same baseline.
Where Pith is reading between the lines
- Inspection systems built on this benchmark could eventually output maintenance recommendations that inspectors can verify in the field.
- The same multimodal structure might be adapted to other infrastructure domains such as bridge or tunnel inspection.
- Wider community use of the released dataset could surface additional edge cases that improve annotation quality over time.
- If the multi-turn interactions capture expert reasoning patterns, models trained here may transfer more readily to live highway monitoring.
Load-bearing premise
The curated annotations, hard-distractor examples, and question-answer pairs in PaveBench and PaveVQA are accurate, representative of real highway conditions, and free of systematic labeling errors that would distort model evaluations.
What would settle it
A follow-up study that collects new unlabeled highway images from different regions or seasons and shows that models ranked highly on PaveBench perform poorly on those images would indicate the benchmark does not capture real-world variability.
Figures

read the original abstract
Pavement condition assessment is essential for road safety and maintenance. Existing research has made significant progress. However, most studies focus on conventional computer vision tasks such as classification, detection, and segmentation. In real-world applications, pavement inspection requires more than visual recognition. It also requires quantitative analysis, explanation, and interactive decision support. Current datasets are limited. They focus on unimodal perception. They lack support for multi-turn interaction and fact-grounded reasoning. They also do not connect perception with vision-language analysis. To address these limitations, we introduce PaveBench, a large-scale benchmark for pavement distress perception and interactive vision-language analysis on real-world highway inspection images. PaveBench supports four core tasks: classification, object detection, semantic segmentation, and vision-language question answering. It provides unified task definitions and evaluation protocols. On the visual side, PaveBench provides large-scale annotations and includes a curated hard-distractor subset for robustness evaluation. It contains a large collection of real-world pavement images. On the multimodal side, we introduce PaveVQA, a real-image question answering (QA) dataset that supports single-turn, multi-turn, and expert-corrected interactions. It covers recognition, localization, quantitative estimation, and maintenance reasoning. We evaluate several state-of-the-art methods and provide a detailed analysis. We also present a simple and effective agent-augmented visual question answering framework that integrates domain-specific models as tools alongside vision-language models. The dataset is available at: https://huggingface.co/datasets/MML-Group/PaveBench.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PaveBench, a large-scale benchmark for pavement distress perception and interactive vision-language analysis on real-world highway inspection images. It supports four core tasks—classification, object detection, semantic segmentation, and vision-language question answering—via unified definitions and protocols. The visual component includes large-scale annotations and a curated hard-distractor subset; the multimodal component introduces PaveVQA for single-turn, multi-turn, and expert-corrected interactions covering recognition, localization, quantitative estimation, and maintenance reasoning. The work also presents an agent-augmented VQA framework integrating domain-specific models with vision-language models and evaluates several state-of-the-art methods.
Significance. If the annotations and interactions prove reliable, PaveBench would offer a valuable bridge between conventional computer-vision perception tasks and multimodal interactive reasoning for practical highway maintenance, addressing the current gap in datasets that connect visual recognition with fact-grounded, multi-turn decision support.
major comments (2)
- [Dataset construction (abstract and §3)] Dataset construction (abstract and §3): the claim of 'large-scale annotations' and 'curated hard-distractor subset' for robustness evaluation is load-bearing, yet no inter-annotator agreement figures, expert review protocol, or systematic error-rate analysis are supplied; without these, downstream model scores on classification, detection, segmentation, and PaveVQA could reflect label noise rather than model capability.
- [Experiments and analysis (abstract and §4)] Experiments and analysis (abstract and §4): the manuscript states that 'several state-of-the-art methods' are evaluated with 'detailed analysis' and an agent-augmented framework is presented, but supplies no quantitative tables, baseline numbers, or error breakdowns; this absence prevents verification that the proposed framework or benchmark actually advances performance on the four tasks.
minor comments (1)
- [Abstract] The dataset URL is given but the manuscript should explicitly list which subsets (hard-distractor, PaveVQA splits) are released and under what license to facilitate reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on PaveBench. We address each major comment below and will revise the manuscript accordingly to strengthen the presentation of dataset reliability and experimental results.
read point-by-point responses
-
Referee: Dataset construction (abstract and §3): the claim of 'large-scale annotations' and 'curated hard-distractor subset' for robustness evaluation is load-bearing, yet no inter-annotator agreement figures, expert review protocol, or systematic error-rate analysis are supplied; without these, downstream model scores on classification, detection, segmentation, and PaveVQA could reflect label noise rather than model capability.
Authors: We agree that quantitative validation of annotation quality is essential. The current manuscript describes the annotation process in §3 but omits agreement metrics and error analysis. In revision we will add a dedicated subsection reporting inter-annotator agreement (Fleiss' kappa for classification, mean IoU for segmentation), the expert review protocol involving domain specialists, and a systematic error-rate study on a 5% held-out sample. These additions will directly address concerns about label noise. revision: yes
-
Referee: Experiments and analysis (abstract and §4): the manuscript states that 'several state-of-the-art methods' are evaluated with 'detailed analysis' and an agent-augmented framework is presented, but supplies no quantitative tables, baseline numbers, or error breakdowns; this absence prevents verification that the proposed framework or benchmark actually advances performance on the four tasks.
Authors: We acknowledge the absence of quantitative results in the submitted draft. We will expand §4 with comprehensive tables reporting accuracy/F1 for classification, mAP for detection, mIoU for segmentation, and accuracy/BLEU for PaveVQA across multiple SOTA models and our agent-augmented framework. Error breakdowns by distress category and failure-case analysis will also be included to demonstrate concrete performance gains. revision: yes
Circularity Check
No circularity: benchmark dataset release with no derivations or self-referential fits
full rationale
The paper presents PaveBench as a new curated dataset and benchmark supporting classification, detection, segmentation, and VQA tasks on real highway images, along with PaveVQA for interactive analysis. No equations, fitted parameters, predictions derived from inputs, or self-citation chains appear in the abstract or described content. The load-bearing elements are data collection, annotation curation, and task definitions, which are external to any internal derivation and do not reduce to self-definition or renaming of prior results by the same authors. This is a standard dataset release paper whose claims rest on the existence and utility of the released resources rather than any closed logical loop.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Human annotations for distress locations, types, and QA pairs are accurate and representative of real highway conditions.
Reference graph
Works this paper leans on
-
[1]
Rabih Amhaz, Sylvie Chambon, Jérôme Idier, and Vincent Baltazart. 2016. Au- tomatic crack detection on two-dimensional pavement images: An algorithm based on minimal path selection. IEEE Transactions on Intelligent Transportation Systems 17, 10 (2016), 2718–2729
work page 2016
-
[2]
Deeksha Arya, Hiroya Maeda, Sanjay Kumar Ghosh, Durga Toshniwal, and Yoshihide Sekimoto. 2024. RDD2022: A multi-national image dataset for au- tomatic road damage detection. Geoscience Data Journal 11, 4 (2024), 846–862
work page 2024
-
[3]
Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Jun- yang Lin, Chang Zhou, and Jingren Zhou. 2023. Qwen-vl: A versatile vision- language model for understanding, localization. Text Reading, and Beyond 2, 1 (2023), 1
work page 2023
-
[4]
Satanjeev Banerjee and Alon Lavie. 2005. METEOR: An automatic metric for MT evaluation with improved correlation with human judgments. In Proceedings of the acl workshop on intrinsic and extrinsic evaluation measures for machine translation and/or summarization . 65–72
work page 2005
-
[5]
Liang-Chieh Chen, Yukun Zhu, George Papandreou, Florian Schroff, and Hartwig Adam. 2018. Encoder-decoder with atrous separable convolution for se- mantic image segmentation. In Proceedings of European Conference on Computer Vision. 801–818
work page 2018
-
[6]
Marius Cordts, Mohamed Omran, Sebastian Ramos, Timo Rehfeld, Markus En- zweiler, Rodrigo Benenson, Uwe Franke, Stefan Roth, and Bernt Schiele. 2016. The cityscapes dataset for semantic urban scene understanding. In Proceedings of the IEEE conference on computer vision and pattern recognition . 3213–3223
work page 2016
-
[7]
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. 2009. Im- agenet: A large-scale hierarchical image database. In Proceedings of IEEE/CVF International Conference on Computer Vision and Pattern Recognition . Ieee, 248– 255
work page 2009
-
[8]
Markus Eisenbach, Ronny Stricker, Daniel Seichter, Karl Amende, Klaus Debes, Maximilian Sesselmann, Dirk Ebersbach, Ulrike Stoeckert, and Horst-Michael Gross. 2017. How to get pavement distress detection ready for deep learning? A systematic approach. In 2017 international joint conference on neural networks (IJCNN). 2039–2047
work page 2017
-
[9]
Tanmay Gupta and Aniruddha Kembhavi. 2023. Visual programming: Compo- sitional visual reasoning without training. In Proceedings of IEEE/CVF Interna- tional Conference on Computer Vision and Pattern Recognition . 14953–14962
work page 2023
-
[10]
Ali Hatamizadeh, Greg Heinrich, Hongxu Yin, Andrew Tao, Jose M Alvarez, Jan Kautz, and Pavlo Molchanov. 2023. Fastervit: Fast vision transformers with hierarchical attention. arXiv (2023), 1–14
work page 2023
-
[11]
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2022. LoRA: Low-Rank Adaptation of Large Language Models. In Proceedings of International Conference on Learning Repre- sentations. 1–12
work page 2022
-
[12]
Shihua Huang, Zhichao Lu, Xiaodong Cun, Yongjun Yu, Xiao Zhou, and Xi Shen
-
[13]
In Proceedings of the computer vision and pattern recognition conference
Deim: Detr with improved matching for fast convergence. In Proceedings of the computer vision and pattern recognition conference . 15162–15171
-
[14]
Lakshay Middha. 2020. Crack Segmentation Dataset. Kaggle dataset
work page 2020
-
[15]
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Yanwei Li, Ziwei Liu, and Chunyuan Li. 2024. Llava-onevision: Easy visual task transfer. arXiv (2024), 1–33
work page 2024
-
[16]
Chunyuan Li, Cliff Wong, Sheng Zhang, et al. 2023. LLaV A-Med: Training a Large Language-and-Vision Assistant for Biomedicine in One Day. In Proceed- ings of Advances in Neural Information Processing Systems . 28541–28564
work page 2023
-
[17]
Chen Li, Rui Zhao, Zeyu Wang, Huiying Xu, and Xinzhong Zhu. 2025. Remdet: Rethinking efficient model design for uav object detection. In Proceedings of the AAAI conference on artificial intelligence , Vol. 39. 4643–4651
work page 2025
-
[18]
Chin-Yew Lin. 2004. Rouge: A package for automatic evaluation of summaries. In Proceedings of Text Summarization Branches Out . 74–81
work page 2004
-
[19]
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. 2014. Microsoft coco: Common objects in context. In Proceedings of European Conference on Computer Vision . Springer, 740–755
work page 2014
-
[20]
Bo Liu, Li-Ming Zhan, Li Xu, Lin Ma, Yan Yang, and Xiaodan Mo Wu. 2021. SLAKE: A Semantically-Labeled Knowledge-Enhanced Dataset for Medical Vi- sual Question Answering. In Proceedings of IEEE International Symposium on Biomedical Imaging. 1650–1654
work page 2021
-
[21]
Hui Liu, Chen Jia, Fan Shi, Xu Cheng, and Shengyong Chen. 2025. SCSegamba: Lightweight Structure-Aware Vision Mamba for Crack Segmentation in Struc- tures. In Proceedings of IEEE/CVF International Conference on Computer Vision and Pattern Recognition. 29406–29416
work page 2025
-
[22]
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. 2023. Visual In- struction Tuning. In Proceedings of Advances in Neural Information Processing Systems. 34892–34916
work page 2023
-
[23]
Wang Liu, Xudong Kang, Puhong Duan, Zhuojun Xie, Xiaohui Wei, and Shutao Li. 2025. SOSNet: Real-Time Small Object Segmentation via Hierarchical Decod- ing and Example Mining. IEEE Transactions on Neural Networks and Learning Systems 36, 2 (2025), 3071–3083
work page 2025
-
[24]
Yahui Liu, Jian Yao, Xiaohu Lu, Renping Xie, and Li Li. 2019. DeepCrack: A deep hierarchical feature learning architecture for crack segmentation. Neurocomput- ing 338 (2019), 139–153
work page 2019
-
[25]
Zhen Liu, Wenxiu Wu, Xingyu Gu, and Bingyan Cui. 2024. PaveDistress: A comprehensive dataset of pavement distresses detection. Data in Brief 57 (2024), 111111
work page 2024
-
[26]
Meng Lou and Yizhou Yu. 2025. Overlock: An overview-first-look-closely-next convnet with context-mixing dynamic kernels. In Proceedings of IEEE/CVF Inter- national Conference on Computer Vision and Pattern Recognition . 128–138
work page 2025
-
[27]
Haoyu Lu, Wen Liu, Bo Zhang, Bingxuan Wang, Kai Dong, Bo Liu, Jingxiang Sun, Tongzheng Ren, Zhuoshu Li, Yaofeng Sun, et al. 2024. DeepSeek-VL: to- wards real-world vision-language understanding. arXiv (2024), 1–29
work page 2024
-
[28]
Hiroya Maeda, Takehiro Kashiyama, Yoshihide Sekimoto, Toshikazu Seto, and Hiroshi Omata. 2021. Generative adversarial network for road damage detection. In Computer-Aided Civil and Infrastructure Engineering , Vol. 36. 47–60
work page 2021
-
[29]
Hiroya Maeda, Yoshihide Sekimoto, Toshikazu Seto, Takehiro Kashiyama, and Hiroshi Omata. 2018. Road damage detection and classification using deep neu- ral networks with smartphone images. Computer-Aided Civil and Infrastructure Engineering 33, 12 (2018), 1127–1141
work page 2018
-
[30]
Hamed Majidifard, Peng Jin, Yaw Adu-Gyamfi, and William G Buttlar. 2020. Pavement image datasets: A new benchmark dataset to classify and densify pavement distresses. Transportation Research Record 2674, 2 (2020), 328–339
work page 2020
-
[31]
Ahmed Masry, Do Xuan Long, Jia Qing Tan, Shafiq Joty, and Enamul Hoque
-
[32]
In Proceedings of Association for Computational Lin- guistics
ChartQA: A Benchmark for Question Answering about Charts with Vi- sual and Logical Reasoning. In Proceedings of Association for Computational Lin- guistics. 2263–2279
-
[33]
Zhixiong Nan, Xianghong Li, Jifeng Dai, and Tao Xiang. 2025. MI-DETR: an object detection model with multi-time inquiries mechanism. In Proceedings of IEEE/CVF International Conference on Computer Vision and Pattern Recognition . 4703–4712
work page 2025
-
[34]
Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. 2002. Bleu: a method for automatic evaluation of machine translation. In Proceedings of the 40th annual meeting of the Association for Computational Linguistics . 311–318
work page 2002
-
[35]
Ranjan Sapkota, Rahul Harsha Cheppally, Ajay Sharda, and Manoj Karkee. 2025. YOLO26: key architectural enhancements and performance benchmarking for real-time object detection. arXiv (2025), 1–15
work page 2025
-
[36]
Yong Shi, Limeng Cui, Zhiquan Qi, Fan Meng, and Zhensong Chen. 2016. Au- tomatic Road Crack Detection Using Random Structured Forests. IEEE Transac- tions on Intelligent Transportation Systems 17, 12 (2016), 3434–3445
work page 2016
-
[37]
Ao Wang, Hui Chen, Zijia Lin, Jungong Han, and Guiguang Ding. 2025. Lsnet: See large, focus small. In Proceedings of IEEE/CVF International Conference on Computer Vision and Pattern Recognition . 9718–9729
work page 2025
-
[38]
Sanghyun Woo, Shoubhik Debnath, Ronghang Hu, Xinlei Chen, Zhuang Liu, In So Kweon, and Saining Xie. 2023. Convnext v2: Co-designing and scaling convnets with masked autoencoders. In Proceedings of IEEE/CVF International Conference on Computer Vision and Pattern Recognition . 16133–16142
work page 2023
-
[39]
Chenfei Wu, Shengming Yin, Weizhen Qi, Xiaodong Wang, Zecheng Tang, and Nan Duan. 2023. Visual ChatGPT: Talking, Drawing and Editing with Visual Foundation Models. arXiv (2023), 1–14
work page 2023
-
[40]
Xi Xiao, Yunbei Zhang, Janet Wang, Lin Zhao, Yuxiang Wei, Hengjia Li, Yanshu Li, Xiao Wang, Swalpa Kumar Roy, Hao Xu, et al. 2026. Roadbench: A vision- language foundation model and benchmark for road damage understanding. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vi- sion. 6016–6026
work page 2026
-
[41]
Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M Alvarez, and Ping Luo. 2021. SegFormer: Simple and efficient design for semantic segmen- tation with transformers. In Proceedings of Advances in Neural Information Pro- cessing Systems, Vol. 34. 12077–12090
work page 2021
-
[42]
Fan Yang, Lei Zhang, Sijia Yu, Danil Prokhorov, Xue Mei, and Haibin Ling. 2019. Feature pyramid and hierarchical boosting network for pavement crack detec- tion. IEEE transactions on intelligent transportation systems 21, 4 (2019), 1525– 1535
work page 2019
-
[43]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. 2022. React: Synergizing reasoning and acting in language models. In The eleventh international conference on learning representa- tions
work page 2022
-
[44]
Shaofeng Yin, Ting Lei, and Yang Liu. 2025. ToolVQA: A Dataset for Multi-step Reasoning VQA with External Tools. In Proceedings of IEEE/CVF International Conference on Computer Vision . 4424–4433
work page 2025
-
[45]
Fanhong Zeng, Huanan Li, Juntao Guan, Rui Fan, Tong Wu, Xilong Wang, and Rui Lai. 2025. An Efficient Hybrid Vision Transformer for TinyML Applications. In Proceedings of IEEE/CVF International Conference on Computer Vision . 19914– 19924
work page 2025
-
[46]
Tianyi Zhang, Varsha Kishore, Felix Wu, Kilian Q. Weinberger, and Yoav Artzi
-
[47]
In Proceedings of In- ternational Conference on Learning Representations
BERTScore: Evaluating Text Generation with BERT. In Proceedings of In- ternational Conference on Learning Representations
-
[48]
Xiaoman Zhang, Chaoyi Wu, Ziheng Zhao, et al. 2023. PMC-VQA: Visual In- struction Tuning for Medical Visual Question Answering. arXiv (2023), 1–19. Dexiang Li, Zhenning Che, Haijun Zhang, Dongliang Zhou, Zhao Zhang, and Yahong Han
work page 2023
-
[49]
Qingguo Zou, Yu Cao, Qingquan Li, Qingzhou Mao, and Song Wang. 2012. CrackTree: Automatic Crack Detection from Pavement Images. Pattern Recog- nition Letters 33, 3 (2012), 227–238
work page 2012
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.