On Data Thinning for Model Validation in Small Area Estimation
Pith reviewed 2026-05-13 16:47 UTC · model grok-4.3
The pith
Data thinning splits area-level survey estimates into independent training and test components to validate small area estimation models without external data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
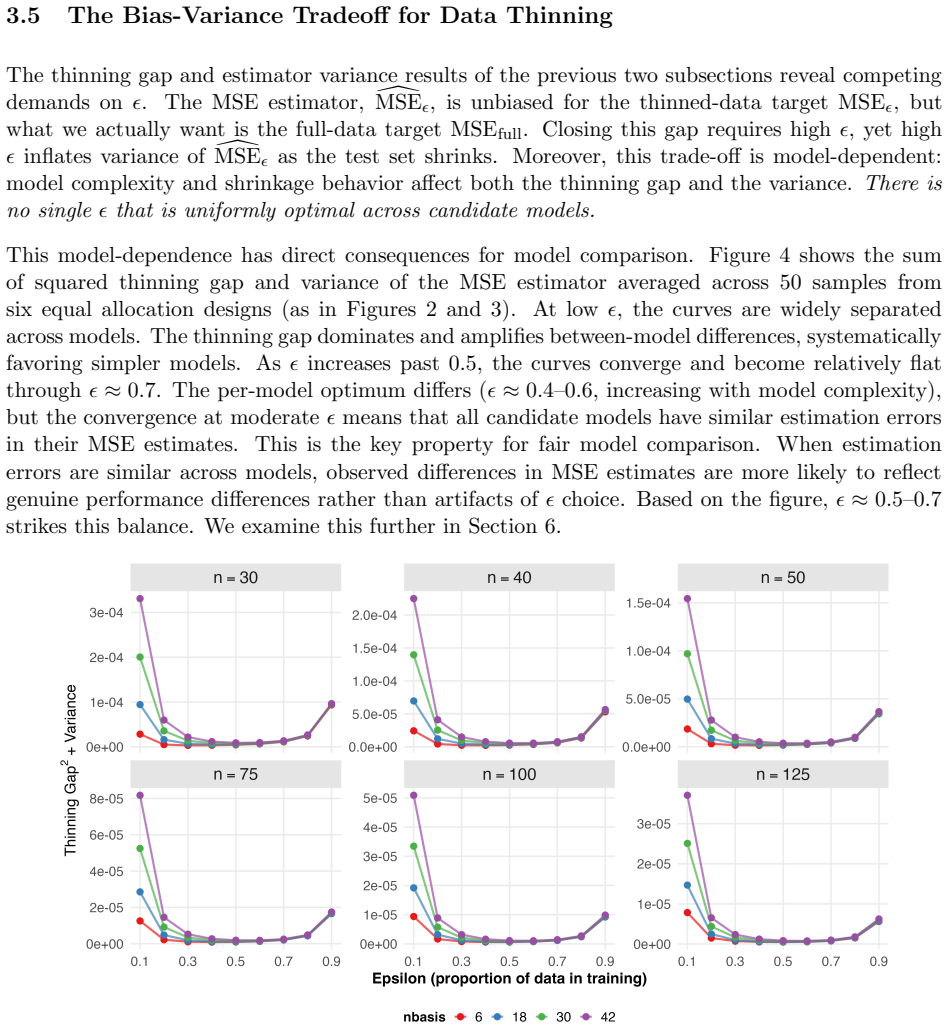
The central claim is that data thinning creates independent training and test components from area-level observations under the Fay-Herriot model, enabling principled out-of-sample validation where none existed. Theoretical analysis establishes that metrics computed on the thinned training component target a different quantity than full-data metrics, with the discrepancy scaling by model complexity. The bias-variance tradeoff is formally characterized, and specific thinning parameters are identified that balance the competing effects to support reliable model selection.
What carries the argument
Data thinning, which splits each area-level direct estimate into independent training and test components under the Fay-Herriot model to support out-of-sample validation.
If this is right
- Thinned training metrics can be used directly for model comparison once the bias-variance tradeoff is accounted for by the recommended allocation.
- Increasing the share of information retained for training narrows the gap to full-data performance but simultaneously raises the variance of the thinned estimator.
- The identified thinning parameters produce consistent and stable validation results across heterogeneous sampling designs in ACS-based simulations.
- The approach supplies a practical validation scheme that relies solely on routinely available area-level direct estimates.
Where Pith is reading between the lines
- The same thinning construction could be adapted to SAE models that extend the Fay-Herriot framework by adding random effects or spatial structure.
- Validated SAE models produced this way could feed more directly into policy allocations that depend on poverty or health estimates for small domains.
- Empirical checks on other national surveys would test whether the recommended thinning ratios generalize beyond the ACS sampling designs examined.
Load-bearing premise
The thinned training and test components remain independent and performance metrics measured on the thinned training component can be meaningfully related to full-data metrics despite targeting a different quantity whose gap varies by model complexity.
What would settle it
A design-based simulation on ACS microdata in which model rankings or performance values obtained from the recommended thinned training component diverge from full-data rankings by more than the bias amount predicted by the tradeoff analysis.
Figures







read the original abstract
Small area estimation produces estimates of population parameters for geographic and demographic subgroups with limited sample sizes. Such estimates are critical for policy decisions, yet principled validation of these models remains a challenge. Unlike conventional predictive settings, validation data are rarely available. Data thinning splits a single observation into independent training and test components. It enables out-of-sample validation using only the area-level summary statistics routinely available, requiring only their Gaussianity and known sampling variances. However, the properties of thinning-based model comparison have not been formally studied. In this paper, we develop these properties. We construct an unbiased estimator of thinned-data mean squared error and show that it differs systematically from its full-data counterpart; for the standard Fay-Herriot model, the gap admits a closed-form expression that depends on the candidate model's shrinkage behavior. We further show that the estimator variance increases sharply as the training fraction approaches one, producing a bias-variance tradeoff with no universally optimal thinning parameter. Practical recommendations balancing these forces are informed by theory and verified empirically. Design-based simulations using American Community Survey microdata show that the recommended data thinning approach is competitive with information-criterion and simulation-based methods, and substantially more stable across heterogeneous sampling designs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes data thinning to split area-level direct estimates into independent training and test components for out-of-sample validation of Fay-Herriot small area estimation models. It theoretically characterizes the bias-variance tradeoff arising because thinned-training performance metrics target a different quantity than full-data metrics (with the gap depending on model complexity), derives practical recommendations for the thinning proportion, and reports consistent and stable performance across heterogeneous sampling designs in design-based simulations on American Community Survey microdata.
Significance. If the recommended thinning parameters preserve relative model rankings despite the documented gap in target quantities, the method would address a longstanding practical gap in SAE validation where external data are unavailable. The use of design-based simulations on real ACS microdata provides a stronger test of robustness than purely model-based evaluations.
major comments (2)
- [Theoretical Analysis and Simulation Results] The abstract and theoretical analysis note that the gap between thinned-training and full-data metrics varies by model complexity, yet no explicit verification is provided that relative model orderings are preserved under the recommended thinning proportion; without this, the procedure's utility for model comparison (rather than absolute performance) is not established.
- [Simulation Results] The design-based simulations claim stability across heterogeneous sampling designs, but the reported results do not include side-by-side comparison of model rankings obtained from thinned-training metrics versus full-data metrics; this comparison is required to confirm that the bias-variance tradeoff does not systematically alter selection decisions.
minor comments (2)
- [Abstract] The abstract refers to 'these settings' for the thinning parameters without stating the numerical values; these should be given explicitly in the abstract and again in the recommendations section.
- [Methods] Notation for the thinned training and test components should be introduced with a clear definition of the independence property and how the performance metric on the thinned training component relates to the full-data target.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the scope and presentation of our results. We agree that explicit checks on model ranking preservation are valuable for demonstrating the method's utility in model selection. Below we address each major comment and outline the corresponding revisions.
read point-by-point responses
-
Referee: [Theoretical Analysis and Simulation Results] The abstract and theoretical analysis note that the gap between thinned-training and full-data metrics varies by model complexity, yet no explicit verification is provided that relative model orderings are preserved under the recommended thinning proportion; without this, the procedure's utility for model comparison (rather than absolute performance) is not established.
Authors: We appreciate this observation. Our theoretical results characterize the gap as a function of model complexity and thinning proportion, and the recommended parameters are explicitly chosen to keep the gap small enough to support stable relative comparisons. Nevertheless, we agree that a direct numerical verification of ranking preservation would strengthen the manuscript. In the revision we will add an explicit check (new table or figure in the simulation section) that compares model orderings under the recommended thinning proportions to the full-data orderings across the ACS-based designs. revision: yes
-
Referee: [Simulation Results] The design-based simulations claim stability across heterogeneous sampling designs, but the reported results do not include side-by-side comparison of model rankings obtained from thinned-training metrics versus full-data metrics; this comparison is required to confirm that the bias-variance tradeoff does not systematically alter selection decisions.
Authors: We agree that a side-by-side ranking comparison is the most direct way to confirm that the bias-variance tradeoff does not change selection decisions. The current simulations already demonstrate low variability of the thinned metrics across designs, but they stop short of tabulating the implied rankings against the full-data benchmark. We will add this comparison (new table or supplementary figure) in the revised manuscript, using the same simulation settings and model candidates already reported. revision: yes
Circularity Check
Derivation self-contained; bias-variance tradeoff derived directly from thinning construction without reduction to inputs
full rationale
The paper starts from the proposed data-thinning split of area-level Fay-Herriot observations into independent training and test components, then derives the explicit bias-variance tradeoff for the thinned-training performance metric versus the full-data target. This is a first-principles characterization of the method's own properties rather than any self-definitional loop, fitted parameter renamed as prediction, or load-bearing self-citation. Recommendations for thinning fractions follow from balancing the derived expressions, and stability is checked via external design-based simulations on ACS microdata. No step equates a claimed result to its inputs by construction, and the central validation claim rests on simulation evidence outside the analytic derivation.
Axiom & Free-Parameter Ledger
free parameters (1)
- thinning proportion
axioms (1)
- domain assumption Thinned training and test components are independent
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Our approach is based on data thinning, which splits area-level observations into independent training and test components... Theorem 3.2 (Unbiased MSE estimation)... Proposition 3.3 (MSE thinning gap under known parameters) Δ_i(ε) = (1-ε)/ε · γ_i(ε)γ_i d_i
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Gaussian data thinning... y(1)_i ~ N(ε θ_i, ε d_i) and y(2)_i ~ N((1-ε) θ_i, (1-ε) d_i)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 2 Pith papers
-
Design-Based Cross-Validation for Comparing Small Area Estimators
A new cross-validation approach for small area estimators decomposes error to reveal bias and bound uncertainty, outperforming leave-one-area-out methods in simulations and Zambia literacy data.
-
Design-Based Cross-Validation for Comparing Small Area Estimators
A cross-validation framework for small area estimation decomposes error to separate measurable bias from bounded unknowns, showing that leave-one-area-out methods can produce misleading model rankings while the new ap...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.